the-go-programming-language
Table of Contents
- Chapter 01: Tutorial
- Chapter 02: Program Structure
- Chapter 03: Basic Data Types
- Chapter 04: Composite Types
- Chapter 05: Functions
- Chapter 06: Methods
- Chapter 07: Interfaces
- Interfaces as Contracts
- Interface Types
- Interface Satisfaction
- Parsing Flags with flag.Value
- Interface Values
- Sorting with sort.Interface
- The http.Handler Interface
- The error Interface
- Example: Expression Evaluator
- Type Assertions
- Discriminating Errors with Type Assertions
- Querying Behaviors with Interface Type Assertions
- Type Switches
- Example: Token-Based XML Decoding
- A Few Words of Advice
- Chapter 08: Goroutines and Channels
- Chapter 09: Concurrency with Shared Variables
Chapter 01: Tutorial
Hello, World
- 下面就是go的helloworld代码
https://play.golang.org/p/pEydfiFPIs
package main import "fmt" func main() { fmt.Println("Hello, 世界") } // <===================OUTPUT===================> // Hello, 世界
- go是编译语言, go toolchain会把源代码以及源代码依赖的库转换成native machine language.
- 编译的方法是使用命令go 加上一些subcommand,最简单的subcommand就是run, 比如上
面的代码就是使用go run获得的OUTPUT
$ go run main.go Hello, 世界
- go内部支持Unicode,所以他可以处理世界上的所有语言
- 另外一个常见的sucommand就是build, go build可以把源代码编译成一个executable binary file
- go的代码是以package的形式进行组织的.一个package包含一个或者多个.go文件,并且 被定义在同一个文件夹下面
- 每一个文件都要以package开头,上面的例子是以package main开头,指的是main package
- go的standard libray有超过100个package,比如fmt,这个package就包含input,output 等的函数
- package main是一个test的package,只有它是表示了自己是standalone executable文 件其他所有的package都是代表library
- 在package main内部, 函数main也是特别的,它是表示了executable文件开始的地方
- 你必须同时告诉编译器,你需要哪些package,告诉编译器的方式就是import. 我们的 hello-world程序只使用了一个其他package的function,但是一般来说都会import多个 package
- go要求你只能import"刚刚好的"package,import没有被用到的package会导致编译失败
- function declaration包括了如下的几个部分:
- func关键字
- 函数的名字(这里是main)
- 函数的参赛list(这里是空)
- 函数的返回值list(这里也是空)
- Go不要求statement结尾的分好,除非多个语句出现在同一行.在内部,其实编译器是如
下处理的:
If the newline comes after a token that could end a statement, insert a semicolon
- 这也就解释了为什么为什么'{'不能单独一行,因为, 如果'{'单独一行的话,'{'之前的
语句之后就会被加上一个分号,如下f()后面会有一个分号
if i < f() // wrong { // wrong g() }
- Go语言对格式的要求非常严格,你需要对自己的代码运行gofmt来保证其格式.这也是一 个在工程上来讲特别有效的做法.你可以设置每次save的时候都gofmt一遍以便保证自己 格式的正确性
- 一个不在standard distribution里面的命令是goimports,goimports可以同时起到如
下两个作用:
- gofmt
- import 必要的package
- 我们可以使用如下的命令来安装goimports
$ go get golang.org/x/tools/cmd/goimports
Command-Line Arguments
- 和c语言类似,我们的go exe文件需要在运行之初获得一些参数,这些参数在go里面是存 放在变量Args里面的,而这个变量是package os暴露出来的,所以这个变量叫做os.Args
- os.Args的类型是string slice. 而你现在可以把它理解为一个string"变长数组".这样
一来os.Args就和Java里面的args差不多了:
- os.Args表示exe自己
- os.Args[1:len(os.Args)]表示剩下的参数. Go使用类似python的数组表达方式,所 以可以不加':'后面的数字,默认就是剩下所有.所以os.Args[1:len(os.Args)]和 Args[1:]完全等价
- 下面是一个使用go来重写unix的echo函数的例子
https://play.golang.org/p/0CjFBMUrTG
// Echo1 prints its command-line arguments. package main import ( "fmt" "os" ) func main() { var s, sep string for i := 1; i < len(os.Args); i++ { s += sep + os.Args[i] sep = " " } fmt.Println(s) } // <===================OUTPUT===================> // $ go run main.go a b c d E f // a b c d E f
- 上面是比较c的方式来实现我们的逻辑,其实还有更加go的方式,那就是使用range函数:
range函数是非常特殊的一种函数,它返回两个值(所以必须使用`:`), 第一个值是index
而第二个值是value,我们只需要value,所以第一个值可以使用`_`占位符,例子如下
https://play.golang.org/p/vhKc6nYNNT
// Echo2 prints its command-line arguments. package main import ( "fmt" "os" ) func main() { s, sep := "", "" for _, arg := range os.Args[1:] { s += sep + arg sep = " " } fmt.Println(s) }
- 这个版本的代码中,使用了short variable declaration来"声明并且初始化了"s和sep
这种方法使用了':',初始化一个变量有很多种方法,如下的四种方法都是等价的.
s := "" var s string var s = "" var s string = ""
- 第一种也就是short variable declaration是最简洁的,但是它"只能用在function里面" 不能用于package-level的变量
- 第二种方法之所以和其他等价,在于go的string的默认初始化值就是"",没有这个前提 是无法推导出等价的
- 第三种格式用的时候不多
- 第四种的用法把string也列出来带来,显得有些多余,但是在某些时候是必须的
- 总结起来就是,前两种方法分别用在function里面和function外面.
- 和java语言类似,string在go里面也是immutable的,所以上面两个例子接连在循环中append
字符给s可能会造成性能方面的缺失.解决的办法是下面的例子:使用strings package里
面的Join函数(大写函数为public函数)
https://play.golang.org/p/XylG_RKQ7Z
// Echo3 prints its command-line arguments. package main import ( "fmt" "os" "strings" ) //!+ func main() { fmt.Println(strings.Join(os.Args[1:], " ")) }
Finding Duplicate Lines
- Unix有个命令叫做uniq,就是把"相邻"的重复行给找出来.注意只是能找"相邻"重复的行
所以在使用的时候要使用sort命令,把重复的行都排在一块.如下是sort和uniq配合使用
的例子
i309511@ tmp (master) $ cat test.txt A good idea Below everage Below everage Below everage Custom Issue Below everage Below everage Custom Issue Custom Issue Custom Issue A good idea i309511@ tmp (master) $ sort test.txt A good idea A good idea Below everage Below everage Below everage Below everage Below everage Custom Issue Custom Issue Custom Issue Custom Issue i309511@ tmp (master) $ uniq test.txt A good idea Below everage Custom Issue Below everage Custom Issue A good idea i309511@ tmp (master) $ sort test.txt | uniq A good idea Below everage Custom Issue i309511@ tmp (master) $ sort test.txt | uniq -c 2 A good idea 5 Below everage 4 Custom Issue
- 下面就是模仿uniq -c的演示程序dup,我们先来看看第一个版本dup1
https://play.golang.org/p/sas2jcgPuH
// Dup1 prints the text of each line that appears more than // once in the standard input, preceded by its count. package main import ( "bufio" "fmt" "os" ) func main() { counts := make(map[string]int) input := bufio.NewScanner(os.Stdin) for input.Scan() { counts[input.Text()]++ } // NOTE: ignoring potential errors from input.Err() for line, n := range counts { if n > 1 { fmt.Printf("%d\t%s\n", n, line) } } } // <===================OUTPUT===================> // go run main.go // hello // hello // world // world // world // we // 2 hello // 3 world
- 借助内置的map,实现uniq变得如此的容易!我们来看看几个细节:
- 内置数据结构map,使用函数make来创建(make只能用来创建map, slice, chan三种类 型)一个empty的map. map的存,储,测三个操作的复杂度都是线性时间的
- map key的类型可以是所有可以使用"=="进行比较的类型,string是最常见的key,这 里的key就是string, value是int
- bufio.NewScanner创建了一个Scanner,所谓Scanner你理解成token array就可以了.
- 我们这里又见到了"short variable declaratin"
input := bufio.NewScanner(os.Stdin)
- for input.Scan():这一句要注意了.这里的for,其实是起到了while (true)的作用, 因为input.Scan()会"探测"下面还有没有.如果下面还有新的一行,token.Scan function会返回true, 否则会返回false
- input.Text()其实就是取出当前的token(也就是一个string)
- 下面的for … range是go特殊的用法了. range函数会返回两个值(key, value)的 循环. map iteration是顺序是随机的.(为了更有效的设计map结构)
- Printf就是跟c语言学的啦,会产生formatted output: 常见的%代表如下. 比较"新颖"
的是%v的设计:
- 如果打印的数据为字符串,那么%v就相当于%s
- 如果打印的数据为bool,那么%v就相当于%t
- 等等…
format Meaning %d decimal integer %x, %o, %b integer in hexadecimal, octal, binary %f, %g, %e float-pint number %t boolean: true or false %c rune(Unicode code point) %s string %q quoted string "abc" or rune 'c' %v any value in a natural format %T type of any value %% literal percent sign
- 下面我们来看版本二dup2, 这个版本,可以通过有没有参数(os.Args)来决定是从文件
读入,还是从standard input读入
https://play.golang.org/p/YESysDK9_F
// Dup2 prints the count and text of lines that appear more than once // in the input. It reads from stdin or from a list of named files package main import( "bufio" "fmt" "os" ) func main() { counts := make(map[string]int) files := os.Args[1:] if len(files) == 0 { countLines(os.Stdin, counts) } else { for _, arg := range files { f, err := os.Open(arg) if err != nil { fmt.Fprintf(os.Stderr, "dup2: %v\n", err) continue } countLines(f, counts) f.Close() } } for line, n := range counts { if n > 1 { fmt.Printf("%d\t%s\n", n, line) } } } func countLines(f *os.File, counts map[string]int) { input := bufio.NewScanner(f) for input.Scan() { counts[input.Text()]++ } // NOTE: ignoring potential errors from input.Err() }
- 函数os.Open返回两个值,第一个是我们真正想要的file的descriptor的对象(*os.File),
第二个就是一个error type用来表示这次打开文件是否成功:
- 如果err为nil,就说明成功
- 如果err不为为nil,为某个error类型的值,那么就是打开失败了,打印错误,使用%v 然后继续这里的处理是继续,打开下一个文件
- 这里我们把一个map传递给了以子函数.这里我们需要对map做点解释.在go里面,有些类 型是reference的, 比较典型的就是map. 当我们使用make来创建一个map的时候,返回值 是这个map的ref(也就是指针)!当我们把ref传递给子函数的时候,即便是值传递,也不 有太多的拷贝出现!
- Tips:go里面的reference type有 map,slice, channel.而array则是一个value
- dup2是依赖了Scanner的特性,把文件都"按行"给处理成'input数组'了.这个可能是go
里面的比较方便的一个类,别的语言并不一定有.更加通用的方法是把字符串全部读入
内存,然后使用split('\n')的方法把大字符串切成'真的数组'.dup3就是这么做的
https://play.golang.org/p/7S7Q6o0Z0M
// Dup3 prints the count and text of lines that appear more than once // in the named input files. package main import ( "fmt" "io/ioutil" "os" "strings" ) func main() { counts := make(map[string]int) for _, filename := range os.Args[1:] { data, err := ioutil.ReadFile(filename) if err != nil { fmt.Fprintf(os.Stderr, "dup3: %v\n", err) continue } for _, line := range strings.Split(string(data), "\n") { counts[line]++ } } for line, n := range counts { if n > 1 { fmt.Printf("%d\t%s\n", n, line) } } }
Animated GIFs
- 下面是一个创建"动态gif"文件的程序,其实并不需要你完全的理解创建gif的过程,只
是通过这个例子来快速了解一些golang的特性
https://play.golang.org/p/o2o2lDR3Eg
// Lissajous generates GIF animations of random Lissajous figures. package main import ( "image" "image/color" "image/gif" "io" "math" "math/rand" "os" ) //!-main // Packages not needed by version in book. import ( "log" "net/http" "time" ) //!+main var palette = []color.Color{color.White, color.Black} const ( whiteIndex = 0 // first color in palette blackIndex = 1 // next color in palette ) func main() { //!-main // The sequence of images is deterministic unless we seed // the pseudo-random number generator using the current time. // Thanks to Randall McPherson for pointing out the omission. rand.Seed(time.Now().UTC().UnixNano()) if len(os.Args) > 1 && os.Args[1] == "web" { //!+http handler := func(w http.ResponseWriter, r *http.Request) { lissajous(w) } http.HandleFunc("/", handler) //!-http log.Fatal(http.ListenAndServe("localhost:8000", nil)) return } //!+main lissajous(os.Stdout) } func lissajous(out io.Writer) { const ( cycles = 5 // number of complete x oscillator revolutions res = 0.001 // angular resolution size = 100 // image canvas covers [-size..+size] nframes = 64 // number of animation frames delay = 8 // delay between frames in 10ms units ) freq := rand.Float64() * 3.0 // relative frequency of y oscillator anim := gif.GIF{LoopCount: nframes} phase := 0.0 // phase difference for i := 0; i < nframes; i++ { rect := image.Rect(0, 0, 2*size+1, 2*size+1) img := image.NewPaletted(rect, palette) for t := 0.0; t < cycles*2*math.Pi; t += res { x := math.Sin(t) y := math.Sin(t*freq + phase) img.SetColorIndex(size+int(x*size+0.5), size+int(y*size+0.5), blackIndex) } phase += 0.1 anim.Delay = append(anim.Delay, delay) anim.Image = append(anim.Image, img) } gif.EncodeAll(out, &anim) // NOTE: ignoring encoding errors } //!-main //////////////////////////////////////////////////// // <===================OUTPUT===================> // // go run main.go > lissajous.gif // ////////////////////////////////////////////////////
- 上面的程序蕴含了许多的信息,我们重点来看看这些信息:
- 我们import的很多package,虽然有时候名字是image/color两个部分组成的,但是使 用的时候,还是会使用后面的部分,比如color.White就是color package里面的, 而 gif.GIF则是image/gif package里面的
- const关键字是给予'常量'一个有意义的名字的.const的定义可以出现在两个地方:
- package level(在main packge就是全局变量啦), 整个package可见
- function level, 只在function内部可见
- const的值只可能是三种值:number, string或者boolean.这一点非常重要!
- 类似于[]color.Color{…}的这种表达式叫做composite literal. 我们一下子有两
个composite literal的例子:
- []color.Color是一个slice(长度不固定数组)!所以{}里面是数组的初始化变量, 也就是两个颜色color.Black和color.White. 这里这两个值是采用one by one的 方式列出来的
- gif.GIF是一个struct,所以{}里面就是类似json的一种初始化方式,也可以使用one by one的方式,但是明显的json的方式更加友好
- gif.GIF是一个struct类型,我们在c语言里面已经了解过这个类型了,这个类型的特 点是:它包括了其他的类型,把他们"包裹"起来,形成一个新的类型.换句话说就是用户 自创类型.在cpp里面struct关键字等于是public的class,由此我们也可以看出go使用 这个关键字的一点点端倪:所有的struct field都可以直接访问!
- 前面说过了,我们使用composite literal的方式,提供了一个json格式的初始化列表
{LoopCount:nframes}给gif.GIF.但是gif.GIF明显不会只有这个一个域名,其他所有
没有被赋值的域名都要使用"零值". 后面我们会看到struct的普通field都直接使用
dot notation来访问,比如
anim.Delay = append(anim.Delay, delay) anim.Image = append(anim.Image, image)
- 这个例子的lissajous 函数的形参是io.Writer,实参是os.Stdout,我们后来会看到我
们也可以把结果写入到网页上.这就涉及到go的interface, 如下两个对象都符合io.Writer:
- http.ResponseWriter
- os.Stdout
Fetching a URL
- 我们来看如下一个使用go来模仿bash里面的curl的例子
https://play.golang.org/p/PDpqAKi_gO
// Fetch prints the content found at a URL. package main import ( "fmt" "io/ioutil" "net/http" "os" ) func main() { for _, url := range os.Args[1:] { resp, err := http.Get(url) if err != nil { fmt.Fprintf(os.Stderr, "fetch: %v\n", err) os.Exit(1) } b, err := ioutil.ReadAll(resp.Body) resp.Body.Close() if err != nil { fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err) os.Exit(1) } fmt.Printf("%s", b) } } //!- /////////////////////////////////////////////////////////////////////// // <===================OUTPUT===================> // // $ ./fetch http://baidu.com // // <html> // // <meta http-equiv="refresh" content="0;url=http://www.baidu.com/"> // // </html> // ///////////////////////////////////////////////////////////////////////
- 这个例子有如下的要点要学习:
- http.Get函数是会使用GET method来访问某个url,如果没有错误的话,resp里面就会 含有Response类型的变量,包含有所有的HTTP response的信息
- iotil.ReadAll负责把Body里面的信息读取出来返回给b, 然后我们caller需要负责 Close() resp.Body
- 其实更让我们需要学习的是go组织代码的方式:
- Response本身就是一个struct
- Body是Response内部的一个interface,两者的关系用代码表示如下
type Response struct { Status string // e.g. "200 OK" // .... Body io.ReadCloser // .... }
- 我们的Body作为io.ReadCloser类型的数据,想从中读取数据,就要借助一些library
这里借助的是ioutil.ReadAll,我们看到ioutil.ReadAll的函数声明如下
func ReadAll(r io.Reader) ([]byte, error)
- 这就引出了一个问题:我们如何知道io.Reader是io.ReadCloser的父类的?这就又
要看ReadCloser的定义了
// ReadCloser is the interface that groups the basic Read and Close methods. type ReadCloser interface { Reader Closer }
- 这里又引出了go里面对"怎样算实现了interface"的定义:
实现了interface里面所有的函数,就算实现了这个interface,不需要显式的写出implement - 我们的ReadCloser interface里面包括了Reader interface,所以实现了ReadCloser interface的instance肯定实现了N个函数,这个N歌函数里面肯定有Reader需要的M 个函数(N > M)
Fetching URLs Concurrently
- 下面我们来简单的使用以下go的killer feature, goroutine, 下面是goroutine的一
个例子:多线程的来fetch url数据.这个例子设计的比较巧妙,goroutine之间没有依赖
关系,没有访问shared memory所以也不需要用锁.所以,最终的抓取时间取决于最慢的那一个
https://play.golang.org/p/l3t-FanD3X
// Fetchall fetches URLs in parallel and reports their times and sizes. package main import ( "fmt" "io" "io/ioutil" "net/http" "os" "time" ) func main() { start := time.Now() ch := make(chan string) for _, url := range os.Args[1:] { go fetch(url, ch) // start a goroutine } for range os.Args[1:] { fmt.Println(<-ch) // receive from channel ch } fmt.Printf("%.2fs elapsed\n", time.Since(start).Seconds()) } func fetch(url string, ch chan<- string) { start := time.Now() resp, err := http.Get(url) if err != nil { ch <- fmt.Sprint(err) // send to channel ch return } nbytes, err := io.Copy(ioutil.Discard, resp.Body) resp.Body.Close() // don't leak resources if err != nil { ch <- fmt.Sprintf("while reading %s: %v", url, err) return } secs := time.Since(start).Seconds() ch <- fmt.Sprintf("%.2fs %7d %s", secs, nbytes, url) } //!- ///////////////////////////////////////////////////////////////////////////////// // <===================OUTPUT===================> // // > go run main.go http://www.baidu.com http://www.bing.com http://www.360.cn // // 0.21s 61705 http://www.bing.com // // 0.31s 98409 http://www.baidu.com // // 0.41s 105174 http://www.360.cn // // 0.41s elapsed // /////////////////////////////////////////////////////////////////////////////////
- 为了理解这个例子,首先介绍两个概念:
- goroutine: 是一个并发的function execution.我们可以把它看做是轻量级thread
- channel: 是一个允许goroutine间传递"某种一种类型"数据的"通道". channel是有 类型的,比如上面例子的channel就是string类型的,那么string类型的channel就只 可以在goroutine之间传递string
- 我们来看看整个代码:
- 创建channel使用的是make, make只可以为slice, map, chan三种类型服务, 而且make 的返回值是引用而不是指针.
- 对于每一个Arg参数, 我们都会使用go关键字来创建一个goroutine来'单独地异步地' 运行fetch函数
- fetch函数的原理就和上一节的main函数很像啦:就是GET打开一个url, 只不过这次
我们不关心具体数据是啥(所以Discard掉),只是把字节数写入nbytes而已.discard
还很文艺,使用了ioutil.Discard
// Discard is an io.Writer on which all Write calls succeed // without doing anything. var Discard io.Writer = devNull(0)
- 第二个循环就是把channel里面的内容打印出来.
- 关于channel:
- channel有两个操作,注意箭头总是向左的,进入ch就是输入,从ch出来就是输出:
- 写入:
ch <- fmt.Sprintf("while reading %s: %v", url, err)
- 读取:
fmt.Println(<-ch) // receive from channel ch
- 写入:
- 当goroutine 试图去写入channel的时候是会block住的,直到有另外一个goroutine来 '读取'. 在上面的例子中main goroutine 中"读取"ch的操作会一直block,直到ch被 某个其他的goroutine写入.反之亦然
- channel有两个操作,注意箭头总是向左的,进入ch就是输入,从ch出来就是输出:
A Web Server
- 刚才写的fetch是client端的操作,go也很容易写出server的服务器,比如下面就是一个
简单的echo server服务器
https://play.golang.org/p/5My0dnzqIs
// Server1 is a minimal "echo" server. package main import ( "fmt" "log" "net/http" ) func main() { http.HandleFunc("/", handler) // each request calls handler log.Fatal(http.ListenAndServe("localhost:8000", nil)) } // handler echoes the Path component of the request URL r. func handler(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "URL.Path = %q\n", r.URL.Path) }
- 此程序的要点:
- HandleFunc设置了一个函数handler来处理"所有以/开头的request"
- 函数handler就是接受类型为http.Request的input,然后把结果写入到ResponseWriter 里面.
- 一个最简单的更改就是增加一个HandleFunc和一个handler
https://play.golang.org/p/wAnKCZwlem
// Server2 is a minimal "echo" and counter server. package main import ( "fmt" "log" "net/http" "sync" ) var mu sync.Mutex var count int func main() { http.HandleFunc("/", handler) http.HandleFunc("/count", counter) log.Fatal(http.ListenAndServe("localhost:8000", nil)) } // handler echoes the Path component of the requested URL. func handler(w http.ResponseWriter, r *http.Request) { mu.Lock() count++ mu.Unlock() fmt.Fprintf(w, "URL.Path = %q\n", r.URL.Path) } // counter echoes the number of calls so far. func counter(w http.ResponseWriter, r *http.Request) { mu.Lock() fmt.Fprintf(w, "Count %d\n", count) mu.Unlock() }
- 这里的新handler是用来记录从多个不同的client来的不同访问总过有多少.
- 因为是多个不同的client访问同一块内存count,所以要保证我们的count只能"同时被 一个client更新",所以我们这个例子还需要mutex的支持.所以这里使用了sync.Mutex
- 对server的进一步扩展就是增加了header信息
https://play.golang.org/p/YsH3jIqzMv
// Server3 is a minimal "echo" and counter server. package main import ( "fmt" "log" "net/http" "sync" ) var mu sync.Mutex var count int func main() { http.HandleFunc("/", handler) http.HandleFunc("/count", counter) log.Fatal(http.ListenAndServe("localhost:8000", nil)) } //!+handler // handler echoes the HTTP request. func handler(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "%s %s %s\n", r.Method, r.URL, r.Proto) for k, v := range r.Header { fmt.Fprintf(w, "Header[%q] = %q\n", k, v) } fmt.Fprintf(w, "Host = %q\n", r.Host) fmt.Fprintf(w, "RemoteAddr = %q\n", r.RemoteAddr) if err := r.ParseForm(); err != nil { log.Print(err) } for k, v := range r.Form { fmt.Fprintf(w, "Form[%q] = %q\n", k, v) } } //!-handler // counter echoes the number of calls so far. func counter(w http.ResponseWriter, r *http.Request) { mu.Lock() fmt.Fprintf(w, "Count %d", count) mu.Unlock() }
- 这个例子里面提供了一个check err的新思路"nested err in if statement"
if err := r.ParseForm(); err != nil { log.Print(err) }
- 我们还可以使用function literal的方法来设置匿名函数处理不同的url
http.HandleFunc("/", func(w http.ResonseWriter, r *http.Request){lissajous(w)})
- 下面就是前面讲到的,因为都实现了io.Writer,我们可以把原本写入到io.Stdout的内
容,写入到http.ResponseWriter里面
https://play.golang.org/p/shcJUg8b8E
// Lissajous generates GIF animations of random Lissajous figures. package main import ( "image" "image/color" "image/gif" "io" "math" "math/rand" "os" ) //!-main // Packages not needed by version in book. import ( "log" "net/http" "time" ) //!+main var palette = []color.Color{color.White, color.Black} const ( whiteIndex = 0 // first color in palette blackIndex = 1 // next color in palette ) func main() { //!-main // The sequence of images is deterministic unless we seed // the pseudo-random number generator using the current time. // Thanks to Randall McPherson for pointing out the omission. rand.Seed(time.Now().UTC().UnixNano()) if len(os.Args) > 1 && os.Args[1] == "web" { //!+http handler := func(w http.ResponseWriter, r *http.Request) { lissajous(w) } http.HandleFunc("/", handler) //!-http log.Fatal(http.ListenAndServe("localhost:8000", nil)) return } //!+main lissajous(os.Stdout) } func lissajous(out io.Writer) { const ( cycles = 5 // number of complete x oscillator revolutions res = 0.001 // angular resolution size = 100 // image canvas covers [-size..+size] nframes = 64 // number of animation frames delay = 8 // delay between frames in 10ms units ) freq := rand.Float64() * 3.0 // relative frequency of y oscillator anim := gif.GIF{LoopCount: nframes} phase := 0.0 // phase difference for i := 0; i < nframes; i++ { rect := image.Rect(0, 0, 2*size+1, 2*size+1) img := image.NewPaletted(rect, palette) for t := 0.0; t < cycles*2*math.Pi; t += res { x := math.Sin(t) y := math.Sin(t*freq + phase) img.SetColorIndex(size+int(x*size+0.5), size+int(y*size+0.5), blackIndex) } phase += 0.1 anim.Delay = append(anim.Delay, delay) anim.Image = append(anim.Image, img) } gif.EncodeAll(out, &anim) // NOTE: ignoring encoding errors }
Losse Ends
- go里面的switch是自动break的,不需要额外的break
- 而且switch是可以没有operand的, 如下.这种其实就是switch true的意思
func Siignum(x int) int { switch { case x > 0: return +1 default: return 0 case x < 0: return -1 } }
- go里面也是有break和continue的
- type是一个c语言里面typedef的继承者,能够给struct一个更加"容易记住的名字",当 然了,我们后面会看到interface也会使用type来起名字的
- Go语言还是提供了pointer.对pointer的态度一般有两种:
- 比如c语言里面pionter几乎是不受限制的
- 比如java语言里面,没有pointer这个概念,使用reference来取代pointer.reference 除了被传递来传递去,也没有其他的作用
- Go对pointer采取了"折中"的态度:
- 和c一样有pionter,而且&同样是'取地址', *是'解地址'
- 但是pointer不能像c里面一样进行算术运算
- function是一个常见的概念,c语言开始就有.method则是一个OO语言里面的概念:某个类 型所拥有的function就叫做method
- interface则是Go的特点了,它以你"是否实现了interface规定的function"来决定你是否 implements了这个interface.而不是显示的写出implements
- go比c语言先进的地方是它有了package系统
- go的注释也是和c语言一样,/*…*/ 或者//都可以
Chapter 02: Program Structure
- 和其他的语言一样,go里面的:
- 变量存储数据
- 简单的expression会通过操作符合成一个大的expression
- 不同的'稍微简单的类型'通过组合成为struct,相同的简单类型通过组合形成了array
- expression会进一步成为statment,expression自己本身就是statement, 但是statement 还包括更多,比如condition control
- statement会把一段单独的逻辑独立出来,形成可以复用的function
- function组合起来就形成了package
Names
- go的命名规则和c一致,大小写也是区分的.
- keyword有25个,keyword的特点是不能用作name
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var
- 除了keyword以外,还有,如下三类的predeclared names. predeclared names不是保留
字,所以你可以在declaration里面使用它们,当然我们不推荐这样做
Constants: true false iota nil _________________________________________________________________________________________ Types: int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr float32 float64 complex128 complex64 bool byte rune string error _________________________________________________________________________________________ Functions: make len cap new append copy close delete complex real imag panic recover - 如果一个entity在function内部定义,那么这个entity是local于这个function的
- 如果定义在function之外,那么这个entity是在整个package内可见的.
- 如果定义在function之外,那么变量的第一个字母决定了这个变量是不是在"不同package之间可见":
- 如果变量第一个字母大写,那么再package之间可见,比如fmt的Printf
- 第一字母小写则package之间不可见.为了表示区分,一般package自己的名字都是全 小写的.
- 变量的长度是没有要求的,但是go倾向于你在作用域比较小的变量上面:作用域越小的 变量名字应该越简单.
- 同样的Go的变量命名格式一般是"camel case"的,比如parseRequestLine,但是绝对不会 是parse_request_line
- 需要特别注意的是,如果HTML或者WTO这种首字母大写的拼写,一定会是"共进退":
- 要么全大写: HTMLEscape, escapeHTML
- 要么全小写: htmlEscape
- 单绝不可能不一致: escapeHtml
Declarations
- 声明(declaration)命名了一个program entity,并且确定了它"全部或者部分"的properties
- 主要的声明方式有四种:
- var
- const
- type
- func
- Go语言程序是存储在一个或者多个.go文件里面的,每个问题件都是以package为开头,来 表明当前的文件属于哪个package
- package文件后面是一系列的import
- import之后是package level的type, variable, const,或者function
- 下面是一个.go文件的例子
https://play.golang.org/p/bt033asf7f
// Boiling prints the boiling point of water. package main import "fmt" const boilingF = 212.0 func main() { var f = boilingF var c = (f - 32) * 5 / 9 fmt.Printf("boiling point = %g°F or %g°C\n", f, c) // Output: // boiling point = 212°F or 100°C } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // boiling point = 212°F or 100°C // ////////////////////////////////////////////////////
- 这个例子的要点有:
- 常量boilingF是一个package-level的声明(和main是一个层次),所有package-level 的entity是可以在所有的相同package文件里面可见的
- 变量f和c都是main函数的local变量,local变量的可见域就只有自己的function(或者 仅仅是被定义的一个for)内部了
- 函数声明有如下部分组成:
- name
- a list of parameters
- optional list of results
- function body
- 下面就是一个例子,我们把温度转换的逻辑转移到一个function里面,然后多次调用这
个函数,就可以做到"定义一次,使用多次"
https://play.golang.org/p/uQsRDXGTN8
// Ftoc prints two Fahrenheit-to-Celsius conversions. package main import "fmt" func main() { const freezingF, boilingF = 32.0, 212.0 fmt.Printf("%g°F = %g°C\n", freezingF, fToC(freezingF)) // "32°F = 0°C" fmt.Printf("%g°F = %g°C\n", boilingF, fToC(boilingF)) // "212°F = 100°C" } func fToC(f float64) float64 { return (f - 32) * 5 / 9 } // <===================OUTPUT===================> // 32°F = 0°C // 212°F = 100°C
Variables
- 下面我们来看第一种声明的方法var. var是声明变量的最基本方法,其常规格式如下
var name type = expression
- 其中,'type'和'= expression'都是可以省略的.但不能同时省略!因为:
- 如果type省略了, type可以依靠expression来确定自己的类型
- 如果expression省略了.那么name的initial value就都是zero value(也就是如果是 数字就为0,如果是布尔就为false,string就为"", interface和reference type就为 nil, 如果是数组那么就是成员个数为0的数组)
- 这里多说一句zero-value机制保证了变量"总是"拥有well-defined value of its type
这也就避免了c语言里面的"uninitialized variable"
var s string fmt.Println(s) // ""
- 上面的例子打印出了空字符串(""),而不是错误或者是内存里面的随机值,这是一个非 常好的特性,所以在自己创建的type里面能够保证有一个"有意义的zero value"也是非 常好的习惯
- 一个声明表达式声明多个变量是可行的.甚至一个表达式里面可以赋值不同类型的变量,
当然,这种情况需要通过expression来判断
var i, j, k int // int, int, int var b, f, s = true, 2.3, "four" // bool, float64, string
- 声明所使用的Initializer可以是literal value或者是任意的expression
- 需要注意的是:Package-level变量在main函数之前进行初始化,而local variable则是
程序运行遇到了才进行初始化
Package-level variables are initialized before main begins, and local variables are initialized as their declarations are encountered during function execution.
- 也可以使用函数的返回值来初始化变量,比如
var f, err = os.Open(name) // os.Open returns a file and an error
Short Variable Declarations
- var是最基本的声明方式,而且哪里都可以用.另外go还在"function level"提供了一个
声明变量的方式,叫做short variable declaration. 用来声明local variable,其格
式如下
name := expression
- 注意这种方式要求必须提供expression来初始化变量,所以type就不需要了.前面用到
过的short variable declaration的例子有
anim := gif.GIF{loopCount: nframes} freq := rand.Float64() * 3.0 t := 0.0
- 因为这种声明的方式简洁而灵活,所以local variable就大多使用这种方式来声明啦
- 当然了var在local variable里面也有其多种的用途:
- 声明一个变量其初始值无法有效推导出类型
i := 100 // an int var boiling float64 = 100 // a float64
- 声明一个一开始没有值的变量,过一会才会有"有意义的值"
- 声明一个变量其初始值无法有效推导出类型
- 和var能够声明多个变量一样, short variable declaration也可以声明多个变量比
如:
i, j := 0, 1
- 需要注意的是,使用short variable declaration一次声明多个变量只有在"能够提高 readability的时候"才使用.比如for loop里面
- 需要注意的是:=是声明,而=是赋值. multi-variable 声明不能和tuple assignment
相混淆,如下是tuple assignment
i, j = j, i // swap values of i and j
- short variable declaration 一个重要的却容易被忽视的特性:它并不要求":="左边
的多个变量,全部都是没声明过的.
A short variable declaration does NOT necessarily declare all the variable on its left-hand side
- 也就是说如果short variable declaration的左边的"其中一部分变量"已经声明过了,
那么shaort variable declaration自动转成对其进行"赋值":
- 注意一定是"一部分变量",比如下面例子中err在第二次的short variable声明中其
实已经被第一次short variable声明中"声明"过了.所以第二次其实是赋值.而short
variable的这种"赋值"只会对"定义在同一层次"的变量有效.如果是声明在outer block
的,那么外面的声明就直接被忽略掉了
in, err := os.Open(infile) // ... out, err := os.Create(outfile)
- 注意,如果全部都声明过了,是会报错的
f, err := os.Open(infile) // ... f, err := os.Create(outfile) // compile error: no new variables
- 注意一定是"一部分变量",比如下面例子中err在第二次的short variable声明中其
实已经被第一次short variable声明中"声明"过了.所以第二次其实是赋值.而short
variable的这种"赋值"只会对"定义在同一层次"的变量有效.如果是声明在outer block
的,那么外面的声明就直接被忽略掉了
Pointers
- 在计算机看来:变量就是一片存储着value的storage
- 大部分的variable是通过一个name比如'x'来identified的,但是也有通过expression 来识别的,比如x[i]或者是x.f
- 无论是name还是expression,它们都会自动读取value的值,除非它出现在赋值符号的 左边,这种情况下,这个vairable会有一个新的值!
- 所谓的pointer value(注意有value),其实就是variable的地址.也就是说是"存储一 个value的storage的地址"
- 不是每个value都有地址(比如0值),但是每个variable都肯定有地址
Not every value has an address, but every variable does.
- 使用pointer的一大意义在于:我们可以读取甚至更新varaible的值,但是同时甚至不 需要知道这varaible的name(如果它有name的话)!
- 如果使用var x int来定义一个variable的话,那么:
- &就是"c++中的取地址符", &x这个操作会产生一个类型为*int的value,而这个value如果有 name的话,比如p.那么我们就说"p contains the address of x"
- *就是"c++中的解引用(我们这里就没有引用的概念了,所以不能这么叫)", *p这个 操作就会产生类型为int的variable!注意,这里*p产生的不是一个值,而是一个variable! 所以它可以出现在赋值符号的左边
- 下面是一个pointer的例子, 表达了pointer在go里面的能力.
x := 1 p := &x // p, of type *int, points to x fmt.Println(*p) // "1" *p = 2 // equivalent to x = 2 left side of assignment fmt.Println(x) // "2"
- pointer的zero value是nil, 使用p != nil来确定p是否指向一个variable.两个
pointer相等的情况只有两种:都等于零,或者都指向同一个变量
var x, y in fmt.Println(&x == &x, &x == &y, &x == nil) // "true false false"
- 和c语言不同的地方是, 在go里面"函数返回一个指向local variable的地址"是非常
安全的(因为go是GC的语言),比如下面的例子. 注意,我们每次返回的地址都不一样.
https://play.golang.org/p/IMesLxqyWk
package main import "fmt" var p = f() func f() *int { v := 1 return &v } func main() { fmt.Println(p) fmt.Println(f() == f()) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 0x82024e220 // // false // ////////////////////////////////////////////////////
- "返回function的local variable的地址"这种方法极大的提高了生存率,我们知道在 c语言里面,如果想返回稍微复杂的数据(int类型可以放在寄存器里面返回),那么就需 要声明一个static的存储结构,然后返回这个存储结构的地址.这又引入了另外一个问题: 由于使用了static存储,程序就无法做成reentrant的了
- 由于pointer包含了variable的地址,所以把pointer传递给函数就可以更新pointer指
向的变量的值.这和c语言里面的用法是一样的:
函数值传递的情况下,使用指针作为参数来更改"指针指向的变量" - 每次我们对一个变量做"取地址"操作,或者我们copy一个pointer(也就有了一个新的
name),我们都会对某个variable创建一个新的alias,比如*p就是v的一个alias
v := 1 p := &v // p, of type *int, points to x
- alias允许我们在不使用variable name的情况下进行对variable的使用,但是代价就 是GC的时候,我们可能要找到所有的alias,而copy一个pionter会出现在非常多的地方: 一个极端的例子就是copy reference type(slice, map, channel等)的时候,reference type内部所有的成员都是pointer,都会创建一个alias!
- "返回function的local variable的地址,这种c语言里面无法使用,但是go里面却可以
的feature"被std里面的flag库应用,轻松实现了分析一个command line参数,然后返
回指向参数值的"pointer".源代码如下
// Bool defines a bool flag with specified name, default value, and usage string. // The return value is the address of a bool variable that stores the value of the flag. func (f *FlagSet) Bool(name string, value bool, usage string) *bool { p := new(bool) // equals to var x bool first, then &x f.BoolVar(p, name, value, usage) return p } // Bool defines a bool flag with specified name, default value, and usage string. // The return value is the address of a bool variable that stores the value of the flag. func Bool(name string, value bool, usage string) *bool { return CommandLine.Bool(name, value, usage) }
- 使用flag的一个例子如下
https://play.golang.org/p/TGDginIe_B
// Copyright © 2016 Alan A. A. Donovan & Brian W. Kernighan. // License: https://creativecommons.org/licenses/by-nc-sa/4.0/ // See page 33. //!+ // Echo4 prints its command-line arguments. package main import ( "flag" "fmt" "strings" ) var n = flag.Bool("n", false, "omit trailing newline") var sep = flag.String("s", " ", "separator") func main() { flag.Parse() fmt.Print(strings.Join(flag.Args(), *sep)) if !*n { fmt.Println() } } //!- //////////////////////////////////////////////////////////////////// // <===================OUTPUT===================> // // i309511@ echo4 (master) $ go run main.go -s="," Hello World // // Hello,World // // i309511@ echo4 (master) $ go run main.go -n -s="," Hello World // // Hello,Worldi309511@ echo4 (master) $ // ////////////////////////////////////////////////////////////////////
The new Function
- 另外一种创建variable的方法是使用内置的new function.因为expression new(T)会
创建一个unnamed variable of type T, 初始化为zero值,并且返回其地址*T,所以这
种创建方法是和指针密切联系的!
The expression new(T) creates an unnamed variable of type T, initializes it to the zero value of T, and returns its address, which is a value of type *T
- 例子如下
https://play.golang.org/p/LX-aOM5T9s
package main import "fmt" func main() { p := new(int) fmt.Println(p) fmt.Println(*p) *p = 2 fmt.Println(p) fmt.Println(*p) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 0x82024e220 // // 0 // // 0x82024e220 // // 2 // ////////////////////////////////////////////////////
- new创建变量和我们使用var等方法创建的变量没有本质的不同,只不过现在我们不需
要给变量取名字了!所以,下面的两个例子其实是等价的.只不过第二个例子写起来就
有点复杂:
- use new function:
func newInt() *int { return new(int) }
- use dummy variable
func newInt() *int { var dummy int return &dummy }
- use new function:
- 每次new"大多数情况下"都会返回一个unique的address
p := new(int) q := new(int) fmt.Println(p == q) // "false"
- 但是"根据具体implementation", 有些时候也会返回相同的地址,这些情况,通常是一
个类型没有任何的信息,其size为0. 比如struct{}, int
https://play.golang.org/p/pD6Vr98zdt
package main import "fmt" func main() { fmt.Printf("%d\n", new(int)) fmt.Printf("%d\n", new(int)) fmt.Printf("%d\n", new([0]int)) fmt.Printf("%d\n", new([0]int)) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 34898576208 // // 34898576240 // // &[] // // &[] // ////////////////////////////////////////////////////
- new function虽然存在,但是在实际情况下却很少使用!因为unnamed variable大多数 情况下都是struct type的,而struct type的unnamed variable使用struct literal syntax是最简单的方法吧
- 因为new只是predeclared function,而不是keyword,所以我们是可以redefine new使 用的.当然,这不推荐.
Lifetime of Variables
- 所谓变量的作用域,是值的程序运行的过程中,某个变量存在的"时间段"(interval of time)
- 一个variable根据其类型的不同,有不同的作用域:
- 对于package level variable来说,在程序运行的全部时刻都一直有效
- 对于local variable来说,每当local variable的declaration运行的时候,这个variable 就开始有效,直到其变得unreachable.也就是在这个时候,变量占用的storage可能 会被回收
- function的参赛和返回值都是local variable,每次函数调用都会创建一份(当然调 用完大部分都会被回收)
- GC如何知道一个variable的storage可以被回收?完整的真相肯定不是我们这里可以一
下子说完的.但是总体的思路如下:
- 要判断一个变量x,首先要把它能够接触到的所有的package-level变量和local变量都找到做成数组a
- 然后遍历a中所有的元素,看看从这些元素是不是能够找到一条道路(道路通过pointer或者reference到达变量x)
- 如果没有任何元素能够到达x,说明x是unreachable了
- 所以,go和c最大的不同就在于local variable,go中local variable并不是在 离开作用域后就不可用,而是直到unreachable才不可用.也就是说,我们可以在其作用 域消失后依然存在.
- 是编译器在编译的时候来决定某个变量存放在heap或者stack,从而拥有不同的生命期
的.但是编译器是通过分析程序,而不是通过这个变量使用了var或者new来决定其放置
在heap或者stack的.比如下面两个例子:
- 虽然x看起来是个局部变量,但是因为它一被global所"reach",即便func f退出,这个
x还是要reachable,所以编译器要把它分配在heap上面.而这种情况下,我们称x"esacpe
from f"
var global *int func f() { var x int x = 1 global = &x }
- 下面这个例子,虽然y是一new上面分配的一个地址,但是因为它并没有escape from g,
所以把g分配在stack上面也是很安全的
func g() { y := new(int) *y = 1 }
- 虽然x看起来是个局部变量,但是因为它一被global所"reach",即便func f退出,这个
x还是要reachable,所以编译器要把它分配在heap上面.而这种情况下,我们称x"esacpe
from f"
- 总之,虽然变量是否"escape"其function不需要我们关系,但是了解原理是非常重要的, 这会让我们写出更高效的代码,比如了解了上面的机制,我们就知道:最好不要使用"存 在于long-lived(比如全局变量) object(比如slice)里面的pointer"来指向short-lived 对象(比如函数里面的对象),因为这会阻止GC来回收这些short-lived 对象
Assignments
- 了解了variable和value的关系以后,我们来看看variable是怎样来更新其内部的value的
- 更新有如下常用几种方式: go中的assignment和c中的assignment没有什么区别:
- 使用"="赋值
x = 1 // named variable *p = true // indirect variable person.name = "bob" // struct field count[x] = count[x] * scale // array or slice or map element
- 每一种binary operator 都有对应的assignment operator,比如上面最后一个例子
使用assignment operator改写就是如下效果
count[x] *= scale
- 支持自增,自减
v := 1 v++ // v becomes 2 v-- // v becomes 1 again
- 使用"="赋值
Tuple Assignment
- go中新引入的一种assignment叫做tuple assignment,其核心是多个变量"同时"赋值:
right-hand的expression先做evaluation,然后才assign给左边的值.由于evaluation
和assignment分开了,所以特别适合变量同时出现在assignment 操作符左右两边的情
况,简言之就是swap
- 赋值数为两个的时候,可以用来swap两个变量的值
https://play.golang.org/p/hq0aoRwZLK
package main import "fmt" func main() { x := 1 y := 2 fmt.Println(x, y) x, y = y, x fmt.Println(x, y) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 1 2 // // 2 1 // ////////////////////////////////////////////////////
- 赋值数多于三个的时候,也是可以使用的,如下,但是为了让程序更加易懂,尽量少使
用为妙
i, j, k = 2, 3, 5
- 赋值数为两个的时候,可以用来swap两个变量的值
https://play.golang.org/p/hq0aoRwZLK
- 赋值为两个的时候,还有如下几种常见的用法,一共有四种:
- 我们前面说过变量"声明"的时候讲过short variable declaration可以允许用函数
返回值来"声明一个或者两个未声明的变量", 但如果两个变量都已经声明过了的情
况下,我们就只能使用tuple assignment了
package main import ( "fmt" "os" ) func main() { f, err := os.Open("foo.txt") fmt.Println(f) fmt.Println(err) //! ERROR no new variables on left side of := // f, err := os.Open("foo.txt") f, err = os.Open("foo.txt") }
- map是两个值么,key和value,所以map lookup是会用到tuple assignment
https://play.golang.org/p/Y11HZi_GFU
package main import "fmt" func main() { m := make(map[int]string) m[1] = "One" m[2] = "Two" var v string var ok bool v, ok = m[2] fmt.Println(v, ok) }
- type assertion: go特有的,对inteface的assertion
https://play.golang.org/p/EFkIAHjIwh
package main import ( "fmt" ) func main() { var x interface{} x = "abc" var v string var k bool v, k = x.(string) if k { fmt.Println(v, k) } else { fmt.Println("first x is Not a String") } x = 12 v, k = x.(string) if k { fmt.Println(v, k) } else { fmt.Println("second x is Not a String") } } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // abc true // // second x is Not a String // ////////////////////////////////////////////////////
- channel receive
v, ok = <-ch // channel receive
- 我们前面说过变量"声明"的时候讲过short variable declaration可以允许用函数
返回值来"声明一个或者两个未声明的变量", 但如果两个变量都已经声明过了的情
况下,我们就只能使用tuple assignment了
- 当然了,如果我们赋的值并不是都有receiver的话,我们可以把我们不想要的reciver 写作blank identifier(_),这个和声明是一样的
Assignability
- 有"="的情况下是explicit assignment, 但是还有很多情况下发生了assignment,但
是因为没有"=",所以是implicit assignment,比如:
- function call的时候,实参是都是通过assignment来传递给形参的
- function call的 return value也是assignment给接收function结果的变量
- go特有的literal expression(也就是我们前面说的unnamed variable最舒服的创
建方式),这里的例子是slice,但是其实map和channel也是一样的
medals := []string{"gold", "sliver", "bronze"} // equals to medals[0] = "gold" medals[1] = "sliver" medals[2] = "bronze"
- 无论赋值是explicit还是implicit,必须遵守赋值的最基本要求:variable(left side) 和value (right side)拥有一样的type.
- 这里"一样的type"是一个宽泛的概念,并不是要求type完全一样,而是说value(right side) is assignable to the variable(left side)的type
- 我们后面会详细解释assignable
- 我们的"=="和"!="和我们的assignablitiy有关:只有first operand和second operand 可以相互assignable的时候,才能使用"=="和"!="
Type Declarations
- 变量(或者exporession)的type定义了其在语言里面的非常多的特性,比如:
- 他们的size(bit数目)
- 程序语言内部表达方式
- 哪些语言intrinsic operation可以操作它们
- 它们"自带"了哪些method
- 在程序里面,会经常会出现两个事物"表现形式"完全一样(完全可以使用同一种type表 示),但是concept却并不完全一样.比如float64即可以代表, 速度(几点几秒),也可以 代表温度(几点几度)
- Go给这种情况一个解决方案就是type declaration,它可以把一个underlying-type定
义成一种新的named的类型
type new-named-type underlying-type
- 我们来看看下面这个例子,华氏温度和摄氏温度是"温度"的两种不同的表达方式,其实
都可以使用float64表示但是我们定义成不同的type
// Package tempconv performs Celsius and Fahrenheit conversions. package tempconv import "fmt" type Celsius float64 type Fahrenheit float64 const ( AbsoluteZeroC Celsius = -273.15 FreezingC Celsius = 0 BoilingC Celsius = 100 ) func (c Celsius) String() string { return fmt.Sprintf("%g°C", c) } func (f Fahrenheit) String() string { return fmt.Sprintf("%g°F", f) }
- 定义成不同type的好处,是当两者进行运算的时候,因为类型不同,我们必须先"convert",
这会减少很多错误.这种错误在underlying type为float64的时候不是很明显,但是如果
underlying type是复杂的struct的话,我们会减少非常多的错误.
package tempconv // CToF converts a Celsius temperature to Fahrenheit. func CToF(c Celsius) Fahrenheit { return Fahrenheit(c*9/5 + 32) } // FToC converts a Fahrenheit temperature to Celsius. func FToC(f Fahrenheit) Celsius { return Celsius((f - 32) * 5 / 9) }
- 上面使用T(x)的方法作用是:
convert value x to type T.
- 这种转换在c-like语言里面也存在,但是在go里面,这种转换的要求非常的严格,允许转
换的情况不多:
- 如果x当前的类型和类型T拥有相同的underlying type(也就是我们这个例子里面的 情况,华氏和摄氏问题都是float64类型)
- 如果两种类型都是unnamed pointer,并且指向的变量类型相同
- 高精度的数值转换成低精度的数值(会损失精度, 比如float转换成int就会损失所有 的小数部分)
- string转换成[]byte
https://play.golang.org/p/cGitbsVI6d
package main import ( "fmt" "os" ) func main() { s := "ABCDE" arr := []byte(s) fmt.Println(s) fmt.Printf("%v\n", arr) fmt.Println(string(arr)) os.Exit(0) } // <===================OUTPUT===================> // ABCDE // [65 66 67 68 69] // ABCDE
- 最最重要的是无论怎样的情况下,在运行期,转换绝对不会失败.注意是"运行期"不会失
败,也就是说你必须首先满足go conversion的要求.
In any case, a conversion never fails at run time.
- named type的underlying type决定了它能接受哪些intrinsic operation,比如摄氏和
华氏本质上是float64.所以所有对float64起作用的intrinsic operation都可以对摄氏
华氏起作用
https://play.golang.org/p/ZjSJcqEEJC
package main import ( "fmt" "os" ) type Cel float64 type Fah float64 func main() { var c Cel = 99.5 var f Fah = 500.7 fmt.Printf("%v\n", c) fmt.Printf("%g\n", f) ////////////////////////////////////////////////////////////////////// // //invalid operation: c - f (mismatched types Cel and Fah) // // fmt.Printf("%g\n", c-f) // ////////////////////////////////////////////////////////////////////// os.Exit(0) } // <===================OUTPUT===================> // 99.5 // 500.7
- 相同的named type之间,或者named type和自己的underlying type之间是可以使用
comparision operator的(比如==, <),不同的named type之间连加减都不可以,更不要
说比较了.
https://play.golang.org/p/Yte0wz8VLm
package main import ( "fmt" "os" ) type Cel float64 type Fah float64 func main() { var c Cel var f Fah fmt.Println(c == 0) fmt.Println(f >= 0) fmt.Println(c == Cel(f)) ///////////////////////////////////////////////////////////////////// // invalid operation: c == f (mismatched types Cel and Fah) // // fmt.Println(c == f) // ///////////////////////////////////////////////////////////////////// os.Exit(0) } // <===================OUTPUT===================> // true // true // true
- 而 named type的method就不是underlying type能够决定的了.换句话说,method是定
义在named type上的,而不是定义在underlying type的
- 比如,我们可以定义String(), 会被打印函数调用.
func (c Celsius) String() string { return fmt.Sprintf("%g°C", c) }
- 调用结果如下,但是其他的underlying type为float的类型并不会享受到这个method
package main import "fmt" import "github.com/harrifeng/gopl.io/ch2/tempconv0" func main() { var c tempconv.Celsius fmt.Println(c) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 0°C // ////////////////////////////////////////////////////
- 比如,我们可以定义String(), 会被打印函数调用.
- 使用named type当然有一个最明显的优势,就是可以把复杂的类型,使用type改成简单 的名字,会减少书写复杂度.当然了,原来的名字越复杂就能获得更大的简化
Packages and Files
- 和其他语言一样,package在go里面起到了模块化,封装,分离编译还有重用等功能
- 队友某个package的代码来说,它们会存在于一个或者多个.go文件里面,而且这一个或 者多个文件一般会放在文件x/y/z/{package-name}下面,其中最后一层一般是package的 名字,比如我们最常用的package fmt存放在src/fmt文件夹下
- 每个package其实都提供了一个namespace,比如image package和unicode/utf16两个package
里面都有identifier Decode,如果要区分,我们就要分别写成:
- image.Decode
- utf16.Decode
- package还可以来控制哪些name是可以在package外面被看到的(在外面被看到叫做exported) 在Go里面,export的原则很简单.首字母大写的会被exported
- 下面我们来看一个package例子,比如我们想把我们的华氏摄氏问题开源:
- 首先我们定义我们的package名字为tempconv,所以我们创建如下的文件夹
mkdir -p src/gopl.io/ch2/tempconv
- 我们建立第一个文件,主要放了我们的type, constant,还有为这个type创建的method
// file path: src/gopl.io/ch2/tempconv/tempconv.go // Package tempconv performs Celsius and Fahrenheit conversions. package tempconv import "fmt" type Celsius float64 type Fahrenheit float64 const ( AbsoluteZeroC Celsius = -273.15 FreezingC Celsius = 0 BoilingC Celsius = 100 ) func (c Celsius) String() string { return fmt.Sprintf("%g°C", c) } func (f Fahrenheit) String() string { return fmt.Sprintf("%g°F", f) }
- 然后我们把另一块逻辑:两种type 转换的例子放到package文件夹下面的另外一个文
件
// file path: src/gopl.io/ch2/tempconv/conv.go package tempconv // CToF converts a Celsius temperature to Fahrenheit. func CToF(c Celsius) Fahrenheit { return Fahrenheit(c*9/5 + 32) } // FToC converts a Fahrenheit temperature to Celsius. func FToC(f Fahrenheit) Celsius { return Celsius((f - 32) * 5 / 9) }
- 在package上面会有一段comment(这个叫doc comment),比如这个package的doc就如下.
一般只有一个package 文件里面会有这个doc comment
// Package tempconv performs Celsius and Fahrenheit conversions.
- 首先我们定义我们的package名字为tempconv,所以我们创建如下的文件夹
Imports
- 有了package,那么就得有导入package的方法.go里面,导入package的方法是使用import
- import后面跟的是我们"确定了导入工具后(一般是git)", 使用这个工具下载的代码, 比如gopl.io/ch2/tempcov
- 我们当然不会使用"gopl.io/ch2/tempcov"这么长的名字,一般来说就是最后一节名字 这里是tempcov
- 下面就是import我们tempcov的例子
https://play.golang.org/p/z6rRJlVlBL
// Cf converts its numeric argument to Celsius and Fahrenheit. package main import ( "fmt" "os" "strconv" "gopl.io/ch2/tempconv" ) func main() { arr := []string{"32", "212"} for _, arg := range arr { t, err := strconv.ParseFloat(arg, 64) if err != nil { fmt.Fprintf(os.Stderr, "cf: %v\n", err) os.Exit(1) } f := tempconv.Fahrenheit(t) c := tempconv.Celsius(t) fmt.Printf("%s = %s, %s = %s\n", f, tempconv.FToC(f), c, tempconv.CToF(c)) } } // <===================OUTPUT===================> // 32°F = 0°C, 32°C = 89.6°F // 212°F = 100°C, 212°C = 413.6°F
- import了但没有使用的话,会被认为是error type(error就是一个type, err才是变量 名字!),这是为了减少不必要的依赖,当然这也会引入问题,因为有时候你comment了一 行代码,因为只有一处用到这个package,这个package就被删除了.我们推荐的方法是使 用goimports来自动加入import
Package Initialization
- package 的initializtion的第一步是initialize package-level的variable,其顺序一
般是按照variable的定义的顺序,除非先定义的variable依赖了后定义的variable,比
如下面的a依赖b,c, 而b依赖c(在函数里面), 所以package-level的variable只有让c
先初始化
var a = b + c // a initialized third, to 3 var b = f() // b initialized second, to 2, by calling f var c = 1 // c initialized first, to 1, func f() int { return c + 1 }
- 如果一个package有多个文件的话,是安装字母顺序的先后进行初始化的(go tool会发 送文件给编译器前,进行这个排序)
- package level的变量其初始化值就是其初始化expression里面赋予的.但是有些时候
initializer expression不是最好的初始化方式,这种情况下init function就被引入
了.
func init() { /* ... */ }
- init function和其他function一样,唯二的区别就是一不能被call,二不能被refer
- 每个文件里面都可以含有多个init()函数
- 每个文件里面的init()函数都会在程序运行的之后,自动运行.顺序和声明的顺序相同
- 前面讲述的是单个package初始化的顺序.如果我们import了多个package,那么就安装 import的顺序来初始化.当然了,如果这些package之间有dependency关系,那么要先初 始化被依赖的.这样才能保证某个package开始初始化的时候,前提条件都已经具备了
- main package是最后初始化的.换句话说,当main function开始的时候,所有的import 的package都已经初始化好了
- 下面就是一个使用init()函数的例子:计算某个64bit无符号书里面bit的个数,我们这
里使用了一个技巧:
- 64bit个数字就是2**64个数,我们把它分成8个2**8个部分,
- 我们在init()函数里面把第一个2**8数组里面每个序列含有的bit个数计算出来,我 们可以把这个pc数组想成是一个简单的map
- 输入一个数,我们就把它依次向右移动8位,然后是有byte()强制转换成8bit的数字, 然后就可以去map pc里面找到对应的数字
- 代码如下:注意for i, _ := range pc可以简单写作for i := range pc(例子里面的
写法)
https://play.golang.org/p/0md9KLYnVy
package main import ( "fmt" "os" ) var pc [256]byte // 2**8 elements func init() { for i := range pc { pc[i] = pc[i/2] + byte(i&1) } } func PopCount(x uint64) int { return int(pc[byte(x>>(0*8))] + pc[byte(x>>(1*8))] + pc[byte(x>>(2*8))] + pc[byte(x>>(3*8))] + pc[byte(x>>(4*8))] + pc[byte(x>>(5*8))] + pc[byte(x>>(6*8))] + pc[byte(x>>(7*8))]) } func main() { fmt.Println(PopCount(0xFFFF)) fmt.Println(PopCount(0xFFF0)) fmt.Println(PopCount(0xFF00)) fmt.Println(PopCount(0xF000)) os.Exit(0) } // <===================OUTPUT===================> // 16 // 12 // 8 // 4
Scope
- scope是一种通过program text就可以分析到的,也就是是一种compile-time 属性
- 而lifetime和scope是不同的概念.lifetime是一个run-time的属性,必须在运行时进行 判断
- syntactic block是一个{}, 在syntactic block里面定义的变量在外面是看不到的.
- 如果declaration没有在一个明显的{}里面的话,有几种情况:
- declaration定义在了universe block (block for entire source code)
- declaration定义在了package
- declaration定义在了for
- declaration定义在了if
- declaration定义在了switch statement
- 一个程序可以多次declare一个name,只要每次declare都在一个不同的lexical block, 比如你可以定义一个local variable和package-level拥有同样的名字
- 当编译器遇到一个名字的时候,它会从最近的block(innermost enclosing lexical block)里面开始寻找,知道universe block
- 如果编译器在这个过程中没有找到哪怕一个declaration,它会报告"undeclared name" error
- 如果编译器在这个过程中遇到了第一个declaration,它就不会继续寻找了.换句话说,
如果一个name同时声明在inner block和outer block,那么inner declaration会shadow
(hide) outer declaration
https://play.golang.org/p/U3fWcnuXCE
package main import "fmt" func f() {} var g = "g" func main() { f := "f" fmt.Println(f) fmt.Println(g) //////////////////////////// // // undefined: h // // fmt.Println(h) // //////////////////////////// } // <===================OUTPUT===================> // f // g
- 在一个function里面,lexical block会嵌套任意多层,所以两个local declartion也会 shadow另外的local declaration
- 大多数的function内部的block都是通过if和for 创建的!下面是一个反面例子,x这个
name被declare了三次
https://play.golang.org/p/1qyLFZzXho
package main import "fmt" func main() { x := "hello!" // one for i := 0; i < len(x); i++ { x := x[i] // two if x != '!' { x := x + 'A' - 'a' // three fmt.Printf("%c", x) } } } // <===================OUTPUT===================> // HELLO
- block和其scope并不一定完全一致,比如,for loop会创建两个lexical block:
- explicit block: block全体loop body, 这个block的scope也是loop body
- implicit block: block全体就是for开始,到'第一个分号'结束的这个语句. 但是这
个block的scope却比block大,包括了:
- condition阶段: i < len(x)
- post-state阶段: i++
- for body全体
- 和for一样,if statement也会创建implicit block.如下
if x := f(); x == 0 { fmt.Println(x) } else if y := g(x); x == y { fmt.Println(x, y) } else { fmt.Println(x, y) } // compile error: x and y are not visible here fmt.Println(x, y)
- 第二个个if和第一个if是相互nested的,所以第一个if里面定义的vairable也会在第二 个if里面被看到.switch statement也遵循这个准则
- 在package level, 声明出现的顺序不重要(因为依赖关系编译器会去处理的),所以一 个声明可以引用它后面出现的声明,或者引用它自己,所以我们是可以在package level 声明recursive的function的.但是变量和const是不能recursive的,所以如果变量或 常量的声明指向了自己,编译器会报错的
- 下面的例子中, f的scope只有if statement,所以if后面的语句再调用f就会报错f没有
定义.当然了编译器还会报错就是f没有使用
if f, err := os.Open(fname); err != nil { // compile error: unused: f return err } f.ReadByte() // compile error: undefined f f.Close() // compile error: undefined f
- 所以一般改动的方法是在condition之前就声明f
f, err := os.Open(fname) if err != nil { return err } f.ReadByte() f.Close()
- short variable declaration需要格外的注意scope的问题,因为short variable
declaration有如下两个特点:
- 没有var关键字,看起来是赋值,其实是声明,只有其中某一个变量在"当前scope"声明 过才会转换为赋值
- 声明的是局部变量
- 下面的这个例子本来的意愿是"把当前的路径存储到cwd里面",但是因为":="其实是声明
所以其实在init()函数里面又创建了一个cwd的局部变量,shadow了全局变量cwd
var cwd string func init() { cwd, err := os.Getwd*() // compile error: unused: cwd if err != nil { log.Fatalf("os.Getwd failed: %v", err) } }
- 所以上面程序的结果是编译器报错,cwd没有被使用
- 一个最错误的修改方法就是简单的"使用一下"局部变量cwd,这样虽然能够运行了,在编
译上没有错误了,但是在逻辑上是错误的!
var cwd string func init() { cwd, err := os.Getwd*() // compile error: unused: cwd if err != nil { log.Fatalf("os.Getwd failed: %v", err) } log.Printf("Working directory = %s", cwd) }
- 正确的改法则是放弃使用":=",而使用真正的assignment "=",当然了要先使用var来声
明err(error是类型,err是变量),因为赋值符号要求左边的操作数都是已经声明过的
var cwd string func init() { var err error cwd, err = os.Getwd() if err != nil { log.Fataf("os.Getwd failed: %v", err) } }
Chapter 03: Basic Data Types
- Go的type主要分成四个大的类别:
- Basic type: 包括number, string, boolean
- Aggregate type: 包括array,struct, 他们共同的特点是把多个不同的value结合在 一起
- Refference type: 包括pointer, slice, map, function, channel.他们的特点是间 接的"包含"variable
- Interface type
Integers
- Go的number是按照其长度(bit数)和是否有符号,分成了,如下的多个类型
int8, 1int16, int32, int64, uint8, uint16, uint32, uint64
- 而最最常用的类型是int和unit,他们对应int32"或者"int64, 这是根据平台不同而不同 的,所以不要assume int的size
- rune也是一种int32的同义词,但是使用rune了以后,就标示了这个variable其实就是一 个Unicode.
- 同样的, byte也是uint8的同义词,但是使用了byte以后,就说明这个变量是raw data而 不是small numeric quantity
- uintptr是一个width没有定义的类型,但是可以用来存储"全部类型的pointer", uintptr 类型主要是为了low-level编程,比如和C library相关的操作
- 即便是size一样, int和int32也不能相互直接转换,而是需要explicit conversion.我 们可以把int和int32(或者64!)想象成underlying type一致,但是type不一样的两个类 型相互之间肯定是需要显式的转换的.
- Go里面的有符号数是通过two's complement form(二补数)的方法来存储:high-order bit
要存储符号,所以n-bit number的取值区间是(-2)**(n-1)到(2)**(n-1)-1.比如int8的
取值区间就是-128到127.二补数的方法负数采取"首位为1表示负数,除此之外取反加一
获得真正数值"的办法来表达负数,我们来看一个例子
Hex highest sign + number one's complement two's complement +7 0111 Same with left Same with left +6 0110 Same with left Same with left +5 0101 Same with left Same with left +4 0100 Same with left Same with left +3 0011 Same with left Same with left +2 0010 Same with left Same with left +1 0001 Same with left Same with left +0 0000 Same with left Same with left -0 0000 1111 0000 for both -0 and +0 -1 1001 1110 1111 -2 1010 1101 1110 -3 1011 1100 1101 -4 1100 1011 1100 -5 1101 1010 1011 -6 110 1001 1010 -7 1111 1000 1001 -8 overflow for 4bit overflow for 4bit 1000 - 由于two's complement复杂的表达方式,我们写个例子来进行理解
https://play.golang.org/p/TBSF8sxEkZ
package main import "fmt" func GetTwoComplement(num int8) string { var ret = []byte("00000000") for i := range ret { if ((1 << uint(i)) & uint(num)) > 0 { ret[i] = '1' } } beg := 0 end := len(ret) - 1 for beg <= end { ret[beg], ret[end] = ret[end], ret[beg] beg++ end-- } return string(ret) } func main() { for i := 0; i < 8; i++ { fmt.Printf("Hex: %d \t\tTwo's complement %s\n", i, GetTwoComplement(int8(i))) } for i := -121; i >= -128; i-- { fmt.Printf("Hex: %d \t\tTwo's complement %s\n", i, GetTwoComplement(int8(i))) } } // <===================OUTPUT===================> // Hex: 0 Two's complement 00000000 // Hex: 1 Two's complement 00000001 // Hex: 2 Two's complement 00000010 // Hex: 3 Two's complement 00000011 // Hex: 4 Two's complement 00000100 // Hex: 5 Two's complement 00000101 // Hex: 6 Two's complement 00000110 // Hex: 7 Two's complement 00000111 // Hex: -121 Two's complement 10000111 // Hex: -122 Two's complement 10000110 // Hex: -123 Two's complement 10000101 // Hex: -124 Two's complement 10000100 // Hex: -125 Two's complement 10000011 // Hex: -126 Two's complement 10000010 // Hex: -127 Two's complement 10000001 // Hex: -128 Two's complement 10000000
- 无符号数就不需要存储符号了,所以range全是正数,比如uint8的range就是0到255
- 所有basic type内部,都是可以使用==或者!=来进行比较大小
- Go的二元操作符的有如下五个level的优先级顺序(同一级别的,左边的操作符优先级高),
这五个级别如下
* / % << >> & &^ ___________________ + - | ^ ___________________ == != < <== > >= ___________________ && ___________________ ||
- 这五行里面的前面两行都可以有对应的assignment operator:比如'+'其对应的assignment operator是'+='
- 常见的+,-,*,/可以对所有的number(包括integer, float, complex number)进行操作
- 但是%符号只能用到integer上面
- 而且%符号的"负数操作"是众所周知的麻烦,因为每个语言的处理都不太一样,在Go语言
里面,%操作的结果的符号"永远和被除数(dividend)的符号相同"
https://play.golang.org/p/cQcxbAI09p
package main import "fmt" func main() { fmt.Println(-5 % 3) fmt.Println(-5 % 3) } // <===================OUTPUT===================> // -2 // -2
- /操作符的行为是和其操作数(operand)相关的,只有'/操作符'的两个操作数全部是整数
其操作结果才会是整数(去掉小数部分)
package main import "fmt" func main() { fmt.Println(5 / 4) fmt.Println(5.0 / 4) fmt.Println(5 / 4.0) fmt.Println(5.0 / 4.0) } // <===================OUTPUT===================> // 1 // 1.25 // 1.25 // 1.25
- 如果算术运算的结果所拥有的bit数"大于"它type所能拥有的bit数值,我们就说出现了
overflow.overflow的结果就是把最high-order的bit给丢弃掉了,所以"带符号数"由于
最high-order的一个bit是表示符号的,所以其结果可能是负数(即便两个正数操作的情
况下)
https://play.golang.org/p/_LScrRQ1oI
package main import "fmt" func main() { var u uint8 = 255 fmt.Println(u, u+1, u*u) var i int8 = 127 fmt.Println(i, i+1, i*1) } // <===================OUTPUT===================> // 255 0 1 // 127 -128 127
- Go里面的二元比较符(binary comparison operator)有下面几种
== equal to != not equal to < less than <= less than or equal to > greater than >= greater than or equal to
- 一个类型是否可以使用比较符号可以推断出这个type的两个特性:
- comparable:就是可以比较性,并不是所有的类型都可以比较,先阶段我们知道的可 比较的类型有所有的基本类型,也就是boolean, number, string.后面我们介绍每 个类型的时候,会介绍这个类型是否可以比较
- ordered:就是可以排序性,这个也是通过比较符号来实现的.在Go语言里面,可以order 的类型是固定的,只有三个:integer, float-point number和string
- 然后还有一元的操作符:
- 一元的加法操作符: + 一般没什么意义, +x就是0+x的缩写
- 一元的减法操作符: - 一般表示负数, -x就是0-x的缩写
- 接下来是二元二进制操作符(bitwise binary operator).
& bitwise AND | bitwise OR ^ bitwise XOR &^ bit clear (AND NOT) ___________________________ << left shift >> right shift
- 前四种是"真的底层"操作,会把它们的操作数(operand)作为bit pattern来对待并不会
认为他们有算术特征:比如进位(carry)和符号(highest order 作为符号).换句话说前
四种操作(我们利用自己写的libray bitutil来写个实验):
- 只是当前bit的操作,结果只会是1或者0,不会对其他bit有影响(没有进位)
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { fmt.Println(bitutil.TwoComplementInt8ToRaw(127 & 127)) // no carry os.Exit(0) } // <===================OUTPUT===================> // 01111111
- 把两个操作数当做raw data,不会考虑补码是使用的one's 还是two'是的complement
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { // -1 's two's complement binary is 11111111 fmt.Println(bitutil.TwoComplementInt8ToRaw(64 | -1)) os.Exit(0) } // <===================OUTPUT===================> // 11111111
- 两个操作数是low-bit对齐,没有对应bit的位,无论进行什么操作,都保持原有数字
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { // -1 's two's complement binary is 11111111 fmt.Println(bitutil.TwoComplementInt8ToRaw(-1 &^ 7)) os.Exit(0) } // <===================OUTPUT===================> // 11111000
- 只是当前bit的操作,结果只会是1或者0,不会对其他bit有影响(没有进位)
- 而shift operation()就是有算术相关性了:
- 'x<<n'表示x乘以 2 ** n
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(5), 5) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(5<<2), 5<<2) os.Exit(0) } // <===================OUTPUT===================> // 00000101 -> 5 // 00010100 -> 20
- 'x>>n'表示x除以 2 ** n
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(5), 5) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(5>>2), 5>>2) os.Exit(0) } // <===================OUTPUT===================> // 00000101 -> 5 // 00000001 -> 1
- ''的算术相关性还体现在:向右移动的时候,如果是负数,则会填充1.其他所有
的情况(包括无符号数的右移,所有数的左移,都是填充零)
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { // minus number '>>' will pad with 1 fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-128), -128) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-128>>6), -128>>6) fmt.Println("----------------------") // All other cases pad with 0 fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(127>>6), 127>>6) fmt.Println("----------------------") fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(1<<6), 1<<6) fmt.Println("----------------------") fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-1), -1) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-1<<6), -1<<6) os.Exit(0) } // <===================OUTPUT===================> // 00000101 -> 5 // 00000001 -> 1
- 当然了还有特殊的情况,有符号数最高一位是符号,假设最高位是1(是0则相反),我们
有没有可能把左边的一个0(或者1)"左移<<"到最高位上呢?答案是否定的,因为这就
溢出了啊!左移就没有这个问题,最后都会到0的
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(127>>6), 127>>6) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(127>>7), 127>>7) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-1<<6), -1<<6) fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-1<<7), -1<<7) /////////////////////////////////////////////////////////////////////////////////// // //constant -256 overflows int8 // // fmt.Printf("%s -> %d\n", bitutil.TwoComplementInt8ToRaw(-1<<8), -1<<8) // /////////////////////////////////////////////////////////////////////////////////// os.Exit(0) } // <===================OUTPUT===================> // 00000001 -> 1 // 00000000 -> 0 // 11000000 -> -64 // 10000000 -> -128
- 'x<<n'表示x乘以 2 ** n
- 在很多算法当中,要使用int作为bit pattern,为了确保行为的可预测性最好使用unsigned 数(因为负数使用的是two's complement表示法)
- 从c语言时代开始,语言就提供了signed和unsigned两种格式的int格式,按理说对于某
些不可能为负数的情况,比如数组的长度,我们可以使用unsigned int.但是我们所有的
例子中还是使用了signed int,甚至内置函数len也返回了signed int.这绝不是巧合,
真正的原因在于
计算机采用了从0开始的计数方式!使用unsigned int会导致i >= 0 一直为true - 比如下面的例子,本来三次循环就可以结束的,但是却报错数组越界
https://play.golang.org/p/AOf53Gzgox
package main import ( "fmt" "os" ) func main() { medals := []string{"gold", "silver", "bronze"} var i uint for i = uint(len(medals) - 1); i >= 0; i-- { fmt.Println(medals[i]) } fmt.Println() os.Exit(0) } // <===================OUTPUT===================> // bronze // silver // gold // panic: runtime error: index out of range
- 因为对于uint32来说0-1并不是-1,而是unit32里面最大的数2**32-1,所以数组访问就 越界了https://play.golang.org/p/HvX4bg8oxl
- 所以,并不是说只要是"不可能为负值"的数就使用unsinged,而是只有个别领域可以使用
unsigned:
- bit相关操作
- hash的key
- 密码学(cryptography)
- Go里面的算术运算(加减乘除)和逻辑运算(与或非,不包括shift)里面的所有的binary
operation肯定是需要两个操作数(operand)啦,go里面要求这两个操作数的type必须完
全一致!implicit conversion是不存在的
https://play.golang.org/p/I1DFXrTshN
package main import ( "fmt" "os" ) func main() { var i int var u uint //////////////////////////////////////////////////////////////////////// // // invalid operation: i & u (mismatched types int and uint) // // fmt.Println(i & u) // //////////////////////////////////////////////////////////////////////// fmt.Println(uint(i) & u) var apples int32 = 1 var oranges int16 = 2 ////////////////////////////////////////////////////////////////////////////////////// // // invalid operation: apples + oranges (mismatched types int32 and int16) // // fmt.Println(apples + oranges) // ////////////////////////////////////////////////////////////////////////////////////// fmt.Println(int(apples) + int(oranges)) os.Exit(0) } // <===================OUTPUT===================> // 0 // 3
- 前面已经说过了conversion operation T(x)有可能会损失精度,比如float 和int之间
两个方向的转换
https://play.golang.org/p/JvNzPMsV9l
package main import ( "fmt" "os" ) func main() { f := 3.14 i := int(f) fmt.Println(f, i) f = 1.99 fmt.Println(int(f)) os.Exit(0) } // <===================OUTPUT===================> // 3.14 3 // 1
- 这种丢失精度的方式还是有迹可循的(就是丢失小数部分),还有一种丢失精度的方式完
全无法预判(implementation-dependent),那就是原始的操作数的值已经"大于了目标
操作数的取值范围"
https://play.golang.org/p/mEcvjMfYGQ
package main import ( "fmt" "os" ) func main() { f := 1e100 fmt.Println(f) fmt.Println(int(f)) // result is implementation-dependent os.Exit(0) } // <===================OUTPUT===================> // 1e+100 // -9223372036854775808
- 所有的integer都可以表示成:
- 八进制:以0开头.用处不大,现在主要是POSIX系统的file system
- 十六进制:以0x或者0X开头.如今还是广泛的应用在各个领域
- 八进制和十六进制的format 打印的字母分别是%o,和%x(%X),如果需要带上前缀(0,0x,0X)
的话,就需要分别使用%#o, %#x(%#X). 下面例子还介绍了一个技巧就是告诉fmt.Printf
反复使用第一个操作数(operand)来打印
https://play.golang.org/p/sBNthgqZPD
package main import ( "fmt" "os" ) func main() { o := 0666 fmt.Printf("%d %[1]o %#[1]o\n", o) x := int64(0xdeadbeef) fmt.Printf("%d %[1]x %#[1]x %#[1]X\n", x) os.Exit(0) } // <===================OUTPUT===================> // 438 666 0666 // 3735928559 deadbeef 0xdeadbeef 0XDEADBEEF
- Rune是能够容纳所有Unicode的字符集,所有被single quote(')包围的单个字符就是rune
类型.format打印字母是%c,如果需要quote就是%q
https://play.golang.org/p/_yTgOmMLKc
package main import ( "fmt" "os" ) func main() { ascii := 'a' unicode := '国' newline := '\n' fmt.Printf("%d %[1]c %[1]q\n", ascii) fmt.Printf("%d %[1]c %[1]q\n", unicode) fmt.Printf("%d %[1]q\n", newline) os.Exit(0) } // <===================OUTPUT===================> // 97 a 'a' // 22269 国 '国' // 10 '\n'
Floating-Point Numbers
- Go提供了两种floating-point number:
- float32:提供了6个decimal digit: 最大值保存在math.MaxFloat32大约是3.4e38
- float64:提供了15个decimal digit: 最大值保存在math.MaxFloat64大约是1.8e308
- float32是非常容易出错的,因为float32的最大表示值不是很大. 所以在绝大多数情况
下,我们应该使用float64
https://play.golang.org/p/HuTXck5Pmn
package main import "fmt" func main() { var f float32 = (1 << 24) fmt.Println(f) fmt.Println(f + 1) fmt.Println(f == f+1) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 1.6777216e+07 // // 1.6777216e+07 // // true // ////////////////////////////////////////////////////
- floating-point number可以使用十进制的初始化方法,比如
const e = 2.171828 - 非常大的数字可以使用scientific notation,也就是e(或者E)来代表以10为底的指数
注意,我们使用%e来故意打印scientific notation
https://play.golang.org/p/lO0452rSAG
package main import "fmt" func main() { fmt.Printf("%e\n", 1200.00) const Avogadro = 6.02214129e23 const Planck = 6.6206957e-34 fmt.Println(Avogadro) fmt.Println(Planck) } // <===================OUTPUT===================> // 1.200000e+03 // 6.02214129e+23 // 6.6206957e-34
- float数字如果整数部分或者小数部分为0,那么可以省略,当然了小数点不能省略.如下
两种都是合格的float数:
- .707
- 1.
- float有三种format打印格式:
- %f:最传统的方式,无论数字有多大都不使用exponent的方式打印
- %e:无论数字大小,都使用exponent的方式打印
- %g:根据数据的大小来动态决定是使用%f,还是%e
- 我们可以使用% +"总数.小数部分"+f的方式来right align(或者left align)的打印float
数字
https://play.golang.org/p/9I5GixyVu6
package main import ( "fmt" "math" ) func main() { fmt.Println("-------Right Align--------------") for x := 0; x < 8; x++ { fmt.Printf("x = %d ex = %8.3f\n", x, math.Exp(float64(x))) } fmt.Println("-------Left Align---------------") for x := 0; x < 8; x++ { fmt.Printf("x = %d ex = %-8.3f\n", x, math.Exp(float64(x))) } } // <===================OUTPUT===================> // -------Right Align-------------- // x = 0 ex = 1.000 // x = 1 ex = 2.718 // x = 2 ex = 7.389 // x = 3 ex = 20.086 // x = 4 ex = 54.598 // x = 5 ex = 148.413 // x = 6 ex = 403.429 // x = 7 ex = 1096.633 // -------Left Align--------------- // x = 0 ex = 1.000 // x = 1 ex = 2.718 // x = 2 ex = 7.389 // x = 3 ex = 20.086 // x = 4 ex = 54.598 // x = 5 ex = 148.413 // x = 6 ex = 403.429 // x = 7 ex = 1096.633
- 除了这些正常的操作,IEEE 754还定义了一些异常的操作, Go也是支持的:
- positive infinity: 正数除以0
- negative infinity: 负数除以0
- NaN(not a Number): 一些不合理的数学操作,比如0/0,还有Sqrt(-1)
- 这三个特殊值的列表如下,值得注意的是竟然还有正零,一个是负零
https://play.golang.org/p/xBUyq6Ib1b
package main import "fmt" func main() { var z float64 fmt.Println(z, -z, 1/z, -1/z, z/z) } // <===================OUTPUT===================> // 0 -0 +Inf -Inf NaN
- 这里的NaN值得再说一说,这个值除了0/0可以创建出来,我们还可以使用math.NaN创建
出来,这个值的特性是,它和谁compare的结果都是false(包括它自己!).所以我们要使用
math.IsNaN来测试某个值是不是NaN
https://play.golang.org/p/L6REIhkxco
package main import ( "fmt" "math" ) func main() { nan := math.NaN() fmt.Println(nan) fmt.Println(math.IsNaN(nan), math.IsNaN(0)) fmt.Println(nan == nan, nan < nan, nan > nan) } // <===================OUTPUT===================> // NaN // true false // false false false
- 如果一个返回float的函数可能失败,那么最好使用另外的err(error是类型,err是变量)
来报告这个错误
func compute() (value float64, ok bool) { // ... if failed { return 0, false } return result, true }
Complex Numbers
- Go提供了两种complex number:
- complex64 (由两个float32组成)
- complex128(由两个float64组成)
- Go提供了一个build-in函数complex()来创建一个complex number, build-in函数real()
用来取得实数部分,imag()取得虚数部分
https://play.golang.org/p/aEoe_ZDOo9
package main import "fmt" func main() { var x complex128 = complex(1, 2) // 1+2i var y complex128 = complex(3, 4) // 3+4i fmt.Println(x * y) fmt.Println(real(x * y)) fmt.Println(imag(x * y)) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // (-5+10i) // // -5 // // 10 // ////////////////////////////////////////////////////
- 如果不需要实数部分,可以直接一个integer或float加上一个i就是一个实数部分为零的
imaginary literal
https://play.golang.org/p/7Je3FikIh2
package main import "fmt" func main() { fmt.Println(1i * 1i) } // <===================OUTPUT===================> // (-1+0i)
- complex const可以是如下三种
- 只有real部分
- 只有imag的部分
- 两者皆有的complex
- 两个complex const可以任意相加,所以我们可以使用如下的加法来方便的初始化complex
number
x := 1 + 2i y := 3 + 4i
- complex number当然可以使用==和=!比较是否相同:只有real部分和imag部分都相同的 两个complex number才是真的相同的
- go有math/cmplx package来提供complex number的帮助函数,比如对-1开分号在普通数
字里面是没有意义的.但是对于complex number就是有意义的
https://play.golang.org/p/odeuDdDTnG
package main import ( "fmt" "math/cmplx" ) func main() { fmt.Println(cmplx.Sqrt(-1)) } // <===================OUTPUT===================> // (0+1i)
Booleans
- Go里面的bool值有两个可能的值true或false(都是小写)
- if和for里面的condition都是boolean值,这和Java是一样的,int值做condition是不可以的
https://play.golang.org/p/uq1zgwB7Kn
package main import "os" func main() { //////////////////////////////////////////////////////////////////// // //non-bool 1 (type untyped number) used as if condition // // if 1 { // // fmt.Println() // // } // //////////////////////////////////////////////////////////////////// os.Exit(0) }
- !是逻辑否,也就是说(!true==false)==true
- 如果x类型为boolean,我们通常不写x==true,而是直接写作x
- boolean值之间可以使用&&(AND)和||(OR)操作,他们都有着短路(short-circuit)的特
性:如果结果已经可以通过第一个操作数(operanad)判断出来了,那么第二个操作数就
不用再去判断了,这种短路特性让我们可以放心的写下如下的表达式
s != "" && s[0] == 'x'
- 因为&&有比||高的优先级(可以通过一些窍门来记忆,比如&&叫做布尔乘法,而||叫做布
尔加法),所以如下的代码其实是可以不需要括号的
if 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z' { // ... }
- 在Go里面是没有boolean和int的implicit conversion的,同样的连T(x)的转换也不行,
所以我们要自己手动写代码来转换
package main import ( "fmt" "os" ) func main() { i := 0 fmt.Println(bool(true)) //////////////////////////////////////////////////////// // // cannot convert i (type int) to type bool // // fmt.Println(bool(i)) // //////////////////////////////////////////////////////// t := true //////////////////////////////////////////////////////// // // cannot convert t (type bool) to type int // // fmt.Println(int(t)) // //////////////////////////////////////////////////////// os.Exit(0) }
Strings
- string是一系列"immutable" byte序列的集合
- 一般来说byte就是uint8, 所以string里面也可以存储0等数字,但是一般来说都是存储 有意义的字符
- string还可以被解释成rune(UTF-8字符)的组合,这是用来存储Unicode的组织方式.后面 我们会看到,Go的这种组织方式非常有效率
- 内置的len()函数用来返回string里面的byte(注意!不是rune)的数目,而s[i]则返回ith
byte.还有类似python的s[i:j]功能. 当然了如果字符串不全是ascii的话
https://play.golang.org/p/pKnjl1YFSG
package main import "fmt" func main() { s := "hello, world" fmt.Println(len(s)) fmt.Println(s[0], s[7]) fmt.Println(s[0:5]) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // 12 // // 104 119 // // hello // ////////////////////////////////////////////////////
- Go也是有类似Java的数组边界检查,所以如下代码会直接报错
c := s[len(s)] // panic: index out of range
- s[i:j]操作会产生一个新的string!范围是前面inclusive,后面exclusive的[i,j)
- 类似于python,前后的index都可以省略
fmt.Println(s[:5]) // hello fmt.Println(s[7:]) // world fmt.Println(s[:]) // hello, world
- "+"可以作用于两个string的连接,也同样和s[i:j]一样,会产生一个新的字符串!
- string可以使用==和<进行比较,而比较是byte by byte进行的,直到分出胜负(不存在
的byte被看做是无穷小)
https://play.golang.org/p/X9pBasATPL
package main import ( "fmt" "os" ) func main() { fmt.Println("abcd" == "abcd") fmt.Println("abce" > "abcd") fmt.Println("abc" > "abcd") os.Exit(0) } // <===================OUTPUT===================> // true // true // false
- string的重大特点是string是immutable的.如下操作是不允许的
s[0] = 'L' // compile error: cannot assign to s[0]
- 而我们类型+=的操作,其实是分配了一块新的string,老的string一直都在
https://play.golang.org/p/X9pBasATPL
package main import ( "fmt" "os" ) func main() { fmt.Println("abcd" == "abcd") fmt.Println("abce" > "abcd") fmt.Println("abc" > "abcd") os.Exit(0) } // <===================OUTPUT===================> // true // true // false
- immutability有很多的好处:
- 内容相同的string copy可以安全的共享一份内存
- substring的操作也是在一个固定的内存里面的操作,所以substring操作也很cheap, 因为不需要分配新的内存
String Literals
- string value最常见的引入方式就是双引号""啦,因为Go对source code默认的encode
方法就是UTF-8,所以我们完全可以在string literal里面就引入UTF-8字符串
var s = "Hello, 世界"
- 双引号里面的string value对待backslash + 字符(\c)是要转义的和c语言一样,常见
的转义符如下
\a "alert" or bell \b backspace \f form feed \n new line \r carriage return \t tab \v vertical tab \\ backslash
- string的每个成员都是一个byte,而byte我们说了,它是通过type byte uint8得来的, 但是其concept不再是无符号8bit的整数,而是"raw data in 8bit"
- 我们的byte含义是"字符", 但是其实还是可以使用整数的表示方式,而且既然我们的byte
不超过8bit,那么我们就可以使用两个十六位数来表示,为了和普通的整数加以区分
我们在前面加一个'\x',叫做hexadecimal escape. 它的范围是
\x00 => \xff (\xFF)
- 同样的,我们我们还可以使用三个八进制数(当然了要浪费一个bit:3*3 - 8 = 1),来
表示叫做octal escape.这个escape有特权,其就是\加数字(因为8进制不会出现字母!)
其range是
\000 => \377
- 任何语言都有不需要escape的raw string literal, Go的表示方法是`<string>`,唯 一不同的是所有在raw string literal里面的'\r'(carriage return)都会被删除 ('\n' new line会被保留),以保证在每个平台上面的表现一致
- raw string literal的特点决定了它可以很方便的用在以下几个方面(一般都有很多
的backslash):
- 正则表达式
- HTML template
- JSON literal
- command 参数所使用的message
const GoUsage = `Go is a tool for managing Go source code. Usage: go command [arguments] `
Unicode
- 最早的时候,计算机字符串就是ASCII的同义词,可以使用7个bit来管理128个"character"
- 为了让英语以外的国家也能享受到计算机字符的处理,诞生了包含非常多字符信息的 字符集:Unicode
- Unicode version 8定义了超过120000个character.需要32bit的存储,也就是int32.
在Go里面,设计了int32的一个同义词rune来处理Unicode.从容量上来看int32还有很
大富裕
https://play.golang.org/p/xsKYTSGnl
package main import ( "fmt" "math" ) func main() { fmt.Println(math.MaxInt32) // Unicode version 8 defines code for over 120,000 characters fmt.Println(120000) fmt.Println(math.MaxInt16) } // <===================OUTPUT===================> // 2147483647 // 120000 // 32767
- 有了Unicode,如果把所有的字符串里面的每个字符都设计成Unicode(rune类型)的话, 一切问题就都解决了.这种情况下,这个字符串叫做UTF-32(或者UCS-4)
- 这种做法简单而粗暴.虽然解决了问题,但是造成了巨大的浪费.因为计算机中最主要 的字符还是ASCII(而ASCII只需要8bit,那么剩下的24bit就白白浪费了)
- 解决这个问题的新技术就是UTF-8
UTF-8
- UTF-8就是为了克服Unicode浪费空间而设计的一种新的编码方式. 其核心就是:
- 对于ASCII 字符使用1byte
- 对于常用的字符串使用2-3byte
- 其他不常用字符串使用4byte
- 具体实现的方法是第一个byte的前几个bit来"告知"系统后面有几个byte是和当前byte
是"一体的"(当前byte的小弟):
- 小弟(非第一个byte)的编码是10xxxxxx
- 大哥(第一个byte)的编码前几位有几个1就是自己有几个"小弟"(包括自己)
- 按照上面的规则,我们可以看出不同的Unicode值对应的UTF-8长度
Runes number UTF-8 bits Notes 0 - 127 0xxxxxxx ASCII 128 - 2047 110xxxxx 10xxxxxx values < 128 unused 2048 - 65535 1110xxxx 10xxxxxx 10xxxxxx values < 2048 unused 65535 - 0x10ffff 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx other values unused - Go的代码总是以UTF-8来进行编码.
- 如果是对于某些单个rune(uint32),Go提供了一个叫做unicode的package来处理一 些比如区别字符还是数字,大小写转换(不仅仅是英语了)等功能
- 而如果是对于UTF-8字符串来说,我们"能够"处理rune的前提是,我们把UTF-8字符串 转换成rune,使用的package是unicode/utf8
- 很多Unicode字符都是无法打印出来的.所以我们需要转义符来打印.这里的转义字符
就叫做Unicode escape,使用\u来转义:
- 对于16-bit value来说就是\uhhhh
- 对于32-bit value来说就是\Uhhhhhhhh(注意U大写)
- 需要注意的是这里的Unicode escape和前面的Hexdecimal Escape以及Octdecimal不 要混淆,不是一回事,但是有联系:一个16bit Unicode escape可以使用两个Hexdecimal (或者 Octdecimal)Esacpe来表示, 32bit Unicode escape就可以使用4个
- 下面就是我们分别使用三种方式来表达同一个Unicode字符串"世界":
- 直接书写
"世界" - hexdecimal escape
"\xe4\xb8\x96\xe7\x95\x8c" - 16-bit Unicode escape
"\u4e16\u754c" - 32-bit Unicode escape
"\U00004e16\U0000754c"
- 直接书写
- 上面的32-bit和16bit的Unicode escape之间的转换是非常容易理解的,我们再来看看
另外两个转换:
- "世界"是两个汉字,其中"世"的unicode值是(通过https://unicode-table.com/en/search/?q=%E4%B8%96查询)
十进制19990,也就是u4e16, 同样也可以算出'界'的unicode值16位表示是754c
https://play.golang.org/p/ZvkSYwdI1
package main import ( "fmt" "strconv" ) func main() { // Unicode value for '世' fmt.Println(strconv.FormatInt(19990, 16)) // Unicode value for '界' fmt.Println(strconv.FormatInt(30028, 16)) } // <===================OUTPUT===================> // 4e16 // 754c
- 下面就是Unicode和UTF-8值之间的转换了,首先我们写了一个程序来把我们的unicode
十六进制的值转换成二进制
package main import ( "fmt" "os" "github.com/harrifeng/bitutil" ) func main() { fmt.Println(bitutil.HexStringToBinaryString("4e16")) os.Exit(0) } // <===================OUTPUT===================> // 0100|1110|0001|0110
- 得到了二进制字符串0100|1110|0001|0110,然后我们从后面开始每六个一组,从而
得到
0100|1110|0001|0110 => One:0100 two:|1110|00 three:01|0110
- two和three前面都加上10,表示是小弟.one加上1110表是是大哥从而得到
One:0100 two:|1110|00 three:01|0110 + 1110 10 10 => 11100100 10111000 10010110 => E4 B8 96
- "世界"是两个汉字,其中"世"的unicode值是(通过https://unicode-table.com/en/search/?q=%E4%B8%96查询)
十进制19990,也就是u4e16, 同样也可以算出'界'的unicode值16位表示是754c
https://play.golang.org/p/ZvkSYwdI1
- 这就是UTF-8的全部内容,其核心就是依赖尽可能能少的bit(最少8个)来实现Unicode
Unicode, 也就是我们说的Rune, 都是32bit的,但是其中"有意义的内容"有8bit,16bit,
24bit,32bit的四种情况,其中:
- 最多的情况是8bit,这种情况下一个hexdecimal escape就够了,比如'\x41'就 可以表示A. 也就是一个rune literal可以使用一个hexdecimal escape来表示
- 16bit,24bit,32bit的情况下就不能使用"一个"hexdecimal escape了,要使用好几个 比如'xe4\xb8\x96'这虽然是一个legal的UTF-8literal,但是取并不是一个legal的 rune literal.因为一个rune literal必须是一个escape,不能是三个.所以这种情 况下一个rune literal必须使用一个Unicode escape!
- 由于UTF-8出色的设计,我们的很多string操作完全不需要decoding,比如我们可以通
过如下的代码来测试某个string是不是contains另外的string:
- 作为prefix
https://play.golang.org/p/RbWRJa7NmE
package main import ( "fmt" "os" ) func HasPrefix(s, prefix string) bool { return len(s) >= len(prefix) && s[:len(prefix)] == prefix } func main() { fmt.Println(HasPrefix("我们的爱", "我们")) fmt.Println(HasPrefix("我们的爱", "们")) os.Exit(0) } // <===================OUTPUT===================> // true // false
- 作为suffix
https://play.golang.org/p/qXYZ6TYid0
package main import ( "fmt" "os" ) func HasSuffix(s, suffix string) bool { return len(s) >= len(suffix) && s[len(s)-len(suffix):] == suffix } func main() { fmt.Println(HasSuffix("我们", "们")) fmt.Println(HasSuffix("我们", "我们的")) os.Exit(0) } // <===================OUTPUT===================> // true // false
- 作为prefix
https://play.golang.org/p/RbWRJa7NmE
- 实际上,所有使用UTF-8编码的字符串都可以使用同样的逻辑,这种简洁性来自于UTF-8的编码
- 我们前面讲过,包含了超过8bitUnicode的字符串,其len()的结果,和rune的个数不会一样
https://play.golang.org/p/b6XoblT29f
package main import ( "fmt" "unicode/utf8" ) func main() { s := "hello, 世界" fmt.Println(len(s)) fmt.Println(utf8.RuneCountInString(s)) } // <===================output===================> // 13 // 9
- 如果我们不想一个一个byte(8bit)的处理,而是一个一个rune(32-bit)的处理,,那么
我们就要使用unicode/utf8 package
https://play.golang.org/p/aZsVr2my_b
package main import ( "fmt" "unicode/utf8" ) func main() { s := "hello, 世界" for i := 0; i < len(s); { r, size := utf8.DecodeRuneInString(s[i:]) fmt.Printf("%d\t%c\n", i, r) i += size } } // <===================OUTPUT===================> // 0 h // 1 e // 2 l // 3 l // 4 o // 5 , // 6 // 7 世 // 10 界
- 当然了,自己算index的方法很麻烦,可喜的是,虽然len()是以byte为中心的,但是内置
的range确是以rune为核心的
- 代码如下
https://play.golang.org/p/pn4voeyqrM
package main import "fmt" func main() { for i, r := range "hello, 世界" { fmt.Printf("%d\t%q\t%d\n", i, r, r) } } // <===================OUTPUT===================> // 0 'h' 104 // 1 'e' 101 // 2 'l' 108 // 3 'l' 108 // 4 'o' 111 // 5 ',' 44 // 6 ' ' 32 // 7 '世' 19990 // 10 '界' 30028
- 其示意图如下
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ |...| h | e | l | l | o | , | | e4| b8| 96| e7| 95| 8c|...| | | | | | +---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ ^ _____世____+_____界_____ | | +----------+ | | data -+--------+ +----------+ | len: 13 | +----------+
- 代码如下
https://play.golang.org/p/pn4voeyqrM
- 换句话说就是range implicit地调用了utf8.DecodeRuneInString.那么问题来了,我们 调用utf8.DecodeRuneInString,无论是explicit还是implicit的情况下,有时候会遇到 所decode的字符串里含有unexpected的input byte.这种情况下,go会自动将unexpected 的字符替换成'\uFFFD'(�),这会是一个菱形的问号.如果遇到这个字符,说明上游的字 符串出了问题(不是一个legal的UTF-8字符串)
- UTF-8很方便,又节省空间.但是有时候,我们更重视效率(rune大小一致,效率更高),直 接使用rune类型是一个好主意.
- rune类型是为Unicode设计的,即便是ASCII类型的字符也是使用32个bit.换句话说,rune 类型数组的len不在是以8bit为单位记录的了,而是以32bit为单位记录.这样虽然不高 效,但是容易理解.
- byte对应的是rune,那么string对应的就是[]rune了(%x会在hex digit之间加空格)
https://play.golang.org/p/CQcZyiOarS
package main import "fmt" func main() { s := "a世界" r := []rune(s) fmt.Println(len(r)) fmt.Printf("%x\n", r) } // <===================OUTPUT===================> // 3 // [61 4e16 754c]
- []rune(slice of rune)可以直接通过T(x)类型转换成string,自动变成"连续的UTF-8" 字符串
- string(x)的参数x如果是整数类型的话,会被理解成rune的integer值,然后转换成
string类型!这一点非常重要,不要理解为会转成"相应字符串",那是itoa做的事情,invalid
的Unicode字符串当然就是打印'\uFFFD'(�)了
https://play.golang.org/p/HwolI0MzKN
package main import ( "fmt" "os" "strconv" ) func main() { fmt.Println(string(65)) fmt.Println(string(0x4eac)) // convert integer to corresponding string fmt.Println(strconv.Itoa(65)) // invalid rune Unicode value fmt.Println(string(0x123456)) os.Exit(0) } // <===================OUTPUT===================> // A // 京 // 65 // �
Strings and Byte Slices
- go处理string主要有如下几个package:
- bytes: 主要对byte提供search, replace, compara, trim, split join等功能.而 且因为string是immutable的,所有有些情况下需要使用bytes.Buffer类型来提高字 符串处理的效率
- strconv: 负责boolean, integer, floating-point值和string之间的相互转换.
- unicode: 提供了对rune类型的帮助函数,比如IsDigit, IsLetter, IsUpper, IsLower 等,都是对一个rune的处理,处理的结果,还是一个rune类型.
- strings: 主要对string提供对字符串的查找更改等内容.strings里面也有unicode 里面类似的ToUpper,ToLower功能,只不过输入是UTF-8的字符串,输出也是UTF-8的字 符串
- 依靠这四个package的帮助,我们能够很轻松的实现一些功能,比如Unix里面求basename
的命令
$ basename "a/b/c.go" c - 实现的方法核心其实就是strings.LastIndex
https://play.golang.org/p/QxNxhC5Kpl
package main import ( "fmt" "os" "strings" ) func basename(s string) string { slash := strings.LastIndex(s, "/") // -1 if "/" not found s = s[slash+1:] if dot := strings.LastIndex(s, "."); dot >= 0 { s = s[:dot] } return s } func main() { fmt.Println(basename("a/b/c.g")) os.Exit(0) } // <===================OUTPUT===================> // c
- 下面一个例子是给integer里面每三个数字之间插入一个逗号,这是一个简洁的递归版本
https://play.golang.org/p/VHa7APJvA4
package main import ( "fmt" "os" ) func comma(s string) string { n := len(s) if n <= 3 { return s } return comma(s[:n-3]) + "," + s[n-3:] } func main() { fmt.Println(comma("12345")) os.Exit(0) } // <===================OUTPUT===================> // 12,345
- 前面我们说过,使用T(x)的类型转换,可以在string和byte slice之间来回转换.当然
这两种转换的过程中,都会申请一个新的空间来存储新的slice(底层数组)或者新的字
符串
https://play.golang.org/p/zHTvLHvZHC
package main import ( "fmt" "os" ) func main() { s := "abc" b := []byte(s) s2 := string(b) fmt.Println(s, b, s2) os.Exit(0) } // <===================OUTPUT===================> // abc [97 98 99] abc
- 为了减少byte和string之间转换带来的额外空间使用,我们的bytes库很多地方都拷贝
了strings库的样式(这样就可以在byte类型和string类型完成工作,而不需啊哟先转
换成彼此再工作啦):
- 一些strings库的函数
func Contains(s, substr string) bool func Count(s, sep string) int func Fields(s string) []string func HasPrefix(s, prefix string) bool func Index(s, sep string) int func Join(a []string, sep string) string
- 相同名字(类型为[]byte的)bytes库的函数
func Contains(b, subslice []byte) bool func Count(s, sep []byte) int func Fields(s []byte) [][]byte func HasPrefix(s, prefix []byte) bool func Index(s, sep []byte) int func Join(s [][]byte, sep []byte) []byte
- 一些strings库的函数
- bytes package提供了一个叫做Buffer的东西(bytes.Buffer)来管理byte slice,它的
特点是内部存储是使用的byte数组,但是提供了写入byte,string,rune的三个接口,如下:
https://play.golang.org/p/h7G26jnShq
package main import ( "bytes" "fmt" "os" ) func intsToString(values []int) string { var buf bytes.Buffer buf.WriteRune(23383) buf.WriteRune('符') buf.WriteString("数组:") buf.WriteByte('[') for i, v := range values { if i > 0 { buf.WriteString(", ") } fmt.Fprintf(&buf, "%d", v) } buf.WriteByte(']') return buf.String() } func main() { fmt.Println(intsToString([]int{1, 2, 3})) os.Exit(0) } // <===================OUTPUT===================> // 字符数组:[1, 2, 3]
Conversions between Strings and Numbers
- 除了在string, rune和byte直接的转换,另外常见的转换就是numeric value和它们字 符表达方式直接的转换了,在c里面有atoi和itoa两个函数
- 先看integer转换成string,有两种方法:一个是fmt.Sprintf,另外一个就是strconv package
里面的Itoa(integer to ASCII)
https://play.golang.org/p/p8F3JnKMFb
package main import ( "fmt" "os" "strconv" ) func main() { x := 123 fmt.Println(strconv.Itoa(x)) y := fmt.Sprintf("%d", x) fmt.Println(y) os.Exit(0) } // <===================OUTPUT===================> // 123 // 123
- 上面integer转换成string的十进制,有时候我们还想转换成二进制,八进制,十进制,十六
进制这个时候fm.Printf的%b, %x, %u是最可以依赖的.
https://play.golang.org/p/yM3e6n6SQs
package main import ( "fmt" "os" ) func main() { x := 15 fmt.Printf("x = %b\n", x) // binary fmt.Printf("x = %o\n", x) // octonary fmt.Printf("x = %d\n", x) // decimal fmt.Printf("x = %x\n", x) // hexadecimal fmt.Printf("x = %X\n", x) os.Exit(0) } // <===================OUTPUT===================> // x = 1111 // x = 17 // x = 15 // x = f // x = F
- strconv package里面也有Format系列函数来达到上面同样的目的,但是不够灵活,比如
无法像前面加上"x="
https://play.golang.org/p/o7y9biwmKm
package main import ( "fmt" "os" "strconv" ) func main() { fmt.Println(strconv.FormatInt(int64(15), 2)) fmt.Println(strconv.FormatInt(int64(15), 8)) fmt.Println(strconv.FormatInt(int64(15), 10)) fmt.Println(strconv.FormatInt(int64(15), 16)) fmt.Println(strconv.FormatUint(uint64(15), 2)) os.Exit(0) } // <===================OUTPUT===================> // 1111 // 17 // 15 // f // 1111
- 第二个大的转换就是"字符串到integer"了,这个时候fmt(其中的Scanf)就不是特别好 使了,因为它只能处理input,并且要求输入在同一行
- 那么就只要靠strconv package的两个函数Atoi(主要负责十进制转换),还有就是
ParseInt(负责各个进制的转换)
https://play.golang.org/p/niPs58jLeb
package main import ( "fmt" "os" "strconv" ) func main() { x, _ := strconv.Atoi("23") fmt.Println(x) y, _ := strconv.ParseInt("F", 16, 64) fmt.Println(y) y, _ = strconv.ParseInt("10", 10, 64) fmt.Println(y) y, _ = strconv.ParseInt("10", 8, 64) fmt.Println(y) y, _ = strconv.ParseInt("10", 2, 64) fmt.Println(y) os.Exit(0) } // <===================OUTPUT===================> // 23 // 15 // 10 // 8 // 2
Constants
- 所谓Constant,就是在compile time就被编译器所知的,而且不会改变的值.
- 只有如下三种类型可以设置为constant:
- boolean
- string
- number
- const的会声明一个named value,这个named value和很多的variable一样,只不过它的
值不可能改变
const pi = 3.14159 // approximately: math.Pi is a better approximation
- const value只是mathematical constant的一种更为容易接受的表示方法(对人类更友 好, 对编译器来说,没区别)
- const可以在()里面一次定义多个
const ( e = 2.71828 pi = 3.1415926 )
- const会对错误detect有好处:某些操作,如果使用变量,那么就要在runtime发现问题, 比如"除以零integer division by zero"
- 但是如果我们使用常量来替代变量作为operand(操作数),那么问题就会暴露在编译阶段
- 对const 操作数的算术操作,逻辑操作,比较操作结果都可以算作是constant
- 某些built-in的函数操作结果也是const,比如len, cap, real, imag, complex, unsafe.Sizeof
- 因为constant其值在compile time已知,所以const(或者const expression)可以出现
在type定义的时候,比如定义array 类型的长度
const IPv4Len = 4 // parseIPv4 parses an IPv4 addresss func parseIPv4(s string) IP { var p [IPv4Len]byte // ... }
- const 声明和var声明不一样的地方是,const声明必须有值!但是类型可以省略,因为可
以从值里面推出类型
package main import ( "fmt" "os" "time" ) func main() { const noDelay time.Duration = 0 const timeout = 5 * time.Minute fmt.Printf("%T %[1]v\n", noDelay) fmt.Printf("%T %[1]v\n", timeout) fmt.Printf("%T %[1]v\n", time.Minute) os.Exit(0) } // <===================OUTPUT===================> // time.Duration 0s // time.Duration 5m0s // time.Duration 1m0s
- 定义的时候,如果某一项不赋值,其值(和类型)来自于上一项(previous expression
and its type used again)
https://play.golang.org/p/x-f9UeuqPb
package main import "fmt" func main() { const ( a = 1 b c = 2 d ) fmt.Println(a, b, c, d) } // <===================OUTPUT===================> // 1 1 2 2
The Constant Generator iota
- const 的定义还可以更加的"智能",就是iota,能够"智能"的增加.默认从0开始,默认
每次增加1
https://play.golang.org/p/nKw9Dcb7Xp
package main import "fmt" func main() { type Weekday int const ( Sunday Weekday = iota Monday Tuesday Wednesday Thursday Friday Saturday ) fmt.Println(Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday) } // <===================OUTPUT===================> // 0 1 2 3 4 5 6
- 还可以使用更加复杂的用法, 复杂在使用了expression给const赋值,iota还是遵循"从
零开始,每次增长1"的规律
https://play.golang.org/p/4np6pGINTC
package main import "fmt" func main() { const ( First uint = 1 << iota Second Third Fourth Fifth ) fmt.Println(First, Second, Third, Fourth, Fifth) fmt.Println("Binary:") fmt.Printf("%b, %b, %b, %b, %b", First, Second, Third, Fourth, Fifth) } // <===================OUTPUT===================> // 1 2 4 8 16 // Binary: // 1, 10, 100, 1000, 10000
- 一个更加复杂的例子就是使用iota来生成二进制的容量
- 从这个例子也能看出iota的局限性:只能使用位移操作的话,只能以二进制为底,无法产
生1000等不是以2为底产生的数(KB其实就是1000M, KiB是1024B)
https://play.golang.org/p/GZ7CekDRmf
package main import ( "fmt" "os" ) func main() { const ( _ = 1 << (10 * iota) KiB MiB GiB TiB ) fmt.Println(KiB) fmt.Println(MiB) fmt.Println(GiB) fmt.Println(TiB) os.Exit(0) } // <===================OUTPUT===================> // 1024 // 1048576 // 1073741824 // 1099511627776
Untyped Constants
- 虽然constant可以是一种basic data type比如int或者float64,但是很多情况下constant 在编译时间是无法确定其类型的.这种情况下, go编译器会使用一个最大256bit的存储 空间来存储这个constant,这就是所谓的untyped constant
- 这种不确定类型的const有六种表现形式:
- untyped boolean
- untyped integer
- untyped rune
- untyped floating-point
- untyped complex
- untyped string
- 256bit是非常大的一个区间,能够表示非常大的数,大于64bit的数你都不能用fmt打印
出来.为了演示,我们扩展一下上面的例子,打印更多的容量表示方法
https://play.golang.org/p/kmbx438oSa
package main import ( "fmt" "os" ) func main() { const ( _ = 1 << (10 * iota) KiB MiB GiB TiB PiB EiB ZiB YiB ) fmt.Println(KiB) fmt.Println(MiB) fmt.Println(GiB) fmt.Println(TiB) fmt.Println(PiB) fmt.Println(EiB) // fmt.Println(ZiB) //exceeds 1 << 64 from here // fmt.Println(YiB) fmt.Println(YiB / ZiB) os.Exit(0) } // <===================OUTPUT===================> // 1024 // 1048576 // 1073741824 // 1099511627776 // 1125899906842624 // 1152921504606846976 // 1024
- ZiB, YiB就是这样的使用了256bit(最大)存储的untype integer.这种untype integer
虽然不能打印,却能够正常的使用
fmt.Println(YiB/Zib) // "1024"
- 另外一个常见的untype的const是math.Pi,它可以在任何float32或者float64应该出现
的位置出现,而且不需要加类型信息
var x float32 = math.Pi var y float64 = math.Pi var z complex128 = math.Pi
- 如果我们的math.Pi是float64类型的,单说精度降低不假,我们还要每次写代码的时候
写上类型信息(因为Go不允许任何形式的implicit conversion)
const Pi64 float64 = math.Pi var x float32 = float32(Pi64) var y float64 = Pi64 var z complex128 = complex128(Pi64)
- 在Go的编译器设计中,literal其实都被设计成为了untyped const,对应六种untyped
const,我们就有六种zero value:
- untyped boolean: 两个:true和false
- untyped integer: 0
- untyped rune: '\u0000'
- untyped float: 0.0
- untyped complex: 0i
- untyped string: 任何string literal
- literal的这种const特性在判断算术结果的时候非常重要,换句话说使用不同的syntax
的literal,得出的结果完全不同
package main import ( "fmt" "os" ) func main() { var f float64 = 212 fmt.Println((f - 32) * 5 / 9) // (f-32) is a float64 fmt.Println(5 / 9 * (f - 32)) // 5/9 is an untyped integer, 0 fmt.Println(5.0 / 9.0 * (f - 32)) // 5.0/9.0 is an untyped float os.Exit(0) } // <===================OUTPUT===================> // 100 // 0 // 100
- 只有const具有untyped的特性,其他的variable是不可能具有untyped特性的.换句话
说,当一个const赋值给某个variable(声明时候的初始化值也算赋值),implicit
conversion发生了!这种我们第一次在Go里面遇到implicit conversion
var f float64 = 3 + 0i // untyped complex -> float64 f = 2 // untyped integer -> float64 f = 1e123 // untyped floating-point -> float64 f = 'a' // untyped rune -> float64
- 下面的代码也就等同于如下(的explicit conversion)
var f float64 = float64(3 + 0i) f = float64(2) f = float64(1e123) f = float64('a')
- 我们untyped 六种类型,在var without type 或者short variable declaration这两
种不提供type的初始化方法中,会起到作用(能够定义变量的类型).需要注意的是untype
float会变成确定高精度的float64, untype complex会变成确定的高精度的complex128
但是untype int只会变成int. 这是因为Go中并不存在unsized的float和complex类型,
因为对于浮点数来说,不知道具体bit长度实在太麻烦了
https://play.golang.org/p/YkATM4_20u
package main import ( "fmt" "os" ) func main() { i := 0 r := '\000' var f = 0.0 var c = 0i fmt.Printf("%T\n", i) // untyped integer; implicit int(0) fmt.Printf("%T\n", r) // untyped rune; implicit rune('\000') fmt.Printf("%T\n", f) // untyped floating-pint; implicit float64(0.0) fmt.Printf("%T\n", c) // untyped complex; implicit complex128(0i) os.Exit(0) } // <===================OUTPUT===================> // int // int32 // float64 // complex128
- 如果不想安装预定的类型转换,那么就要明确的进行T(x)转换
var i = int8(0) var i int8 = 0
- 我们这里第一次见到Go的implicit转换,虽然是implicit的转换,但是和explicit一样,
目的的type必须能够装的下我们的数据,否则会overflow
https://play.golang.org/p/nwNM9H_qME
package main import ( "fmt" "os" ) const ( deadbeef = 0xdeadbeef a = uint32(deadbeef) b = float32(deadbeef) // rounded up c = float64(deadbeef) ) func main() { fmt.Println(deadbeef) fmt.Println(a) fmt.Println(b) fmt.Println(c) /////////////////////////////////////////////////// // // constant 3735928559 overflows int32 // // const d = int32(deadbeef) // /////////////////////////////////////////////////// ///////////////////////////////////////////////// // // constant 1e+309 overflows float64 // // const e = float64(1e309) // ///////////////////////////////////////////////// ////////////////////////////////////////// // // constant -1 overflows uint // // const f = uint(-1) // ////////////////////////////////////////// os.Exit(0) } // <===================OUTPUT===================> // 3735928559 // 3735928559 // 3.7359286e+09 // 3.735928559e+09
Chapter 04: Composite Types
- 前面一章我们介绍了Go里面的basic type,这些类型是语言的不可再分的基石(atom),这 一章我们将介绍composite type: array, slice, map, struct
- 这四个composite type还能根据长度特性分成两组:
- fix length: array, struct
- dynamic length: slice, map
- 而根据内容的性质array和struct又有不同:
- array的所有成员的类型一定是相同的,所以它是homogeneous
- struct的所有成员类型不一定相同,所以它是heterogeneous
Arrays
- Array是一种"固定"长度的某种类型的element的集合.因为其长度固定,所以在"具有动 态特性"的go语言中,很少使用.而更具动态特点的slice则更多的被使用.slice和array 则是相辅相成的一对.不理解array,则无法理解slice
- array使用最传统的中括号进行访问,而且index从0开始,长度不超过len(arr) - 1
var a [3]int // array of 3 integers fmt.Println(a[0]) // print the first element fmt.Println(a[len(a)-1]) // print the last element, a[2]
- array初始化方法主要以array literal为主(如果不初始化,或者literal没有提到的,就
设置为0), array literal是一个重点,因为很多奇怪的语法都是因为看不懂array literal
https://play.golang.org/p/EUYz-koBIT
package main import "fmt" func main() { var q [3]int = [3]int{1, 2, 3} var r [3]int = [3]int{1, 2} fmt.Println(q) fmt.Println(r) } // <===================OUTPUT===================> // [1 2 3] // [1 2 0]
- 当然了,如果我们想让literal的长度来决定数组的话,就要使用ellipsis(…), 值得
注意的是如果不写'…',就变成了slice类型的literal初始化方法
https://play.golang.org/p/Xj5mhBNDmy
package main import "fmt" func main() { q := [...]int{1, 2, 3, 4} fmt.Println(q) fmt.Printf("%T\n", q) } // <===================OUTPUT===================> // [1 2 3 4] // [4]int
- 我们看到数组的类型是int,说明了数组的长度也是数组的类型元素之一,所以int
和int就不是一直类型!
https://play.golang.org/p/QUx_6OO06Y
package main import ( "fmt" "os" ) func main() { q := [3]int{1, 2, 3} /////////////////////////////////////////////////////////////////////////////////// // //cannot use [4]int literal (type [4]int) as type [3]int in assignment // // q = [4]int{1, 2, 3, 4} // /////////////////////////////////////////////////////////////////////////////////// fmt.Println(q) os.Exit(0) } // <===================OUTPUT===================> // [1 2 3]
- 数组的长度必须是constant expression,换言之这个数必须在编译阶段已知.使用const
expresion作为数组长度,是非常"强硬"的一个要求,因为所有变量都不是const.如果我
们在一个function里面进行运算的时候,如果function的一个参数(也就是变量)是容器
长度的最好选择,我们却不能使用它来初始化array!当然了,go有替代的方法,那就是slice,
而且是make创建的slice,因为我们要指定长度
https://play.golang.org/p/nX6Z1WHVMR
package main import ( "fmt" "os" ) func groupDisplay(l int, s string) { ////////////////////////////////////////// // // non-constant array bound l // // foo := [l]string{} // ////////////////////////////////////////// ret := make([]string, l) // bytes.Buffer instead of string is better for i, c := range s { ret[i%l] += string(c) } fmt.Println(ret) } func main() { groupDisplay(5, "abcdefghijklmn") os.Exit(0) } // <===================OUTPUT===================> // [afk bgl chm din ej]
- 我们前面多次强调过literal是非常重要的,不理解literal会导致很多代码看不到.literal
这种初始化类型的形式其实主要就是为composite type服务的. composite type一般
成员有两个特性:
- 顺序:数组里面的顺序是前后有别的,但是struct里面的顺序一般语言里面是没有别的 但是在Go里面是有别的
- key:如果把index看成是数组的key,那么数组和struct一样也是有key的,所以literal
在数组中也可以设置成有key的形式
https://play.golang.org/p/FQCVRu4V6h
package main import ( "fmt" "os" ) func main() { symbol := [...]string{0: "Dollar", 1: "RMB", 2: "Yen"} fmt.Println(symbol) os.Exit(0) } // <===================OUTPUT===================> // [Dollar RMB Yen]
- 正是由于可以指定index,那么没有指定的就是默认的zero值, 比如指定了index 9为-1
之后,前八个值都为0,第九个为-1
https://play.golang.org/p/Jln0_01ePU
package main import "fmt" func main() { symbol := [...]int{9: -1} fmt.Println(symbol) } // <===================OUTPUT===================> // [0 0 0 0 0 0 0 0 0 -1]
- 如果两个array的element type是"可以比较的", 那么这两个array也是可以比较的,比
较只有"相同"和"不相同",没有大小关系.所以只能使用"==","!="来比较
https://play.golang.org/p/huOZmdjU6S
package main import "fmt" func main() { a := [2]int{1, 2} b := [...]int{1, 2} c := [2]int{1, 3} fmt.Println(a == b, a == c, b == c) d := [3]int{1, 2} _ = d ////////////////////////////////////////////////////////////////////////////// // // invalid operation: a == d (mismatched types [2]int and [3]int) // // fmt.Println(a == d) // ////////////////////////////////////////////////////////////////////////////// } // <===================OUTPUT===================> // true false false
- 可以比较数组是非常"实用"的功能.这样让两个"非常长的数"放到两个数组里面,比较
这两个数组就能比较两个"非常长的数".这里的就是长度为256bit,所以放在byte
类型的byte数组里面的两个hash值的比较
https://play.golang.org/p/J99rOKgZEw
package main import ( "crypto/sha256" "fmt" ) func main() { c1 := sha256.Sum256([]byte("x")) c2 := sha256.Sum256([]byte("X")) fmt.Printf("%x\n%x\n%t\n%T\n", c1, c2, c1 == c2, c1) } // <===================OUTPUT===================> // 2d711642b726b04401627ca9fbac32f5c8530fb1903cc4db02258717921a4881 // 4b68ab3847feda7d6c62c1fbcbeebfa35eab7351ed5e78f4ddadea5df64b8015 // false // [32]uint8
- Go的函数调用使用的pass by value,也就说function的每个参数都会有一份拷贝,所以 function收到的是拷贝,而不是original的variable.
- 数组在Go里面并不是一种reference type,所以我们传递一个数组给function的话,调 用的时候,Go还是会复制一份数组的(如果数组大的话,这个开销会比较大).优点当然是 不会改变原来的数组啦
- 绝大部分的语言对于数组来说,都是pass by reference的,而Go却不是!
- Go中还保留着指针,所以相比于把整个数组传递进去,更好的方式显然是传递数组的指
针(和c语言学的),这种方法对于数组的操作可以被caller看到.比如我们下面的例子,
将一根byte数组的内容都值零
https://play.golang.org/p/k0oc9NTgSF
package main import ( "fmt" "os" ) func zero(ptr *[32]byte) { for i := range ptr { ptr[i] = 0 } } func main() { var arr = [32]byte{1, 2, 3, 4} fmt.Println(arr) zero(&arr) fmt.Println(arr) os.Exit(0) } // <===================OUTPUT===================> // [1 2 3 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] // [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
- 这段代码是不是看起来很晕?怎么range就range了一个指针了(指向数组的指针),而且
还可以直接使用指针加[]的方法访问成员变量!这是因为spec里面定义了对于pointer
to array 的优待
https://golang.org/ref/spec
For a of pointer to array type: + a[x] is shorthand for (*a)[x]
- 上面的例子可以改写成如下
https://play.golang.org/p/OhlSax5KCB
package main import ( "fmt" "os" ) func zero(ptr *[32]byte) { for i := range *ptr { (*ptr)[i] = 0 } } func main() { var arr = [32]byte{1, 2, 3, 4} fmt.Println(arr) zero(&arr) fmt.Println(arr) os.Exit(0) } // <===================OUTPUT===================> // [1 2 3 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] // [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
- 我们还可以利用byte{}整个literal产生的数组本来就是zero value数组这个事实
来简化我们的代码
https://play.golang.org/p/1kcOrqTV03
package main import ( "fmt" "os" ) func zero(ptr *[32]byte) { *ptr = [32]byte{} } func main() { var arr = [32]byte{1, 2, 3, 4} fmt.Println(arr) zero(&arr) fmt.Println(arr) os.Exit(0) } // <===================OUTPUT===================> // [1 2 3 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] // [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
- 尽管这样,把数组作为function的参数仍然不是一个好的主意,因为数组长度也是数组 类型的一部分,所以上面的例子对于byte就不适用.
- 所以除非是256bit哈希值那种例子,大部分的Go代码都不会使用数组作为参数,而是使 用slice
Slices
- slice是"变长"的相同数据类型的集合.和数组的"固定长度"相对立.数组的类型一般是 [n]T, 数组长度不一样,其类型肯定不一样. 而slice的类型则是[]T, 也就是说slice 的类型,只和其内部数据的类型有关系
- slice其实是依附于array的, 每个slice都有三部分组成:
- pointer: 指向自己的underlying array的某个一位置(不一定是underlying数组的 第一个)
- length: slice的长度. len函数返回这个值,不能超过capacity
- capacity: slice的长度(pointer指向的underlying array位置开始,到underlying array 结束时候的长度). cap函数返回这个值
- 多个slice可以共享同一个underlying array,比如下面的例子中Q2和summer就共享了June
https://play.golang.org/p/m1a4fYyoag
package main import ( "fmt" "os" ) func main() { months := [...]string{ 1: "January", 2: "Febrary", 3: "March", 4: "April", 5: "May", 6: "June", 7: "July", 8: "August", 9: "September", 10: "October", 11: "November", 12: "December"} Q2 := months[4:7] summer := months[6:9] fmt.Printf(" Q2: %v len:%d cap:%d\n", Q2, len(Q2), cap(Q2)) fmt.Printf("summer: %v len:%d cap:%d\n", summer, len(summer), cap(summer)) os.Exit(0) } // <===================OUTPUT===================> // Q2: [April May June] len:3 cap:9 // summer: [June July August] len:3 cap:7
- 我们的slice的cap其实就是从我们的slice开始,到达underlying数组的最后一个数值,
可以通过下面的图直观的看出来
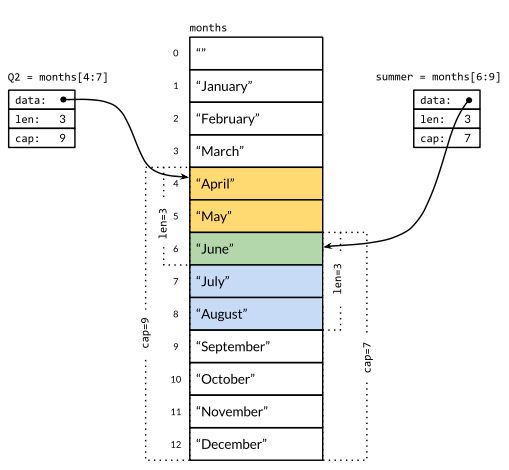
- slice的创建方法是s[i:j], 其中这里的s类型可能是:
- array
- 指向array的pointer
- 另外一个slice
- [i:j]的规则和python相同,所以大家应该不会陌生.但是和python不同的是cap的设计
(也就是underlying数组的设计),我们的j可以超过len,但是不能超过cap
fmt.Println(summer[:20]) // panic: out of range endlessSummer := summer[:5] // extend a slice(within capacity) fmt.Println(endlessSummer) // "[June July August September October]"
- 这里插一句,如果把string看成是underlying数组的话,可以重复使用underlying string 的slice就是[]byte
- 所以slice看起来有点像c语言里面的数组指针!只不过是包裹过的,更加安全的指针!因 为是指针,所以两个slice之间也是有可能重叠的.
- 还是因为slice内部有一个指针,所以传递一个slice到一个函数里面是常用的做法,因为
这避免了传递数组会发生的拷贝.既然是slice含有指针,那么副作用必然会有,那就是
underlying array的值可能会被改变
https://play.golang.org/p/hub1AS4Ov4
package main import "fmt" func reverse(s []int) { for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 { s[i], s[j] = s[j], s[i] } } func main() { a := [...]int{0, 1, 2, 3, 4, 5} reverse(a[:]) fmt.Println(a) } // <===================OUTPUT===================> // [5 4 3 2 1 0]
- 编程珠玑里面的rotate 一个数组n个位置的经典问题,在slice看来就变得非常简单,下
面就是例子的代码.Note:这里是初始化的slice,所以类型写的是[]int,而不是[…]int
当然了,因为后面还是literal string,我们还是可以1:按顺序书写,2:写上index加某号
指定,未指定的位置值为0
https://play.golang.org/p/udhSGhHyY9
package main import "fmt" func reverse(s []int) { for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 { s[i], s[j] = s[j], s[i] } } func main() { // rotate s by 2 s := []int{0, 1, 2, 3, 4, 5} // Important! slice is []int type reverse(s[:2]) reverse(s[2:]) reverse(s) fmt.Println(s) } // <===================OUTPUT===================> // [2 3 4 5 0 1]
- 和数组不一样的是,slice是不能使用==进行比较的.唯一一个类外,是[]byte类型的slice
可以使用bytes.Equal来进行比较.除此以外我们必须自己写函数来比较两个slice.比如
func equal(x, y []string) bool { if len(x) != len(y) { return false } for i := range x { if x[i] != y[i] { return false } } return true }
- 写出代码后,我们并没有发现这段代码有特别难的地方(基本和比较两个字符串数组没
什么区别,这里比较的是两个字符串slice),那既然支持"=="两个字符串数组,为什么我
们就不支持"=="两个字符串slice呢?原因有两点:
- slice是indirect的,它不能"包含"自己
- slice所以依赖的underlying数组是可能改变的我们无法控制
- 能够支持"=="的重要意义在于,能够使用"=="比较的类型才能作为map的key.所以slice 是不能作为key值的
- slice使用==的情况只有一种,就是和nil比较.
if summer == nil { /* ... */ }
- 之所以可以和nil比较.是因为slice有一种形态叫做zero value. 注意不是成员是zero
个,而是什么都没有的状态. 这种状态下的slice是没有underlying array的.反之,有
zero个的slice是存在的,比如[]int{}, 其明显有类型为[]int.所以
If you need to test whether a slice is empty, use len(s) == 0, not s == nil
- 除了和nil比较的结果不同,一个nil的slice和一个长度为0的slice是完全一致的,比如 reverse(nil)是完全合理的,这也就要求go的库要始终考虑nil的情况(如果不能兼顾,要 在document里面体现)
- go使用内置的make函数来创建一个slice(其核心就是创建一个unnamed array, 然后在
这个array基础上创建slice),其有三个参数:类型, length, capacity.其中capacity
可以省略,省略的情况下length等于capacity. 其实这个capacity就是unnamed array的
全部长度啦.
make([]T, len) make([]T, len, cap)
- make创建一个slice的原理是首先创建一个unnamed array,并且返回这个array的slice 因为是unnamed,所以这个数组是只能通过slice访问.
- 使用make创建,再次印证了slice是reference type三剑客(另外两个是map, channel) 之一
The append Function
- append是go语言内置的函数,用来添加item到slice里面.append添加的数目不受slice
capacity的限制,所以最后很可能返回一个和原来的slice'不相同的'slice(重新分配
了地址). 比如下面的runes slice从0开始,最后的size肯定不是0
https://play.golang.org/p/XEj_bs_pO0
package main import "fmt" func main() { var runes []rune for _, r := range "Hello, 世界" { runes = append(runes, r) } fmt.Printf("%q\n", runes) } // <===================OUTPUT===================> // ['H' 'e' 'l' 'l' 'o' ',' ' ' '世' '界']
- append对于slice的处理,类似c++中对于vector的处理–空间不够的情况下,cap加倍
当然这只是简单的描述,具体的算法可能更加的精密.去除精密的设计以后,append的真
实骨架可能就和下面我们自己实现的appendInt差不多
func appendInt(x []int, y int) []int { var z []int zlen := len(x) + 1 if zlen <= cap(x) { // There is room to grow. Extend the slice z = x[:zlen] } else { // There is insufficient space. Allocate a new array. // Grow by doubling, for amortized linear complexity. zcap := zlen if zcap < 2*len(x) { zcap = 2 * len(x) } z = make([]int, zlen, zcap) copy(z, x) // a built-in function copy(dist, source) } z[len(x)] = y return z }
- 每次appendIt运行的时候,都要看看我们新的位置zlen是不是在capacity以内:
- 是的话,它会extend原来的slice,使用下面这句.本质上还是在同一个underlying数
组上进行操作
z = x[:zlen] // new slice, with 1 bigger larger length
- 不是的话要申请新的更大的underlying数组(cap最少是当前length的两倍,这样可以 减少分配次数)来存放,然后把原来的value拷贝过来.这样一来,当前的z指向的是一 个全新的underlying数组
- 是的话,它会extend原来的slice,使用下面这句.本质上还是在同一个underlying数
组上进行操作
- 当然一个一个的拷贝是最显然的做法了,但是更好的办法是使用built-in函数copy(dist, source) 这个函数要求两个参数必须是同一类型的slice!
- 我们来通过下面的例子来真正的调用append,看看结果
https://play.golang.org/p/jqTIfvu2sP
package main import "fmt" func main() { var x, y []int for i := 0; i < 10; i++ { y = append(x, i) fmt.Printf("%d cap =%d\t%v\n", i, cap(y), y) x = y } } /////////////////////////////////////////////////////// // <===================OUTPUT===================> // // 0 cap =1 [0] // // 1 cap =2 [0 1] // // 2 cap =4 [0 1 2] // // 3 cap =4 [0 1 2 3] // // 4 cap =8 [0 1 2 3 4] // // 5 cap =8 [0 1 2 3 4 5] // // 6 cap =8 [0 1 2 3 4 5 6] // // 7 cap =8 [0 1 2 3 4 5 6 7] // // 8 cap =16 [0 1 2 3 4 5 6 7 8] // // 9 cap =16 [0 1 2 3 4 5 6 7 8 9] // ///////////////////////////////////////////////////////
- 虽然我们看到了built-in的append和我们的appendInt使用的策略是一样的,但可能它
只是在数目比较小的时候一致,built-in的append可以在后面使用更加精密的算法,所
以我们不能"想当然"的去assume这个算法什么时候重新分配underlying数组,所以使
用append最常见的做法,就是把返回值赋给原来的variable
runes = append(runes, r)
- slice虽然叫做reference type,但是需要注意的是虽然slice underlying的数组是indirect
的,但是slice的pointer, length, capacity却是真真正正的和slice在一起的:
- indirect的数组可以不和slice打招呼就更改
- 和slice在一起的pointer, length, capacity就需要"显式"的使用赋值等方法来更 改了
- 所以我们大可以把slice看成是如下的一个struct
type IntSlice struct { ptr *int len, cap int }
- append函数更加强大的地方在于其允许每次加多个item, 甚至允许增加一整个slice.
https://play.golang.org/p/rXiTV9iaMQ
package main import "fmt" func main() { var x []int x = append(x, 1) x = append(x, 2, 3) x = append(x, 4, 5, 6) fmt.Println(x) x = append(x, x...) fmt.Println(x) } // <===================OUTPUT===================> // [1 2 3 4 5 6] // [1 2 3 4 5 6 1 2 3 4 5 6]
- 加入整个数组作为参数的时候,使用了ellipsis "…",这种用法在Go里面叫做variadic
pamater
The final parameter in a function signature may have a type prefixed with .... A function with such a parameter is called variadic and may be invoked with zero or more arguments for that parameter
- 调用的时候样子是append(x, x…),而我们的append函数声明如下
func append(x []int, y ...int) []int { }
- 根据参数的不同y会被初始化成不同的slice:
- append(x, 1): y => []int{1}
- append(x, 4, 5, 6): y => []int{4, 5, 6}
- append(x, x…): y => []int{1, 2, 3, 4, 5, 6}
In-Place Slice Techniques
- in-place的更改一个slice的值是非常常用的手段.比如下面的这个nonempty的例子,就 是输入一个slice,去除这个slice里面为empty的string,然后返回.
- nonempty函数"implicit"的更改了input slice(因为使用了相同的underlying array
这样能节省一次array的申请), 使用公共underlying array也可以从下例中看到(所
以返回值要写明strings[:i])
https://play.golang.org/p/VOjSuhBC4-
package main import "fmt" func nonempty(strings []string) []string { i := 0 for _, s := range strings { if s != "" { strings[i] = s i++ } } return strings[:i] } func main() { data := []string{"one", "", "three"} // usually write // data = nonempty(data) fmt.Printf("%q\n", nonempty(data)) fmt.Printf("%q\n", data) } // <===================OUTPUT===================> // ["one" "three"] // ["one" "three" "three"]
- 所以上面的例子中的nonempty最常用的手法和append相同
data = nonempty(data)
- 一个slice可以用来实现stack:
- 比如我们一开始有一个empty slice `stack`,我们可以使用append来模仿push
stack = append(stack, v) // push v
- [len(stack)-1]就可以模仿top
top := stack[len(stack)-1] // top of stack
- [:len(stack)-1]就可以模仿pop
stack = stack[:len(stack)-1] // pop
- 比如我们一开始有一个empty slice `stack`,我们可以使用append来模仿push
- 从slice中间删除数据:
- 如果需要保持原来的顺序,那么就用我们前面讲的dist和slice的类型一致的函数
copy(dist, src)
https://play.golang.org/p/5UsqG0cmbK
package main import "fmt" func remove(slice []int, i int) []int { copy(slice[i:], slice[i+1:]) return slice[:len(slice)-1] } func main() { s := []int{5, 6, 7, 8, 9} fmt.Println(remove(s, 2)) } // <===================OUTPUT===================> // [5 6 8 9]
- 如果不需要保持原来的顺序
https://play.golang.org/p/XcvL8JgX4F
package main import "fmt" func remove(slice []int, i int) []int { slice[i] = slice[len(slice)-1] return slice[:len(slice)-1] } func main() { s := []int{5, 6, 7, 8, 9} fmt.Println(remove(s, 2)) } // <===================OUTPUT===================> // [5 6 9 8]
- 如果需要保持原来的顺序,那么就用我们前面讲的dist和slice的类型一致的函数
copy(dist, src)
https://play.golang.org/p/5UsqG0cmbK
Maps
- 哈希表是计算机重要的数据结构,能够做到search,insert,delete三种操作的复杂度在 O(logN)
- 在go里面,是使用map关键字来指代hashmap,而且map是一个reference类型,既然是refrene type,那么就需要使用make来声明,声明的时候,有两个类型需要指定,一个是key的类型, 一个是value的类型(两者类型不一定需要相同)
- key的类型是需要能够使用"=="来比较的类型,所以,虽然float类型可以使用"=="来比较 但是显然比较不准确,所以使用float类型做key是不合理的.
- 创建map有两种方式:
- 最基本的当然是使用make
ages := make(map[string]int)
- 也可以使用map literal(literal是Go的重要语法,在所有的reference type,包括数
组中都地位重要)
ages := map[string]int{ "alice": 31, "charlie": 34, }
- 使用map literal等同于先使用make,然后赋值
ages := make(map[string]int) ages["alice"] = 31 ages["charlie"] = 34
- 尽然两者相等,我们还可以使用更简单literal, 可以避免使用make来实现一个成员
个数为0的map.下面这种方法非常常用(大多数情况下是希望有个空的map)
map[string]int{}
- 最基本的当然是使用make
- map的访问是使用[]
- map的删除是使用内置的delete函数
delete(ages, "alice") // remove element ages["alice"]
- go中map的一大特性是:如果key不存在就会返回zero value,所以如下操作即便是在map
中没有bob的时候,依然不会出错. delete一个不存在的当然也不会出错啦
https://play.golang.org/p/EWVt96-14j
package main import ( "fmt" "os" ) func sum(x, y, z int) int { return x + y + z } func main() { ages := map[string]int{} fmt.Println(ages) ages["bob"] = ages["bob"] + 1 fmt.Println(ages) delete(ages, "alice") fmt.Println(ages) os.Exit(0) } // <===================OUTPUT===================> // map[] // map[bob:1] // map[bob:1]
- map element还支持+= 和++操作
ages["bob"] += 1 ages["bob"]++
- 但是map element不是一个variable,所以我们无法取得它的地址. 这样做也是有其深 层次原因的. 因为map可能每加入一个element就会重构内部的存储,m[key]的存储位置 可能就会改变.
- 对于map来说,和数组一样使用range遍历,只不过range返回的结果,不再是index value,
而是key,value
for name, age := range ages { fmt.Printf("%s\t%d\n", name, age) }
- 需要特别注意的是,map的结果是random的,没有顺序的.这么做当然也是故意的.所以我
们不要依赖range返回的顺序,真的需要顺序访问的话,需要借助slice和sort
https://play.golang.org/p/tBo_ksV6R6
package main import ( "fmt" "os" "sort" ) func main() { ages := map[string]int{ "Jan": 12, "Bob": 14, "Zoe": 18, } var names []string for name := range ages { names = append(names, name) } sort.Strings(names) for _, name := range names { fmt.Printf("%s\t%d\n", name, ages[name]) } fmt.Println() os.Exit(0) } // <===================OUTPUT===================> // Bob 14 // Jan 12 // Zoe 18
- 上面的代码中我们分配了一个初始值为空的slice,但是因为我们的长度其实是固定的
所以最好是分配一个数组或固定长度的slice.同时我们要使用append,所以必须是slice
那么,最好的方案是固定长度的slice(当然了以后我们会发现大部分情况下我们都是只
会使用slice)
names := make([]string, 0, len(ages))
- 在第一次循环中,我们的range返回的顺序是key, value,在我们只需要key的时候,可以 省略第二个参数value. 但是第二次循环的时候,我们返回顺序是index, value.我们只 需要value的情况下,必须使用blank identifier "_"来忽略第一个参数
- map type的zero value是nil,换句话说就是referenfe to no hash table at all
https://play.golang.org/p/-_gt47Upx7
package main import "fmt" func main() { var ages map[string]int fmt.Println(ages == nil) fmt.Println(len(ages) == 0) } // <===================OUTPUT===================> // true // true
- delete, len, range这些操作于一个nil的map(而不是empty size map)都是可以的,这
一点我们前面也说过,对于一个nil的容器和zero size的容器结果需要一样.除非另外
说明,这里我们就要另外说明的是m[key] = value操作不可以在一个nil的map上面.你
得分配了空间才能用啊!
ages["carol"] = 21 // panic: assignment to entry in nil map
- m[key]一个值,即便key不存在,也是没有问题的,但是很多情况下,我们希望知道有没有,
然后进行后续的操作,这就出现了如下的两种写法,它们是等价的,注意返回的第二个参
数不是error类型的err而是boolean类型的true或者false:
- two-line version:
age, ok := ages["bob"] if !ok { /* bob is not a key in this map age == 0 */}
- one-line version
if age, ok := ages["bob"]; !ok { /* ... */}
- two-line version:
- 从上面的例子中我们再次看到了"返回两个值"的用法:
- 如果只要第一个值,那么第二个值可以忽略
- 如果只要第二个值,那么第一个值必须要明确使用blank identifier
- 所以error类型(或者bool类型)一般是第二个值,因为像map[key]的情况下,我们可以 忽略第二个值而直接使用zero值.
- 存在第二个bool对于map[key]来说还是很重要的,因为有两种情况的返回0:一种是不 存在,一种是value就是0!
- 和slice一样,两个map也不可以相互比较(和nil的比较是可以的).如果想比较两个map
的内容是否完全一致需要自己写loop
func equal(x, y map[string]int) bool { if len(x) != len(y) { return false } for k, xv := range x { if yv, ok := y[k]; !ok || yv != xv{ return false } } return true }
- 这里我们的equal使用ok来分辨"不存在,所以value是zero value0"和"value值就是0"
如果我们没有写ok,而是直接使用xv != y[k]的话,那么下面这两个map就会碰巧一样!
package main import ( "fmt" "os" ) // Incorrect version! func navieEqual(x, y map[string]int) bool { if len(x) != len(y) { return false } for k, xv := range x { if xv != y[k] { return false } } return true } func main() { fmt.Println(navieEqual(map[string]int{"A": 0}, map[string]int{"B": 42})) os.Exit(0) } // <===================OUTPUT===================> // true
- go没有为我们提供set类型,但是因为map的key也是必须distinct的,所以我们可以如下
提供一个string类型的set
set := make(map[string]bool)
- 有时候,我们需要使用slice做为key,但是slice显然无法使用'==',进行比较,那么我们
就需要一些方法来让slice变成string,然后string肯定就可以使用'=='比较啦.
https://play.golang.org/p/eJc3grat_B
package main import "fmt" var m = make(map[string]int) func k(list []string) string { return fmt.Sprintf("%q", list) } func Add(list []string) { m[k(list)]++ } func Count(list []string) int { return m[k(list)] } func main() { Add([]string{"1", "2", "3"}) Add([]string{"1", "2", "3"}) Add([]string{"1", "2", "3", "4"}) Add([]string{"1", "2", "3"}) fmt.Println(Count([]string{"1", "2", "3"})) for k, v := range m { fmt.Println(k, v) } } // <===================OUTPUT===================> // 3 // ["1" "2" "3" "4"] 1 // ["1" "2" "3"] 3
- 注意,我们上面的函数使用了"q", 这会给字符串数组每个参数加上""
https://play.golang.org/p/TbNhh_sw3h
package main import ( "fmt" "os" ) func main() { arr := []string{"1", "2", "3"} fmt.Println(arr) fmt.Printf("%q\n", arr) os.Exit(0) } // <===================OUTPUT===================> // [1 2 3] // ["1" "2" "3"]
Structs
- struct 是一种aggregate date type. 它的内部可能有0个或者多个"任意类型的"named value
- struct的每一个named valu都叫做一个field. 下面就是一个有多个field的struct类型
Employee. 而 dilbert则是Employee类型的一个实例
import "time" type Employee struct { ID int Name string Address string DoB time.Time Position string Salary int ManagerID int } var dilbert Employee
- struct 实例的每个field都可以使用"<instance>.<field>"来访问, 而且这些个实例
都是真正的variable,都有自己地址的
package main import ( "fmt" "time" ) type Employee struct { ID int Name string Address string DoB time.Time Position string Salary int ManagerID int } func main() { var dilbert Employee fmt.Println(dilbert.Salary) dilbert.Salary += 5000 fmt.Println(dilbert.Salary) dilbert.Position = "Engineer" fmt.Println(dilbert.Position) position := &dilbert.Position *position = "Senior " + *position fmt.Println(dilbert.Position) } // <===================OUTPUT===================> // 0 // 5000 // Engineer // Senior Engineer
- dot notation 的"奇特"之处在于不能仅仅instance可以使用"pointer to instance"
也可以使用(相对于go, c语言里面指针会使用->)
var employeeOfTheMonth *Employee = &dilbert employeeOfTheMonth.Position += " (proactive team player)"
- 上面例子的最后一句相当于在编译的时候,自动给指针加了"解引用"(* ),给指针主动
加解引用这种方法广泛的应用在Go语言里面,比如range一个指向数组的指针的时候,也
会主动的给这个数组解引用
(*employeeOfTheMonth).Position += " (proactive team player)"
- 下面例子中的函数EmployeeByID会返回一个指向Employee struct的指针,虽然返回的
是指针,但是由于Go会"友好的"为我们加上解引用,所以使用dot访问域也是可以的
func EmployeeByID(id int) *Employee { /* ... */ } fmt.Println(EmployeeByID(dilbert.ManagerID).Position) // "Pointy-haired boss" id := dilbert.ID EmployeeByID(id).Salary = 0 // fired for ... no real reason
- 上面最后一条语句"通过返回值"更改了一个域名!而如果我们的函数声明变成下面的样
子,那么是编译不过去的!因为返回值是一个Employee类型的话,这个返回值是一个值类
型的value(在c语言里面就是一个stack里面的auto变量,调用结束后会被回收),而不是
我们这里的指针!
func EmployeeById(id int) Employee { /* ... */} // will NOT compile!! EmployeeByID(id).Salary = 0 // EmployeeByID(id) is not a variable !!
- struct的类型信息里面是包括filed的位置信息的,所以struct里面field的位置是不能 随便换的.一旦换了,那么就是一个新的struct类型了.
- 如果首字母大写的话,那么这个field就是exported的啦.这是Go独特的控制field是否 private的方法
- struct的类型是非常非常的啰嗦,因为它会包含struct自己所有的field
package main import ( "fmt" "os" ) func main() { fmt.Printf("%T\n", struct { id int name string address string }{1, "", ""}) os.Exit(0) } // <===================OUTPUT===================> // struct { id int; name string; address string }
- 我们当然可以每次都写出完整的struct类型,但是这太麻烦了,所以我们可以看到基本 上每次struct出现的时候,都伴随着type的使用:type把整个struct重定义成另外的named type
- 一个struct类型内部不能声明另外一个自己的类型, 但是却可以声明一个自己类型的指
针. 这样的话,才可以实现linkedlist,或者是二叉树等数据结构.下面就是一个利用二
叉树排序的例子
package main import ( "fmt" "os" ) func main() { input := []int{1, 3, 5, 7, 2, 4, 6} fmt.Println(input) Sort(input) fmt.Println(input) os.Exit(0) } type tree struct { value int left, right *tree } func Sort(values []int) { var root *tree for _, v := range values { root = add(root, v) } appendValues(values[:0], root) } // appendValues appends the elements of t to values in order // and returns the resulting slice. func appendValues(values []int, t *tree) []int { if t != nil { values = appendValues(values, t.left) values = append(values, t.value) values = appendValues(values, t.right) } return values } func add(t *tree, value int) *tree { if t == nil { // Equivalent to return &tree{value: value} t = new(tree) t.value = value return t } if value < t.value { t.left = add(t.left, value) } else { t.right = add(t.right, value) } // t is the parameter of the function // paramter of one function is also local variable of the function return t } // <===================OUTPUT===================> // [1 3 5 7 2 4 6] // [1 2 3 4 5 6 7]
- 对于一个struct来说,它的zero value,就是它的每个成员的zero value的组合.大多数 情况下,zero value都是有意义的,但是有些时候,设计者需要自己的努力来完成这项工 作(让自己struct的zero value有意义)
- 如果一个struct什么"其他field都不包含",那么它的样子是这样子的struct{}.它的size
为0并且没有携带任何的信息,但是有时候会有意义,有些用户使用这个来代替Set(map的
value为bool)里面的bool, 但是我们不推荐这样做
seen := make(map[string]struct{}) // set of strings // ... if _, ok := seen[s]; !ok { seen[s] = struct{}{} // ...first time seeing s... }
Struct Literals
- 一般来说,初始化struct有两种literal:
- 无field版本:(需要自己记住struct初始化时候field的顺序,这也是为什么struct
初始化的顺序改变了的话,就是不同的struct了)
type Point struct{X, Y int} p := Point{1, 2}
- 有field版本,安装filed:value的方式设置,顺序没有关系(没有设置的field自动设
置为zero value)
anim := gif.GIF{LoopCount: nframes}
- 无field版本:(需要自己记住struct初始化时候field的顺序,这也是为什么struct
初始化的顺序改变了的话,就是不同的struct了)
- 上面两种方法不能"混着用"
- 另外需要注意的是,初始化列表并不能改变某个field是不是exported的事实,如果这个
struct的field是unexported的(小写),那么只可以在本package内部使用,那你无论用
什么办法,在package外也是没法用literal来初始化的
package p type T struct{a, b int} // a and b are not exported package q import "p" var _ = p.T{a:1, b:2} // compile error: can't reference a, b var _ = p.T{1, 2} // compile error: can't reference a, b
- struct 可以传递给函数,也可以从函数中返回
func Scale(p Point, factor int) Point { return Point(p.X * factor, p.Y * factor) }
- 如果struct的size过大,我们就最好使用pointer来传递数据, 因为Go语言是如假包换
的pass-by-value.太大的数据结构拷贝一遍不是闹着玩的
func Bonus(e *Employee, percent int) int { return e.Salary * percent / 100 }
- 如果需要更改参数的值,那么使用pointer传递数据也是必须的
func AwardAnnualRaise(e *Employee) { e.Salary = e.Salary * 105 / 100 }
- 由于struct和pointer如此紧密的联系,Go设计了一种shorthand notation来创建一个
struct,并且马上获取它的指针的写法. 这种写法非常简洁有效
pp := &Point{1, 2}
- 它等同于如下的语句,但是&Point{1, 2}不仅仅是简短了一半长度这么简单,它可以灵
活的运用在function里面
pp := new(Point) *pp = Point{1, 2}
Comparing Structs
- struct是一个值value,如果struct的每个field都可以比较,而且顺序相同(顺序是类 型的一部分),那么两个struct就可以比较(注意只是比较"相等"或者"不相等",而不是 比较大小)
- 可以比较的struct,就可以做为map的key,换句话说,所有能够使用==或者=!比较的类型 都能作为map的key
Struct Embedding and Anonymous Fields
- 下面介绍的是Go语言struct的嵌套,这种嵌套是把一个named的struct放入到另外的一 个struct里面,作为一个anonymous field.这种做法是Go语言特有的.这个特性是Go语 言"单继承"的一种实现方式,能够实现使用x.f代替x.d.e.f
- 我们通过一个例子来看看这个特性:
- 2D图像中常用的shape类型有如下两个(一个是圆形,一个是车轮)
type Circle struct { X, Y, Radius int } type Wheel struct { X, Y, Radius, Spokes int }
- 车轮和Circle都有X,Y,也都有Radius,只是车轮比Circle多了一个Spoke.而X,Y很明
显能转换成一个Point类型的struct.于是在"其他语言中"会有如下的写法
type Point struct { X, Y int } type Circle struct { Center Point Radius int } type Wheel struct { Circle Circle Spokes int } var w Wheel w.Circle.Center.X = 8 w.Circle.Center.Y = 8 w.Circle.Radius = 5 w.Spokes = 20
- 这一切看起来太麻烦了.Go让一个named struct可以直接存在于另外一个struct里面
而且不需要name(所以叫做anonymous field),注意存一个struct可以,或者存struct
的指针也可以.
type Circle struct { Point Radius int } type Wheel struct { Circle Spokes int }
- 更绝的是,使用以后时候,访问具体的field的时候,不需要再加上anonymous struct
的名字了
var w Wheel w.X = 8 w.Y = 8 w.Radius = 5 w.Spokes = 20 - 当然了,一旦你选择了anonymous struct,就不能再向下面一样使用literal了
w = Wheel{8, 8, 5, 20} // compile error: unknown fields w = Wheel{X:8, Y:8, Radius: 5, Spokes:20} // compile error: unknown fields
- 使用的方法是要列出anonymous field
w = Wheel {Circle{Point{8, 8},5}, 20} w = Wheel { Circle: Circle{ Point: Point{X: 8, Y:8}, Radius: 5, } Spokes: 20, }
- 匿名的部分名字如果想打印出来,要依靠fmt里面的'#'
package main import ( "fmt" "os" ) type Point struct { X, Y int } type Circle struct { Point Radius int } type Wheel struct { Circle Spokes int } func main() { w := Wheel{Circle{Point{8, 8}, 5}, 20} fmt.Println(w) // equal to "%v" fmt.Printf("%#v\n", w) os.Exit(0) } // <===================OUTPUT===================> // {{{8 8} 5} 20} // main.Wheel{Circle:main.Circle{Point:main.Point{X:8, Y:8}, Radius:5}, Spokes:20}
- 2D图像中常用的shape类型有如下两个(一个是圆形,一个是车轮)
- anonymous field其实还是有名字的,所以你不能拥有两个类型完全一致的匿名field( 注意:两个类型一致的普通field是可以的).因为两个类型一致的匿名field会冲突
- 如果你了解到匿名field是Go实现"继承"的方式,那么你可以这么理解一个匿名类型只 允许出现一次:Go只允许"单继承"
- 匿名类型作为一个类型,其大小写决定其作用域,我们这里的例子Point, Circle都是大
写的,所以package都是全局可见的.如果我们把他们改成piont, circle,那么package
外部是不可见的.所以下面两种等价的写法在package外只能使用第一种:
- w.X = 8
- w.circle.point.X = 8
- 匿名类型不仅仅可以是struct type, 普通的named type,甚至是pointer to named type都可以作为匿名类型.但是问题在于使用普通类型(或者说pointer)作为匿名类型 的好处是什么呢?它们又没有field让我们使用!!
- 答案是我们embed一个匿名类型,不仅仅会包含它的域,还会包含它的method!而一个pointer embed起来不仅仅体积小,还能带来很多的method(这也解释了为什么只能包含一次某个 类型,否则会有好多份同名method)
- 这种embed其他类型的方法在其他语言中叫做composition, 在Go中composition是最 主要的OO编程方式
Json
- 在互联网上传送structured information.有很多的协议,比如json, xml, asn.1等,Go 统统都有支持,比如encoding/json, encoding/xml, encoding/asn1. 但是当前显然大 部分人都只使用json,所以我们使用encoding/json来介绍,但是其实三者的API大体相似
- JSON是一种对js value的encoding,JSON类型支持的javascript types只有如下几种:
- string
- numbers(javascript数值都是float类型的)
- boolean(true or false)
- array
- object
- JSON也是支持Unicode的,但是它使用的UTF-16(所谓UTF-16就是要用一个或者两个16bit 字符来表示Unicode)
- 上面五种javascript的类型其中前三种是基本类型,前三种的组合组成第四五种组合类型:
- javascript中的array,可以使用Go里面的array和slice来encode成js array
- javascript中的object是一种key必须是string,value可以是各种类型的特殊js类型, 可以使用Go里面map(string作为key)或者struct来encode成js object
- 下面的例子就是使用Go来表示json,注意``里面的内容叫做field tag,我们稍后介绍
type Movie struct { Title string Year int `json:"released"` Color bool `json:"color,omitempty"` Actors []string } var movies = []Movies{ {Title: "Casablanca", Year: 1942, Color: false, Actors: []string{"Humphrey Bogart", "Ingrid Bergman"}}, {Title: "Cool Hand Luke", Year: 1967, Color: true, Actors: []string{"Paul Newman"}}, {Title: "Bullitt", Year: 1968, Color: true, Actors: []string{"Steve McQueen", "Jacqueline Bisset"}}, }
- 像上面的这种structure是非常适合和JSON进行"双向的转换"的.从Go data structure
转换成JSON叫做marshaling,使用json.Marshal
data, err := json.Marshal(movies) if err != nil { log.Fatalf("JSON marshaling failed: %s", err) } fmt.Printf("%s\n", data)
- Marshal的结果如下(我们加了两个回车,否则实在是太长)
[{"Title":"Casablanca","released":1942,"Actors":["Humphrey Bogart","Ingrid Bergman"]}, {"Title":"Cool Hand Luke","released":1967,"color":true,"Actors":["Paul Newman"]}, {"Title":"Bullitt","released":1968,"color":true,"Actors":["Steve McQueen","Jacqueline Bisset"]}] - 看起来返回值好像是一个数组,或者是slice什么的,里面的内容是struct?答案都不对,
返回值是一个byte slice,也就是[]byte,我们使用%T会得到结果(显示为[]uint8,一回事)
package main import ( "encoding/json" "fmt" "log" "os" ) func main() { type Movie struct { Title string Year int `json:"released"` Color bool `json:"color,omitempty"` Actors []string } var movies = []Movie{ {Title: "Casablanca", Year: 1942, Color: false, Actors: []string{"Humphrey Bogart", "Ingrid Bergman"}}, {Title: "Cool Hand Luke", Year: 1967, Color: true, Actors: []string{"Paul Newman"}}, {Title: "Bullitt", Year: 1968, Color: true, Actors: []string{"Steve McQueen", "Jacqueline Bisset"}}, } data, err := json.Marshal(movies) if err != nil { log.Fatalf("JSON marshaling failed: %s", err) } fmt.Printf("%T\n", data) os.Exit(0) } // <===================OUTPUT===================> // []uint8
- 这个[]byte里面没有多余的空格,看起来非常麻烦.其实也不是为你看的,这是在网络上
传送的版本,当然尽可能的减少空格和回车,以减小体积.如果你想要"给人看"的版本,
那么就需要使用MarshalIndent来替代Marshall,新的函数需要多两个参数:第一个是
不同行之间的seperator,我们设置为空字符串"",第二个参数来设置indent长度,我们
设置为两个空格
package main import ( "encoding/json" "fmt" "log" "os" ) func main() { type Movie struct { Title string Year int `json:"released"` Color bool `json:"color,omitempty"` Actors []string } var movies = []Movie{ {Title: "Casablanca", Year: 1942, Color: false, Actors: []string{"Humphrey Bogart", "Ingrid Bergman"}}, {Title: "Cool Hand Luke", Year: 1967, Color: true, Actors: []string{"Paul Newman"}}, {Title: "Bullitt", Year: 1968, Color: true, Actors: []string{"Steve McQueen", "Jacqueline Bisset"}}, } data, err := json.MarshalIndent(movies, "", " ") if err != nil { log.Fatalf("JSON marshaling failed: %s", err) } fmt.Printf("%s\n", data) os.Exit(0) } // <===================OUTPUT===================> // [ // { // "Title": "Casablanca", // "released": 1942, // "Actors": [ // "Humphrey Bogart", // "Ingrid Bergman" // ] // }, // { // "Title": "Cool Hand Luke", // "released": 1967, // "color": true, // "Actors": [ // "Paul Newman" // ] // }, // { // "Title": "Bullitt", // "released": 1968, // "color": true, // "Actors": [ // "Steve McQueen", // "Jacqueline Bisset" // ] // } // ]
- 你如果细心就会发现,Year在[]byte里面变成了released, Color变成了color,这就是 我们前面说的field tag的作用
- field tag可以是任意的literal string,但是一般来说,都是如下的格式
key:"value"[空格] key:"value"...
- 由于field tag里面的value一定是double quotation(双引号)的格式,所以我们需要使 用raw string literal(``),因为这样能够保证""不被删除
- field tag里面的key往往用来指定encode的格式,比如这里是json
- field tag里面的value用来指定encode后的名字(因为Go里面想要export,这个名字必 须得是大写,我们又不一定能够容忍所有的json名字是大写的,所以这个value很重要)
- value还能有附加参数,比如这里omitempty就是.用来表示,如果结果是false(或者空)的 话,我们就不需要在结果里面显示这一项目:我们的卡萨布兰卡就没有color这一项
- marshaling的"相反的操作":就是把JSON转换成Go的data structure,叫做unmarshaling 使用的接口是json.Unmarshal
- json.Unmarshal的第二个参数是一个struct,只有我们的struct里面设置的field才会
被真正的转换,其他部分都被丢弃掉了
var titles []struct{ Title string } if err := json.Unmarshal(data, &titles); err != nil { log.Fatalf("JSON unmarshaling failed: %s", err) } fmt.Println(titles) // "[{Casablanca} {Cool Hand Luke} {Bullitt}]"
- 很多的web service都是使用的JSON作为传输的格式,比如github.下面就是一个使用github
API的例子,传输的格式就是json:
- 首先定义类型,类型必须是首字母大写,如果api的返回不是首字母大写的,我们需要一个field tag
package github import "time" const IssuesURL = "https://api.github.com/search/issues" type IssuesSearchResult struct { TotalCount int `json:"total_count"` Items []*Issue } type Issue struct { Number int HTMLURL string `json:"html_url"` Title string State string User *User CreatedAt time.Time `json:"created_at"` Body string // in Markdown format } type User struct { Login string HTMLURL string `json:"html_url"` }
- 下面就是对这个API的使用,先调用HTTP request,返回值解析成我们前面定义的类型
这里我们没有使用Unmarshal,而是使用了straming decoer: json.Decoder,它的特
性是能够允许多个JSON 一块进行decode
package github import ( "encoding/json" "fmt" "net/http" "net/url" "strings" ) func SearchIssues(terms []string) (*IssuesSearchResult, error) { q := url.QueryEscape(strings.Join(terms, " ")) resp, err := http.Get(IssuesURL + "?q=" + q) if err != nil { return nil, err } // We must close resp.Body on all execution paths. if resp.StatusCode != http.StatusOK { resp.Body.Close() return nil, fmt.Errorf("search query failed: %s", resp.Status) } var result IssuesSearchResult if err := json.NewDecoder(resp.Body).Decode(&result); err != nil { resp.Body.close() return nil, err } resp.Body.Close() return &result, nil }
- 使用方法如下
package main import ( "fmt" "log" "os" "gopl.io/ch4/github" ) func main() { result, err := github.SearchIssues(os.Args[1:]) if err != nil { log.Fatal(err) } fmt.Printf("%d issues:\n", result.TotalCount) for _, item := range result.Items { fmt.Printf("#%-5d %9.9s %.55s\n", item.Number, item.User.Login, item.Title) } } // <===================OUTPUT===================> // $ go build gopl.io/ch4/issues // $ ./issues repo:golang/go is:open json decoder // 13 issues: // #5680 eaigner encoding/json: set key converter on en/decoder // #6050 gopherbot encoding/json: provide tokenizer // #8658 gopherbot encoding/json: use bufio // #8462 kortschak encoding/json: UnmarshalText confuses json.Unmarshal // #5901 rsc encoding/json: allow override type marshaling // #9812 klauspost encoding/json: string tag not symmetric // #7872 extempora encoding/json: Encoder internally buffers full output // #9650 cespare encoding/json: Decoding gives errPhase when unmarshalin // #6716 gopherbot encoding/json: include field name in unmarshal error me // #6901 lukescott encoding/json, encoding/xml: option to treat unknown fi // #6384 joeshaw encoding/json: encode precise floating point integers u // #6647 btracey x/tools/cmd/godoc: display type kind of each named type // #4237 gjemiller encoding/base64: URLEncoding padding is optional
- 首先定义类型,类型必须是首字母大写,如果api的返回不是首字母大写的,我们需要一个field tag
Text and HTML Templates
- 前面的例子我们使用了Printf来打印format,但是有些时候format的格式要求的更高,
不能简单的使用format,这个时候最好是能够把如下两个概念区分开来:
- format
- code logic
- 我们ruby的erb文件其实就是这样一种模板系统,而在Go里面,对应的概念就是template
注意,所谓的template其实就是一个string或者file,只不过内部有{{…}}这种格式符
号(叫做actions),用来在其内部存放变量
A template is a string or file containing one or more portions enclosed in double braces, {{...}}, called actions - 除了action以外的其他string都会如实打印, action里面因为是代码逻辑,所以会有不
同的变化, 比如:
- 打印value
- 选择struct field
- 调用function或者method
- 使用flow-control的代码,比如if-else,或者range loop
- 实例化其他template
- 下面是一个template的例子(其实就是一个string,只不过使用了raw string来表示),而
template一般也是不会改变的,所以用了const
const templ = `{{.TotalCount}} issues: {{range .Items}}--------------------------------------- Number: {{.Number}} User: {{.User.Login}} Title: {{.Title | printf "%.64s"}} Age: {{.CreatedAt | daysAgo}} days {{end}}`
- 这里的template虽然我们不说,但是也能感觉到它是和我们前面的一个struct相互联系
的.这里剧透一句Go里面会以一个template string(或者file)为基础创建出一个对象
(比如下面的tempObj)然后这个对象Execute的时候,会有两个参数,一个是output,另一
个就是一个struct,我们的template里面的内容就是联系的这个struct
tempObj.Execute(os.Stdout, someStruct)
- 我们还注意到上面的action{}里面,有个"| notation",它在这里的作用和在Unix里面
的管道的作用相似,都是把一个操作的结果传递给下一个操作,作为它的参数.我们这里
就有两个例子,一个是printf,另外一个是daysAgo. printf一看就是fmt的函数,那daysAgo
呢?也是一个函数,只不过是我们自己写的
func daysAgo(t time.Time) int { return int(time.Since(t).Hours() / 24) }
- 这又有一个问题啦printf是内置的我们可以理解(其实也不是很里面,因为是小写的p),
那程序如何知道daysAgo是我们自己写的呢,答案就是我们需要自己制定自己写的函数到
一个map里面,让template object知道如何使用.这个map里面已经default了一些常用
的函数,比如printf:
- 添加自己制定的函数,通过Funcs来添加,注意这种"链式"写法也来自c语言,要求这个
链上的每个函数返回值都一样,都是*Template
report, err := template.New("report"). Funcs(template.FuncMap{"daysAgo": daysAgo}). Parse(templ)
- FuncMap(其实就是个map)里面已经内置了一些函数了,比如printf就是fmt.Printf
package template // ... type FuncMap map[string]interface{} var builtins = FuncMap{ "and": and, "call": call, "html": HTMLEscaper, "index": index, "js": JSEscaper, "len": length, "not": not, "or": or, "print": fmt.Sprint, "printf": fmt.Sprintf, "println": fmt.Sprintln, "urlquery": URLQueryEscaper, // Comparisons "eq": eq, // == "ge": ge, // >= "gt": gt, // > "le": le, // <= "lt": lt, // < "ne": ne, // != } // ...
- 添加自己制定的函数,通过Funcs来添加,注意这种"链式"写法也来自c语言,要求这个
链上的每个函数返回值都一样,都是*Template
- 把template输出需要两个步骤:
- 首先转换template string(file)成一个内部的object:Template struct,步骤前面
在"链式"函数中写过了,Parse的返回值就是*Template
type Template struct { name string *parse.Tree *common leftDelim string rightDelim string }
- 第二步就是使用这个*Template来"联系"上output和我们想要解析的struct
var report = template.Must(template.New("issuelist"). Funcs(template.FuncMap{"daysAgo": daysAgo}). Parse(templ)) result, err := github.SearchIssues(os.Args[1:]) report.Execute(os.Stdout, result)
- 首先转换template string(file)成一个内部的object:Template struct,步骤前面
在"链式"函数中写过了,Parse的返回值就是*Template
- 我们可以看到代码中有个Must函数,这其实是一种判断返回值是否为nil的简单写法
func Must(t *Template, err error) *Template { if err != nil { panic(err) } return t }
- 我们再来看看html/template package,其基本的用法和text/template一致,只不过增 加了对html来说防止注入攻击(injection attack)的feature:自动escape HTML(JS, css, URL等)里面的特殊字符串,比如'>' , '&'等
- html/template会对template string(file) 的action里面的所有的特殊string进行
escape(比如'>' , '&'等),如果你不想让这些字符串被escape.你要赋予字符串一个新
的type(我们前面讲过,两种实质上相同的类型,可能有不同的类型名字),实际上html/template
也是这么做的
// Strings of content from a trusted source. type ( // CSS encapsulates known safe content that matches any of: // 1. The CSS3 stylesheet production, such as `p { color: purple }`. // 2. The CSS3 rule production, such as `a[href=~"https:"].foo#bar`. // 3. CSS3 declaration productions, such as `color: red; margin: 2px`. // 4. The CSS3 value production, such as `rgba(0, 0, 255, 127)`. // See http://www.w3.org/TR/css3-syntax/#parsing and // https://web.archive.org/web/20090211114933/http://w3.org/TR/css3-syntax#style // // Use of this type presents a security risk: // the encapsulated content should come from a trusted source, // as it will be included verbatim in the template output. CSS string // HTML encapsulates a known safe HTML document fragment. // It should not be used for HTML from a third-party, or HTML with // unclosed tags or comments. The outputs of a sound HTML sanitizer // and a template escaped by this package are fine for use with HTML. // // Use of this type presents a security risk: // the encapsulated content should come from a trusted source, // as it will be included verbatim in the template output. HTML string // ..... )
- 换句话说,我们自己写一个type也可以,只要不是string类型,template就不会去escape
它的特殊字符.所以下面两种方法的结果一样:
- 使用templte.HTML
https://play.golang.org/p/TdtDcx8gOx
package main import ( "fmt" "html/template" "log" "os" ) func main() { const templ = `<p>A: {{.A}}</p><p>B: {{.B}}</p>` t := template.Must(template.New("escape").Parse(templ)) var data struct { A string // untrusted plain text B template.HTML // trusted HTML } data.A = "<b>Hello!</b>" data.B = "<b>Hello!</b>" if err := t.Execute(os.Stdout, data); err != nil { log.Fatal(err) } fmt.Println() os.Exit(0) } // <===================OUTPUT===================> // <p>A: <b>Hello!</b></p><p>B: <b>Hello!</b></p>
- 自己创建一个type,underlying type还是string
https://play.golang.org/p/BUE_lKngwP
package main import ( "fmt" "html/template" "log" "os" ) type HTML string func main() { const templ = `<p>A: {{.A}}</p><p>B: {{.B}}</p>` t := template.Must(template.New("escape").Parse(templ)) var data struct { A string // untrusted plain text B HTML // trusted HTML } data.A = "<b>Hello!</b>" data.B = "<b>Hello!</b>" if err := t.Execute(os.Stdout, data); err != nil { log.Fatal(err) } fmt.Println() os.Exit(0) } // <===================OUTPUT===================> // <p>A: <b>Hello!</b></p><p>B: <b>Hello!</b></p>
- 使用templte.HTML
https://play.golang.org/p/TdtDcx8gOx
Chapter 05: Functions
- function让我们把一系列的statement包裹在一起,然后可以到处,多次调用.并且对用户 掩藏了实现的细节.对于任何语言来说function都是必不可少的部分
Function Declarations
- Go中的函数定义方法如下
func name(parameter-list) (result-list) { body } - parameter-list就是函数的参赛(包括name和type),函数的参赛也是函数的local variable, 它们的实际值是由使用者提供的
- result-list是指的返回值的类型.如果函数返回一个unnamed result,或者干脆没有返 回值,那么result-list往往省略.函数也就没有返回值,只是在调用的时候起作用.
- 既然说到了unnamed result,那也就是说,Go里面的返回值也是可以被named的,而named
result的初始化值为zero value. 这种情况下return后面什么都没有,但是不能省略
https://play.golang.org/p/fygES6ah_a
package main import ( "fmt" "os" ) func split(sum int) (x, y int) { fmt.Println(x, y) x = sum * 4 / 9 y = sum - x return // can not omit } func main() { fmt.Println(split(17)) os.Exit(0) } // <===================OUTPUT===================> // 0 0 // 7 10
- 类型相同的可以定义在一起,以下两个声明的作用一致
func f(i, j, k int, s, t string) { /* ... */ } func f(i int, j int, k int, s string, t string) { /* ... */ }
- 再考虑到可以省略参数的名字,或者使用blank identifier来代替参数,我们有如下四种
等价定义一个"参数为两个int,返回值为一个int的函数",而且我们发现,它们的类型(
function 's type) 是一样的
https://play.golang.org/p/vC7Q0Xq17Q
package main import ( "fmt" "os" ) func add(x int, y int) int { return x + y } func sub(x, y int) (z int) { z = x - y; return } func first(x int, _ int) int { return x } func zero(int, int) int { return 0 } func main() { fmt.Printf("%T\n", add) fmt.Printf("%T\n", sub) fmt.Printf("%T\n", first) fmt.Printf("%T\n", zero) os.Exit(0) } // <===================OUTPUT===================> // func(int, int) int // func(int, int) int // func(int, int) int // func(int, int) int
- 函数定义里面还是可以有blank identifier(_),可以用来彰显这个field根本就没用
- 每一个function都必须提供所有的paramter,并且以我们定义时候的顺序提供给函数,
这也就说明了两点:
- Go没有default paramter的概念
- Go也不能使用name的方法来specify argument,这也说明了paramter的名字并不重要
- paramter是function内部的local variable参数,初始化值就是调用函数时候的"实参". Go中还有named result, named result也是和parameter一样的local变量(在function 的最开始这一层)
- 在Go中所有的参赛都是按照value传递的
Arguments are passed by value, so the function receives a copy of each argument; modifications to the copy do not affect the caller.
- 如果argument是任意一种reference,那么还是有可能在调用的过程当中,间接的更改变
量里面的值的
- 可以是pointer这种真的reference
- 也可以是slice, map, channel这种reference type
- 还可以是function(Go里面function是first class object)
- 有些情况下你会看到function的声明了,却没有body, 这是因为这个function是使用其
他的语言实现的
package math func Sin(x float64) float64 // implemented in assembly language
Recursion
- 函数可以自己直接或者间接的调用自己,这叫做recursive.这是计算机里面一种解决很 多问题的强大技术
- 下面我们来看一个使用recursion的问题,这个问题使用了一个golang.org/x/net/html 的包.行如golang.org/x/net/html的包是Go team来维护的.这些包质量肯定是有保证的 但是因为并不是所有的人都会用到,所以没有放到standrd library(但是也是standard library的强力候选)
- golang.org/x/net/html会调用html.Parse来读取一系列的bytes, 分析过后,返回HTML document true(以html.Node的格式). HTML会有很多种node,比如text, comments,等等 这里我们只会使用如下的字符串来打印结果<name key='value'>
- 下面是简略版本的html package 代码来显示其内部对于html的解释
// golang.org/x/net/html package html type Node struct { Type NodeType Data string Attr []Attribute FirstChild, NextSibling *Node } type NodeType int32 const ( ErrorNode NodeType = iota TextNode DocumentNode ElementNode CommentNode DoctypeNode ) type Attribute struct { Key, Val string } func Parse(r io.Reader) (*Node, error)
- 使用的方法是curl获取一个网页的string,然后我们分析这个string得到结果
// Findlinks1 prints the links in an HTML document read from standard input. package main import ( "fmt" "os" "golang.org/x/net/html" ) func main() { doc, err := html.Parse(os.Stdin) if err != nil { fmt.Fprintf(os.Stderr, "findlinks1: %v\n", err) os.Exit(1) } for _, link := range visit(nil, doc) { fmt.Println(link) } } // visit appends to links each link found in n and returns the result. func visit(links []string, n *html.Node) []string { if n.Type == html.ElementNode && n.Data == "a" { for _, a := range n.Attr { if a.Key == "href" { links = append(links, a.Val) } } } for c := n.FirstChild; c != nil; c = c.NextSibling { links = visit(links, c) } return links } // <===================OUTPUT===================> // $ curl https://golang.org | go run main.go // % Total % Received % Xferd Average Speed Time Time Time Current // Dload Upload Total Spent Left Speed // 100 7902 100 7902 0 0 11896 0 --:--:-- --:--:-- --:--:-- 11900 // / // / // # // /doc/ // /pkg/ // /project/ // /help/ // /blog/ // http://play.golang.org/ // # // # // //tour.golang.org/ // https://golang.org/dl/ // //blog.golang.org/ // https://developers.google.com/site-policies#restrictions // /LICENSE // /doc/tos.html // http://www.google.com/intl/en/policies/privacy/
- 这里的visit函数就是一个典型的递归函数:
- 首先把当前页面里面符合<a href='…'>的标签都找出来,放到links里面
- 然后以当前页面第一个child开始,到最后一个child为止递归调用visit函数
- 我们再来看看另一个例子:打印HTML node tree
// Outline prints the outline of an HTML document tree. package main import ( "fmt" "os" "golang.org/x/net/html" ) func main() { doc, err := html.Parse(os.Stdin) if err != nil { fmt.Fprintf(os.Stderr, "outline: %v\n", err) os.Exit(1) } outline(nil, doc) } func outline(stack []string, n *html.Node) { if n.Type == html.ElementNode { stack = append(stack, n.Data) // push tag fmt.Println(stack) } for c := n.FirstChild; c != nil; c = c.NextSibling { outline(stack, c) } } // <===================OUTPUT===================> // $ curl https://golang.org | go run main.go // % Total % Received % Xferd Average Speed Time Time Time Current // Dload Upload Total Spent Left Speed // 100 7902 100 7902 0 0 9499 0 --:--:-- --:--:-- --:--:-- 9497 // [html] // [html head] // [html head meta] // [html head meta] // [html head meta] // [html head title] // [html head link] // [html head link] // [html head link] // [html head script] // [html head script] // [html body] // [html body div] // ...
- 这个例子和前面的fetchlink大体一样,只不过它要打印中间的所有过程,所以我们的stack 每次都会被打印.
- 这个slice名字虽然叫stack,但是却是只push,不pop.因为我们函数每次都是"pass by value",所以传递给下一层的都是新的slice.函数返回的时候,这个新的slice就会被丢 弃.这也同时解释了,我们没什么可以使用nil作为stack(还有前面例子里面的link)的 初始化值
- 递归是编程语言最常见的函数使用方法,但是普通的编程语言为了防止stack的增长过快, 设置了fiexed-size的stack.一般是64KB到2MB, 而Go语言则设置了variable-size stack stack最高可以达到gigabyte. 这让我们在Go里面可以放心的使用递归.
- 但是比如斐波那契数那种肯定有更好的复杂度解法的情况下,盲目使用递归会极大的提 高运行时间
Multiple Return Values
- Go里面的function可以返回多个返回值,最常见的情况就是返回两个值:
- 一个一般来说,是caller希望的返回值
- 另外一个是error类型的错误,或者是一般boolean类型(只可能有一种error错误的情况 下,比如map的获取,那么我们就没必要使用error了,使用一个boolean就可以了)
- 下面的例子是findlinks的变体:它变在自己能够发送HTTP request,所以我们不需要自
己来进行fetch了.而由于HTTP获取可能失败,而parsing 也可能失败,所以我们的返回值
自然而然的分成了两部分:
- list of link
- error类型变量err(不止一种错误,我们就要用error类型了)
- 下面就是finklink2的代码
https://play.golang.org/p/8XjgZvv11l
// Usage: // findlinks url ... package main import ( "fmt" "net/http" "os" "golang.org/x/net/html" ) // visit appends to links each link found in n, and returns the result. func visit(links []string, n *html.Node) []string { if n.Type == html.ElementNode && n.Data == "a" { for _, a := range n.Attr { if a.Key == "href" { links = append(links, a.Val) } } } for c := n.FirstChild; c != nil; c = c.NextSibling { links = visit(links, c) } return links } func main() { for _, url := range os.Args[1:] { links, err := findLinks(url) if err != nil { fmt.Fprintf(os.Stderr, "findlinks2: %v\n", err) continue } for _, link := range links { fmt.Println(link) } } } // findLinks performs an HTTP GET request for url, parses the // response as HTML, and extracts and returns the links. func findLinks(url string) ([]string, error) { resp, err := http.Get(url) if err != nil { return nil, err } if resp.StatusCode != http.StatusOK { resp.Body.Close() return nil, fmt.Errorf("getting %s: %s", url, resp.Status) } doc, err := html.Parse(resp.Body) resp.Body.Close() if err != nil { return nil, fmt.Errorf("parsing %s as HTML: %v", url, err) } return visit(nil, doc), nil } // <===================OUTPUT===================> // go run main.go http://www.baidu.com // https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F // http://www.nuomi.com/?cid=002540 // http://news.baidu.com // http://www.hao123.com // http://map.baidu.com
- 这个例子里面有四个地方进行了return,每次都是一对儿返回值,前三次都是返回了http
和html package里面的error "转发"了一下:
- 第一中情况下:err没有被"添加评论",直接进行了转发
- 第二钟情况下:err被"包裹"了一些context信息,使用fmt.Errorf
- 第二钟情况下:err也是被"包裹"了一些context信息
- 我们要自己关闭resp.Body,因为Go的gc是只收集unused内存,而其他的系统资源,还是 要我们自己手动explicitly进行回收.
- 我们前面见到过,range或者map的返回值是两个,我们如果不想使用第二个值,可以省略
package main import ( "fmt" "os" ) func main() { m := make(map[int]int) m[18] = 18 v, ok := m[18] fmt.Println(v, ok) v = m[18] fmt.Println(v) arr := [3]int{1, 2, 3} for i, v := range arr { fmt.Println(i, v) } for i := range arr { fmt.Println(i) } os.Exit(0) } // <===================OUTPUT===================> // 18 true // 18 // 0 1 // 1 2 // 2 3 // 0 // 1 // 2
- 但是这只适用于range和map,在函数返回值为两个的情况下,必须两个返回值都设置!
https://play.golang.org/p/ci0M8R1-dX
package main import ( "fmt" "os" ) func getTwo() (int, int) { return 1, 2 } func main() { ////////////////////////////////////////////////////////////////////////////// // // ./three.go:14: multiple-value getTwo() in single-value context // // a := getTwo() // // fmt.Println(a) // ////////////////////////////////////////////////////////////////////////////// os.Exit(0) }
- 当然了,如果某个函数的返回值和自己一样,我们也可以通过return这个函数来满足返回
值的类型要求
// Note: 这里的error不是变量是类型! Go里面的函数返回值可以只有类型,没有变量名! func findLinksLog(url string) ([]string, error) { log.Printf("findLinks %s", url) return findLinks(url) }
- 同样的我们也可以把某个函数所有的返回值(是一个tuple)作为另外函数的参数,这是
很容易就能"联想"到的,但是实际情况运用的不多.只有一个地方经常使用,那就是Println
因为Println可以允许不同长度的参数!下面两组代码具有相同的效果:
log.Println(findLinks(url)) links, err := findLinks(url) log.Println(links, err)
- 对于多返回值函数来说,每一个返回值的名字都特别重要,因为特别合适的名字能起到
文档的作用
func Split(path string) (dir, file string)
- 当然了,有些情况下,我们的返回值名字是固定的:
- 对于错误原因多种的情况下,用名字err来返回类型为Error的错误
- 对于错误原因肯定只有一种的情况下,用名字bool来返回类型为boolean的错误
- Go中还有所谓的bare return,就是说你的return的value有name的话(也就是分配了变 量内存),我可以不"显式"的返回, 而是function block结束的时候named return value 是啥,就返回啥.
- 但是由于bare return很容易会造成理解上的偏差,所以我们完全不鼓励大家使用bare return
Errors
- 有些function总是完成它们的工作.比如strings.Contains,还有strconv.FormatBool
- 还有一些function总是返回成功,只要它们的precondition能够得到满足.而如果"不成功 就成仁"(preconditoin不满足,以time.Date为例, 第二个参数为nil), 函数就会直接panic
- 但是还有更多更多的函数,其成功与否依赖太多的factor,都不是程序员可以控制的.比 如IO操作的时候,文件是否存在这种是程序员无法控制的,所以我们必须要为可能存在的 错误负责.
- 因为这些错误是可以预期的,那么这些错误其实也是package API里面重要的组成部分, 从另外一个较多讲,我们可以把这些错误当做expected behavior(Java里面把这种估 计到的错误叫做checked exception)
- 在Go里面,如果一个function的excepted behavior里面包括某些错误,那么这个function
会返回一个额外的result(一般来说是最后一个)
- 如果"expected error"只有一种的情况下,我们可以只返回一个Boolean类型(一般叫
做ok)
value, ok := cache.Lookup(key) if !ok { // ...cache[key] does not exist }
- 当然了,大多数情况下expected error不可能只有一种情况,这个时候,就不能再返回
boolean类型了,而要返回error类型(是一个interface type,一般叫做err!).
// src/builtin/builtin.go type error interface { Error() string }
- 如果"expected error"只有一种的情况下,我们可以只返回一个Boolean类型(一般叫
做ok)
- 前面看到了error(注意是小写)类型是一种interface类型(绝大多数情况下其变量名是err):
- 如果没有错误,那么err就是nil
- 如果有错误, 那么err就是non-nil,可以通过打印'Error()函数的返回值(类型为 string)'来打印错误信息.
- 我们注意到,我们总是可以使用fmt.Println(),或者fmt.Printf()来打印error类型的
结果.因为error这个interface只有一个函数Error(),我们很容易想到package fmt肯定
是在内部调用了Error()来打印仅有的那个错误信息,答案是肯定的,源代码如下.我看到
Stringer interface也是在这里处理的(直接调用其String()函数)
// src/fmt/print.go if p.fmt.sharpV { if stringer, ok := p.arg.(GoStringer); ok { handled = true defer p.catchPanic(p.arg, verb) // Print the result of GoString unadorned. p.fmt.fmt_s(stringer.GoString()) return } } else { // If a string is acceptable according to the format, see if // the value satisfies one of the string-valued interfaces. // Println etc. set verb to %v, which is "stringable". switch verb { case 'v', 's', 'x', 'X', 'q': // Is it an error or Stringer? // The duplication in the bodies is necessary: // setting handled and deferring catchPanic // must happen before calling the method. switch v := p.arg.(type) { case error: handled = true defer p.catchPanic(p.arg, verb) p.fmtString(v.Error(), verb) return case Stringer: handled = true defer p.catchPanic(p.arg, verb) p.fmtString(v.String(), verb) return } } }
- 我们说,我们返回的err只要满足error interface接口就可以了.但是我们终究要有一
个地方来'实例化'我们的返回值的(也就是Error()的返回值string终究是有地方要来放
置的):
- 我们一般的做法是使用内置的error type类型生成器fmt.Errorf.我们发现类型为
*errors.errorString
https://play.golang.org/p/-50myryX42
package main import ( "fmt" "os" ) func main() { e := fmt.Errorf("%s", "hello") fmt.Printf("%T, %s\n", e, e) os.Exit(0) } // <===================OUTPUT===================> // *errors.errorString, hello
- 这个*errors.errorString从名字来看,就是一个errors package下面的没有export
的一个struct类型,它实现了Error()这个函数,所以也就implement了error interface
// file: src/fmt/print.go // Errorf formats according to a format specifier and returns the string // as a value that satisfies error. func Errorf(format string, a ...interface{}) error { return errors.New(Sprintf(format, a...)) } // file: src/errors/erros.go // Package errors implements functions to manipulate errors. package errors // New returns an error that formats as the given text. func New(text string) error { return &errorString{text} } // errorString is a trivial implementation of error. type errorString struct { s string } func (e *errorString) Error() string { return e.s }
- 所以我们看到了,是errorString的指针类型*errorString满足了error interface,而 不是errorString类型.所以New()函数返回的也是带取地址符'&'的结果
- 我们可以自己写一个error返回,毫无违和感,我们这里没有用指针,也可以.具体什么
时候用指针,什么时候不用,请看后面的章节
https://play.golang.org/p/uckj_EHalu
package main import ( "fmt" "os" ) type hfengError struct { s string } func (h hfengError) Error() string { return h.s } func adder(i int) (ret int, err error) { ret = i + 1 err = hfengError{"Error by hfeng"} return } func main() { ret, err := adder(18) fmt.Println(ret, err) os.Exit(0) } // <===================OUTPUT===================> // 19 Error by hfeng
- 我们一般的做法是使用内置的error type类型生成器fmt.Errorf.我们发现类型为
*errors.errorString
https://play.golang.org/p/-50myryX42
- 一旦返回值的error不为nil,那么其返回的前面的值也就不再可以被信任了.在某些特殊 情况下,返回值可能是有意义的.比如,读取一个文件,Reqad()返回它已经成功读取的byte 个数,并且外加一个描述错误的err.这个成功读取的byte个数就是可以被信任的.但是毕 竟这是特例,我们需要在函数的文档里面说清楚
- 如今大部分的语言都是把"可以预见的错误"以exception的方式来抛出来,而Go却并不是 它还是沿袭了比较古老的返回值的方式来处理.
- 后面的章节我们会看到,Go的确是有exception机制的.但是Go的exception机制是用来报
告"不可以预见的错误"的,这种unexpected的错误往往意味着bug.和Java比较起来:
- Go使用返回值来报告expected error; Java使用checked exception
- Go使用exception(panic&recover)来处理unexpcted error; Java使用unchecke exception.大多数情况下,这预示着代码存在着bug
- Go不使用exception来处理expected error有它自己的考虑,因为这意味着excepted error(routine error)以一种更加复杂的方式展现给用户(充满着不相关的stack trace)
- Go使用了if和return等"常规手段"来对付expected error,这增强了调用者对错误处理 的重视程度.这正是Go设计者想要的
Error Handling Stratgies
- 每当function call返回错误的时候,caller有责任和义务去check这个返回值,并且做 出相应的举动.根据情况的不同,处理方式会有五种:
Propagate the error
- 这样是最常见的处理方式,也就是把被调用者的错误,通过包装添加些信息以后,变成
调用者的错误
A failure in a subroutine becomes a failure of the calling routine.
- 被调用者的错误,要经过包装,这个包装是添加些信息.这个信息是需要才添加.没有
就不需要添加的,也就是说A failure in a subroutine directly becomes a failure
of the calling routine.:
- 首先看一个不需要添加额外信息的例子.我们findlinks第一步会使用http.Get来获
取某个url的信息.如果失败的话,因为我们并没有做什么其他的事情.http.Get的
error信息就已经包含了全部错误解释.这种情况下,我们直接把被调用者的error信
息返回,作为我们(调用者)的错误信息
resp, err := http.Get(url) if err != nil { return nil, err }
- 而html处理resp.Body出错的时候.其err就不能覆盖调用者的错误了,我们的调用者
除了调用Parse出错了,我们有两件事情没有在这个err里面体现.第一我们是parse
的时候出的问题,第二我们parse出错的url是什么.所以我们用Errorf里面加了两条
第一parsing,第二url
doc, err := html.Parse(resp.Body) resp.Body.Close() if err != nil { return nil, fmt.Errorf("parsing %s as HTML: %v", url, err) }
- 首先看一个不需要添加额外信息的例子.我们findlinks第一步会使用http.Get来获
取某个url的信息.如果失败的话,因为我们并没有做什么其他的事情.http.Get的
error信息就已经包含了全部错误解释.这种情况下,我们直接把被调用者的error信
息返回,作为我们(调用者)的错误信息
- 这样做的好处是,(最终)我们的main会得到如下一条chain的错误链(例子从NASA acident
来)
genesis: crashed: no parachute: G-switch failed: bad relay orientation
- 这个例子如下的两个特点,易于我们使用grep来对它们进行分析
- 没有大写字母
- 没有换行符
- 当然,这种良好的error message的返回离不开我们每次都"认真并且简洁有效"的自己 书写error message.才能让总体的message简洁有效.
- Go的standard library是书写良好error message的典范.比如os package里面的函数 一旦出现了error message,其错误信息不仅仅包含错误原因(比如permission denied, no shu directory等等), 同时还包括了自己所处理的file name.所以caller并不需要 自己再使用fmt.Errorf来再次"自己处理"error了.(也就是和上面例子1. http.Get处 理方法一致)
- 讲了这么多,我们可以来总结一下
当我们调用f(x)的时候,如果出现了error. error message里面必须包 括operation f失误的信息,以及参数x的信息
Transient or unpredictable problem
- 第二种比较常见的处理error的策略就是:处理某些transient错误(或者是unpredictable
错误, 也是一个策略)的时候, 我们可以重试几次,当然每次要等一段random的时间.
下面就是这样一个例子
func WaitForServer(url string) error { const timeout = 1 * time.Minute deadline := time.Now().Add(timeout) for tries := 0; time.Now().Before(deadline); tries++ { _, err := http.Head(url) if err == nil { return nil // success } log.Printf("server not responding (%s); retrying...", err) time.Sleep(time.Second << unit(tries)) } return fmt.Errorf("server %s failed to respond after %s", url, timeout) }
Print the error and stop the program gracefully
- 第三种情况是,caller可以打印错误,然后直接关闭这个program.这种情况下只能用于
main函数, library是不建议这样做的.
package main func main() { // ... if err := WaitForServer(url); err != nil { fmt.Fprintf(os.Stderr, "Site is down: %v\n", err) os.Exit(1) } }
- 一种达到那个如上同样,但是更便捷的方法是使用log.Fatalf.千万不要在web server
里面使用log.Fatalf
if err := WaitForServer(url); err != nil { log.Fatalf("Site is down: %v\n", err) }
- 使用log是对于long-running server来说特别好的一个方式(对于interactive tool)
来说就有点过了.它一般会打印当前的时间等信息,还可以统一设置prefix,以及控制
打印的格式.还能只打印某种程度以上的错误
package main import ( "fmt" "log" "os" ) func main() { log.SetPrefix("Test logging:") log.Printf("OK by now") log.Printf("By now we have time") log.SetFlags(0) // suppress the display of the date and time log.Fatalf("Site is down") fmt.Println() os.Exit(0) } // <===================OUTPUT===================> // Test logging:2017/01/20 17:51:15 OK by now // Test logging:2017/01/20 17:51:15 By now we have time // Test logging:Site is down // exit status 1
Just to log and then continue
- 第四种情况是error并不影响我们的程序,比如ping某个ip失败,那么"只记录error,
而不返回,让程序继续运行下去".
- 可以只用log来记录(所有log函数都会加回车,如果原字符没有回车的情况下)
if err := Ping(); err != nil { log.Printf("ping failed: %v; networking disabled", err) }
- 也可以使用fmt打印到standard error stream
if err := Ping(); err != nil { fmt.Fprintf(os.Stderr, "ping failed: %v; networking disabled\n", err) }
- 可以只用log来记录(所有log函数都会加回车,如果原字符没有回车的情况下)
Sefely ignore entirely
- 第五种情况,就是直接忽略错误,连log一下都不需要!!用到的地方不多.比如删除
temporary文件夹, 这个行为就算我们做失败了,每过一段时间,操作系统也会像清理
zombie进程一样清理temporary文件夹,所以出了error,连记录都不需要
dir, err := ioutil.TempDir("", "scratch") if err != nil { return fmt.Errorf("failed to create temp dir: %v", err) } // ...use temp dir... // ignore errors; $TMPDIR is cleaned periodically by os os.RemoveAll(dir)
Summary
- Go的error处理有自己的节奏:往往是先处理failure,然后处理success的情况.所以 如果failure导致了function返回,那么succes也不会运行到,这种情况下,success也 不必再else里面处理了,直接在和'if处理error'一层就好
End of File (EOF)
- 大多数情况下, function返回的错误是给end user的,而不是给中间的程序(intervening
program)的.这句话怎么理解呢?
- 就是说我们的error的返回值一般是来告诉使用者错误信息的,这个信息是一个描述性 的语句,一般是string,没有enum类型的概念.因为其目的就是传递这个错误信息(string)
- 而如果给intervening program来用,必须有类型概念.要不然if判断是什么错误的时 候,总不能以string是内容来判断是什么错误吧.
- 仅有不多的几个给intervening program来用的错误中,最具代表性的是EOF错误,这个错
误可以用来告诉用户,你对IO的读取完成了,但是没有读取到你要求的个数,因为文件到
头了.用户要区分'普通的读取错误(比如文件不存在)'和'读取到文件最后的错误(EOF)'
这个时候,我们就要给'读取到文件最后的错误(EOF)'一个类型了,让它能够应用到if里
面
package io import "errors" // EOF is the error returned by Read when no more input is available. var EOF = errors.New("EOF")
- 在if里面的使用方法如下
in := bufio.NewReader(os.Stdin) for { r, _, err := in.ReadRune() if err == io.EOF { break // finish reading } if err != nil { return fmt.Errorf("read failed: %v", err) } // ...use r ... }
Function Values
- 在Go语言里面, function是first-class value. 它拥有和value一样的特质:
- 拥有自己的类型(type)
- 可以assigned给变量
- 可以传递给函数
- 可以从函数中返回
- function之所以叫first-class value,是因为它还具有value不具有的额外优势:它可以 被调用!
- 下面是一个把function"当成变量使"的例子
https://play.golang.org/p/TjOB996DUS
package main import "fmt" func square(n int) int { return n * n } func negative(n int) int { return -n } func product(m, n int) int { return m * n } func main() { f := square fmt.Println(f(3)) f = negative fmt.Println(f(3)) fmt.Printf("%T\n", f) //////////////////////////////////////////////////////////////////////////////////////////////// // // cannot use product (type func(int, int) int) as type func(int) int in assignment // // // f = product // //////////////////////////////////////////////////////////////////////////////////////////////// } // <===================OUTPUT===================> // 9 // -3 // func(int) int
- 上面的例子中,我们可以看到,一个function的类型是由两部分组成的:
- 所有的参数的类型
- 返回值的类型
- function type的zero value为nil(也就是你声明了这个函数,但是却没有函数"实体")
这种情况下,调用zero value的function会产生panic
var f func(int) int f(3) // panic: call of nil function
- 但是zero value function可以和nil相互比较. 但是function之间不可以相互比较!这个
特性是和slice一样的.这种情况下一般都是预示着类型是reference特性:可以和nil(空
指针)比较,但是由于指针类型不能进行算术计算,所以相互之间不能比较
var f func(int) int if f != nil { f(3) }
- function可以作为参数传入另外的function,这样一来,我们可以传给"另外的function"
一个behavior, 而不仅仅是像传统参数一样,传递一个data.
Function values let us parameterize our functions over not just data, but behavior too
- 标准库里面就有很多实用函数参数,引入"behavior"的例子,比如strings.Map就会把自
己第一个参数的"behavior",应用到第二个参数上.下面的例子中behavior就是把char
的ascii值'加一'
https://play.golang.org/p/SsRw6jo7Gf
package main import ( "fmt" "strings" ) func add1(r rune) rune { return r + 1 } func main() { fmt.Println(strings.Map(add1, "ABC")) fmt.Println(strings.Map(add1, "WXY")) } // <===================OUTPUT===================> // BCD // XYZ
- 前面5.2中的findLinks中,实用了一个helper函数visit来对某个节点访问,并且遍历这
些个节点.代码如下
func main() { doc, err := html.Parse(os.Stdin) for _, link := range visit(nil, doc) { fmt.Println(link) } } func visit(links []string, n *html.Node) []string { // 节点处理逻辑 if n.Type == html.ElementNode && n.Data == "a" { for _, a := range n.Attr { if a.Key == "href" { links = append(links, a.Val) } } } // 遍历逻辑 for c := n.FirstChild; c != nil; c = c.NextSibling { links = visit(links, c) } return links }
- 从代码中我们可以发现,html.Parse()返回的只是一个指针,其他全部的工作都visit做
的,visit做了两件事情:
- 对每个节点进行处理
- 负责遍历节点
- 使用function value的话,我们可以做到把上面的两个逻辑区分开,helper只负责遍历,
而对每个节点的处理,可以使用传入的function value里面的logic
// forEachNode calls the functions pre(x) and post(x) for each node // x in the tree rooted at n. Both functions are optional. // pre is called before the children are visited (preorder) and // post is called after (postorder) func forEachNode(n *html.Node, pre, post func(n *html.Node)) { if pre != nil { pre(n) } for c := n.FirstChild; c != nil; c = c.NextSibling { forEachNode(c, pre, post) } if post != nil { post(n) } }
- 这个新的函数forEachNode比原来的逻辑还先进了一步:它允许访问node之前和访问node
之后调用的函数不一样.我们可以利用这个有点设计如下两个函数startElement和endElement
来分别打印HTML的elment的开始和结束tag,比如<b>…</b>
import ( "fmt" "golang.org/x/net/html" ) var deptrh int func startElement(n *html.Node) { if n.Type == html.ElementNode { fmt.Printf("%*s<%s>\n", depth*2, "", n.Data) depth++ } } func endElement(n *html.Node) { if n.Type == html.ElementNode { depth-- fmt.Printf("%*s</%s>\n", depth*2, "", n.Data) } }
- 这里我们又遇到一个fmt.Printf'花式打印'的新例子:使用%*s来打印字符串pad到固定
长度,比如下面就是一个简单的使用例子,注意. 第一个参数提供pad后的长度.第二个参
数提供打印的字符串的长度.如果第一参数小于第二个参数,那么就相当于不起作用
https://play.golang.org/p/k-TL4FBinE
package main import ( "fmt" "os" ) func main() { fmt.Printf("%*s\n", 2, "fix") fmt.Printf("%*s\n", 3, "fix") fmt.Println("--------------------") fmt.Printf("%*s\n", 4, "fix") fmt.Printf("%*s\n", 5, "fix") fmt.Printf("%*s\n", 6, "fix") os.Exit(0) } // <===================OUTPUT===================> // fix // fix // -------------------- // fix // fix // fix
- 我们整个例子的效果如下
// Outline prints the outline of an HTML document tree. package main import ( "fmt" "net/http" "os" "golang.org/x/net/html" ) func main() { for _, url := range os.Args[1:] { outline(url) } } func outline(url string) error { resp, err := http.Get(url) if err != nil { return err } defer resp.Body.Close() doc, err := html.Parse(resp.Body) if err != nil { return err } //!+call forEachNode(doc, startElement, endElement) //!-call return nil } //!+forEachNode // forEachNode calls the functions pre(x) and post(x) for each node // x in the tree rooted at n. Both functions are optional. // pre is called before the children are visited (preorder) and // post is called after (postorder). func forEachNode(n *html.Node, pre, post func(n *html.Node)) { if pre != nil { pre(n) } for c := n.FirstChild; c != nil; c = c.NextSibling { forEachNode(c, pre, post) } if post != nil { post(n) } } //!-forEachNode //!+startend var depth int func startElement(n *html.Node) { if n.Type == html.ElementNode { fmt.Printf("%*s<%s>\n", depth*2, "", n.Data) depth++ } } func endElement(n *html.Node) { if n.Type == html.ElementNode { depth-- fmt.Printf("%*s</%s>\n", depth*2, "", n.Data) } } //!-startend // <===================OUTPUT===================> // $ go run outline.go http://gopl.io // <html> // <head> // <meta> // </meta> // <title> // </title> // <script> // </script> // <link> // </link> // <style> // </style> // </head> // <body> // <table> // <tbody> // <tr> // <td> // <a> // <img> // </img> // </a> // <br> // </br> // <div> // <a> // <img> // </img>
Anonymous Functions
- 在Go中, named function只可以定义在package level,这是C语言开始就有的设定.没有 考虑到函数式编程
- 如果希望在任何expression能够出现的地方都能定义function,那么我们不能再使用named function,而要使用匿名函数anonymous function
- 匿名函数(anonymous function)是一个value,其表现形式是function literal
所谓function literal就是
A function literal is written like a function declaration, but without a name following the func keyword
- 比如上面ascii值"加一"的例子,我们就可以使用function literal来实现
strings.Map(func(r rune) rune {return r + 1}, "ABC")
- 匿名函数的优点不是仅仅'少些了一个函数名'这么简单,使用function literal定义的
匿名函数,可以访问"包括匿名函数的scope"里面的变量. 这是所有的"函数式"程序必定
有的一个特性
https://play.golang.org/p/V7GQNwaV6Q
package main import "fmt" func squares() func() int { var x int return func() int { x++ return x * x } } func main() { f := squares() fmt.Println(f()) fmt.Println(f()) fmt.Println(f()) fmt.Println(f()) } // <===================OUTPUT===================> // 1 // 4 // 9 // 16
- 上面的squares 返回了另外一个function作为返回值(类型是func()int)
- 对squares()函数的调用会创建一个local variable x,并且返回了类型为func()int类 型的函数(而且是个匿名函数),并赋值给变量f
- 变量f就指向了返回的匿名函数,每次f的调用,都会给x加一并且返回其二次方
- 需要注意的是,我们再次调用squares()的情况下,就会重新创建local variable x,进而
重新从1开始一次计算
https://play.golang.org/p/xayBRQZygX
package main import "fmt" func squares() func() int { var x int return func() int { x++ return x * x } } func main() { f := squares() fmt.Println(f()) fmt.Println(f()) f2 := squares() fmt.Println(f2()) fmt.Println(f2()) } // <===================OUTPUT===================> // 1 // 4 // 1 // 4
- squares的例子证明function values不仅仅是code,它同时还有state.这个state就是存 在于enclosing scope(也就是包裹匿名函数的scope)里面的local variable.
- 由于function value 可以和enclosing scope里面的local variable有所联系,那么 也就可以认为anonymous function 始终保留着对enclosing scope里面局部变量的"引用", 那么这么看来,function类型被分类为"reference type"也就不足为奇了.
- Go实现这种function value的方法叫做closure.其实这也是绝大部分的functional语言 实现function value的方法
- 这里我们再次看到了,在Go里面,variable的lifetime不是由scope决定的:squares里面的 局部变量x会一直存在着(被f调用),即便是squares已经成功返回了.这也预示着使用GC 的语言更容易实现function value
- 下面我们来看一个更加学术化的问题:假设我们有一个map里面的key是某一节课,其value 是其key所需要的"先导课程"(必须先上完某些value里面的课,才能开始key的课),要求 输出一个满足"先导"要求的上课顺序
- 这种问题在计算机科学里面叫做"拓扑排序(topological sorting)",prerequisite信 息组成了一个有向图(directed graph):每个node都是一个课程,并且每个课程所需要的 "前导"课程和它之间,会有一条边.这个图是不会存在环的
- 我们可以使用depth-first的方法通过如下代码来完成遍历
package main import ( "fmt" "sort" ) var prereqs = map[string][]string{ "algorithms": {"data structures"}, "calculus": {"linear algebra"}, "compilers": { "data structures", "formal languages", "computer organization", }, "data structures": {"discrete math"}, "databases": {"data structures"}, "discrete math": {"intro to programming"}, "formal languages": {"discrete math"}, "networks": {"operating systems"}, "operating systems": {"data structures", "computer organization"}, "programming languages": {"data structures", "computer organization"}, } func topoSort(m map[string][]string) []string { var order []string seen := make(map[string]bool) var visitAll func(items []string) visitAll = func(items []string) { for _, item := range items { if !seen[item] { seen[item] = true visitAll(m[item]) order = append(order, item) } } } var keys []string for key := range m { keys = append(keys, key) } sort.Strings(keys) visitAll(keys) return order } func main() { for i, course := range topoSort(prereqs) { fmt.Printf("%d:\t%s\n", i+1, course) } } // <===================OUTPUT===================> // 1: intro to programming // 2: discrete math // 3: data structures // 4: algorithms // 5: linear algebra // 6: calculus // 7: formal languages // 8: computer organization // 9: compilers // 10: databases // 11: operating systems // 12: networks // 13: programming languages
- 这里我们使用了匿名函数(所以就可以随心所欲的使用enclosing scope的局部变量,有 种我们原来随意使用global variable的快感!), 而且匿名函数还运用了递归.由于匿名 函数本身没有名字,所以递归的时候,如果不给一个变量名的话,会找不到内存地址.所以 我们这里在递归以前,都使用变量来存储了我们的匿名函数
- 我们的findLink也可以使用匿名函数来做递归,代码如下
// Extract makes an HTTP GET request to the specified URL, parses import ( "fmt" "net/http" "golang.org/x/net/html" ) // the response as HTML, and returns the links in the HTML document. func Extract(url string) ([]string, error) { resp, err := http.Get(url) if err != nil { return nil, err } if resp.StatusCode != http.StatusOK { return nil, fmt.Errorf("getting %s: %s", url, resp.Status) } doc, err := html.Parse(resp.Body) resp.Body.Close() if err != nil { return nil, fmt.Errorf("parsing %s as HTML: %v", url, err) } var links []string visitnode := func(n *html.Node) { if n.Type == html.ElementNode && n.Data == "a" { for _, a := range n.Attr { if a.Key != "href" { continue } link, err := resp.Request.URL.Parse(a.val) if err != nil { continue // ignore bad URLS } links = appenda(links, link.String()) } } } forEachNode(doc, visitNode, nil) // need only pre function return links, nil }
- 我们刚才讲到的拓扑排序(topoSort)其实是一种对graph的深度优先遍历,而在互联网 应用里面还存在着一种对graph的广度优先遍历,就是爬虫(crawler)
- 下面的代码就简单描述了如何做一个广度优先遍历,从而实现爬虫
// Findlinks3 crawls the web, starting with the URLs on the command line. package main import ( "fmt" "log" "os" "gopl.io/ch5/links" ) //!+breadthFirst // breadthFirst calls f for each item in the worklist. // Any items returned by f are added to the worklist. // f is called at most once for each item. func breadthFirst(f func(item string) []string, worklist []string) { seen := make(map[string]bool) for len(worklist) > 0 { items := worklist worklist = nil for _, item := range items { if !seen[item] { seen[item] = true worklist = append(worklist, f(item)...) } } } } //!-breadthFirst //!+crawl func crawl(url string) []string { fmt.Println(url) list, err := links.Extract(url) if err != nil { log.Print(err) } return list } //!-crawl //!+main func main() { // Crawl the web breadth-first, // starting from the command-line arguments. breadthFirst(crawl, os.Args[1:]) } //!-main // <===================OUTPUT===================> // $ go run findlinks.go https://golang.org // https://golang.org // https://golang.org/ // https://golang.org/doc/ // https://golang.org/pkg/ // https://golang.org/project/ // https://golang.org/help/ // https://golang.org/blog/ // http://play.golang.org/ // https://tour.golang.org/ // https://golang.org/dl/ // https://blog.golang.org/ // https://developers.google.com/site-policies#restrictions // https://golang.org/LICENSE // https://golang.org/doc/tos.html // http://www.google.com/intl/en/policies/privacy/ // https://golang.org/doc/install // https://code.google.com/p/go-tour/
- 一般来说,广度优先遍历都是使用FIFO的队列来实现的,这里通过把worklist设置成nil 然后返回新的worklist来完成两点FIFO
Caveat: Capturing Iteration Variables
- 这一小节,我们主要来看一下由于Go的lexical scope(使用了匿名函数才会有)带来的 一些surprising result, 了解这些有助于防止写出错误代码.因为这些问题即便是有 经验的程序员也难以避免
- 看下面的这个例子, 这个例子要我们先要创建一系列的文件夹,而我们需要在后面把这
些文件夹一一删除掉
var rmdirs []func() for _, d := range tempDirs() { dir := d // NOTE: necessary! os.MkdirAll(dir, 0755) // clean up functions are stored in one slice, will be called // one by one later rmdirs = append(rmdirs, func() { // Use anonymous function here os.RemoveAll(dir) }) } // ... do some work... for _, rmdir := range rmdirs { rmdir() // clean up one by one }
- 上面版本"诡异"的地方在于其在每个loop里面都又申请了一个local variable dir而
不是像下面这样,直接使用for里面声明的变量
var rmdirs []func() for _, dir := range tempDirs() { os.MkdirAll(dir, 0755) rmdirs = append(rmdirs, func() { os.RemoveAll(dir) }) }
- 这两者的差异在哪里呢?
- 第二种方法等于多个不同的匿名函数共享了一个局部变量dir,最后一一调用的时候 会不断的删除同一个文件夹
- 第一种方法等于多个不同的匿名函数每个函数都有一个自己的局部变量dir,最后一 一删除的时候,不会影响其他function
- 经过这个例子我们会看到出现这种问题一般需要两个条件:
- 使用多个匿名函数,所以才有可能多个函数引用同一个变量
- delay 匿名函数的调用. 这里的例子是我们根据业务需要些出来的.而在Go语言的 机制里面,defer和go statement是两个最经常使用延时调用的地方,也是容易出现 这个错误的地方
- 上面这个例子中使用d和dir的方法当然是可以的,但是也可以定义一个inner的dir,虽
然看起来奇怪,倒是也可以工作
for _, dir := range tempDirs() { dir := dir // declares inner dir, initialized to outer dir // ... }
- 这个错误不是range才有的,所有的loop都可能会有类似的问题
var rmdirs []func() dirs := tempDirs() for i := 0; i < len(dirs); i++ { os.MkdirAll(dirs[i], 0755) // ok rmdirs = append(rmdirs, func() { os.RemoveAll(dirs[i]) // NOTE: incorrect! }) }
Variadic Functions
- 变长参数是一个非常重要的特性,这个特性在c里面就有, go里面支持就不足为奇了.常 见的例子就是fmt.Printf. 它需要一个固定的参数,后面允许有个数不等的参数
- 变长参数在go里面的要求是"在声明的时候"最后一个参数的类型为"…<Type>", 在调
用的时候,实参可以对应零个或者多个.
https://play.golang.org/p/3kZckk5wPc
package main import "fmt" func sum(vals ...int) int { total := 0 for _, val := range vals { total += val } return total } func main() { fmt.Println(sum()) fmt.Println(sum(3)) fmt.Println(sum(1, 2, 3, 4)) } // <===================OUTPUT===================> // 0 // 3 // 10
- 上面例子的Go编译器内部实现机制是:
- caller创建一个array,把参数都拷贝进去(个数一定,那就用数组就好了)
- caller把指向整个array的slice给予function
- function就可以使用某个slice来代表自己的不定参数了
- 上面的三个步骤,不使用"不定参数"也可以实现,只不过稍微麻烦了一点.需要注意的是
我们把一个slice"赋值给"不定参数"做实参"的时候,需要在变量右边加上"…",而虚
参则是放在type的左边!
values := []int{1, 2, 3, 4} fmt.Println(sum(values...)) // "10"
- …int类型的(虚参)行为和 integer slice类型[]int是一样的,但是还是不同的类型
https://play.golang.org/p/Kp1ZaorD9b
package main import "fmt" func f(...int) {} func g([]int) {} func main() { fmt.Printf("%T\n", f) fmt.Printf("%T\n", g) } // <===================OUTPUT===================> // func(...int) // func([]int)
- variadic function最主要的应用场景就是字符串format,一般来说其参数是interface{}
类型.这就意味着函数可以接受任何类型的输入(然后使用反射来判断其真正的类型)
func errorf(linenum int, format string, args ...interface{}) { // ... }
Deferred Function Calls
- 为了了解defer的必要性,先来看一个场景:还是我们的findLinks,我们用http.Get来获
取url的内容,然后把这个内容作为input传递给html.Parse.这个流程能够顺利进行的前
提,是我们的html类型是text/html,如果是image, plain text等类型的话,就得不到想
要的结果了,所以我们的例子会进行防御性的'排除'
func title(url string) error { resp, err := http.Get(url) if err != nil { return err } // Check Content-Type is HTML(e.g., "text/html; charset=utf-8"). ct := resp.Header.Get("Content-Type") if ct != "text/html" && !strings.HasPrefix(ct, "text/html") { resp.Body.Close() return fmt.Errorf("%s has type %s, not text/html", url, ct) } doc, err := html.Parse(resp.Body) resp.Body.Close() if err != nil { return fmt.Errorf("parsing %s as HTML: %v", url, err) } visitNode := func(n *html.Node) { if n.Type == html.ElementNode && n.Dat == "title" && n.FirstChild != nil { fmt.Println(n.FirstChild.Data) } } forEachNode(doc, visitNode, nil) return nil }
- 我们注意到上面由于防御性编程的要求,resp.Body.Close()在代码里面出现了两次,这 样能够保证在failure的情况下,资源也不会泄露.但是随着代码数目的增长,上述repeat code会成为一大隐患.我们迫切的需要一种"无论成败与否"请记得帮我释放资源(不是 内存)的办法.这个办法在Go里面就是defer
- Go使用defer来进行deferred function call,因为go是自动释放内存的语言,但是却不
能自动释放其他资源,比如打开的文件(或者网络链接),下面一个就是"自动"释放打开
文件的例子. 文件就是一种资源
package ioutil func ReadFile(filename string) ([]byte, error) { f, err := os.Open(filename) if err != nil { return nil, err } defer f.Close() return ReadAll(f) }
- 把mutex看成一种资源的话,defer也是一样工作的
var mu sync.Mutex var m = make(map[string]int) func lookup(key string) int { mu.Lock() defer mu.Unlock() return m[key] }
- defer statement还可以用来在debug的时候设置"on entry"和"on exit"动作,这种设置 非常的巧妙.是使用defer调用一个函数,而这个函数是通过另外一个函数的返回值返回 的.
- 另外一个函数可以在其内部设置时间戳,表示'开始'就运行.其返回值会被defer标记,从而
在'最后'运行
https://play.golang.org/p/U1fFJc9jYq
package main import ( "fmt" "time" ) func bigSlowOperation() { defer trace("bigSlowOperation")() // don't forget the extra parentheses time.Sleep(3 * time.Second) } func trace(msg string) func() { start := time.Now() fmt.Printf("enter \t%s\n", msg) return func() { fmt.Printf("exit \t%s after (%v)", msg, time.Since(start)) } } func main() { bigSlowOperation() } // <===================OUTPUT===================> // enter bigSlowOperation // exit bigSlowOperation after (3.00531379s)
- defer还有一个特性是和匿名函数联手,其原理基于如下几个事实:
- deferred function是在return statement更新了result variable以后才运行的
- 匿名函数是可以访问local variable
- named result也是函数的local variable
- 所以,我们可以使用defer 匿名函数的办法来打印某个函数的参数和结果
package main import ( "fmt" "os" ) func double(x int) (result int) { defer func() { fmt.Printf("double(%d) = %d\n", x, result) }() return x + x } func main() { _ = double(4) os.Exit(0) } // <===================OUTPUT===================> // double(4) = 8
- 对于double来说,这个trick看起来是很多余的,但是对于多个参数返回的情况下,好好 利用这个trick,会有意想不到的结果
- 我们设置可以使用这个trick来设置可以"更改"函数返回值,来创建新的函数(由于defe
r的代价高昂,这并不是一个好主意,只是可行而已)
package main import "fmt" func double(x int) int { return x + x } func triple(x int) (result int) { defer func() { result += x }() return double(x) } func main() { fmt.Println(triple(4)) } // <===================OUTPUT===================> // 12
- 我们的defer只是运行在return之后,但并不是在function execution的"最最后",所以
在loop里面运行defer需要额外的关注.下面的代码有可能会耗尽所有的文件描述符,因
为因为在处理完所有文件之前(函数返回前,defer的运行周期是以当前函数记),没有文
件会被关闭
for _, filename := range filenames { f, err := os.Open(filename) if err != nil { return err } defer f.Close() // NOTE: risky; could run out of file descriptors // ...process f... }
- 一个更改办法是把loop主体(包括defer)放入到一个function里面,由于defer是在enclosing
它的function结束前运行,所以这会带来更安全的体验
for _, filename := range filenames { if err := doFile(filename); err != nil { return err } } func doFile(filename string) error { f, err := os.Open(filename) if err != nil { return err } defer f.Close() // ...process f... }
- 下面的例子是我们fetch的变体,把结果写入到文件系统,而不是standard output
// Fetch downloads the URL and returns the // name and length of the local file. func fetch(url string) (filename string, n int64, err error) { resp, err := http.Get(url) if err != nil { return "", 0, err } defer resp.Body.Close() local := path.Base(resp.Request.URL.Path) if local == "/" { local = "index.html" } f, err := os.Create(local) if err != nil { return "", 0, err } n, err = io.Copy(f, resp.Body) // Close file, but prefer error from Copy, if any. // IT IS err == nil NOT closeErr == nil if closeErr := f.Close(); err == nil { err = closeErr } return local, n, err }
- 这个例子中的defer resp.Body.Close我们是非常熟悉了,但是我们发现上面例子中,我
们并没有使用defer去调用f.Close.这是基于如下原因
在很多文件系统中(代表是NFS), write错误并不会马上报告,而是会在文件close的 时刻才报告.而且这些error是不能忽略的 - 换句话说,resp.Body的close错误是可以忽略的,os.Create得到的f的close错误是不能 忽略的.这种情况下不能使用defer来处理f,因为defer不去管返回值
- io.Copy和f.Close都有错误的情况下,优先报io.Copy的错误,因为它是先发生的
Panic
- Go在编译期会发现很多错误,但是某些错误,比如out-fo-bounds array access, 或者 nil pointer dereference需要在run time进行处理. 而Go在runtime遇到这种问题的 方法,就是直接panic
- 一个panic发生的时候:
- 所有normal execution停止
- deferred function马上执行!
- 程序crash并且会产生一个log message. 这个log message 包括panic value(提示 某种类型的错误)和每个goroutine一个的stack trace.对于debug错误,这些信息往往 足够了
- 不是所有的panic都来自于runtime,也可以"自制"panic,也就是直接调用panic函数,这个
函数接受任何类型的参赛
// buitin func panic(v interface{})
- 我们调用panic 函数的时候,往往是impossible情景发生的时候.这种情景"不应该"被
逻辑语句走到
switch s := suit(drawCard()); s { case "Spades": case "Hearts": case "Diamonds": case "Clubs": default: panic(fmt.Sprintf("invalid suit %q", s)) // Joker? }
- 需要牢记的是panic总是发生在runtime,你可以调用panic,但是你调用panic是为了向 上面的例子一样提供"额外"的重要信息(上面的default不写的话,遇到Joker也是会panic 的).
- 如果不能提供"额外"的信息,那么就让runtime去panic好了,log message足够你去调试
的.下面的例子就不适合panic.因为x是nil这件事情runtime抛出panic的时候,几乎肯
定会写到log message里面
func Reset(x *Buffer) { if x == nil { panic("x is nil") // unnecessary! } x.elements = nil }
- 对于一个程序来说,所有的panic都应该看做是一种bug.在健壮的系统里面,所有的expected error,比如错误的input,错误配置,failing IO,都应该使用error value来处理,而不是 使用panic!
- 除了提供额外的信息以外,使用panic的另外一个情景就是"强制性检查error value,不 对就爆出bug".
- 看下面的正则表达式的例子,正则表达式如果错误的话,会返回error value
package regexp func Compile(expr string)(*Regexp, error) { /* ... */ }
- 而如果正则表达式的字符串不是用户输入的,而是在代码里面的,那么如果写错了,意味 着这是一个bug,而不是仅仅是error value.针对这种非常特殊的情况,我们引入了一个 帮助函数MustCompile
- 这个Must已经在Go里面是一种命名规范了,表示输入如果不对,就是个bug,不要墨迹啥
error value的事了,因为bug了的话,后面都不会是对的.也就是说这不是expected error
而是expected bug
package regexp func MustCompile(expr string) *Regexp { re, err := Compile(expr) if err != nil { panic(err) } return re }
- 这个Must wrapper函数调用起来,就非常的轻松了,不用去管error.字符串错了,就直接
抛出panic
var httpSchemeRE = regexp.MustCompile(`^https?:`) // "http:" or "https:"
- 当panic发生的时候,所有的deferred function都会以相反的顺序被调用.所谓相反的
顺序,就是从stack里面最压的最里的函数开始,到main函数为止.换句话说,就是先defer
的函数后调用!
package main import "fmt" func main() { f(3) } func f(x int) { fmt.Printf("f(%d)\n", x+0/x) // panics if x == 0 defer fmt.Printf("defer %d\n", x) f(x - 1) } // <===================OUTPUT===================> // f(3) // f(2) // f(1) // defer 1 // defer 2 // defer 3 // panic: runtime error: integer divide by zero // // goroutine 1 [running]: // panic(0x90b40, 0xc42000a0a0) // /usr/local/Cellar/go/1.7.1/libexec/src/runtime/panic.go:500 +0x1a1 // main.f(0x0) // /Users/hfeng/tmp/panic_demo.go:10 +0x1c8 // main.f(0x1) // /Users/hfeng/tmp/panic_demo.go:12 +0x18f // main.f(0x2) // /Users/hfeng/tmp/panic_demo.go:12 +0x18f // main.f(0x3) // /Users/hfeng/tmp/panic_demo.go:12 +0x18f // main.main() // /Users/hfeng/tmp/panic_demo.go:6 +0x2a // exit status 2
- 后面我们会看到,panic的结果并不一定是termination!我们可以使用recover来兜底
- 从调试的角度讲,我们的runtime package提供了一个函数Stack,可以打印dump stack
信息到IO,下面的例子就是通过defer来在panic的时候打印stack
package main import ( "fmt" "os" "runtime" ) func main() { defer printStack() f(3) } func f(x int) { fmt.Printf("f(%d)\n", x+0/x) // panics if x == 0 defer fmt.Printf("defer %d\n", x) f(x - 1) } func printStack() { var buf [4096]byte n := runtime.Stack(buf[:], false) os.Stdout.Write(buf[:n]) } // <===================OUTPUT===================> // f(3) // f(2) // f(1) // defer 1 // defer 2 // defer 3 // goroutine 1 [running]: // main.printStack() // /Users/hfeng/tmp/panic_demo.go:22 +0x6e // panic(0x911c0, 0xc42000a0a0) // /usr/local/Cellar/go/1.7.1/libexec/src/runtime/panic.go:458 +0x243 // main.f(0x0) // /Users/hfeng/tmp/panic_demo.go:15 +0x1c8 // main.f(0x1) // /Users/hfeng/tmp/panic_demo.go:17 +0x18f // main.f(0x2) // /Users/hfeng/tmp/panic_demo.go:17 +0x18f // main.f(0x3) // /Users/hfeng/tmp/panic_demo.go:17 +0x18f // main.main() // /Users/hfeng/tmp/panic_demo.go:11 +0x46 // panic: runtime error: integer divide by zero // // goroutine 1 [running]: // panic(0x911c0, 0xc42000a0a0) // /usr/local/Cellar/go/1.7.1/libexec/src/runtime/panic.go:500 +0x1a1 // main.f(0x0) // /Users/hfeng/tmp/panic_demo.go:15 +0x1c8 // main.f(0x1) // /Users/hfeng/tmp/panic_demo.go:17 +0x18f // main.f(0x2) // /Users/hfeng/tmp/panic_demo.go:17 +0x18f // main.f(0x3) // /Users/hfeng/tmp/panic_demo.go:17 +0x18f // main.main() // /Users/hfeng/tmp/panic_demo.go:11 +0x46 // exit status 2
- 值得注意的是runtime.Stack打印了非常全面的stack信息,这得益于Go的panic机制会 在unwind stack之前,调用defer函数,所以defer 函数运行的时候,stack还没有被破坏
- 关于unwind的定义,我们可以看下C++中的定义
In the C++ exception mechanism, control moves from the throw statement to the first catch statement that can handle the thrown type. When the catch statement is reached, all of the automatic variables that are in scope between the throw and catch statements are destroyed in a process that is known as stack unwinding.
Recover
- 对于绝大多数的出现panic的程序来说来说,放弃这个程序可能是最明智的做法.但是有 时候,我们也是需要"拯救"这个panic,或者至少说"暂时拯救",先做些clean up,然后 再退出.这个"拯救"的过程,叫做recover
- 一个最常见的,即便是出现了panic,但是也不应该退出的情况,就是web server:当web
server内部出现错误的时候:
- 如果在development模式下,我们应该显示500错误,把错误报给client.典型的例子比 如rails里面某个变量没定义,rails会在网页端打印这个错误.server不会关闭
- 如果在production模式下,我们应该给用户抛出500.server也不会关闭
- 让built-in的recover函数其作用,是要有先决条件的:
- recover是调用在一个defer function里面的. 而这个defer function是嵌入在另外 一个正常的function里面的(一般通过匿名函数,一来使用local variable,二来马上 调用)
- 另外一个正常的function发生了panic
- 下面就是这样一个例子,我们注意到recover()函数的返回值就是panic函数的参数.如果
需要,我们还可以在后面加上runtime.Stack的信息
https://play.golang.org/p/cZgdOiJzcQ
package main import ( "fmt" "os" ) func Parse(input string) (output int, err error) { defer func() { if p := recover(); p != nil { err = fmt.Errorf("internal error: %v", p) } }() panic("panic throw this error") } func main() { fmt.Println(Parse("hello")) os.Exit(0) } // <===================OUTPUT===================> // 0 internal error: panic throw this error
- 一旦recover起了作用(证明发生了panic),那么正常的流程(导致panic的流程)就不再走 了,而是完成defer 函数以后,直接就返回了!defer是最后一道工序.所以我们的函数使 用了named result,从而可以更容易的更改返回值
- 如果recover被调用在任何其他的地方,它没有任何的效果,返回值总是nil
- 不分青红皂白的从panic里面recover是一种不可靠的行为,因为在panic以后,一个package
的variable state是无定义的(或者没有documented的):或许
- data structure是不完整的
- file(network connection也是一种file)打开了却没有close
- lock获取了,却没有释放
- 实际上我们是以一行log来代替了crash,会掩盖很多问题
- 对同一个package内部的panic进行recover,是一种处理unexpected error非常好的方式 但是需要注意的是:决不允许revoer 其他package的panic
- 同时public API不应该抛出panic,而应该以error来表示错误
- 你也不能对'你不能控制的function里面的panic'来进行recover,比如caller provided
callback.虽然这么说,但是我们在写web server的时候,却恰恰recover了用户提供的
函数里面的panic:
- net/http package提供的web server会把incoming request分发到用户提供的handler function里面
- 这种用户提供的handler function是不受控制的,用户可能写出runtime panic的程序, 当然也可以直接panic
- web server不会让用户handler里面的panic kill掉进程(我们是web server不能没事 就被kill),而是recover这个panic, 打印stack trace,并且继续server的服务
- 需要注意的是,这个特例是为了实践上的方便,但是它的确有泄露资源的风险,并且让failed handler处在了一种unspecified的状态.可能会导致后续的错误.这也是为什么500的错 误总需要修复的原因
- 说了这么多,recover最理想的用法是:recover那些panic本来就希望用户能够recover的
情况(这种情况不会多见).为了能够区分这些不多见的panic,我们可以为这些panic的情
况设计一些特别的type,作为panic的参数,也就是recover的返回值.我们可以通过检查
返回值的类型来决定这个recover的合理性:
- 如果recover返回值的类型的我们理想的,那么就返回错误来代替kill process
- 否则,直接再次抛出panic+recover的返回值!记住不是简单的kill process,而是还原 原来的panic
- 下面的例子就是一个根据recover返回值类型来决定是否把panic降级为error的例子:判
断HTML文档是不是有两个<title> element(当然,从某种程度上来说,有两个<title>有
点类似expected error,这里我们是为了讲述用法,所以可能有些违背我们前面使用error
处理expected error的理念)
func soleTitle(doc *html.Node) (title string, err error) { type bailout struct{} defer func() { switch p := recover(); p { case nil: // no panic case bailout{}: // "expected" panic err = fmt.Errorf("multiple title elements") default: panic(p) // unexpected panic; carry on panicking } }() // Bail out of recursion if we find more than one non-empty title forEachNode(doc, func(n *html.Node) { if n.Type == html.ElementNode && n.Data == "title" && n.FirstChild != nil { if title != "" { panic(bailout{}) // multiple title elements } title = n.FirstChild.Data } }, nil) if title == "" { return "", fmt.Errorf("no title element") } return title, nil }
Chapter 06: Methods
- 从1990年代开始,OOP就已经开始主导了programming 领域.Go也不例外
- 从我们Go开发者的角度上讲, object其实就是一个value(或者varaible), 只不过这个value 是拥有method.
- method呢,其实是一种特殊的function, 只不过这个function和一个particular type相 关联.
- 所谓OOP,其实就是用户通过'使用method来'表示data structure的property和operation. 而不需要直接访问data structure
Method Declarations
- 前面说过了, method和function只有一处不同,就是和一个Type 相关联, Go的设计就让 这个关联体现在method的declare的时候(而不是像java一样写在class的定义处)
- 下面第就是一个method的例子, 多出来的(p Point),就是method的receiver
package geometry import "math" type Point struct{ X, Y float64 } // traditional function func Distance(p, q Point) float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) } func (p Point) Distance(q Point) float64 { return math.Hypot(q.X-p.x, q.Y-p.Y) }
- 在Go里面,我们不使用一个特殊的变量(比如this或者self)来作为receiver,而是像其 他变量一样取一个name,因为这个receiver经常被使用,所以我们可以选择一个比较短 的变量名,一般是Type的第一个小写字母,这里就是p
- 声明的时候,我们的receiver是在前面的,这是为了"映射"我们使用时候的情况,使用的
时候type也是在前面的
p := Point{1, 2} q := Point{4, 6} fmt.Println(Distance(p, q)) // "5" function call fmt.Println(p.Distance(q)) // "5", method call
- p.Distance是一个表达式,叫做selector.名字的来历是因为这个表达式select了type Point的method Distance.因为selector也会被用在struct type的选择中,比如p.X,所 以,显然我们没办法定义一个名为X的method
- method的类型里面包含了type,所以不同的type可以看成是method的namespace,那么很
显然,不同的type可以拥有名字相同的method.所以我们的type Path也可以拥有一个叫
做Distance的函数
// A Path is a jorney connecting the points with straight lines. type Path []Point // Distance returns the distance traveled along the path. func (path Path) Distance() float64 { sum := 0.0 for i := range path { if i > 0 { sum += path[i-1].Distance(path[i]) } } return sum }
- Path说白了就是named slice type,不是像Point一样的struct类型,但是我们依然可以 为它定义method.和其他oo语言不同的是,Go允许method和任意类型相联系
- 实践证明,为简单的类型(比如number, string, slice, map甚至是function)定义函数
是非常方便的,需要注意的是可以为本package里面所有的named type定义method,只要
这个named type其本质不是如下两种:
- pointer类型
- interface类型
- point和path都有Distance method,但是两者是完全不同的类型,虽然path.Distance内 部使用了point.Distance
- 下面是一个使用path.Distance的例子,我们来计算一个三角形的边长
package main import ( "fmt" "math" ) type Point struct{ X, Y float64 } func (p Point) Distance(q Point) float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) } type Path []Point func (path Path) Distance() float64 { sum := 0.0 for i := range path { if i > 0 { sum += path[i-1].Distance(path[i]) } } return sum } func main() { perim := Path{ {1, 1}, {5, 1}, {5, 4}, {1, 1}, } fmt.Println(perim.Distance()) } // <===================OUTPUT===================> // 12
- 前面说过,不同的type里面可以有同名的method,但是相同的type里面肯定不能有同名的 method.而且method的类型里面是包括type的,所以不需要写出PathDistance这种函数名, 这里我们就引出了method相比于常规function的第一个优点:method的名字要短一点.
- 当我们在package外面来调用的时候,method的优势会更大一点,因为它可以使用更短的
名字,并且不需要package name
import "gopl.io/ch6/geometry" perim := geometry.Path{{1, 1}, {5, 1}, {5, 4}, {1, 1}} fmt.Println(geometry.PathDistance(perim)) // "12", standalone function fmt.Println(perim.Distance()) // "12", method of geometry.Path
Methods with a Pointer Receiver
- 因为function的调用,会copy每一个argument,所以如果出现下面两种情况,我们一般会选择
使用pointer参数:
- 函数的参数"过大",copy一次很耗费内存
- 希望更改这个参数
- 我们可以把method的associated type看成是另外一个paramter,那么很明显,我们也需
要再遇到上述两种情况的时候,把associated type设置为pointer类型,比如
func (p *Point) ScaleBy(factor float64) { p.X *= factor p.Y *= factor }
- 这个method的名字就是(*Point).ScaleBy啦,这个括号是必须的如果没有括号,表达式会 被解析成*(Point.ScaleBy)
- 使用Type作为method 的associated Type是常见现象,但是如果使用Pointer来作为method
的associated type,那么务必要要让所有的method都使用Pointer来作为associate type,
否则的话,使用(*Pointer).method_a之后,再使用(*Pointer).method_b发现不能调用,
是非常奇怪的行为.
In a realistic program, convention dictates that if any method of Point has a pointer receiver, then all methods of Point should have a pointer receiver, even ones that don't strictly need it!
- 当然了,我们这里一个Type,不同的method_a,method_b一会使用Type, 一会使用pointer, 是为了让我们学习两者区别
- 在receiver declaration里面,只能出现named type(比如Pointer)或者pointer to named
type(比如*Pointer),为了避免误解,method declaration是不允许使用"自己本身是pointer
type"的named type的,比如
type P *int func (p) f() { /* ... */ } // compile error: invalid receiver type
- (*Point).ScaleBy method在使用的时候,有如下几种方法:
- 提供一个*Point类型的receiver
r := &Pointer{1, 2} r.ScaleBy(2) fmt.Println(*r) // "{2, 4}"
- 提供一个Pointer类型变量, 然后取这个变量的地址,再调用
p := Point{1, 2} pptr := &p pptr.ScaleBy(2) fmt.Println(p) // "{2, 4}"
- 或者更干脆的使用(&p)
p := Point{1, 2} (&p).ScaleBy(2) fmt.Println(p) // "{2, 4}"
- 提供一个*Point类型的receiver
- 三种方法无一例外的都非常的麻烦,所以Go不得已做了一个语言级别的支持.那就是
如果method的associated Type是*Point类型, 我们可以在使用的时候 提供Point类型, 编译器(注意是编译器)会把Point类型变量p换成(&p) - 注意,这种方法的本质是加"取地址符&", 所以只有有地址的类型,比如struct, array,
或者slice element(比如perim),如果一个receiver无法取得地址,那么是无法适用
的!比如下面的情况Point{1, 2}是一个struct literal,它是没有地址的,编译器就无能
为力
Point{1, 2}.ScaleBy(2) // compile error: can't take address ofPoint literal
- 反之,如果我们定义的时候是associated type是普通Point类型,那么我们"总是"可以使 用*Point类型的instance的变量来调用它. 这是因为对于任意指针变量,我们总可以取 到它指向的地址里面的value.我们编译器每次帮我们插入(*)而已,只不过对于pointer 来说(*p)总成功(即便是Nil也没事, 后面会介绍)
- 我们来总结一下所有的三种情况,因为它们很容易混淆:
- 情况1: receiver argument和receiver paramter拥有一样的类型(要么都是T,要么都
是*T),这种情况下编译器什么都不做
Point{1, 2}.Distance(q) // Point pptr.ScaleBy(2) // *Point
- 情况2: receiver argument是类型T,而receiver parameter是类型*T.这种情况下编
译器要做取地址操作(只有有内存地址的varaible才能做这个操作,struct literal不可以)
p.ScaleBy(2) // implicit (&p)
- 情况3: receiver argument是类型*T, 而receiver 是类型T,这种情形编译器要做"引
用"(dereference)来获取地址里面的value(所有的地址都能获取value,nil也可以,所
有这个操作总能成功)
pptr.Distance(q) // implicit (*pptr)
- 情况1: receiver argument和receiver paramter拥有一样的类型(要么都是T,要么都
是*T),这种情况下编译器什么都不做
- 总结完毕,再来说说不同receiver parameter的具体情况, receiver paramter是定义时
候使用的类型.这个类型其实是相当于method的第"零"个参数
- 如果receiver parameter是类型T(不是*T),那么就意味着第零个参数在method每次调用的
时候,都会复制一遍.所以类型T的instance t是可以到处export(使用)的,因为即便
别人不小心调用了t的method,也不会对t造成影响.典型的例子是time.Duration,它
其实就是一个float64,因为所有的receiver type都是Duration.所以可以放心的到处
使用.设置是作为参数
https://play.golang.org/p/Ifqp5TccIy
package main import ( "fmt" "os" "time" ) func display(inp time.Duration) { fmt.Println(inp) } func main() { display(23) os.Exit(0) } // <===================OUTPUT===================> // 23ns
- 但是如果receiver parameter是pointer receiver的话,那么你就要避免把t到处拷贝 了.因为这个instance到了别的用户手里,一旦调用其method,有可能会更改instance 内部的状态
- 如果receiver parameter是类型T(不是*T),那么就意味着第零个参数在method每次调用的
时候,都会复制一遍.所以类型T的instance t是可以到处export(使用)的,因为即便
别人不小心调用了t的method,也不会对t造成影响.典型的例子是time.Duration,它
其实就是一个float64,因为所有的receiver type都是Duration.所以可以放心的到处
使用.设置是作为参数
https://play.golang.org/p/Ifqp5TccIy
Nil Is a Valid Receiver Value
- 有些function允许其pointer的paramter为nil,而method receiver其实就是一个参数 而已,所以method也肯定可以允许其receiver为nil. 特别是对于某些receiver type来 说,nil是其meaningful的zero value
- 比如,下面的例子中nil的*IntList代表empty list.这种情况下,你需要在你的文档中
清晰的描述出nil可以作为receiver.如下.
// An IntList is a Linkedlist of integers. // A nil *IntList represents the empty list. type IntList struct { Value int Tail *IntList } // Sum returns the sum of the list elements. func (list *IntList) Sum() int { if list == nil { return 0 } return list.Value + list.Tail.Sum() }
- 我们再来看看net/url package里面Values的例子
package url // Values maps a string key to a lit of values. type Values map[string][]string // Get returns the first value associated withe the given key, // or "" if there are none. func (v Values) Get(key string) string { if vs := v[key]; len(vs) > 0 { return vs[0] } return "" } // Add ads the values to key. // It appends to any existing values associated with key. func (v Values) Add(key, value string) { v[key] = append(v[key], value) }
- 对于Values来说,即便是nil也是一个合法的receiver(当Get的时候),当Add的时候就
会报panic错误了
package main import ( "fmt" "net/url" "os" ) func main() { m := url.Values{"lang": {"en"}} m.Add("item", "1") m.Add("item", "2") fmt.Println(m.Get("lang")) fmt.Println(m.Get("q")) fmt.Println(m.Get("item")) fmt.Println(m["item"]) m = nil fmt.Println(m.Get("item")) ///////////////////////////////////////////////////// // // panic: assignment to entry in nil map // // m.Add("item", "3") // ///////////////////////////////////////////////////// fmt.Println("--------------------------") os.Exit(0) } // <===================OUTPUT===================> // en // // 1 // [1 2] // // --------------------------
- 这里的url.Values是一个map type,所以url.Values.Add所做的操作立马就能被caller
发现,因为改变的是map指向的内容,我们map的地址并没有改变.我们method没有如下这
种功能
m = nil - 换句话说,如果我们有个一个method叫做url.Values.Dosomething来设置m为nil,是不
会成功的
func (v Values) Dosomething(key, value string) { v = nil }
Composing Types by Struct Embedding
- 下例中的ColoredPoint, 我们本可以把ColoredPoint定义成三个field的struct,但是
我们没有这么做,而是把一个Point 嵌入到了ColoredPoint里面.
import "image/color" type Point struct{X, Y float64} type ColoredPoint struct { Point Color color.RGBA }
- embedding会让我们的ColoredPoint拥有Point所有的field,所以ColoredPoint使用Point
的field的时候还可以完全不"mention" Point
var cp ColoredPoint cp.X = 1 fmt.Println(cp.Point.X) // "1" cp.Point.Y = 2 fmt.Println(cp.Y) // "2"
- 不仅仅是field,在使用Point的method的问题上, ColoredPoint也是一点也不含糊.ColoredPoint
可以使用Point的所有method,即便ColoredPoint根本没有声明过它们.这个规则是和field一样的
red := color.RGBA{255, 0, 0, 255} blue := color.RGBA{0, 0, 255, 255} var p = ColoredPoint{Point{1, 1}, red} var q = ColoredPoint{Point{5, 4}, blue} fmt.Println(p.Distance(q.Point)) // "5" p.ScaleBy(2) q.ScaleBy(2) fmt.Println(p.Distance(q.Point)) // "10"
- 注意!这里ColoredPoint能够使用Point的method
并"不是"因为Point是ColoredPoint的base class, 而恰恰相反, ColoredPoint "包含"了Point, 所以这里是一个 composition over inheritance 的例子!
- 从传统的oo语言来的读者可能会把Point看做是ColoredPoint的derived class,或者把 ColoredPoint看成是"is a" Point,但是这里其实不是!这里是ColoredPoint "has a" Point
- 这里编译器其实帮助我们实现了两个wrapper函数,让我们的p可以直接调用Distance,而
不需要p.Point.Distance()
func (p ColoredPoint) Distance(q Point) float64 { return p.Point.Distance(q) } func (p *ColoredPoint) ScaleBy(factor float64) { p.Point.ScaleBy(factor) }
- 当Point.Distance被调用的时候(如上),它的receiver不是p,而是p.Point,所以p.Point 是不会有机会接触到ColoredPoint的
- 匿名field也可以是pointer to a named type.这种情况下,pointer指向的named type
的所有的field和method也会被"收编",例子如下
type ColoredPoint struct { *Point Color color.RGBA } p := ColoredPoint{&Point{1, 1}, red} q := ColoredPoint{&Point{5, 4}, blue} fmt.Println(p.Distance(*q.Point)) // 5 q.Point = p.Point // p and q now share the same Point p.ScaleBy(2) fmt.Println(*p.Point, *q.Point) // "{2 2} {2 2}"
- 一个struct还可以有多个匿名field,比如
type ColoredPoint struct { Point color.RGBA }
- 这样一来,新的类型instance就拥有:
- 所有Point的函数
- 所有color.RGBA的函数
- 所有后来定义在ColoredPoint上面的函数
- method是有类型的funciton,这个类型必须是named type(比如Point),或者是pointer to named type(*Point),但是由于有embedding,我们可以让unnamed struct type拥有 method
- 下面是一个常规的例子:我们使用package level变量mutex来保护一个map
var ( mu sync.Mutex mapping = make(map[string]string) ) func Lookup(key string) string { mu.Lock() v := mapping[key] mu.Unlock() return v }
- 下例和上例在功能上相同,但是却巧妙的借助匿名field让unnamed struct(cache)也有
了method
var cache = struct { sync.Mutex mapping map[string]string } { mapping: make(map[string]string), } func Lookup(key string) string { cache.Lock() v := cache.mapping[key] cache.Unlock() return v }
Method Values and Expressions
- 一般来说,我们都是1select method然后马上2call method,比如p.Distance(), 但因
为在go里面function是first class citizen. 和function实质一样的method其实也是
"first-class object",也可以被存储起来作为变量(method value), 之后这个变量调
用的时候,就不需要receiver信息了(因为receiver其实是method的第0个参数)
p := Point{1, 2} q := Point{4, 6} distanceFromP := p.Distance // method value fmt.Println(distanceFromP(q)) // "5" var origin Point // {0, 0} fmt.Println(distanceFromP(origin)) // "2.236..."
- method value对如下情况非常有用:package API需要一个function value,普通的function
value当然能够满足要求,比如time.AfterFunc第二个参数为function value,第一个参
数设置多久后调用第二个参数:
package main import ( "fmt" "os" "time" ) func main() { fv := func() { fmt.Println("display") } // AfterFunc waits for the duration to elapse and then calls f // in its own goroutine. It returns a Timer that can // be used to cancel the call using its Stop method. timer := time.AfterFunc(3*time.Second, fv) defer timer.Stop() // So we have to sleep at least 4 seconds to see AfterFunc's goroutine to run time.Sleep(4 * time.Second) os.Exit(0) } // <===================OUTPUT===================> // display
- 但是如果不是普通函数,而是一个method的情况下,如果没有method value,写法是这样的
type Rocket struct {/* */} func (r *Rocket) Launch() {/* */} r := new(Rocket) time.AfterFunc(10 * time.Second, func() {r.Launch()})
- 拥有method value的写法是这样的
time.AfterFunc(10 * time.Second, r.Launch)
- 和method value相对的是method expression. 这个"对立"是对在"对象上":
- 对于method value来说,其instance是已经指定了的
- 而对于method expression来说,其仅仅制定了receiver Type,具体使用哪个instance
还需要在"使用的时候",把receiver放成第一个参数.这再次证明了method的type就是
其第零个参数
https://play.golang.org/p/9RcF9JYoAR
package main import ( "fmt" "math" "os" ) type Point struct{ X, Y float64 } func (p Point) Distance(q Point) float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) } func main() { p := Point{1, 2} q := Point{4, 6} fmt.Println(p.Distance(q)) distance := Point.Distance fmt.Println(distance(p, q)) fmt.Printf("%T\n", Point.Distance) os.Exit(0) } // <===================OUTPUT===================> // 5 // 5 // func(main.Point, main.Point) float64
- Method expression在如下情况时候非常有用:需要使用value来代表method中的一个,但
是instance还没有确定(调用的时候才确定,作为method expression的第一个参数)
package main import "fmt" type Point struct{ X, Y float64 } func (p Point) Add(q Point) Point { return Point{p.X + q.X, p.Y + q.Y} } func (p Point) Sub(q Point) Point { return Point{p.X - q.X, p.Y - q.Y} } type Path []Point func (path Path) TranslateBy(offset Point, add bool) { var op func(p, q Point) Point if add { op = Point.Add } else { op = Point.Sub } for i := range path { // Call either path[i].Add(offset) or path[i].Sub(offset). path[i] = op(path[i], offset) } } func main() { paths := Path{Point{1, 2}, Point{2, 4}} fmt.Println(paths) paths.TranslateBy(Point{1, 1}, true) fmt.Println(paths) paths.TranslateBy(Point{1, 1}, false) fmt.Println(paths) } // <===================OUTPUT===================> // [{1 2} {2 4}] // [{2 3} {3 5}] // [{1 2} {2 4}]
Example: Bit Vector Type
- 在Go里面,并没有专门的set类型,我们一般使用map[T]bool类型来替代set,这种方式非 常的灵活,但是有时候我们需要效率更加高的set,也就是常说的bit vector(使用一个bit 的1或者0来替代bool,而set的值则都数值不大的'正整数')
- 下面就是我们使用golang来实现的bit vector
https://play.golang.org/p/gNSsBvrF6T
package main import ( "bytes" "fmt" ) // An IntSet is a set of small non-negative integers. // Its zero value represents the empty set. type IntSet struct { words []uint64 } // Has reports whether the set contains the non-negative value x. func (s *IntSet) Has(x int) bool { word, bit := x/64, uint(x%64) return word < len(s.words) && s.words[word]&(1<<bit) != 0 } // Add adds the non-negative value x to the set. func (s *IntSet) Add(x int) { word, bit := x/64, uint(x%64) for word >= len(s.words) { s.words = append(s.words, 0) } s.words[word] |= 1 << bit } // UnionWith sets s to the union of s and t. func (s *IntSet) UnionWith(t *IntSet) { for i, tword := range t.words { if i < len(s.words) { s.words[i] |= tword } else { s.words = append(s.words, tword) } } } // String returns the set as a string of the form "{1 2 3}". func (s *IntSet) String() string { var buf bytes.Buffer buf.WriteByte('{') for i, word := range s.words { if word == 0 { continue } for j := 0; j < 64; j++ { if word&(1<<uint(j)) != 0 { if buf.Len() > len("{") { buf.WriteByte(' ') } fmt.Fprintf(&buf, "%d", 64*i+j) } } } buf.WriteByte('}') return buf.String() } func main() { var x, y IntSet x.Add(1) x.Add(144) x.Add(9) fmt.Println(x.String()) y.Add(9) y.Add(42) fmt.Println(y.String()) x.UnionWith(&y) fmt.Println(x.String()) fmt.Println(x.Has(9), x.Has(123)) } // <===================OUTPUT===================> // {1 9 144} // {9 42} // {1 9 42 144} // true false
- 我们使用一个slice的unsigned integer来存储我们所有的bit(注意前面说过,不是没 有负数才使用unsigned integer,而是这种bitmap的情况才会使用unsigned integer)
- 我们的uint64 slice是连续的内存空间,从slice第一个bit开始,第i个bit为1就表示 第ith个正整数在bit vector里面
- 因为我们slice里面的每个成员都是64bit的,所以为了找到某个正整数x是否在bit vector
里面:
- 我们要使用x/64来确定它可能在slice的哪个index里面
- 我们要使用x%64来确定是否在特定slice成员的某个bit上
- UnionWith实现的是一个bitmap的 OR操作
- 注意,我们实现了String函数,后面我们会看到实现了如下interface的函数,fmt都会特别对待
type Stringer interface { String() string }
- 这里有一个陷阱:为了和其他的函数一致,我们把method String()的receiver也定义成
了*IntSet的.这导致我们的fmt其实只能对*IntSet自动调用String().如果不注意这一
点,fmt的结果可能会很奇怪
fmt.Println(&x) // {1 9 42 144} fmt.Println(x.String()) // {1 9 42 144} fmt.Println(x) // {[4398046511618 0 65536]}
- 第一句fmt会自动调用instance的String()函数
- 第二句x虽然不是*IntSet类型,但是编译器会自动加上取地址符给x,这就变成了(&x).String()
- 第三句,因为x不是*IntSet类型,而IntSet类型也没有String(),所以fmt就打印了其struct 内部的String()
Encapsulation
- 我们使用过一个object的时候,如果这个object的某些variable和method是我们无法接 触(inaccessible)到的,那么我们就说这个object是封装好的(encapsulated).继承,封 装,多肽是oo编程的三大法宝
- 我们前面说过,一个package里面的name是否能够被package外面看到,取决于这个name的 首字母是不是大写
- 同样的规则适用于:一个struct里面的name是否能够被struct外面看到,取决于这个name的 首字母是不是大写
- struct的这个特性可以让我们在go里面去封装object:所有不想被外人看到的,作为struct 里面的首字母小写的变量
- 这也是为什么前面的IntSet例子中,我们的IntSet其实只有一个单独的[]uint64类型的
域,我们还是要给它"造"一个struct.因为这样完美的对data进行了封装!
type IntSet struct { words []uint64 }
- 如果不考虑封装性,我们可以写出实际上完全等价的另外一个版本
type IntSet []uint64
- 但是这个版本的问题在于没有封装代表内部状态的data,其他package的client可以随便 读取"并改动"这个slice!
- 另外一个特别重要的区别是,无论是package还是struct也好,以首字母来判断是否对"外"
封装的这个方法.里面用来判断"外"的机制不同,在Go看来,本package都是"里",只有其
他package才算外!而其他语言一般是以type为界限的:
- 在Go里面,本package可以方便的访问private的data
https://play.golang.org/p/MA0489_jNs
package main import ( "fmt" "os" ) type test struct{ x int } func main() { t := test{23} fmt.Println(t.x) os.Exit(0) } // <===================OUTPUT===================> // 23
- 在Cpp里面,只有type自己可以访问自己的private data
#include <iostream> using namespace std; struct Test { int x; private: int y; }; int main(int argc, char *argv[]) { Test t; t.x = 23; cout << t.x << endl; //////////////////////////////////////////////////////////////////////////////// // // /Users/hfeng/tmp/main.cc:16:7: error: 'y' is a private member of 'Test' // // t.y = 24; // //////////////////////////////////////////////////////////////////////////////// return 0; } // <===================OUTPUT===================> // 23
- 在Go里面,本package可以方便的访问private的data
https://play.golang.org/p/MA0489_jNs
- OO语言(包括Go)并不是反对exported field,而是说一旦这个field export了以后,就不 能改动了,考虑到未来可能出现的变化,真正需要exported 一个field的情况并不是特别多.
- 其中一个情况就是time.Duration,通过把time.Duration(实质是一个int64)给export
出来,我们可以把所有对于int64可行的操作,都用在time.Duration上面,减轻了很多的负担
type Duration int64 const ( minDuration Duration = -1 << 63 maxDuration Duration = 1<<63 - 1 ) // Common durations. There is no definition for units of Day or larger // to avoid confusion across daylight savings time zone transitions. // // To count the number of units in a Duration, divide: // second := time.Second // fmt.Print(int64(second/time.Millisecond)) // prints 1000 // // To convert an integer number of units to a Duration, multiply: // seconds := 10 // fmt.Print(time.Duration(seconds)*time.Second) // prints 10s // const ( Nanosecond Duration = 1 Microsecond = 1000 * Nanosecond Millisecond = 1000 * Microsecond Second = 1000 * Millisecond Minute = 60 * Second Hour = 60 * Minute )
- 使用方法如下
https://play.golang.org/p/5dCFcdCTR_
package main import ( "fmt" "os" "time" ) func main() { const day = 24 * time.Hour fmt.Println(day.Seconds()) os.Exit(0) } // <===================OUTPUT===================> // 86400
- 我们前面还有两个例子:
- 一个是没有使用封装的Path
type Path []Point
- 另外一个是使用了封装的IntSet
type IntSet struct { words []uint64 }
- 一个是没有使用封装的Path
- 对于Path来说,我们所有对slice可行的操作,都能对Path来进行,但是对于IntSet来说, 因为加了struct,系统无法识别出来其内部只有一个slice,所以append等操作都是无法 直接运用在IntSet上面的
- 而对于IntSet来说,它也有优点,就是内部现在是使用了uint64,但是我们以后可以选择 新的其他的类型来表示,内部实现的改动不会影响到已有代码
Chapter 07: Interfaces
- interface 类型表示了其他类型的一种"抽象"和"概括", 总结起来就是: inteface的存 在,让我们的function更加的flexible和adaptble,因为interface不和特定的implementation 相关
- 很多OO语言都有interface,但是go的interface是一种叫做"暗自符合(satisfied
implicitly)"的方式存在的,换句话说
go并没有必要"显式"的声明一个concrete type符合哪些interface, 只要你有相应的函数,你就"自动"符合某个interface
- 这种设计带来一个极大的便利:你可以创建一个新的interface, 而已经存在的concrete type自动的就"符合"了这个interface的要求,但是我们不需要去更改这个concrete type 对于定义在lib里面的我们无法更改的concrete type, 新定义一个interface,lib就能 适应,那是非常美妙的!
Interfaces as Contracts
- 我们前面所有的类型都是concrete type.它们的特点是:
- 列出了自己内部的exact的value, 以及自己支持的operation
- 提供一系列的method,可以使用这些method来操作自己的类型
- 一旦你拥有了一个concrete type你就非常准确的知道它是什么,以及它可以做什么
- 我们这里要介绍的,就是interface type了, 它和concrete type相比,其只展现了第二 个部分,就是method,而且还不是全部的method,只是类型一部分的method.如果你拥有 一个interface type,你只能知道它"至少能做什么",而对它内部,则一无所知
- 我们整本书都在使用两个函数fmt.Printf把拼接好的字符串写到standord output, 另
外一个是fmt.Sprintf:把拼接好的字符串返回.这两个函数其实最麻烦的地方(也是功能
相同的地方),就是拼接字符串. DRY原则要求我们最好不要重复书写.而golang源代码里
面就把这部分'共同的逻辑'写在了第三个函数fmt.Fprintf里面, 而这个函数的第一个参
数io.Writer,就是一个interface
package fmt func Fprintf(w io.Writer, format string, args ...interface{}) (int, error) func Printf(format string, args ...interface{})(int, error) { return Fprintf(os.Stdout, format, args...) } func Sprintf(format string, args ...interface{}) string { var buf bytes.Buffer Fprintf(&buf, format, args...) return buf.String() }
- 这个Fprintf里面的F代表文件,意思是这个函数要把结果写入到一个file里面:
- 在Printf的例子里面, 我们直接把结果写入到了os.Stdout(是一个*os.File类型)里
面, 可见*os.File是符合io.Writer interface的.借助godoc,我们得到
func (f *File) Write(b []byte) (n int, err error) Write writes len(b) bytes to the File. It returns the number of bytes written and an error, if any. Write returns a non-nil error when n != len(b). - 在Sprintf里面, 传递给Fprintf的是&buf, 这是一个指向memoery buffer的pointer,
专门传递指针,可见这个buffer pointer才是符合io.Writer interface的,借助godoc
我们得到
func (b *Buffer) Write(p []byte) (n int, err error) Write appends the contents of p to the buffer, growing the buffer as needed. The return value n is the length of p; err is always nil. If the buffer becomes too large, Write will panic with ErrTooLarge.
- 在Printf的例子里面, 我们直接把结果写入到了os.Stdout(是一个*os.File类型)里
面, 可见*os.File是符合io.Writer interface的.借助godoc,我们得到
- Fprintf的第一个参数就是我们的主角:io.Writer interface,它的声明如下.我们后面
说的"形如"Write()函数,仅仅样子像就可以,功能满足comment里面的要求逻辑上更好,
不满足编译器也不可能报错!
package io // Writer is the interface that wraps the basic Write method type Writer interface { // Write writes len(p) bytes from p to the underlying data stream // It returns the numer of bytes written from p (0 <= n <= len(p)) // and any error encountered that caused the write to stop early. // Write must return a non-nil error if it retuns n < len(p). // Write must not modify the slice data, even temporarily. // // Implementations must not retain p. Write(p []byte) (n int, err error) }
- io.Writer interface就是在Fprintf和它的caller之间创建了一个"合同"(contract),
这个合同规定了双方的责任:
- caller保证:调用Fprintf的时候,第一个参数T一定要有形如Write(p []byte)的method
- 而被调用者Fprintf保证:只要你提供了形如Write(p []byte)的method,我就能满足你 的调用要求
- 简言之,就是一旦一个type,它有一个和Write(p []byte) (n int, err error)的声明样 式一样的函数,那么,我们就可以使用这个type来作为参数输入.
- 这种不同情况下我们的类型类型判断变得更加的自由:判断不是严格的安装编译器要求, 而是按照某些method是否存在而的判断!这种自由叫做可替换性(substitutability),可 替换下也是OO编程的标志
- 比如我们可以让我们的新类型ByteCounter(其实就是int)也符合io.Writer
type ByteCounter int func (c *ByteCounter) Write(p []byte) (int, error) { *c += ByteCounter(len(p)) return len(p), nil }
- 既然我们的*ByteCounter也满足io.Writer,我们当然可以传递给Fprintf,只不过我们
的Write()没有把p真正的写入到underlying stream(我们也没underlying stream)里面,
只不过是返回了"需要写入的长度"
https://play.golang.org/p/skf76y-70D
package main import ( "fmt" "os" ) type ByteCounter int func (c *ByteCounter) Write(p []byte) (int, error) { *c += ByteCounter(len(p)) return len(p), nil } func main() { var c ByteCounter c.Write([]byte("hello")) fmt.Println(c) c = 0 // reset the counter var name = "Dolly" fmt.Fprintf(&c, "hello, %s", name) fmt.Println(c) // len("hello, Dolly") os.Exit(0) } // <===================OUTPUT===================> // 5 // 12
- 除了io.Writer,另外一个对fmt来说更加重要的interface就是Stringer,它决定了某个
类型在打印的时候的格式.在其他语言比如Java中,这个函数叫做toString().在其他语
言里面(比如java),interface是要显示的写名的,所以不可能为了打印写一个interface
让没给类型implement.而Go是implicit implement,所以它也为字符串打印写了这么一
个interface.我们已经多次用到过这个interface了
package fmt // The String method is use dto print values passed // as an operand to any format that accepts a string // or to an unformatted printer such as Print. type Stringer interface { String() string }
Interface Types
- 所谓的Interface Type,是指:一个concrete type如果想被认为是某个interface的instance 的话,它必须要拥有的method
- io.Writer类型是最常用的interface,因为它提供了一种抽象,在这个抽象下面, byte 可以写入各种类型的介质,比如文件, network connection等等
- io package下面还定义了很多有用的interface,比如io.Reader,这个interface表示了
你可以从各种类型介质里面"读取"byte. Closer是你可以"关闭"这种类型的介质(使用
er也是Go对接口的命名规范)
package io type Reader interface { Read(p []byte) (n int, err error) } type Closer interface { Close() error }
- 我们还可以把两个interface包裹起来,形成一个新的interface
type ReadWriter interface { Reader Writer } type ReadWriteCloser interface { Reader Writer Closer }
- 上面的表述方法其实就等同于如下,只是写起来不够简洁.需要注意的是interface里面
method出现的顺序不重要的,只要有这些个method就可以了
type ReadWriter interface { Read(p []byte) (n int, err error) Write(p []byte) (n int, err error) } // mixture of the two style type ReadWriter interface { Read(p []byte) (n int, err error) Writer }
Interface Satisfaction
- 在Go里面,我们说一个concrete type "is a" particular interface type,意思就是
说这个concrete type"暴露"了某个interface所需要的所有的method.比如我们可以说
*bytes.Buffer is an io.Writer
- 一旦一个expression "is a" interface,那么它就可以assigned to 一个interface
var w io.Writer w = os.Stdout // OK: *os.File has Write method w = new(bytes.Buffer) // OK: *bytes.Buffer has Write method w = time.Second // compile error: time.Duration lacks Write method var rwc io.ReadWriteCloser rwc = os.Stdout // OK: *os.File has Read, Write, Close methods rwc = new(bytes.Buffer) // compile error: *bytes.Buffer lacks Close method
- 这里说的是一旦一个expression "is a" interface.expression的范围很广,不仅仅instance
是expression,我们的interface本身,也是expression.所以
w = rwc // OK: io.ReadWriteCloser has Write method rwc = w // compile error: io.Writer lacks Close method
- 一个值得注意的是,一个type拥有哪些method和它的*type拥有的method并不是共享的,
虽然一个*type拥有了methodA, type可以在编译器的帮助下自动加(&),但这是编译器
的syntactic sugar.某个类型的method还是和定义时候到底选择的type还是*type密切
相关的.比如我们前面的IntSet就没有实现Stringer,是*IntSet实现了Stringer
package main import ( "fmt" "os" ) type IntSet struct { words []uint64 } func (*IntSet) String() string { return "" } func main() { var s IntSet var _ fmt.Stringer = &s /////////////////////////////////////////////////////////////////////////////////////////// // // cannot use s (type IntSet) as type fmt.Stringer in assignment: // // // IntSet does not implement fmt.Stringer (String method has pointer receiver) // // var _ fmt.Stringer = s // /////////////////////////////////////////////////////////////////////////////////////////// fmt.Println() os.Exit(0) }
- 还有一种特殊的interface叫做interface{},就是这个interface不要求暴露"任何的
method", 这种interface叫做empty interface type. 因为不需要暴露任何method,所
以所有的type都"符合"empty interface type的要求.
We can assign any value to the empty interface
- 虽然没有明说,但是我们从第一天开始就使用interface{}啦,因为fmt.Println里面能打
印任意的类型,就是因为它的参赛就是interface{}
func Println(a ...interface{}) (n int, err error) { return Fprintln(os.Stdout, a...) }
- 当然了,interface{}只能负责"接受"这些实参.真正使用的时候,我们还是要确认这些 个实参真实的类型,这个时候就要使用type assertion了.换句话说,interface{}总是 和type assertion联合起来起作用的
- 因为interface只是和type的method有关系,所以在创建concrete type的时候,由于自己
还不知道自己的method有哪些,所以不可能把自己能够实现的interface在定义的时候
就列出来.但是定义完之后,如果我们真的想使用程序来检查我们的Buffer有没有实现
io.Writer,我们可以写出如下的强制检查语句
// *bytes.Buffer must satisfy io.Writer var w io.Writer = new(bytes.Buffer)
- 上面的强制语句有些复杂,我们可以'简化'一下:
- 我们不必使用new来创建一个新的变量,太浪费.因为即便是*bytes.Buffer的zero值, 也就是nil,也是可以创建一个变量的,而且还不用浪费地址存储
- 我们只是用来检查concrete type时候真的实现interface的,所以我们上面的变量w 其实是多余的,我们不会去使用他.可以使用blank identifier来代替
- 总结上面两点,我们可以总结出一个新的写法
// *bytes.Buffer must satisfy io.Writer var _ io.Writer = (*bytes.Buffer)(nil)
- 非空的interce,比如io.Writer在绝大多数的情况下都是由pointer type(特别是pointer to struct)实现的.这一点很重要.因为pointer type意味着更大的灵活性(比如可以更 改receiver).
- 但是说绝大多数情况,也就是还有例外:
- 小部分情况下Go的reference type也是可以实现很多interface的,比如slice, map, 甚至是function类型,都有可能实现interface
- basic type(无pointer)也是可以满足interface的,只不过不是很常见.因为使用basic
type来做method type的情况就不多.已有的例子是time.Duration实现了fmt.Stringer
godoc结果如下
func (d Duration) String() string String returns a string representing the duration in the form "72h3m0.5s". Leading zero units are omitted. As a special case, durations less than one second format use a smaller unit (milli-, micro-, or nanoseconds) to ensure that the leading digit is non-zero. The zero duration formats as 0s.
- 一个concrete type可能满足很多不相关的interface,这些不相关的interface其实代表
了对这些concrete type的分类.比如下面的例子,一个在线电子商店(比如amazon)可能
会给自己定义如下的concrete type
Album Book Movie Magazine Podcast TVEpiosode Track
- 我们可以抽出这些concrete type的一些共同点(在程序里面,共同点就是他们实现的一
组函数),来组成一些interface
type Artifact interface { Title() string Creators() []string Created() time.Time } type Text interface { Pages() int Words() int PageSize() int } type Audio interface { Stream() (io.ReadCloser, error) RunningTime() time.Duration Format() string // e.g. "MP3" } type Video interface { Stream() (io.ReadCloser, error) RunningTime() time.Duration Format() string Resolution() (x, y int) }
- 在分组的过程中,我们会发现"视频"和"音频"有很多共同点,我们可以抽出一些新的interface
type Streamer interface { Stream() (io.ReadCloser, error) RunningTime() time.Duration Format() string }
- 和其他语言不通,Go的interface满足是通过implicit的,这种方式更容易设计一些接口 让"其他package(不是我们能改动)"来implements,因为不需要改动"其他pacakge"的代 码就能完成
Parsing Flags with flag.Value
- 我们先来看一个使用standard interface(flag.Value)的例子
https://play.golang.org/p/8TN7JVNSKd
package main import ( "flag" "fmt" "time" ) var period = flag.Duration("period", 1*time.Second, "sleep period") func main() { flag.Parse() fmt.Printf("Sleeping for %v...\n", *period) time.Sleep(*period) fmt.Println() } // <===================OUTPUT===================> // Sleeping for 1s...
- 这个例子在没有输入任何-period的情况下,默认的停顿一秒了. 我们记得前面的flag.Bool
的例子,所以我们在使用的时候,默认的想法是传入一个int64值,因为time.Duration
本身就是一个int64, 使用"="赋值也能确认这一点
https://play.golang.org/p/kV2jqbA4DP
package main import ( "fmt" "os" "time" ) func main() { var t time.Duration t = 123 fmt.Println(t) var i int64 i = 123 fmt.Println(i) os.Exit(0) } // <===================OUTPUT===================> // 123ns // 123
- 但是我们带着以往的经验,给period一个int值的时候,发现是错误的
package main import ( "flag" "fmt" "time" ) var period = flag.Duration("period", 1*time.Second, "sleep period") func main() { flag.Parse() fmt.Printf("Sleeping for %v...\n", *period) time.Sleep(*period) fmt.Println() } // <===================OUTPUT===================> // > go run main.go -period 2 // invalid value "2" for flag -period: time: missing unit in duration 2
- 而如下的几种设置却可以通过(最后一种不行,使用了双引号),这说明,在flag里面
time.Duration和int64肯定是做了不同的处理
$ ./sleep -period 50ms Sleeping for 50ms... $ ./sleep -period 2m30s Sleeping for 2m30s... $ ./sleep -period 1.5h Sleeping for 1h30m0s... $ ./sleep -period "1 day" invalid value "1 day" for flag -period: time: invalid duration 1 day
- 通过查找源代码,我们发现了原因:
- 在flag package里面,所有的类型都会被type成'另外的类型'.也就是我们常说的"一人千面"
// -- time.Duration Value type durationValue time.Duration // -- int64 Value type int64Value int64 // -- string Value type stringValue string // ....
- type成'另外的类型'以后,这个'另外的类型'需要满足如下的一个interface,也就是
实现两个函数
// Value is the interface to the dynamic value stored in a flag. // (The default value is represented as a string.) // // If a Value has an IsBoolFlag() bool method returning true, // the command-line parser makes -name equivalent to -name=true // rather than using the next command-line argument. // // Set is called once, in command line order, for each flag present. type Value interface { String() string Set(string) error }
- int64和time.Duration实现Set()的时候,方法是不同的,导致flag package设置的时
候需要有不同的输入
func (i *int64Value) Set(s string) error { v, err := strconv.ParseInt(s, 0, 64) *i = int64Value(v) return err } func (d *durationValue) Set(s string) error { v, err := time.ParseDuration(s) // diff int64 here! *d = durationValue(v) return err }
- 在flag package里面,所有的类型都会被type成'另外的类型'.也就是我们常说的"一人千面"
- 通过这个例子,我们学习到了flag对于interface的精妙应用(当然更精妙的是type"一 人千面"的设计):只要能够满足String()和Set()两个函数,就可以被parse.
- 这也就提供了更重要的一点意义:我们可以扩展flag来分析"用户定义类型",比如Celsius:
- 首先type一个'新的类型'
//!+celsiusFlag // *celsiusFlag satisfies the flag.Value interface. type celsiusFlag struct{ Celsius }
- '新的类型'实现这两个函数(从而实现interface),注意上面的例子是使用struct来
包裹Celsius,从而直接拥有String()函数,所以这里只实现Set()
func (f *celsiusFlag) Set(s string) error { var unit string var value float64 fmt.Sscanf(s, "%f%s", &value, &unit) // no error check needed switch unit { case "C", "°C": f.Celsius = Celsius(value) return nil case "F", "°F": f.Celsius = FToC(Fahrenheit(value)) return nil } return fmt.Errorf("invalid temperature %q", s) }
- 使用的时候,就可以直接flag
https://play.golang.org/p/b4xEjEl3z0
// Tempflag prints the value of its -temp (temperature) flag. package main import ( "flag" "fmt" "gopl.io/ch7/tempconv" ) var temp = tempconv.CelsiusFlag("temp", 20.0, "the temperature") func main() { flag.Parse() fmt.Println(*temp) } // <===================OUTPUT===================> // > go run tempflag.go -temp -18C // -18°C // > go run tempflag.go -temp 212°F // 100°C // > go run tempflag.go -temp 212F // 100°C
- 首先type一个'新的类型'
Interface Values
- 任何一个类型的变量都有其value值,而且在没有明确初始化值的情况下,这个变量会有 一个zero值
- interface看成是一种类型的话,interface类型的变量也是要有其值的,这个值叫做 interface value,就好像我们有int value, bool value一样
- interface value和int value(bool value)不一样的地方,在于它在内存中存储的时候,
要有两个部分:
- dynamic type: 实际满足interface的concrete type是哪个,因为会有很多种concrete
type都会满足统一interface,所以单独列出一个内存区域来存储这个concrete type
是必须的这个部分在内存里面的大小应该是固定的,它只需要存储能够唯一标识concrete
type的字符串即可
在statically typed 语言里面,type是一个compile-time的概念,type不是value,所以 我们前面说的dynamic type部分里面存储的不能是一个value,而更应该看成是一个存储 类型名字的字符串.这个字符串能够唯一的定义这个类型就可以了(包括它的名字和method) 我们下面的例子中,type部分都是使用这个字符串(为了简单,只有name)来表示的,希望 你理解,这只是一个conceptual model,在内存中并不是真的这么存的. - dynamic value: 根据dynamic type的不同,会分配不同大小的内存来存储value
- dynamic type: 实际满足interface的concrete type是哪个,因为会有很多种concrete
type都会满足统一interface,所以单独列出一个内存区域来存储这个concrete type
是必须的这个部分在内存里面的大小应该是固定的,它只需要存储能够唯一标识concrete
type的字符串即可
- 我们以下面的这个例子来介绍一下interface value的"概念上的(conceptual)内存布局",
首先总体上来说一说,下面四句话,w共有三个不同的value(第一个和最后一个都是nil)
var w io.Writer w = os.Stdout w = new(bytes.Buffer) w = nil
- 第一句创建io.Writer interface的value w, 因为没有赋值,所以这个时候不知道我们
和哪个concrete type联系上了,所以type是没有名字的,所以是nil(如果我们把这个
conceptual的type想成是string的话,""也是可以的), 所以w也是zero value,
其内存情况如下
w +------------+ type | nil | +------------+ value | nil | +------------+ - 第二句,把一个concrete 类型为*os.File类型的变量(os.Stdout返回值为*os.File)赋
值给w, w的type部分(名字)就是*os.File, value部分是一个指针(因为类型就是一个指
针,那么留给value的肯定只能够放一个指针),指向value值->指向os.Stdout(类型为os.File)
w +------------+ type | *os.File | os.File +------------+ +---------------------+ value | . |----------------->| fd int = 1(stdout) | +------------+ +---------------------+ - 在第二句赋值完之后,我们是可以调用如下的代码的(因为能赋值成功,说明我们的*os.File
肯定有Write()函数啊)
w.Write([]byte("hello")) // "hello"
- w是一个interface type, 无法直接调用Write,所以编译器会生成一段代码,所以上面
的代码会被编译器"改成"如下代码
os.Stdout.Write([]byte("hello")) // "hello"
- 第三句,w被赋予了*bytes.Buffer类型的值,所以type里面的name就是*bytes.Buffer,
value里面还是一个指针(留给它的空间还是只能是一个指针),其value值->指向某块内存,
这块内存的类型我bytes.Buffer 其内存模型为
w +-------------+ type |*bytes.Buffer| bytes.Buffer +-------------+ +---------------------+ value | . |---------------->| | +-------------+ +---------------------+ - 最后一句又把w赋值为zero value,内存模型和第一个一致
- 我们的例子刚好value都是pointer类型,其实value值可以是"任何类型",如果不是pointer
类型,而是一个type的话,那么value的内存大小就是type一个值的大小, 也就是说go还
是会存储它们全部!这就是值语义语言的执着,比如下面的语句中的x
https://play.golang.org/p/qde6sSUv2d
package main import ( "fmt" "os" "time" ) func main() { var x interface{} = time.Now() fmt.Println(x) os.Exit(0) } // <===================OUTPUT===================> // 2017-02-10 14:49:00.369942821 +0800 CST
- x的内存分布如下(注意,这只是conceptual model)
x +---------------------------------+ type | time.Time | | | +---------------------------------+ |+------------------------------+ | value || sec: 65567389742 | | |+------------------------------+ | || nsec: 689632918 | | |+------------------------------+ | || loc: "UTC" | | |+------------------------------+ | +---------------------------------+ - interface value是可以通过==和!=来相互比较的(再次证明了interface value不是一
个reference type).两个interface value相等的条件:
- 两个都是nil
- 两个的dynamic type使用==相比较结果为true,而且两个的dynamic value使用==比 较结果为true
- 正是因为interface value是comparable的(使用==,!=可以比较),所以他们都可以作为 map里面的key,也可以作为switch statement里面的operand
- 但是interface value的比较具有一个特殊的地方,那就是如果interface value的dynamic
type一样,但是dynamic type之间是不能比较的话,那么强制比较会产生panic
package main import ( "fmt" "os" ) func main() { var x interface{} = []int{1, 2, 3} fmt.Println(x) /////////////////////////////////////////////////////////////////////// // // panic: runtime error: comparing uncomparable type []int // // fmt.Println(x == x) // /////////////////////////////////////////////////////////////////////// os.Exit(0) } // <===================OUTPUT===================> // [1 2 3]
- 在这个方面,interface type是特殊的,因为其他类型要么可以安全的比较(比如basic type和pointer),要么完全不能比较.所以比较interface type(包括包含interface value 的aggregate type)的时候,一定要注意潜在panic可能发生
- 上面的这些信息都是"概念性"的, 并非真是真的内存布局,而interface value的信息
则真的是可以通过fmt里面的%T来取得dynamic type, 而fmt能够实现这个的原因是其
使用了reflection机制
package main import ( "bytes" "fmt" "io" "os" ) func main() { var w io.Writer fmt.Printf("%T\n", w) w = os.Stdout fmt.Printf("%T\n", w) w = new(bytes.Buffer) fmt.Printf("%T\n", w) } //////////////////////////////////////////////////// // <===================OUTPUT===================> // // <nil> // // *os.File // // *bytes.Buffer // ////////////////////////////////////////////////////
Caveat: An Interface Containing a Nil Pointer Is Non-Nil
- 如下两个interface是不相同的:
- nil interface value: type和value都是nil,前面讲过
- interface value 包括一个正好为nil的pointer: value是nil, type不是nil!
- 下面这个例子中,debug为true当然可以正常工作,但是一旦debug为false,就无法正常
工作了
package main import ( "bytes" "fmt" "io" ) const debug = true // const debug = false // will panic with following errors ///////////////////////////////////////////////////////////////////////////// // panic: runtime error: invalid memory address or nil pointer dereference // // [signal 0xb code=0x1 addr=0x68 pc=0x57410] // // // // goroutine 1 [running]: // // bytes.(*Buffer).Write(0x0, 0xc82000a370, 0x5, 0x8, 0x5, 0x0, 0x0) // ///////////////////////////////////////////////////////////////////////////// func main() { var buf *bytes.Buffer if debug { buf = new(bytes.Buffer) } f(buf) } func f(out io.Writer) { // Have a assignment here!! if out != nil { out.Write([]byte("done!")) fmt.Println(out) } } // <===================OUTPUT===================> // done!
- 这是因为f(p)的调用中, p会有一次赋值的过程,这个过程就类型于如下代码
var buf *bytes.Buffer // concrete type out = buf // out is interface with dynamic type is *bytes.Buffer and dynamic type is nil
- 这样一来, out就是我们说的"interface containing a Nil Pointer", 它"不等于" nil!!!
- 我们来探求一下这个错误的根源:
- 根源一: interface value是"值",而不是reference
- 根源二: interface value的赋值要求很低,只要你的value实现了接口A,就可以赋 值给interface A value
- 根源三: interface value很容易接受一个nil pointer,但是由于外面还有一层
interface,所以它本身不是nil, 它的内存分布是这样的(type也为nil,才是nil)
w +-------------+ type |*bytes.Buffer| +-------------+ value | nil | +-------------+
- 这段代码正常的写法,是把buf本身就设置成interface value(如果不赋值的话type就
是nil)
var buf io.Writer if debug { buf = new(bytes.Buffer) // enable collection of output } f(buf) // OK
Sorting with sort.Interface
- golang 的sort package提供了in-place的排序功能,排序的原则是ordering function 提供的. 这一点是和传统的语言里面差不多的结构
- 但是golang不一样的地方在于其ording function不再是要求具体的类型, 而只是要求
interface(行为)就可以了,换句话说,要求"想利用sort功能的type"实现如下一个
interface(sort.Interface)就可以了.
package sort type Interface interface { Len() int Less(i, j int) bool //i, j are indices of sequence elements Swap(i, j int) }
- 需要注意的是, "想利用sort功能"的type,一般来说都"实质上是slice类型"(当然了type
可以做到一人千面)的,而Less比较的,则是这个slice类型里面的"两个item"的大小.比
如下面例子中的byte
type StringSlice []string func (p StringSlice) Len() int { return len(p) } func (p StringSlice) Less(i, j int) bool { return p[i] < p[j] } func (p StringSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
- 有了上面的代码,我们在排序StringSlice的时候就简单多了
sort.Sort(StringSlice(names))
- 排列strings数组的需求非常常用,以至于sort package直接提供了sort.Strings(stringslice)
package main import ( "fmt" "os" "sort" ) func main() { s := []string{"hijk", "lm", "a", "o", "b", "cd", "efg"} sort.Strings(s) fmt.Println(s) os.Exit(0) } // <===================OUTPUT===================> // [a b cd efg hijk lm o]
- 如果看看源代码,就会发现,其实sort.String就是通过StringSlice实现的
// Strings sorts a slice of strings in increasing order. func Strings(a []string) { Sort(StringSlice(a)) }
- 更多复杂的情况下,就需要我们的type,自己去实现sort.Interface,好看下面的一个复
杂的例子:
- 首先看type,是一个播放列表中的一个item
type Track struct { Title string Artist string Album string Year int Length time.Duration }
- 再看看我们的slice如何写:这里是有窍门的,我们没有使用'值'数组,而是使用了'指
针'数组.因为存储的是指针,所以swap的时候能够极大的减小消耗(指针大小的内存
swap,最多64bit,而一个Track则是一个多word的值).从这里我们可以看到java的"引
用"语义是有意义的,因为可以极大的提高效率.但是Go做的更好,你可以自己来选择
是使用'值'语义还是'引用'语义
var tracks = []*Track{ {"Go", "Delilah", "From the Roots Up", 2012, length("3m38s")}, {"Go", "Moby", "Moby", 1992, length("3m37s")}, {"Go Ahead", "Alicia Keys", "As I Am", 2007, length("4m36s")}, {"Ready 2 Go", "Martin Solveig", "Smash", 2011, length("4m24s")}, } // 使用下面的代码来进行长度统计 func length(s string) time.Duration { d, err := time.ParseDuration(s) if err != nil { panic(s) } return d }
- 我们可以使用golang提供的tabwriter来更好的格式化代码
func printTracks(tracks []*Track) { const format = "%v\t%v\t%v\t%v\t%v\t\n" tw := new(tabwriter.Writer).Init(os.Stdout, 0, 8, 2, ' ', 0) fmt.Fprintf(tw, format, "Title", "Artist", "Album", "Year", "Length") fmt.Fprintf(tw, format, "-----", "------", "-----", "----", "------") for _, t := range tracks { fmt.Fprintf(tw, format, t.Title, t.Artist, t.Album, t.Year, t.Length) } tw.Flush() // calculate column widths and print table }
- 为了能够sort by Artist field,我们还得必须申请一个新的类型,然后让这个类型
实现sort.Interface接口
type byArtist []*Track func (x byArtist) Len() int { return len(x) } func (x byArtist) Less(i, j int) bool { return x[i].Artist < x[j].Artist } func (x byArtist) Swap(i, j int) { x[i], x[j] = x[j], x[i] }
- 然后就可以调用了
sort.Sort(byArtist(tracks)) printTracks(tracks) // <===================OUTPUT===================> // Title Artist Album Year Length // ----- ------ ----- ---- ------ // Go Ahead Alicia Keys As I Am 2007 4m36s // Go Delilah From the Roots Up 2012 3m38s // Ready 2 Go Martin Solveig Smash 2011 4m24s // Go Moby Moby 1992 3m37s
- sort package还设计了非常好的"反转"特性
sort.Sort(sort.Reverse(byArtist(tracks))) // <===================OUTPUT===================> // Title Artist Album Year Length // ----- ------ ----- ---- ------ // Go Moby Moby 1992 3m37s // Ready 2 Go Martin Solveig Smash 2011 4m24s // Go Delilah From the Roots Up 2012 3m38s // Go Ahead Alicia Keys As I Am 2007 4m36s
- 这个"反转"的写法值得我们关注,因为它使用了composition.sort定义了一个不export
的type reverse,这个type只包含sort.Interface,初始化的时候,只需要给reverse{}
传入data就可以了.所有data的数据都会给reverse,然后我们再重新实现Less
package sort type reverse struct{ Interface } // that is, sort.Interface func (r reverse) Less(i, j int) bool { return r.Interface.Less(j, i) } func Reverse(data Interface) Interface { return reverse{data} }
- 如果我们想再按照year来排序,需要再次创建一个类型
type byYear []*Track func (x byYear) Len() int { return len(x) } func (x byYear) Less(i, j int) bool { return x[i].Year < x[j].Year } func (x byYear) Swap(i, j int) { x[i], x[j] = x[j], x[i] } // <===================OUTPUT===================> // Title Artist Album Year Length // ----- ------ ----- ---- ------ // Go Moby Moby 1992 3m37s // Go Ahead Alicia Keys As I Am 2007 4m36s // Ready 2 Go Martin Solveig Smash 2011 4m24s // Go Delilah From the Roots Up 2012 3m38s
- 如果看看我们byArtist还有byYear的代码,我们就会发现Len()和Swap()代码是相同的
如果我们想要满足DRY原则,我们需要一种新的设计类型的形式: Less设计成function
value: 通过function传入逻辑.而不改动的逻辑,直接作为类型的method
type customSort struct { t []*Track less func(x, y *Track) bool } func (x customSort) Len() int { return len(x.t) } func (x customSort) Less(i, j int) bool { return x.less(x.t[i], xt[j]) } func (x customSort) Swap(i, j int) { x.t[i], x.t[j] = x.t[i], x.t[i] }
- 排序的logic放在一个匿名函数中传入
sort.Sort(customSort(tracks, func(x, y *Track) bool { if x.Title != y.Title { return x.Title < y.Title } if x.Year != y.Year { return x.Year < y.Year } if x.Length != y.Length { return x.Length < y.Length } return false }})
- 首先看type,是一个播放列表中的一个item
- 最后的最后,我们来看看sort package提供的IsSorted function.判断某个sequence是
否是sorted的复杂度是O(N-1),比排序的复杂度(NlogN)要低很多.有些时候会有用.对于
int, float等没有实现sort.Interface的prime类型,sort也提供了IntsAreSorted等"变
体"
https://play.golang.org/p/kCCgj9e9hq
package main import ( "fmt" "os" "sort" ) type StringSlice []string func (p StringSlice) Len() int { return len(p) } func (p StringSlice) Less(i, j int) bool { return p[i] < p[j] } func (p StringSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] } func main() { sl := StringSlice([]string{"zwf", "abc", "def"}) fmt.Println(sort.IsSorted(sl)) sort.Sort(sl) fmt.Println(sort.IsSorted(sl)) values := []int{3, 1, 4, 1} fmt.Println(sort.IntsAreSorted(values)) sort.Ints(values) fmt.Println(sort.IntsAreSorted(values)) os.Exit(0) } // <===================OUTPUT===================> // false // true // false // true
The http.Handler Interface
- go里面处理server,最常见的API的核心接口是http.Handler interface,定义如下
// package net/http package http type Handler interface { ServeHTTP(w ResponseWriter, r *Request) }
- 真正起作用的函数,接受两个参数,一个是类型"localhost:8000"这样的host+port字符
串组合, 另外一个就是一个实现了Handler interface的instance啦
func ListenAndServe(address string, h Handler) error
- 既然是一个server,那么ListenAndServe函数的特点是:
- 要么启动失败
- 要么一直运行
- 要么运行的时候奔溃
- 总之不会"成功"返回,它的成功就是一直运行
- 下面我们来看一个例子:一个电子商城
- 其中的database其实是一个map,把货物映射成美元
- 我们让database类型实现我们的Handler interface,那么它也就能放到ListenAndServe 函数里面,作为第二个参数了.
- 代码如下
package main import ( "fmt" "log" "net/http" ) type dollars float32 func (d dollars) String() string { return fmt.Sprintf("$%.2f", d) } type database map[string]dollars func (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) { for item, price := range db { fmt.Fprintf(w, "%s: %s\n", item, price) } } func main() { db := database{"shoes": 50, "socks": 5} log.Fatal(http.ListenAndServe("localhost:8000", db)) } // <===================OUTPUT===================> // $ go run main.go // go run main.go
- 使用curl能够得到服务器的返回值
$ curl http://localhost:8000 shoes: $50.00 socks: $5.00
- 当前版本的例子是最简单的,服务器只能在"/"返回所有的db内容,这显然不太实用,真正
的server会有很多的URL,不同的URL会有不同的结果.比如我们要求我们的例子可以提供
如下两个功能:
- "/list"列出所有的产品
- "/price?item=xxx"列出某个item的价格
- 代码如下
package main import ( "fmt" "log" "net/http" ) type dollars float32 func (d dollars) String() string { return fmt.Sprintf("$%.2f", d) } type database map[string]dollars func (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) { switch req.URL.Path { case "/list": for item, price := range db { fmt.Fprintf(w, "%s: %s\n", item, price) } case "/price": item := req.URL.Query().Get("item") price, ok := db[item] if !ok { w.WriteHeader(http.StatusNotFound) // 404 fmt.Fprintf(w, "no such item: %q\n", item) return } fmt.Fprintf(w, "%s\n", price) default: w.WriteHeader(http.StatusNotFound) fmt.Fprintf(w, "no such page: %s\n", req.URL) } } func main() { db := database{"shoes": 50, "socks": 5} log.Fatal(http.ListenAndServe("localhost:8000", db)) } // <===================OUTPUT===================> // curl http://localhost:8000/price?item=socks // $5.00
- 当然了,这样看起来,我们的代码非常的简介,我们甚至可以无限制的不停把URL加下去, 但是在正式的项目中,每个URL都代表了一个逻辑,这个逻辑一般是由不同的开发人员写 在不同的函数里面.同时相似的URL可能使用同一个逻辑:比如/images/*.png
- 基于以上原因net/http 提供了一个叫做ServeMux的request multiplexer来简化URL和
handler之间的设置,说起来简单,但是实现方法却是有点绕:
- ListenAndServe这个函数是运行所有go server的必备函数,我们是不可能改动这个函
数的.这个函数除了"一直运行"以外,另外一个特点就是第二个参数要求一定要实现
http.Handler,所以ServeMux的第一个基本思想就是自己作为ListenAndServe的第二
个参数,所以ServeMux是肯定实现了http.Handler啦(使用的是指针)
// ServeHTTP dispatches the request to the handler whose // pattern most closely matches the request URL. func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) { if r.RequestURI == "*" { if r.ProtoAtLeast(1, 1) { w.Header().Set("Connection", "close") } w.WriteHeader(StatusBadRequest) return } h, _ := mux.Handler(r) h.ServeHTTP(w, r) }
- 传统的LinstenAndServe要求所有的http URL的规则都要在第二个参数里面写明,所以
我们肯定要在ServeMux里面为所有的'URL规则'都准备好位置存放,现在的办法是使用
一个map.
// Handle registers the handler for the given pattern. // If a handler already exists for pattern, Handle panics. func (mux *ServeMux) Handle(pattern string, handler Handler) { mux.mu.Lock() defer mux.mu.Unlock() if pattern == "" { panic("http: invalid pattern " + pattern) } if handler == nil { panic("http: nil handler") } if mux.m[pattern].explicit { panic("http: multiple registrations for " + pattern) } if mux.m == nil { mux.m = make(map[string]muxEntry) } mux.m[pattern] = muxEntry{explicit: true, h: handler, pattern: pattern} // ... }
- 这个map的key是'URL pattern', value是handler function value. 注意这是一个
function value,也就是说是fp编程里面的东西.我们把"逻辑"通过函数传递给map.其
中一个"逻辑"的样子和使用方法如下
func (db database) list(w http.ResponseWriter, req *http.Request) { for item, price := range db { fmt.Fprintf(w, "%s: %s\n", item, price) } } func main() { // ... mux.Handle("/list", http.HandlerFunc(db.list)) // ... }
- 这个list函数特别的奇怪,因为它的req这个参数"压根就没有用!!",但是还是要这么
设计,这是为了让http.HandlerFunc能够根据它来创建出符合http.Handler接口的新
instance. 这里的HandlerFunc是一种Go里面接口的特殊用法: 'adapter!'database
的某个method通过'中间类型HandlerFunc'做到了满足http.Handler接口!
package http type HandlerFunc func(w ResponseWriter, r *Request) func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) { f(w, r) }
- "使用http.HandlerFunc来adapt一个function value,使得整个function value能够
满足http.Handler"这个用法实在太常见,所以package http又做了新一步的简化,设
计了HandleFunc函数,它和Handle函数是完全等价的.(下面两行代码完全等价)
mux.Handle("/list", http.HandlerFunc(db.list)) mux.HandleFunc("/list", db.list)
- 最后一条比较容易忽视,那就是,一般一个program(运行起来的叫做process)只会使
用一个端口.这种情况下,一个program也只会使用一个ServeMux.所以我们把ServeMux
定义成一个全局变量,如果第二个参数为nil的情况下,ListenAndServe都会去寻找这
个全局变量作为自己默认的'第二个变量'
func main() { db := database{"shoes": 50, "socks":5} http.HandleFunc("/list", db.list) http.HandleFunc("/price", db.price) log.Fatal(http.ListenAndServe("localhost:8000", nil)) }
- ListenAndServe这个函数是运行所有go server的必备函数,我们是不可能改动这个函
数的.这个函数除了"一直运行"以外,另外一个特点就是第二个参数要求一定要实现
http.Handler,所以ServeMux的第一个基本思想就是自己作为ListenAndServe的第二
个参数,所以ServeMux是肯定实现了http.Handler啦(使用的是指针)
The error Interface
- 从这本书的开始,我们就开始使用error type了,但是没有具体解释,因为error其实是一
个interface
type error interface { Error() string }
- 最简单的创建一个error的方法就是使用errors.New. 整个errors package只有四行代
码!
package errors func New(text string) error { return &errorString{text} } type errorString struct { text string } func (e *errorString) Error() string { return e.text }
- 我们看到errors.New其实就是返回一个errorString类型的指针,而errorString所有的 field加起来只有一个string,但是还是type了struct,而不是type了struct.因为这样 可以保护`text`被"不小心"的更改
- 使用指针类型来实现接口也是有原因的:每次使用New都会创建一个完全'不一样'的error instance.
- 这里的'不一样'是指:即便text内容碰巧完全一致,两个error instance是连比较都无
法比较(因为指针类型是ref类型,只能和nil比较)
package main import ( "errors" "fmt" "os" ) func main() { fmt.Println(errors.New("EOF") == errors.New("EOF")) os.Exit(0) } // <===================OUTPUT===================> // false
- errors.New是默认的创建error的方法,但是却不会经常在代码中看到.那是因为有另外
的wrapper function来包裹了errors.New,另外做些其他的工作,比如format
package fmt import "errors" func Errorf(format string, args ...interface{}) error { return errors.New(Sprintf(format, args...)) }
- *errorString是最简单的error,但是却远远不是唯一的一个.比如syscall package提供
底层的system call API.在许多系统中,这个package都会设计一个叫做Errno的类型来
implement error interface
package syscall type Errno uintptr // operating system error code var errors = [...]string { 1: "operation not permitted", // EPERM 2: "no such file or directory", // ENOENT 3: "no such process", // ESRCH // ... } func (e Errno) Error() string { if 0 <= int(e) && int(e) < len(errors) { return errors[e] } return fmt.Sprintf("errno %d", e) }
- 使用方法如下
package main import ( "fmt" "os" "syscall" ) func main() { var err error = syscall.Errno(2) fmt.Println(err) os.Exit(0) } // <===================OUTPUT===================> // no such file or directory
Example: Expression Evaluator
- 下面的章节,我们要来创建一个简单的例子:来计算算术表达式
- 我们使用一个interface Expr来代表任意的一个expression.最开始我们可以使用如下
的代码来定义expression
// An Expr is an arithmetic expression type Expr interface{}
- 我们的expression可以拥有如下的特性(成员都是float精度):
- binary operator: +, -, *, /
- unary operator: -x, +x
- function call: pow(x, y), sin(x), sqrt(x)
- 变量:比如x或者pi
- 还有就是括号和标准的算术符号优先级
- 我们的expression的几个例子如下:
sqrt(A / pi) pow(x, 3) + pow(y, 3) (F - 32) * 5 / 9
- 我们用如下代码来表达出各个成员
// A Var identifies a variable, e.g., x. type Var string // A literal is a numeric constant, e.g., 3.141 type literal float64 // A unary represents a unary operator expression, e.g., -x. type unary struct { op rune // one of '+', '-' x Expr } // A binary represents a binary operator expression, e.g., x + y. type binary struct { op rune // one of '+', '-', '*', '/' x, y Expr } // A call represents a function call expression, e.g., sin(x). type call struct { fn string // one of "pow", "sin", "sqrt" args []Expr }
- 为了能够知道"变量"的值,我们需要一个map来存储"变量"和float64直接的转化关系
type Env map[Var]float64
- 有了这个Env之后,我们每个expression都需要提供一个把expression转换成float64的
函数,我们暂且把这个函数叫做是Eval好了,那么每个expression都需要这个函数,所以
这个函数必须得是在Expr interface里面了.
type Expr interface { // Eval returns the value of this Expr in the environment env. Eval(env Env) float64 }
- 好了,interface定好了后,我们的类型每个都要去实现这个函数.简单的例子如下
func (v Var) Eval(env Env) float64 { return env[v] } func (l literal) Eval(_ Env) float64 { return float64(l) }
- 复杂的例子,也就是单操作数,或者双操作数的例子(它们会把自己管辖的expr的值算出
来),如下
func (u unary) Eval(env Env) float64 { switch u.op { case '+': return +u.x.Eval(env) case '-': return -u.x.Eval(env) } panic(fmt.Sprintf("unsupported unary operator: %q", u.op)) } func (b binary) Eval(env Env) float64 { switch b.op { case '+': return b.x.Eval(env) + b.y.Eval(env) case '-': return b.x.Eval(env) - b.y.Eval(env) case '*': return b.x.Eval(env) * b.y.Eval(env) case '/': return b.x.Eval(env) / b.y.Eval(env) } panic(fmt.Sprintf("unsupported unary operator: %q", u.op)) }
- 函数调用只支持三个
func (c call) Eval(env Env) float64 { switch c.fn { case "pow": return math.Pow(c.args[0].Eval(env), c.args[1].Eval(env)) case "sin": return math.Sin(c.args[0].Eval(env), c.args[1].Eval(env)) case "sqrt": return math.Sqrt(c.args[0].Eval(env), c.args[1].Eval(env)) } panic(fmt.Sprintf("unsupported unary operator: %q", u.op)) }
- 我们的代码是否管用,可以使用go自带的testing package来进行测试
func TestEval(t *testing.T) { tests := []struct { expr string env Env want string }{ {"sqrt(A / pi)", Env{"A": 87616, "pi": math.Pi}, "167"}, {"pow(x, 3) + pow(y, 3)", Env{"x": 12, "y": 1}, "1729"}, {"pow(x, 3) + pow(y, 3)", Env{"x": 9, "y": 10}, "1729"}, {"5 / 9 * (F - 32)", Env{"F": -40}, "-40"}, {"5 / 9 * (F - 32)", Env{"F": 32}, "0"}, {"5 / 9 * (F - 32)", Env{"F": 212}, "100"}, //!-Eval // additional tests that don't appear in the book {"-1 + -x", Env{"x": 1}, "-2"}, {"-1 - x", Env{"x": 1}, "-2"}, //!+Eval } var prevExpr string for _, test := range tests { // Print expr only when it changes. if test.expr != prevExpr { fmt.Printf("\n%s\n", test.expr) prevExpr = test.expr } expr, err := Parse(test.expr) if err != nil { t.Error(err) // parse error continue } got := fmt.Sprintf("%.6g", expr.Eval(test.env)) fmt.Printf("\t%v => %s\n", test.env, got) if got != test.want { t.Errorf("%s.Eval() in %v = %q, want %q\n", test.expr, test.env, got, test.want) } } }
- 前面的假设"我们是输入都是正确的",但是这并不能一直保证的.为了保证我们输入正
确,我们再加上一个函数Check()来做static check:不需要运行就知道输入格式正确与
否
type Expr interface { Eval(env Env) float64 // Check reports errors in this Expr and adds its Vars to the set. Check(vars map[Var]bool) error }
- 下面就是各个类型用来进行Check的代码,其中对literal和Var的check是永远都不会失
败的. 对于操作符则会先检测是否有正确的符号,然后递归检测它自己的expr.对函数
则是检测参数个数对不对,然后递归检测这些参数
func (v Var) Check(vars map[Var]bool) error { vars[v] = true return nil } func (literal) Check(vars map[Var]bool) error { return nil } func (u unary) Check(vars map[Var]bool) error { if !strings.ContainsRun("+-", u.op) { return fmt.Errorf("unexpected unary op %q", u.op) } return u.x.Check(vars) } func (b binary) Check(vars map[Var]bool) error { if !strings.ContainsRune("+-*/", b.op) { return fmt.Errorf("unexpected binary op %q", b.op) } if err := b.x.Check(vars); err != nil { return err } return b.y.Check(vars) } func (c call) Check(vars map[Var]bool) error { arity, ok := numParams[c.fn] if !ok { return fmt.Errorf("unknown function %q", c.fn) } if len(c.args) != arity { return fmt.Errorf("call to %s has %d args, want %d", c.fn, len(c.args), arity) } for _, arg := range c.args { if err := arg.Check(vars); err != nil { return err } } return nil } var numParams = map[string]int{"pow": 2, "sin": 1, "sart" : 1}
- 好了,研究了这么多我们来看看我们"自己创造一个类型,甚至一个小型的解释器"其意 义在哪里?
- 一个可行的作用,就是"在url的parameter里面"用来判断input字符串是否合格,合格后
可以马上算出结果:
- 首先我们要有一个函数来把string类型转换成Expr类型(部分代码)
func Parse(input string) (_ Expr, err error) { defer func() { switch x := recover().(type) { case nil: // no panic case lexPanic: err = fmt.Errorf("%s", x) default: // unexpected panic: resume state of panic. panic(x) } }() lex := new(lexer) lex.scan.Init(strings.NewReader(input)) lex.scan.Mode = scanner.ScanIdents | scanner.ScanInts | scanner.ScanFloats lex.next() // initial lookahead e := parseExpr(lex) if lex.token != scanner.EOF { return nil, fmt.Errorf("unexpected %s", lex.describe()) } return e, nil }
- 首先检查是不是valid的input,返回一个error.
//!+parseAndCheck func parseAndCheck(s string) (eval.Expr, error) { if s == "" { return nil, fmt.Errorf("empty expression") } expr, err := eval.Parse(s) if err != nil { return nil, err } vars := make(map[eval.Var]bool) if err := expr.Check(vars); err != nil { return nil, err } for v := range vars { if v != "x" && v != "y" && v != "r" { return nil, fmt.Errorf("undefined variable: %s", v) } } return expr, nil }
- 如果没有error就可以直接打印值啦(需要导入Env),然后我们把这个函数(plot)做成可
以作为handler的样子.参数是形如http://localhost:8000/plot?expr=sin(-x)的样
子
//!+plot func plot(w http.ResponseWriter, r *http.Request) { r.ParseForm() expr, err := parseAndCheck(r.Form.Get("expr")) if err != nil { http.Error(w, "bad expr: "+err.Error(), http.StatusBadRequest) return } w.Header().Set("Content-Type", "image/svg+xml") surface(w, func(x, y float64) float64 { r := math.Hypot(x, y) // distance from (0,0) return expr.Eval(eval.Env{"x": x, "y": y, "r": r}) }) }
- 最后就可以把这个plot()设置成某个url(这里是"/plot")的处理函数了
//!+main func main() { http.HandleFunc("/plot", plot) log.Fatal(http.ListenAndServe("localhost:8000", nil)) }
- 首先我们要有一个函数来把string类型转换成Expr类型(部分代码)
Type Assertions
- 所谓type assertion,是形如x.(T)的操作.其中T是类型,而x是interface value.换句 话说type assertion是"只能使用在interface value"上面的类型判断方法.
- 这也很好理解,因为普通value的类型是不需要assert的,是static的.只有interface value的类型才不是固定的:它拥有的是dynamic type.
- 至于type assertion:x.(T)的结果,那会根据T的不同而有所不同:
- 如果T是一个concrete type: type assertion会去检查x的dynamic type是不是"完全
等于"T.如果成功的话,assertion的结果就会是x的dynamic value(对的,你没看错,是
dynamic value,换句话说,这个assertion操作在dynamic type对得上的情况下,会给
你dynamic value).如果失败的话,直接panic
package main import ( "fmt" "io" "os" ) func main() { var w io.Writer w = os.Stdout f := w.(*os.File) fmt.Printf("%T\n", f) fmt.Println(f == os.Stdout) ///////////////////////////////////////////////////////////////////////////////////// // // panic: interface conversion: io.Writer is *os.File, not *bytes.Buffer // // c := w.(*bytes.Buffer) // // fmt.Println(c) // ///////////////////////////////////////////////////////////////////////////////////// os.Exit(0) } // <===================OUTPUT===================> // *os.File // true
- 如果T也是一个interface type的话.assertion就转化为"x的dynamic type是不是满
足T".这种情况下,即便是assertion成功了,也不会"获取"到dynamic value的.但是
assertion之后,会得到一个dynamic type为T, dynamic value不变的,新的interface
value.换句话说,这种情况下的assertion操作是在dynamic value不变的情况下,给你
一个新的dynamic type–也就意味着一系列新的method.需要注意的是如果T还是x不
能满足的情况下,依然会panic.下面的例子中w和rw的dynamic value完全相同,但是只
有rw暴露了Write函数
var w io.Writer w = os.Stdout rw := w.(io.ReadWriter) // success: *os.File has both Read and Write w = new(ByteCounter) rw = w.(io.ReaderWriter) // panic: *ByteCounter has no Read method
- 如果T是一个concrete type: type assertion会去检查x的dynamic type是不是"完全
等于"T.如果成功的话,assertion的结果就会是x的dynamic value(对的,你没看错,是
dynamic value,换句话说,这个assertion操作在dynamic type对得上的情况下,会给
你dynamic value).如果失败的话,直接panic
- 如果x是nil,那么无论T是什么类型,assertion都会失败
- 前面说了,T是concrete type和interface type的情况.用到assertion并且T是interface
type的情况下.T和x就都是interface type.绝大多数情况下T的method要多.因为T的method
要少的话,可以直接赋值,没必要assertion了
w = rw // io.ReadWriter is assignable to io.Writer w = rw.(io.Writer) // falls only if rw == nil
- 前面说到,assertion一旦失败的话,就是panic.这对于一般的程序而言,压力有点大.因
为一般的程序大多数的情况下,是不知道类型.不知道类型的时候,总不能试错一次就panic
吧.而go解决这个问题的办法是返回两个值的时候,第二个返回值,就是来验证assertion
是否成功
package main import ( "bytes" "fmt" "io" "os" ) func main() { var w io.Writer = os.Stdout f, ok := w.(*os.File) fmt.Println(f == os.Stdout, ok) // extract dynamic value b, ok := w.(*bytes.Buffer) fmt.Println(b == nil, ok) // failed, so b is nil os.Exit(0) } // <===================OUTPUT===================> // true true // true false
- 这种第二个返回值为boolean的情况,非常适合马上使用第二个返回值,比如
if f, ok := w.(*os.File); ok { // ... use f ... }
- 当我们的type assertion里面的x本身就是一个变量的时候,我们经常会看到assertion
的返回值并没有新申请一个变量,而是直接使用了x,如下
if w, ok := w.(*os.File); ok { // ... use w ... }
Discriminating Errors with Type Assertions
- 我们下面来看一个os package里面文件错误的例子:I/O可能由于各种各样的原因失败,
但是有三种错误是要特别对待的:
- file already exists
- file not found
- permission denied
- os package提供了下面三个helper函数来identify三种不同的error value
package os func IsExist(err error) bool func IsNotExist(err error) bool func IsPermission(err error) bool
- error 类型之间最大的不同,就是error message.一个非常"天真"的做法就是通过比较
error message来identify错误是不是上面的三种类型
func IsNotExist(err error) bool { // NOTE: not robust! return strings.Contains(err.Error(), "file does not exist") }
- 这种天真的做法至少有如下两个致命的缺点:
- 不同的error可能会报相同的error message,至少是一部分相同的error message
- 相同的错误在不同的平台,报的error message字符串也不一定一样
- Go使用的是一种更加可靠的办法来区分不同的error value.其核心是创建一个新的类型
PathError来描述错误.这个类型包括三个部分:Op(操作), Path(路径), 和err(真正的
error类型)
package os // PathError records an error and the operation and file path that casued it. type PathError struct { Op string Path string Err error } func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }
- 在定义了PathError之后,所有跟filepath相关的错误就不仅仅是一个简单的"报告error
message"的error类型了,而是包含"操作,路径,err"三个的PathError(但是从interface
的角度上来讲,它还是error类型),在得到这种类型之后,使用"#v"打印,就能验证我们
的设想
package main import ( "fmt" "os" ) func main() { _, err := os.Open("/no/such/file") fmt.Println(err) // %#v a Go-syntax representation of the value fmt.Printf("%#v\n", err) os.Exit(0) } // <===================OUTPUT===================> // open /no/such/file: no such file or directory // &os.PathError{Op:"open", Path:"/no/such/file", Err:0x2}
- 下面的代码是go如何去实现的IsNotExist.需要注意的是,我们这里的error只要是下面
三个值中的一个就可以确定其是IsNotExist:
- 等于syscall.ENOENT
- 等于os.ErrNotExist
- 是一个*PathError,其error部分是'syscall.ENOENT或者os.ErrNotExist'
- 代码如下
import ( "errors" "syscall" ) var ErrNotExist = errors.New("file does not exist") // IsNotExist returns a bolean indicating whether the error is known to // report that a file or directory does not exist. It is satisfied by // ErrNotExist as wll as some syscall errors. func IsNotExist(err error) bool { if pe, ok := err.(*PathError); ok { err = pe.Err } return err == syscall.ENOENT || err == ErrNotExist }
- 使用方法如下
_, err := os.Open("/no/such/file") fmt.Println(os.IsNotExist(err)) // "true"
- error产生后,其message会通过组合,"层层上报". PathError的结构可能在这个过程中 被破坏,所以Error discrimination需要在错误"上报"以前就要完成
Querying Behaviors with Interface Type Assertions
- 下面一段逻辑是我们模仿的net/http package里面写入content-type的代码.这段代码
需要两次调用Write(),分别写入"Content-Type",和"text/html"(一个例子)
func writeHeader(w io.Writer, contentType string) error { if _, err := w.Write([]byte("Content-Type: ")); err != nil { return err } if _, err := w.Write([]byte(contentType)); err != nil { return err } // ... }
- 注意,因为Write需要类型[]byte,所以显示的类型转换[]bytes()的conversiont是必须 的.但是这个conversion却有一个问题:为了创建临时的byte[]类型的变量,会申请一份 内存来存放这个临时变量.而且几乎在函数调用完毕之后.这块内存就被抛弃了
- 这个写入header的代码是核心的代码,会被无数次调用.所以直接写入byte[]不是一个好 的选择:我们希望直接写入string类型
- 这里说起来就有故事了.这里的w是一个interface value,其dynamic type肯定是能满
足io.Writer的,但是我们可以给这个dynamic type"多做点工作",让它也能写入string.
而net/http里面的的dynamic type就真的做了这么一个函数:
- net/http里面的io.Writer的concrete类型是Writer:
type Writer struct { err error buf []byte n int wr io.Writer }
- Writer它实现了io.Writer interface
func (b *Writer) Write(p []byte) (nn int, err error) { for len(p) > b.Available() && b.err == nil { var n int if b.Buffered() == 0 { // Large write, empty buffer. // Write directly from p to avoid copy. n, b.err = b.wr.Write(p) } else { n = copy(b.buf[b.n:], p) b.n += n b.flush() } nn += n p = p[n:] } if b.err != nil { return nn, b.err } n := copy(b.buf[b.n:], p) b.n += n nn += n return nn, nil }
- 以及WriteString
func (b *Writer) WriteString(s string) (int, error) { nn := 0 for len(s) > b.Available() && b.err == nil { n := copy(b.buf[b.n:], s) b.n += n nn += n s = s[n:] b.flush() } if b.err != nil { return nn, b.err } n := copy(b.buf[b.n:], s) b.n += n nn += n return nn, nil }
- net/http里面的io.Writer的concrete类型是Writer:
- 这种实现WriteString的方法看起来有点像"灰色地带",但其实很多满足io.Writer接口 concrete的类型,都"偷偷"的实现了WriteString,比如*byte.Buffer, *os.File和 *bufio.Writer
- 好了,你net/http偷偷实现了WriteStirng,但是我不能assume任何一个io.Writer的w都
有这个福气.毕竟io.Writer只能意味着你实现了Write([]byte),所以我们这个时候又要
用到type assertion了.这里用到了一个技巧,就是临时创建一个interface(stringWriter)
这个类型里面只有WriteString()一个函数,我们能assert这个临时类型成功的话,新的
sw就"扩展了自己的method",就肯定可以调用WriteString啦,否则就调用效率较差的Write()
// writeString writes s to w // If w has a WriteString method, it is invoked insted of w.Write func writeString(w io.Writer, s string) (n int, err error) { type stringWriter interface { WriteString(string) (n int, err error) } if sw, ok := w.(stringWriter); ok { return sw.WriteString(s) // avoid a copy } return w.Write([]byte(s)) // allocate temporay copy } func writeHeader(w io.Writer, contentType string) error { if _, err := writeString(w, "Content-Type: "); err != nil { return err } if _, err := writeString(w, contentType); err != nil { return err } // ... }
- 这个例子最令人困惑的地方在于:并没有一个standard interface来定义WriteString, 并且描述清楚WriteString的行为特点.
- 我们能够使用WriteString来替代Write([]byte),其实是建立在我们默认WriteString 能够带来和Write([]byte)一样的效果.而WriteString在自己的documentation里面说 明了这一点.这也是Go开发和其他语言开发非常不一样的地方!但是在实际工作中,这样 做并不会有什么问题!
- fmt.Fprintf也使用了同样的"技巧"来区分一个value是不是error(fmt.Stringer)
package fmt func formatOneValue(x interface{}) string { if err, ok := x.(error); ok { return err.Error() } if str, ok := x.(Stringer); ok { return str.String() } // ... all other types... }
Type Switches
- 从我们已知的知识看,接口主要用在两个"截然不同"的领域:
- 第一个就是像io.Reader, io.Writer, http.Handler, error, sort.Interface一样 表达不同的concrete type之间"相同的部分(能够满足接口)",同时掩盖concrete的 实现细节,其重点是在"共享"的method上,而不是concrete type本身.这也是其他语言 对于interface的共同理解
- 第二个用法则有些不同:go和java不一样,go是一个'值语言', 满足interface的变量 是一个有内存地址的value.所以go里面是有interface value概念的.而一个interface value是可以存储完全不同的concrete type的,而interface则可以看成是这些类型的 "交汇点(union)": type assertion可以让我们的interface value伸缩成不同的type 从而有不同的method.这个用法的重点在于'concrete type',几个concrete type如果 实现了相同的interface,那么可以使用interface value把他们组织起来(使用type assertion来区分).这种特殊的使用interface的办法叫做discriminated unions
- 让我们来看看Go的查询SQL数据库的API,这个API和其他语言处理SQL的API一样,会把改
变的部分和不变的部分区分开,下面是一个例子
import "databse/sql" func listTracks(db sql.DB, artist string, minYear, maxYear int) { result, err := db.Exec( "SELECT * FROM tracks WHERE artist = ? AND ? <= year AND year <= ?", artist, minYear, maxYear) // ... }
- 这里有三个'?',分别对应于三个变量artist, minYear, maxYear.Exec函数会把所有'?', 出现的地方转换成字符串,而字符串的来源则是"对应的变量(比如artist, minYear)".
- 对应的变量可能是任意的类型,这就需要我们有一个逻辑判断:不同的类型转换成对应的
字符串,一个简单的实现如下
import "fmt" func sqlQuote(x interface{}) string { if x == nil { return "NULL" } else if _, ok := x.(int); ok { return fmt.Sprintf("%d", x) } else if _, ok := x.(uint); ok { return fmt.Sprintf("%d", x) } else if b, ok := x.(bool); ok { if b { return "TRUE" } return "FALSE" } else if s, ok := x.(string); ok { return sqlQuoteString(s) // 防止SQL注入 } else { panic(fmt.Sprintf("unexpected type %T: %v", x, x)) } }
- 这一段代码写下来让我们怀念如果有switch case就好了,然后go就果然为这种assertion
专门设计了一种switch(注意,这是switch的特例!switch后面跟关键字type显然不是正
常的例子).这种switch的样子如下
switch x.(type) { case nil: // ... case int, unint: // ... case bool: // ... case string: // ... default: // ... }
- 和普通switch一样,这里的switch"自带break":所以type里面有interface的时候,case 的顺序就非常重要了,因为可能有两个case都会被满足,先满足的就先返回了
- 我们注意到,上面if-else的例子中,我们有些时候还是需要"类型转换完"的变量的,比如
bool, string的case.为了能够满足这种需要,我们特例的switch还支持如下的"形变"
以便类型可以获得"转换完毕"之后的结果
switch x := x.(type) { /* ... */ }
- 我们这里"重用"了x作为"转换完毕"之后的结果,因为type switch"暗地里"创建了一个 新的lexical block.所以这次x的"重新赋值"不会影响到outer block.每个case也会重 新创建一个separate lexical block
- 前面if-else的代码,完整的重写代码如下
func sqlQuote(x interface{}) string { switch x := x.(type) { case nil: return "NULL" case int, uint: return fmt.Sprintf("%d", x) // x has type interface{} here. case bool: if x { return "TRUE" } return "FALSE" case string: return sqlQuoteString(x) // 防止SQL注入 default: panic(fmt.Sprintf("unexpected type %T: %v", x, x)) } }
- 在这个版本的代码中:
- 在每个'single case'里面,x的类型都跟'case后面的类型'完全相同!比如string, bool
- 如果不是'single case',那么x的类型还是interface{}, 比如int,uint那个case
- 在这个例子中,虽然x的类型是interface{},但是我们认为它是int, unit, bool, stirng, nil的"合体"
discriminated union of int, uint, boo, string and nil
Example: Token-Based XML Decoding
- 前面我们介绍了使用encoding/json里面的Marshal和Unmarshal来转换下面两个对象:
- json文件(string)
- Go data structure
- 如果我们希望创建一个document tree, 这种做法非常方便,但是大多数情况下,我们不 需要document tree.
- 如果不构建document tree,我们就希望有一个比较low-level的处理文档token的方法,
encoding/xml就为我们提供了这样一组token-based的API:
- 输入是string input
- 输出是是一系列的token(每次调用Token函数都会返回一个token),一共有四种类型:
- StartElement
- EndElement
- CharData
- Comment
- API部分的代码如下
package xml type Name struct { Local string // e.g., "Title" or "id" } type Attr struct { Name Name Value String } // A Token includes StartElement, EndElement, CharData, // and Comment, plus a few esoteric type (not shown). type Token interface{} type StartElement struct { Name Name Attr []Attr } type EndElement struct { Name Name } // e.g., </name> type Char Data []byte // e.g., <p>CharData</p> type Comment []byte // e.g., <!-- Comment --> type Decoder struct { /* ... */ } func NewDecoder(io.Reader) *Decoder func (*Decoder) Token() (Token, error) // returns next Token in sequence
- 我们这里的Token interface就是一个典型的discriminated union的应用,它不是其他 语言里面interface的用法(忽略各个type的不同,重视共同method,各个类型一视同仁), 因为它根本就没有method!!
- 没有method的interface也是有重大作用的,它可以作为"起作用的类型"的粘合剂(union) 对于这个'没有method的interface'的操作,在具体实施的时候,都会使用switch case 加上type assertion来挑选合适的concrete type来进行操作
- 下面就是典型的discriminated union的操作
package main import ( "encoding/xml" "fmt" "io" "os" "strings" ) func main() { dec := xml.NewDecoder(os.Stdin) var stack []string // stack of element names for { tok, err := dec.Token() if err == io.EOF { break } else if err != nil { fmt.Fprintf(os.Stderr, "xmlselect: %v\n", err) } switch tok := tok.(type) { case xml.StartElement: stack = append(stack, tok.Name.Local) // push case xml.EndElement: stack = stack[:len(stack)-1] // pop case xml.CharData: if containsAll(stack, os.Args[1:]) { fmt.Printf("%s: %s\n", strings.Join(stack, " "), tok) } } } fmt.Println() os.Exit(0) } // containsAll reports whether x contains the elements of y, in order. func containsAll(x, y []string) bool { for len(y) <= len(x) { if len(y) == 0 { return true } if x[0] == y[0] { y = y[1:] } x = x[1:] } return false } // <===================OUTPUT===================> // > wget http://www.w3.org/TR/2006/REC-xml11-20060816 // > cat REC-xml11-20060816 | go run discriminated_union.go div div h2 // html body div div h2: 1 Introduction // html body div div h2: 2 Documents // html body div div h2: 3 Logical Structures // html body div div h2: 4 Physical Structures // html body div div h2: 5 Conformance // html body div div h2: 6 Notation // html body div div h2: A References // html body div div h2: B Definitions for Character Normalization // html body div div h2: C Expansion of Entity and Character References (Non-Normative) // html body div div h2: D Deterministic Content Models (Non-Normative) // html body div div h2: E Autodetection of Character Encodings (Non-Normative) // html body div div h2: F W3C XML Working Group (Non-Normative) // html body div div h2: G W3C XML Core Working Group (Non-Normative) // html body div div h2: H Production Notes (Non-Normative) // html body div div h2: I Suggestions for XML Names (Non-Normative)
A Few Words of Advice
- 当设计新的package的时候,新手Go程序员往往会从创建一系列的interface开始,然后 让其他的concrete type来去implement这些接口(java就是这样).
- 这种设计会导致非常多的interface,而每种interface只有一个implementation,在Go 语言里面,这不是好的设计,应该禁止!
- 如果你想让某个type的method不"泄露",可以使用大小写规则的export mechanism,而 不要采取暴露interface(interface的method肯定外面可以看到),然后让某个concrete type来实现这个interface的method
- interface,绝大多数情况下只有在discriminated uniform的时候才会用得到(而且用的 很多还是空interface)
- 说绝大多数情况,那说明还有少部分情况下,也可以使用interface(即便只有一个 concrete type满足它),那就是在多个package之间合作的时候,interface是绝佳的对 象.因为concrete type有时候因为依赖的原因,无法在其他package出现
- 因为Go里面提倡一个interface至少有两三个concrate来实现它,所以Go里面的interface 通常都比较小,很多时候只有一个method,比如io.Writer, fmt.Stringer.
- 小的interface更容易被新的type所适应,而interface的最佳实践也要求
ask only for what you need
- Go对oo编程有非常好的支持,但是这不意味着你一定要使用object.很多时候standalone function也有他们绝佳的使用方法.
Chapter 08: Goroutines and Channels
- 所谓concurrent programming,就是把一个program表示成多个autonomous activity的 组合体(composition). 在当前的情况下,是最为重要的特性
- 当前的手机app就是一个concurrent的例子:在展现给用户动态信息的同时,在后台还要 同时进行进行网络和计算操作
- 即使是传统的batch 的问题(读取数据,计算,写入output)也会用到concurrency来利用 多核,同时提高在IO读取时候的效率
- Go支持两种concurrent programming:
- CSP: communicating sequential process(表现出来就是goroutine和channel):特点 是value在不同的独立activity(goroutine)之间进行传递,variable只能在一个activity 内部存在
- shared memory multithreadin:特点是thread之间会共享内存
Goroutines
- 在Go里面,每个正在执行的activity都叫做goroutine.比如在一个程序里面有两个function 一个做计算,另外一个写入output,如果两个function相互之间不调用,那么我们就可以 把他们放入到两个activity(goroutine)里面(也就可能同时运行,在有多个核的情况下)
- 如果你使用过thread,你可以吧goroutine当做是一种更加轻量级的thread
- 存在thread的语言里面,程序开始的时候,只有一个thread,就是main thread.同样的,在
go里面,程序开始的时候,只有一个goroutine,就是main goroutine. thread在c语言里
面就是直接作用于一个函数,在Go里面也是最小可以让一个函数作为一个goroutine,方
法是在函数前面加go
f() // call f(); wait for it to return go f() // create a new goroutine that call f(); don't wait
- 我们下面来看一个Go使用goroutine的例子:如果使用递归的方法来计算斐波那契数45
会是非常慢的一个过程,为了不让用户以为程序已经死掉了,我们使用另外一个goroutine
来打印"正在运算的提示符"
package main import ( "fmt" "os" "time" ) func main() { go spinner(100 * time.Microsecond) const n = 45 fibN := fib(n) fmt.Printf("\rFibonacci(%d) = %d\n", n, fibN) os.Exit(0) } func spinner(delay time.Duration) { for { for _, r := range `-\|/` { fmt.Printf("\r%c\n", r) time.Sleep(delay) } } } func fib(x int) int { if x < 2 { return x } return fib(x-1) + fib(x-2) }
- fib(45)会经过非常长的时间才会返回,在这期间,另外一个goroutine会每隔0.1秒就打 印一组"正在运行的提示".而当main goroutine计算完fib(45)并打印结果后,它自己会 返回.注意!当main goroutine返回的时候,所有其他的goroutine都会立马结束!
- 上面的情况下,我们可以说main goroutine通过返回的方式来关闭了其他的goroutine, 还有一种方式就是某一个goroutine可能会exit整个process,这样一来,其他的goroutine 也就不得不返回了.这是仅有的两种"关闭其他goroutine"的方法.Go里面不存在其他关 闭其他goroutine的方法.但是后面我们会看到,一个goroutine可以request其他goroutine 关闭.当然听不听是另外一回事了
- 本节的例子其实就是把如下两个activity进行了compose:
- spinning
- Fibonacci computation
Example: Concurrent Clock Server
- 网络是一个天然的使用concurrency的difang,yinwserver就是默认要同时处理多个不同 的client发来的connection,而且每个client都是相互独立的.(如果从http协议的角度 上来看,甚至每个connection都是独立的)
- 前面我们介绍过net/http package,为我们提供了HTTP的网络的函数.这里我们会使用net
package,它会提供更多网络连接的函数,比如:
- TCP socket
- UDP socket
- Unix domain socket
- 首先,我们来看看一个"反例":一个线性的clock server: sequential clock server
package main import ( "fmt" "io" "log" "net" "os" "time" ) func main() { listener, err := net.Listen("tcp", "localhost:8000") if err != nil { log.Fatal(err) } for { conn, err := listener.Accept() if err != nil { log.Print(err) continue } handleConn(conn) } fmt.Println() os.Exit(0) } func handleConn(c net.Conn) { defer c.Close() for { _, err := io.WriteString(c, time.Now().Format("15:04:05\n")) if err != nil { return // e.g., client disconnected } time.Sleep(1 * time.Second) } }
- 每当有client连接到这个server,这个server会每一秒都写入一个世界给client.功能 上没有什么问题,它的问题在于:每次只能处理一个connection!
- 我们来简单的看个这个例子,这个例子大部分是TCP的知识:
- net.Listen函数是创建listening socket的函数,返回一个listener object
- listener object调用Accept()之后,会一直block,直到有client来"访问",才会返回 注意,Accept()一旦返回,会返回一个net.Conn类型的object(不再是listening socket,而是一个connected socket).
- 正是因为accepted connection和listening connection不相同,所以我们可以在每个 handleConn里面,上来就defer close这个connectin
- handleConn是一个死循环,退出的唯一可能就是WriteString失败,一般也就是意味着 client主动disconnect
- handleConn里面使用了Time.Format函数,这个函数的参数非常有意思,它是一个example,
这是Go里面特有的:接受一个example来作为参数,这种写法明显比HH/MM的样式要直观
如果我们想加上月份和星期几的时候,直接在例子上加上字符串就可以了.位置随意!
_, err := io.WriteString(c, time.Now().Format("Mon Jan 15:04:05\n"))
- 我们使用netcat命令就可以模仿client的访问
> nc localhost 8000 13:58:54 13:58:55 13:58:56
- netcat的原理很简单,我们完全可以使用Go来实现一遍(代码中直接写死了8080)
package main import ( "fmt" "io" "log" "net" "os" ) func main() { conn, err := net.Dial("tcp", "localhost:8000") if err != nil { log.Fatal(err) } defer conn.Close() mustCopy(os.Stdout, conn) fmt.Println() os.Exit(0) } func mustCopy(dst io.Writer, src io.Reader) { if _, err := io.Copy(dst, src); err != nil { log.Fatal(err) } }
- 同时运行两个netcat1,我们会发现,只有第一个client结束了以后,另外一个client才
能获得时间!效果如下,左右是两个netcat1在运行
$ go build gopl.io/ch8/netcat1 $ ./netcat1 13:58:54 $ ./netcat1 13:58:55 13:58:56 ^C 13:58:57 13:58:58 13:58:59 ^C $ killall clock1 - 在Go里面,我们只需要更改server的其中一行,就能做到把sequential的server变成
concurrent的
for { conn, err := listener.Accept() if err != nil { log.Print(err) continue } go handleConn(conn) // Handle connections Concurrently! }
Example: Concurrent Echo Server
- 前面的例子最后的解决方案是每一个connection使用一个goroutine.每个connection 有一个goroutine是保证server concurrent的基本要求,我们的每个connection也是可 以多于一个goroutine的!因为有些时候业务逻辑比较复杂,一个goroutine无法满足要求 本章的echo server就是这样一个例子
- 普通的echo server业务逻辑没有那么复杂,它只是把client写入的内容,写回去代码如下
func handleConn(c net.Conn) { io.Copy(c, c) // NOTE: ignoring errors c.Close() }
- 我们这里的"需要多个goroutine"的echo server显然在逻辑上要麻烦一点,我们返回某
个字符串的三个版本:
- 首先返回一个大写版本,比如"HELLO"
- 然后过一会返回原始版本"Hello"
- 再过一会返回全小写版本"hello".
- 一个最简单的server代码如下
package main import ( "bufio" "fmt" "log" "net" "os" "strings" "time" ) func main() { listener, err := net.Listen("tcp", "localhost:8000") if err != nil { log.Fatal(err) } for { conn, err := listener.Accept() if err != nil { log.Print(err) continue } go handleConn(conn) } fmt.Println() os.Exit(0) } func echo(c net.Conn, shout string, delay time.Duration) { fmt.Fprintln(c, "\t", strings.ToUpper(shout)) time.Sleep(delay) fmt.Fprintln(c, "\t", shout) time.Sleep(delay) fmt.Fprintln(c, "\t", strings.ToLower(shout)) } func handleConn(c net.Conn) { input := bufio.NewScanner(c) for input.Scan() { echo(c, input.Text(), 1*time.Second) } c.Close() }
- client也要有相应的变化,就是要处理从stdin写入的数据到connection,然后要把connection
接受到的数据写给stdout,这里(netcat2)我们再次回用到goroutine
package main import ( "io" "log" "net" "os" ) func main() { conn, err := net.Dial("tcp", "localhost:8000") if err != nil { log.Fatal(err) } defer conn.Close() go mustCopy(os.Stdout, conn) mustCopy(conn, os.Stdin) } func mustCopy(dst io.Writer, src io.Reader) { if _, err := io.Copy(dst, src); err != nil { log.Fatal(err) } }
- 好了,我们来测试下效果(下面左边是client的输入,靠右的是server的返回)
$ go build gopl.io/ch8/reverb1 $ ./reverb1 & $ go build gopl.io/ch8/netcat2 $ ./netcat2 Hello? HELLO? Hello? hello? Is there anybody there? IS THERE ANYBODY THERE? Yooo-hooo! Is there anybody there? is there anybody there? YOOO-HOOO! Yooo-hooo! yooo-hooo! ^D $ killall reverb1 - 我们会看到非常奇怪的现象:第三个shout要等到第二个shout处理完才能进行,这显然是 不合理的,因为我们的client处理又被"线性化"了.而一个real echo是三次shout相互 之间必须是independent的,而不能"必须一起处理",而block其他的shout(因为我们所有 的输入是在同一个client里面,所以go handleConn是无法分出其他的goroutine的).
- 所以,我们要做的,就是把三次shout处理"独立化",方法还是使用go:让处理每次stdin
的输入有有个自己的goroutine
func handleConn(c net.Conn) { input := bufio.NewScanner(c) for input.Scan() { go echo(c, input.Text(), 1*time.Second) } c.Close() }
Channels
- 如果说goroutine是Go program里面的"并行"的activity的话,那么channel就是和这些 activity之间的connection
- Channel是让一个goroutine传递数据给另外一个goroutine的"通信手段"(communication mechanism)
- channel这个名字非常形象化,更形象的是每个channel都是有类型的.换句话说就是在 某种类型的channel里面只能传递某种类型的数据. channel的类型叫做element type. element的写法是chan typex. chan typex类型的channel只能传递typex
- chan int类型channel的创建方法如下
ch := make(chan int) // ch has type 'chan int'
- channel是reference类型(所有可以使用make创建的类型都是reference类型),既然是
reference类型,那么就都满足如下特点:
- 拷贝或者传递数据的时候,拷贝的和被拷贝的都会指向同一个data structure
- reference 类型zero value是nil
- 两个element type相同的channel可以相互比较,使用==.如果两者指向同一个data structure,那么==结果为true,否则为false
- channel有两个主要的操作.叫做send和receive.其实说这是channel的操作有点"不正
确",因为在这两个动作里面,channel都是作为"被动接受者".
- send a statement,其实是"变量"send一个statement给channel, send这个动作是变
量做出来的
ch <- x
- receive expression,,其实是"变量"receive一个expression,receive这个动作也是
变量来"receive"
x = <- ch
- receive statement也可以直接丢弃result
<- ch
- send a statement,其实是"变量"send一个statement给channel, send这个动作是变
量做出来的
- channel还接受第三种操作,就是close.一旦close一个channel以后:
- 其他变量不可以再send statement给这个channel
- 其他变量可以再receive statement,直到这个channel里面没有value可以在读取了. 在没有了value之后,再次读取的话,会马上返回zero value
- close的方法如下
close(ch)
- make()使用一个参数来创建channel的方法,创建出来的是unbuffered channel,也就是
buffer size为0,换句话说如下两句等价
ch = make(chan int) // unbuffered channel ch = make(chan int, 0) // unbuffered channel
- make接受第二个参数来设置channel的capacity,大于零的情况下,就设置了buffer size
的大小
ch = make(chan int, 3) // buffered channel with capacity 3
Unbuffered Channels
- 当我们(goroutine X)send数据给某个unbuffered channel的时候,我们的goroutineX
会在如下两个时间点之间处于block的状态:
- 我们(goroutine X)成功send数据给channel
- 其他goroutine Y成功从这个channl读取(receive)
- 一般情况下,我们写代码的时候,会先写其他goroutineY读取(receive)的代码,这个时
候因为channel里面没数据,所以goroutineY也是会block的.但是其他goroutine Block
没有事,我们main goroutine还可以运行.如果反过来先使用main goroutin来send的
话,程序会无限block下去(其实go编译器不会那么傻的,它会报deadlock的错误)
package main import ( "fmt" "os" "time" ) func fetch(ch chan int) { time.Sleep(4000 * time.Millisecond) var ret int ret = <-ch fmt.Println(ret) } func main() { fmt.Println("BEG") x := 12 ch := make(chan int) ch <- x go fetch(ch) fmt.Println() fmt.Println("END") os.Exit(0) } // <===================OUTPUT===================> // BEG // fatal error: all goroutines are asleep - deadlock! // // goroutine 1 [chan send]: // main.main() // /Users/hfeng/tmp/inf.go:22 +0xef // exit status 2
- 最经常的写法是调换send和receive的位置(注意,我们这里有两个output,意思是至少
可能有两种不同的输出)
package main import ( "fmt" "os" "time" ) func fetch(ch chan int) { time.Sleep(4000 * time.Millisecond) var ret int ret = <-ch fmt.Println(ret) } func main() { fmt.Println("BEG") x := 12 ch := make(chan int) go fetch(ch) ch <- x fmt.Println() fmt.Println("END") os.Exit(0) } // <===================OUTPUT1===================> // BEG // // END // 12 // <===================OUTPUT2===================> // BEG // // 12 // END
- 上面的例子告诉我们,在数据传输完之后,两个goroutine可能分别开始运行(或者一个
运行,或者两个都不运行),之后的情况下就依赖编译器等条件了.我们试着试了试main
goroutine比子goroutine多3微妙的情况下,会大概率同时出现"等得到子goroutine"
和"等不及子goroutine"两种情况:
package main import ( "fmt" "os" "time" ) func fetch(ch chan int) { var ret int ret = <-ch time.Sleep(1000 * time.Millisecond) fmt.Println(ret) } func main() { fmt.Println("BEG") x := 12 ch := make(chan int) go fetch(ch) ch <- x fmt.Println("END") time.Sleep(1003 * time.Millisecond) os.Exit(0) } // <===================OUTPUT1===================> // BEG // END // <===================OUTPUT2===================> // BEG // END // 12
- 但是可以肯定的是:
- 在我们send数据之前, receive肯定是block的
- 在我们receive之前,开始的send也肯定是block的
- 换句话说,通过unbuffered channel,我们synchronize了如下两个goroutine:
- sending goroutine
- receive goroutine
- 所以unbuffered channel有些时候被称作synchronous channel:其作用概况起来就是
当一个value被发送到unbuffered channel上的时候,可以保证"接受到这个数据"发生
的时间比"发送的goroutine重新苏醒"的时间要早
When a value is sent on an unbuffered channel, the receipt of the value happens before the reawakening of the sending goroutine
- 在并发编程的语境里面, 'x在y之前发生'并不仅仅意味着x在时间上早于y运行,而是 意味着一种"依赖关系",因为y发生"肯定比x"晚,我们可以把y需要的一些必要的准备 放在x里面,这样当y发生的时候,x已经把它所需要的都准备好了!
- 当我们不能保证x一定发生在y之前的时候,我没说x是和y并发发生的
x is concurrent with y
- x和y是并发的,也不一定说"x和y一定同时发生",而是说y(或者x)不能指望自己的准备 工作让对方来做了,因为咱们谁先开始还不一定呢.
- goroutine x和 goroutin y是并发的,会让他们变的危险,因为他们可能会同时"访问 一块内存",如果有"同步的goroutine存在"我们就需要一些手段来保证同一时刻某块 内存只能有一个goroutine能访问
- unbuffer channel可以synchronize两个goroutine这件事情,可以用来让main goroutine
等待"其他goroutine".main goroutine一旦结束,无论其他goroutine是否运行完毕,程
序都会立刻结束.所以如果我们希望main goroutine等待其他goroutine的话,可以在
main goroutine和其他goroutine直接设置一个unbuffer channel,并且让main goroutine
依赖于其他goroutine
package main import ( "io" "log" "os" ) func main() { conn, err := net.Dail("tcp", "localhost:8000") if err != nil { log.Fatal(err) } done := make(chan struct{}) go func() { // anyonmous function! io.Copy(os.Stdout, conn) // Note: ignoring errors log.Println("done") done <- struct{}{} // signal the main goroutine }() mustCopy(conn, os.Stdin) conn.Close() <-done // wait for background goroutine to finish }
- 上面这个例子当用户关闭standard input stream的时候"第二个"mustCopy就返回了,
然后main goroutine开始调用conn.Close()关闭了network connection.这个关闭过
程就是我们常说由client发起的的"四次分手",四次分手其实是:
- main client首先关闭conn的write half,表示不会再往里面写了,对面的server会 收到FIN也就是end-of-file condition
- 然后server收到main client不再写conn的表示后,知道client close了,自己也再 ACK client FIN的同时发送FIN给client,也就关闭了conn的read half.
- 然后background goroutine再想去"读取"这个conn的时候,就被告知不行了"read from closed conneciton error'
- background goroutine的io.Copy失败以后,自然就会返回啦,然后会写入channel里面 一个struct{}{}, main goroutine也就等到结果啦!
- 通常来说发往channel里面的message的value都是包含着"通信"的意味,其内容也必然 重要.但是在上述情况下,其实更重要的是这个message发过来了,其value并不重要.换 句话说,这个message只起到了同步的作用,为了强调这一点,我们往往使用一个特殊的 类型struct{}.当然bool或者int也可以.
Pipelines
- channel可以用来连接goroutines,从而让某个goroutine的输出作为另外一个goroutine
的输入.这叫做pipeline(和bash里面的pipeline很像).下面就是一个这样的例子
+---------+ +-----------+ +---------+ | Counter | 0, 1, 2, 3 | Squarer | 0, 1, 4, 9 | Printer | | |------------>| |------------->| | +---------+ +-----------+ +---------+
- 第一个counter goroutine会产生0, 1, 2, 3这些数字,然后发送给第二个squarer goroutine.
- 第二个squarer goroutine会接受counter产生的数字,计算他们的乘方,然后发送给第 三个printer goroutine
- 第三个printer goroutine会接受squarer发送的数字,打印到standard output
- 代码如下,这个程序会一直打印下去,不会停
package main import ( "fmt" "os" ) func main() { naturals := make(chan int) squares := make(chan int) // Counter go func() { for x := 0; ; x++ { naturals <- x } }() // Squarer go func() { for { x := <-naturals squares <- x * x } }() // Printer (in main goroutine) for { fmt.Println(<-squares) } os.Exit(0) } // <===================OUTPUT===================> // 0 // 1 // 4 // 9 // 16 // 25 // 36 // 49 // 64 // 81 // 100 // ...
- 有时候我们产生的数字是有限的,那么我们就不需要一直运行下去."不再想往某个
channel里面传输数据"这件事情,可以使用close(chanelVar)来做到,一旦close了某个
channel:
- 继续向这个channel写数据的话,程序会panic
- channel里面该读取的数据读取完了以后,再次读取,总是会读到zero value
- 读到zero value这件事情,其实并不能说明什么.如下例,虽然后面一直读到0,但是第一
次也是读到了0啊,不能说读到零就有错误
package main import ( "fmt" "os" ) func main() { naturals := make(chan int) squares := make(chan int) // Counter go func() { for x := 0; x < 11; x++ { naturals <- x } close(naturals) }() // Squarer go func() { for { x := <-naturals squares <- x * x } }() // Printer (in main goroutine) for { fmt.Println(<-squares) } os.Exit(0) } // <===================OUTPUT===================> // 0 // 1 // 4 // 9 // 16 // 25 // 36 // 49 // 64 // 81 // 100 // 0 // 0 // 0 // 0 // ...
- 一个可能的方案是传递两个value给channel,第二个value来判断是否channel已经被
closed
// Squarer go func() { for { x, ok := <- naturals if !ok { break // channel was closed and drained } squares <- x * x } close(squares) }()
- 但是显然这样太麻烦了,而且"读取一个channel直到其被close"是如此的常用,以至于
go内置了这个feature,让range能够操作channel,range循环结束的条件就是channel
被关闭了.
package main import ( "fmt" "os" ) func main() { naturals := make(chan int) squares := make(chan int) // Counter go func() { for x := 0; x < 11; x++ { naturals <- x } close(naturals) }() // Squarer go func() { for x := range naturals { squares <- x * x } close(squares) }() // Printer (in main goroutine) for x := range squares { fmt.Println(x) } os.Exit(0) } // <===================OUTPUT===================> // 0 // 1 // 4 // 9 // 16 // 25 // 36 // 49 // 64 // 81 // 100
- channel并不是像"打开的文件描述符"一样是一个必须要close的资源.你close一个 channel并不是说想释放资源,而是想告诉receiving goroutine,所有的数据已经传输 完毕
- 所有试图close一个already-closed channel的行为都会panic,close一个nil channel 也会panic
Unidirectional Channel Types
- 随着程序规模的增加,我们会把程序分成多个部分.上面的例子是把程序的逻辑分成了 三个goroutine,然后通过两个channel通信,是这两个channel是main的local variable
- 我们也可以把上面的三个步骤直接设计成函数
func counter(out chan int) func squarter(out, in chan int) func printer(in chan int)
- 我们发现,来来回回,就两个channel,在squarter里面有清晰的表述:
- in channel:负责从这个channel读取
- out chan:负责写入到这个channel
- 它们的名字很清晰的告诉了我们这一点,in就是读取的,out就是写入的.但这只是习惯 上的约束,你还是可以从out读取,从in写入.
- 因为这种情况非常常见,Go把这种"名字上的约束"转换成了"编译器的约束":只暴露channel
的send或者receive操作.注意这里用的是暴露,指的是使用编译器的力量来检查某些
channel变量(reference)只能读取或者写入.但是这些channel的实例(instance)在别
的,不受控制的环境下,还是可以"既读取,又写入"
Go type system provides unidirectional channel types that expose only one or the other of the send and receive operations.
- 这两种unidirectional channel类型分别是:
- send-only channel int如下.这种只能send,但是不能receive,如果试图从这个channel
里面receive的话,会在compile time就报错.send-only channel也是可以被closed,
因为close的定义就是:不允许向channel send更多的数据
chan<- int
- receive-only channel int如下.这种只能receive,但是不能send,如果试图send到
这个channel的话,会在compile time报错.receive-only channel是不可以被close
的,一旦试图close receive-only channel也是会触发compile time error
<-chan int
- send-only channel int如下.这种只能send,但是不能receive,如果试图从这个channel
里面receive的话,会在compile time就报错.send-only channel也是可以被closed,
因为close的定义就是:不允许向channel send更多的数据
- 例子如下.
package main import ( "fmt" "os" ) func counter(out chan<- int) { for x := 0; x < 10; x++ { out <- x } close(out) } func squarer(out chan<- int, in <-chan int) { for v := range in { out <- v * v } close(out) } func printer(in <-chan int) { for v := range in { fmt.Println(v) } } func main() { naturals := make(chan int) squares := make(chan int) go counter(naturals) go squarer(squares, naturals) printer(squares) os.Exit(0) } // <===================OUTPUT===================> // 0 // 1 // 4 // 9 // 16 // 25 // 36 // 49 // 64 // 81
- 一个非常值得注意的地方是从bidirectional到unidirectional channel是默认允许的
而且不需要显式转换的,但是从unidirectional channel到bidirectional channel的
转换是不允许的!
Conversions from bidirectional to unidirectional channel types are permitted in any assignment. There is no going back, however: once you have a value of a unidirectional type such as chan<- int, there is no way to obtain from it a value fo type chan int that refers to the same channel data structure
Buffered Channels
- 既然说到了unbuffered channel,那就有必要再说说buffered channel,buffered channel
的size是在创建的时候通过make的第二个参数来决定的,比如创建一个三个string容
量的buffer,方法如下
ch = make(chan string, 3)
- 创建完之后,其情况如下
+---+---+---+ +--> | / | / | / | | +---+---+---+ +---+ | |ch |----+ +---+ - 创建channel完之后,我们可以通过send向channel发送数据.注意,数据是以"先进先出"
的方式加入到channel的buffer里面的,换句话说channel的buffer的一个queue结构,
我们试着写入三个字符串
ch <- "A" ch <- "B" ch <- "C"
- 这个时候channel的buffer已经满了,其状态为
+---+---+---+ +--> |"A"|"B"|"C"| | +---+---+---+ +---+ | |ch |----+ +---+ - 在这个状态下,继续send就会block,如果我们receive一个,代码如下
fmt.Println(<-ch) // "A"
- 这个时候属于既不full,也不empty的状态,如下
+---+---+---+ +--> |"B"|"C"| / | | +---+---+---+ +---+ | |ch |----+ +---+ - 这种状态下,无论是send还是receive都不会block了.channel就是通过这种方式"解耦 了"sending goroutine和receiving goroutine
- 很少的情况下,程序需要知道channel的buffer大小.方法是
fmt.Println(cap(ch)) // "3"
- 而len()返回的则是"当前"channel里面元素的个数.注意!因为是在并发的情况下,所以
这个统计是刚产生出来,就马上过期的,所以是不准确的.只有在某些特定的情况下会
使用
fmt.Println(len(ch)) // "2"
- 我们继续receive,当receive到第四个的时候,因为buffer已经空了,所以继续receive
是会继续block
fmt.Println(<-ch) // "B" fmt.Println(<-ch) // "C"
- 在这个例子里面,send和receive operation都发生在一个goroutine里面,但是在真实
的程序里面,send和receive通常是在不同的goroutine里面完成的.新手容易犯的一个
错误,就是把buffered channel在某一个goroutine里面当做queue来使用.但这是一个
错误的用法
It is a mistake to use buffered channels within a single goroutine as a queue
- 错误的原因在于,channel是和goroutine scheduling紧密联系的,如果没有另外的 goroutine对channel进行receiving操作,那么sender goroutine就有可能会变成永远 的block!
- 正确的用法是使用slice来作为"先进先出"的queue就可以了.
- 下面的例子展示了一个buffered channel的用法.这个程序会"同时"发送request到不
同的三个mirror(内容相同但是地理位置不同的server叫mirror).这三个request的
response会send到一个叫做`responses`的buffered channel.
func mirroredQuery() string { responses := make(chan string, 3) go func() { responses <- request("asia.gopl.io") }() go func() { responses <- request("europe.gopl.io") }() go func() { responses <- request("americas.gopl.io") }() return <-responses } func request(hostname string) (respose string) { /* ... */ }
- buffered channel只会返回第一个(也就是返回速度最快的那个!)这样我们可以做到
其他的mirror test还没完成的时候,我们的mirroredQuery()函数已经返回了!如果有
些mirror特别慢的话,这个特性就会非常的有用!
mirroredQuery returns a result even before the two slower servers have responded.
- 如果我们这里使用了unbuffered的话,我们会造成非常严重的后果:goroutine leak, go虽然是自动回收内存,但是很多其他资源,比如文件描述符,数据库句柄是无法自动释 放的,需要手动close.这里的goroutine虽然不需要手动close,但是却要保证没有goroutine 一直在block
- 换句话说,我们有三个goroutine朝一个unbuffered channel里面send,而最终只receive 了一次,那么另外两个goroutine肯定是一直block在那里,goroutine肯定也是无法释放 的,这就造成了leak
- 编程的时候选择buffer或是unbuffered channel,需要知道两者的本质:
- unbuffered channel为send和receive增加了同步保证,事实上是耦合了两者
- buffered channel解耦了send和receive操作
- 如果用channel来连接不同的goroutine,只有每个goroutine都有相同的"速率"最终才 能产生类似流水线的效果
Looping in Parallel
- 这一节我们主要考虑一些常见的和循环相关的concurrency pattern
- 下面的API是把一个full-size的图片转换成thumbnail-size的图片,API实现的细节和
本节内容没关系,先不写
package thumbnail // ImageFile reads an image from infile and writes // a thumbnail-size version of it in the same directory. // It returns the generated file name, e.g., "foo.thumb.jpg". func ImageFile(infile string) (string, error)
- 最简单处理一系列image file的方法是使用循环
// makeThumbnails makes thumbnails of the specified files. func makeThumbnails(filesnames []string) { for _, f := range filenames { if _, err := thumbnail.ImageFile(f); err != nil { log.Println(err) } } }
- 很明显的是,我们处理图片的顺序,是没有关系的.谁先处理,谁后处理都不会影响最后
的结果.这种子问题之间相互独立的问题叫做embarrassingly parallel
Problems like this that consist entirely of subproblems that are completely independent of each other are described as embarrassingly parallel
- embarrassingly parallel 问题是最简单的并发问题,在多核的情况下,性能能够得到 线性的提升
- 我们先来看看最naive的改法,把每个处理函数都变成一个goroutine
// NOTE: incorect! import "gopl.io/ch8/thumbnail" func makeThumbnails(filenames []string) { for _, f := range filenames { go thumbnail.ImageFile(f) // NOTE: ignoring errors } }
- 这个解法运行的特别快,快到即便filenames里面只有一个成员的话,还是比上个版本快 得多.细心的人发现了这肯定里面有问题.
- 问题就是这个解法错了,错在为每个函数创建了一个goroutine以后,main函数就返回了 并没有等待它创建的goroutine完成!
- 因为goroutine不是thread,所以,并没有直接的方法让main函数来等待goroutine完成
在go里面,能够做到这一点(goroutine之间通信)的,只能是channel.所以我们申请一个
unbuffered channel,然后每个goroutine写入channel,最后channel receive 一个特定
的次数:len(filename)
// makeThumbnails makes thumbnails of the specified files in parallel. func makeThumbnails3(filenames []string) { ch := make(chan struct{}) for _, f := range filenames { go func(f string) { thumbnail.ImageFiles(f) // Note ignoring errors ch <= struct{}{} }(f) } // wait for goroutines to complete for range filenames { <-ch } }
- 注意,我们这里的goroutine的函数是有参数的(f string), 而不是像下面这样之间把
f作为匿名函数的参赛传递进去,因为这会导致问题(只处理最后一个, 我们在5.6.1部分
讲过)
// NOTE: incorrect for _, f := range filenames { go func() { thumbnail.ImageFile(f) // NOTE: incorrect! // ... }() }
- 好的,我们暂时获得了一个比较正确的版本.然后,新的需求来了,我们需要把每个worker
的错误信息返回到main.这种情况下,很容易犯错误,因为unbuffered channel满足不了
需求了.下面就是一个典型的错误做法.因为一旦出现了一个error,那么函数就返回了,
所以在循环体里面的<-errors就再也不允许了,那么unbuffered channel就一直无法让
其他的goroutine send入了
// makeThumbnails4 makes thumbnails for the specified files in paralles. // It returns an error if any step failed. func makeThumbnails4(filenames []string) error { errors := make(chan error) for _, f := range filenames { go func(f string) { _, err := thumbnail.ImageFile(f) errors <- err }(f) } for range filenames { if err := <- errors; err != nil { return err // NOTE: incorrect: goroutine leak! } } return nil }
- 解决的办法自然是使用buffered channel啦,就算是中途退出了,其他的goroutine也可
以最终把自己的结果都发送到buffered channel里面,不至于leak goroutine.buffer
的大小就按照最多的情况考虑,filenames的length
// makeThumbnails5 makes thumbnails for the specified files in paralles. // It returns the generated file names in an arbitrary order, // or an error if any step failed. func makeThumbnails5(filenames []string) (thumbfiles []string, err error) { type item struct { thumbfile string err error } ch := make(ch item, len(filenames)) for _, f := range filenames { go func(f string) { var it item it.thumbfile, it.err = thumbnail.ImageFile(f) ch <- it }(f) } for range filenames { it := <- ch if it.err != nil { return nil, it.err } thumbfiles = append(thumbfiles, it.thumbfile) } return thumbfiles, nil }
- 好了,我们的代码又比较完善了,但是这个时候.新的需求又来了:我们不知道有多少的 image file等待处理,所以不能通过slice来传递fileName给我了,而是通过一个channel 来传递.
- 所以这个问题的关键就转换为我们如何记录channel传递来了多少的fileName.这明显是
一个counter,但是我们肯定不可以使用简单的counter,因为这是多goroutine的环境下
面.所以我们的选择是sync.WatiGroup.它的特点就是
A counter that can be safely manipulated from multiple goroutines and that provides a way to wait until it becomes zero
- 代码如下
- 我们看到这个代码的特点, 这些特点适用于处理所有的"不知道数目的loop"的并发操作:
- Add是用来增加counter的,它必须在worker goroutine开始之前调用.因为我们要保 证在wg.Wait()之前Add
- Add有参数1,但是Done却没有参数, 没有参数的Done等同于Add(-1)
- 我们用defer来保证即便出现了error,我们的counter也能够decrement
- 我们新的函数需要返回处理的所有的文件的size,我们是通过一个channel(sizes)来统 计这些信息的.最后通过一个range来读取全部的size
- 我们还要注意的是,我们的closer goroutine是:
- 先Wait(),然后close(sizes)
- closer goroutine必须和loop over size做到并行
- 这两部都是必须的,因为:
- 如果wait在main goroutine里面,并且在loop前面,那么这个函数会死循环, 因为defer
wg Done()这一句要等待sizes<-完成.但是你在main里面确先要Wait(),然后才close()
所以这两个条件的顺序反了,会发生deadlock
package main import ( "log" "os" "sync" ) func main() { arr := []int{1, 2, 3, 4} var wg sync.WaitGroup sizes := make(chan int) for _, a := range arr { wg.Add(1) // worker go func(a int) { defer wg.Done() log.Printf("%d\n", a) sizes <- a }(a) } wg.Wait() close(sizes) var total int for size := range sizes { total += size } log.Printf("%s at %d\n", "finish", total) os.Exit(0) } // <===================OUTPUT===================> // 2017/04/12 11:03:17 4 // 2017/04/12 11:03:17 3 // 2017/04/12 11:03:17 1 // 2017/04/12 11:03:17 2 // fatal error: all goroutines are asleep - deadlock!
- 如果wait在main goroutine里面,并且在loop后面,那么这个代码就永远不会触及到:
因为关闭(close(sizes))的代码再后面,这个channel永远不会关闭,那么range也就
无法完成(没关闭怎么知道一共有多少)
package main import ( "log" "os" "sync" ) func main() { arr := []int{1, 2, 3, 4} var wg sync.WaitGroup sizes := make(chan int) for _, a := range arr { wg.Add(1) // worker go func(a int) { defer wg.Done() log.Printf("%d\n", a) sizes <- a }(a) } var total int for size := range sizes { total += size } wg.Wait() close(sizes) log.Printf("%s at %d\n", "finish", total) os.Exit(0) } // <===================OUTPUT===================> // 2017/04/12 11:03:40 4 // 2017/04/12 11:03:40 1 // 2017/04/12 11:03:40 2 // 2017/04/12 11:03:40 3 // fatal error: all goroutines are asleep - deadlock!
- 即便使用了go func来做closer goroutine,那么也需要在range sizes之前,因为在
range sizes的后面的话,因为closer goroutine在后面,range size不完的话,closer
goroutine根本无法启动嘛!
package main import ( "fmt" "log" "os" "sync" ) func main() { arr := []int{1, 2, 3, 4} var wg sync.WaitGroup sizes := make(chan int) for _, a := range arr { wg.Add(1) // worker go func(a int) { defer wg.Done() log.Printf("%d\n", a) sizes <- a }(a) } var total int for size := range sizes { total += size } fmt.Println("can not go here") go func() { wg.Wait() close(sizes) }() log.Printf("%s at %d\n", "finish", total) os.Exit(0) } // <===================OUTPUT===================> // 2017/04/12 11:05:56 2 // 2017/04/12 11:05:56 4 // 2017/04/12 11:05:56 3 // 2017/04/12 11:05:56 1 // fatal error: all goroutines are asleep - deadlock!
- 正确的简化例子应该如下
package main import ( "log" "os" "sync" ) func main() { arr := []int{1, 2, 3, 4} var wg sync.WaitGroup sizes := make(chan int) for _, a := range arr { wg.Add(1) // worker go func(a int) { defer wg.Done() log.Printf("%d\n", a) sizes <- a }(a) } go func() { wg.Wait() close(sizes) }() var total int for size := range sizes { total += size } log.Printf("%s at %d\n", "finish", total) os.Exit(0) } // <===================OUTPUT===================> // 2017/04/12 11:05:33 3 // 2017/04/12 11:05:33 4 // 2017/04/12 11:05:33 2 // 2017/04/12 11:05:33 1 // 2017/04/12 11:05:33 finish at 10
- 如果wait在main goroutine里面,并且在loop前面,那么这个函数会死循环, 因为defer
wg Done()这一句要等待sizes<-完成.但是你在main里面确先要Wait(),然后才close()
所以这两个条件的顺序反了,会发生deadlock
Example: Concurrent Web Crawler
- 在5.6节中,我们设计了一个breadth-first的爬虫,其代码如下
// Findlinks3 crawls the web, starting with the URLs on the command line. package main import ( "fmt" "log" "os" "gopl.io/ch5/links" ) //!+breadthFirst // breadthFirst calls f for each item in the worklist. // Any items returned by f are added to the worklist. // f is called at most once for each item. func breadthFirst(f func(item string) []string, worklist []string) { seen := make(map[string]bool) for len(worklist) > 0 { items := worklist worklist = nil for _, item := range items { if !seen[item] { seen[item] = true worklist = append(worklist, f(item)...) } } } } //!-breadthFirst //!+crawl func crawl(url string) []string { fmt.Println(url) list, err := links.Extract(url) if err != nil { log.Print(err) } return list } //!-crawl //!+main func main() { // Crawl the web breadth-first, // starting from the command-line arguments. breadthFirst(crawl, os.Args[1:]) } //!-main // <===================OUTPUT===================> // $ go run findlinks.go https://golang.org // https://golang.org // https://golang.org/ // https://golang.org/doc/ // https://golang.org/pkg/ // https://golang.org/project/ // https://golang.org/help/ // https://golang.org/blog/ // http://play.golang.org/ // https://tour.golang.org/ // https://golang.org/dl/ // https://blog.golang.org/ // https://developers.google.com/site-policies#restrictions // https://golang.org/LICENSE // https://golang.org/doc/tos.html // http://www.google.com/intl/en/policies/privacy/ // https://golang.org/doc/install // https://code.google.com/p/go-tour/
- 这个例子的核心就是函数crawl(),但是在上面的例子中,我们只有一个goroutine来调 用(也就是main), 所以效率并不高,我们已经解除了goroutine,所以很自然的,我们希 望每个crawl的调用,都能分配到一个goroutine
- 最简单的改造方法就是如下了(main函数替代了原来的breadthFirst), 这种方法使用
worklist(类型为slice)来存储需要访问的url,初始化使用一个goroutine从命令行参
数设置初始值,这是为了防止deadlock.同时子goroutine都使用了link作为自己的函数
参数
// Copyright © 2016 Alan A. A. Donovan & Brian W. Kernighan. // License: https://creativecommons.org/licenses/by-nc-sa/4.0/ // See page 240. // Crawl1 crawls web links starting with the command-line arguments. // // This version quickly exhausts available file descriptors // due to excessive concurrent calls to links.Extract. // // Also, it never terminates because the worklist is never closed. package main import ( "fmt" "log" "os" "gopl.io/ch5/links" ) //!+crawl func crawl(url string) []string { fmt.Println(url) list, err := links.Extract(url) if err != nil { log.Print(err) } return list } //!-crawl //!+main func main() { worklist := make(chan []string) // Start with the command-line arguments. go func() { worklist <- os.Args[1:] }() // Crawl the web concurrently. seen := make(map[string]bool) for list := range worklist { for _, link := range list { if !seen[link] { seen[link] = true go func(link string) { worklist <- crawl(link) }(link) } } } } //!-main /* //!+output $ go build gopl.io/ch8/crawl1 $ ./crawl1 http://gopl.io/ http://gopl.io/ https://golang.org/help/ https://golang.org/doc/ https://golang.org/blog/ ... 2015/07/15 18:22:12 Get ...: dial tcp: lookup blog.golang.org: no such host 2015/07/15 18:22:12 Get ...: dial tcp 23.21.222.120:443: socket: too many open files ... //!-output */
- 这个看起来很美的版本,有着如下两个特别明显的问题:
- 运行速度过快,超过了可以打开的文件描述符的数目:goroutine可以完全无视任何的
限制创建,可能创建成千上万个,最终的结果就是拖垮了整个系统.解决的办法是把goroutine
的规模限制在20个,这个限制因为是在多线程的情况下做的,所以我们要使用多线程下
的限制手段buffered channel(同时只能允许20个goroutine获得资源,在教材中,这
种工具叫做counting semaphore)
// Copyright © 2016 Alan A. A. Donovan & Brian W. Kernighan. // License: https://creativecommons.org/licenses/by-nc-sa/4.0/ // See page 241. // Crawl2 crawls web links starting with the command-line arguments. // // This version uses a buffered channel as a counting semaphore // to limit the number of concurrent calls to links.Extract. package main import ( "fmt" "log" "os" "gopl.io/ch5/links" ) //!+sema // tokens is a counting semaphore used to // enforce a limit of 20 concurrent requests. var tokens = make(chan struct{}, 20) func crawl(url string) []string { fmt.Println(url) tokens <- struct{}{} // acquire a token list, err := links.Extract(url) <-tokens // release the token if err != nil { log.Print(err) } return list } //!-sema //!+ func main() { worklist := make(chan []string) var n int // number of pending sends to worklist // Start with the command-line arguments. n++ go func() { worklist <- os.Args[1:] }() // Crawl the web concurrently. seen := make(map[string]bool) for ; n > 0; n-- { list := <-worklist for _, link := range list { if !seen[link] { seen[link] = true n++ go func(link string) { worklist <- crawl(link) }(link) } } } } //!-
- 第二个问题就是这个程序永远都不会运行完(但是因为你的goroutine太多,很快就failed
了,所以你看不到这个结果).为了改正,我们需要加一个普通的计数器,来保证worklist
空了,并且没有crawl goroutine active的情况下,我们结束程序
func main() { worklist := make(chan []string) var n int // number of pending sends to worklist // Start with the command-line agruments n++ go func() { worklist <- os.Args[1:] }() // Crawl the web concurrently. seen := make(map[string]bool) for ; n > 0; n-- { list := <-worklist for _, link := range list { if !seen[link] { seen[link] = true n++ go func(link string) { worklist <- crawl(link) }(link) } } } }
- 运行速度过快,超过了可以打开的文件描述符的数目:goroutine可以完全无视任何的
限制创建,可能创建成千上万个,最终的结果就是拖垮了整个系统.解决的办法是把goroutine
的规模限制在20个,这个限制因为是在多线程的情况下做的,所以我们要使用多线程下
的限制手段buffered channel(同时只能允许20个goroutine获得资源,在教材中,这
种工具叫做counting semaphore)
Multiplexing with select
- 下面是一个模拟火箭发送过程的例子,例子中的time.Tick函数会返回一个channel,然后
他会每隔一段时间(设置在参数里面)向这个channel send内容(Time类型,所以channel
的类型也是channel)
package main import ( "fmt" "time" ) func main() { fmt.Println("Commencing countdown.") tick := time.Tick(1 * time.Second) for countdown := 10; countdown > 0; countdown-- { fmt.Println(countdown) <-tick } fmt.Println("launch!") } // <===================OUTPUT===================> // 10 // 9 // 8 // 7 // 6 // 5 // 4 // 3 // 2 // 1 // launch!
- 但是这个例子有个问题,火箭发射要倒数其实是为了在倒数的时候有问题的话,可以及时 停止,这里完全无法停止,所以要改进.
- 改进的办法就是再加一个另外一个goroutine来等待用户输入任意一个键,一旦捕捉到 就停止main goroutine的倒数,直接取消"火箭发射"
- 现在,我们main goroutine里面的loop就要"监听"两个不同的channel:
- ticker channel
- abort event(如果用户输入任何一个键)
- 我们要"同时"监听这两个channel,因为如果在loop里面"有先后"的监听某一个channel, 另外一个channel就会被block.所以很明显,我们需要新的特性,这个特性就是select
- select名字的来历,应该是BSD的socket里面的select system call.这个system call 可以"同时监听"多个文件(通过文件描述符)内容的变化,一旦有其中一个文件变化,就 返回并处理.
- 这里select的意思和select system call非常相近,只不过不是监听的文件,而是监听
的channel.我们用select来实现一个可以abort的火箭发射,代码如下
// Copyright © 2016 Alan A. A. Donovan & Brian W. Kernighan. // License: https://creativecommons.org/licenses/by-nc-sa/4.0/ // See page 244. // Countdown implements the countdown for a rocket launch. package main import ( "fmt" "os" "time" ) //!+ func main() { // ...create abort channel... //!- //!+abort abort := make(chan struct{}) go func() { os.Stdin.Read(make([]byte, 1)) // read a single byte abort <- struct{}{} }() //!-abort //!+ fmt.Println("Commencing countdown. Press return to abort.") select { case <-time.After(10 * time.Second): // Do nothing. case <-abort: fmt.Println("Launch aborted!") return } launch() } //!- func launch() { fmt.Println("Lift off!") } // <===================OUTPUT===================> // > go run countdown.go // Commencing countdown. Press return to abort. // q // Launch aborted! // > go run countdown.go // Commencing countdown. Press return to abort. // Lift off!
- select和switch不一样的地方在于,select的case并没有"前后顺序",它们的地位是相
同的,这也是为什么不能在channel上面使用switch关键字,因为这会让用户以为case会
有先后顺序.下面的例子,巧妙的利用了buffer为1的channel只可能处于两种状态:empty
或者full,所以select也只会碰到一个case ready的情况
package main import ( "fmt" "os" ) func main() { ch := make(chan int, 1) for i := 0; i < 10; i++ { select { case x := <-ch: fmt.Println(x) case ch <- i: } } os.Exit(0) } // <===================OUTPUT===================> // 0 // 2 // 4 // 6 // 8
- 那么问题来了,如果select遇到多个case都ready的情况下,它怎么选呢?首先明确的是 select不是switch,所以不可能谁在前面选择谁.而是,随机的选择一个case进行下去, 是的,你没看错,是随机的选择一个case!
- 随机选择的原因是因为这样让每个case都有equal chance来得到运行的机会,我们来把
上面例子的buffer增大,这样select每次遇到的情况就不再是简单的"要么A ready,要么
B ready啦",它的运行结果,也会是随机的
package main import ( "fmt" "os" ) func main() { ch := make(chan int, 2) for i := 0; i < 10; i++ { select { case x := <-ch: fmt.Println(x) case ch <- i: } } os.Exit(0) } // <===================POSSIBLE OUTPUT===================> // 0 // 1 // 3 // 5 // 7 // <===================POSSIBLE OUTPUT===================> // 0 // 2 // 4 // 5
- 我们再来看看一个更加直观的例子,那就是十秒倒数,每个数字都打印出来.
// Countdown implements the countdown for a rocket launch. package main // NOTE: the ticker goroutine never terminates if the launch is aborted. // This is a "goroutine leak". import ( "fmt" "os" "time" ) //!+ func main() { // ...create abort channel... //!- abort := make(chan struct{}) go func() { os.Stdin.Read(make([]byte, 1)) // read a single byte abort <- struct{}{} }() //!+ fmt.Println("Commencing countdown. Press return to abort.") tick := time.Tick(1 * time.Second) for countdown := 10; countdown > 0; countdown-- { fmt.Println(countdown) select { case <-tick: // Do nothing. case <-abort: fmt.Println("Launch aborted!") return } } launch() } //!- func launch() { fmt.Println("Lift off!") } // <===================OUTPUT===================> // Commencing countdown. Press return to abort. // 10 // 9 // 8 // 7 // 6 // 5 // // Launch aborted! // <===================OUTPUT===================> // Commencing countdown. Press return to abort. // 10 // 9 // 8 // 7 // 6 // 5 // 4 // 3 // 2 // 1 // Lift off!
- 这是我们认为最最合乎人们理解的倒数程序.但是这个程序还是有问题,因为time.Tick 一旦创建,就好比有一个goroutine一直不停的send value.但是如果abort的情况下,其 实是没有receive goroutine的,所以就发生了goroutine leak
- select还有一个特别重要的作用,就是来实现non-blocking communication:也就是说
有时候我们希望send或者receive一个channel,但是如果channel没有ready,我们不希
望等,我们希望马上返回
Try to send or receive on a channel but avoid blocking if the channel is not ready -- a non-blocking communication
- select实现的原理基于两个:
- select和switch一样,有一个default,在所有其他case都不满足的情况下运行default
- channel作为reference type,其zero value是nil, 而且这个nil是有意义的,因为对 nil的send和receive操作都是永远block的,换句话说,对于nil channel的case,永远 都是不会执行的
- 简单的例子如下,如果abort为nil的话,我们直接就运行default啦, 而不是继续block
select { case <-abort: fmt.Println("Launch aborted") return default: // do nothing }
Example: Concurrent Directory Traversal
- 这一节,我们主要来实现一个Unix下面的du命令,最简单的一个版本如下
package main import ( "flag" "fmt" "io/ioutil" "os" "path/filepath" ) // walkDir recursively walks the file tree rooted at dir // and sends the size of each found file on fileSizes. func walkDir(dir string, fileSizes chan<- int64) { for _, entry := range dirents(dir) { if entry.IsDir() { subdir := filepath.Join(dir, entry.Name()) walkDir(subdir, fileSizes) } else { fileSizes <- entry.Size() } } } // dirents returns the entries of directory dir. func dirents(dir string) []os.FileInfo { entries, err := ioutil.ReadDir(dir) if err != nil { fmt.Fprintf(os.Stderr, "du1: %v\n", err) return nil } return entries } func main() { // Determine the initial directories. flag.Parse() roots := flag.Args() if len(roots) == 0 { roots = []string{"."} } // Traverse the file tree. fileSizes := make(chan int64) go func() { for _, root := range roots { walkDir(root, fileSizes) } close(fileSizes) }() // Print the results. var nfiles, nbytes int64 for size := range fileSizes { nfiles++ nbytes += size } printDiskUsage(nfiles, nbytes) } func printDiskUsage(nfiles, nbytes int64) { fmt.Printf("%d files %.1f GB\n", nfiles, float64(nbytes)/1e9) } // <===================OUTPUT===================> // $ go run one.go . // 257079 files 6.2 GB
- 和常规的c语言版本唯一不一样的地方,就是我们使用了一个channel作为walkDir的参数, 同时,除了main goroutine以外,我们还另外起了一个goroutine来调用walDir,并且明确 调用了close来关闭channel,从而让main goroutine可以去统计结果
- 第一个例子统计的时候,程序响应的时间过长,一个可能的改进就是每个一秒(或是半秒)
都在命令行提醒一下当前的进度.这种做法其实就是增加了一个channel(除了fileSize
以外,增加了tick),让select去处理
package main import ( "flag" "fmt" "io/ioutil" "os" "path/filepath" "time" ) // walkDir recursively walks the file tree rooted at dir // and sends the size of each found file on fileSizes. func walkDir(dir string, fileSizes chan<- int64) { for _, entry := range dirents(dir) { if entry.IsDir() { subdir := filepath.Join(dir, entry.Name()) walkDir(subdir, fileSizes) } else { fileSizes <- entry.Size() } } } // dirents returns the entries of directory dir. func dirents(dir string) []os.FileInfo { entries, err := ioutil.ReadDir(dir) if err != nil { fmt.Fprintf(os.Stderr, "du1: %v\n", err) return nil } return entries } var verbose = flag.Bool("v", false, "show verbose progress message") func main() { // Determine the initial directories. flag.Parse() roots := flag.Args() if len(roots) == 0 { roots = []string{"."} } // Traverse the file tree. fileSizes := make(chan int64) go func() { for _, root := range roots { walkDir(root, fileSizes) } close(fileSizes) }() var tick <-chan time.Time if *verbose { tick = time.Tick(500 * time.Millisecond) } // Print the results. var nfiles, nbytes int64 loop: for { select { case size, ok := <-fileSizes: if !ok { break loop } nfiles++ nbytes += size case <-tick: printDiskUsage(nfiles, nbytes) } } printDiskUsage(nfiles, nbytes) } func printDiskUsage(nfiles, nbytes int64) { fmt.Printf("%d files %.1f GB\n", nfiles, float64(nbytes)/1e9) } // <===================OUTPUT===================> // $ go run two.go -v . // 62037 files 0.6 GB // 71076 files 0.7 GB // 80573 files 0.7 GB // 90270 files 0.7 GB // 100006 files 0.8 GB // 109496 files 0.8 GB // 119236 files 0.9 GB // 128305 files 2.0 GB // 138797 files 2.1 GB // 149307 files 2.1 GB // 158870 files 2.2 GB // 168483 files 2.3 GB // 177695 files 2.3 GB // 186614 files 2.3 GB // 196181 files 2.4 GB // 205273 files 2.4 GB // 216340 files 2.4 GB // 226519 files 2.5 GB // 235460 files 3.3 GB // 243919 files 3.5 GB // 254259 files 3.5 GB // 257079 files 6.2 GB
- 另外一个改进的思路,是每一次的walkDir都使用一个goroutine,这样显然会非常非常快,
但是操作系统有打开文件描述符的限制,所以我们这里要使用一个couting semaphore来
把goroutine的数目控制在20
package main import ( "flag" "fmt" "io/ioutil" "os" "path/filepath" "sync" "time" ) // walkDir recursively walks the file tree rooted at dir // and sends the size of each found file on fileSizes. func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) { defer n.Done() for _, entry := range dirents(dir) { if entry.IsDir() { n.Add(1) subdir := filepath.Join(dir, entry.Name()) go walkDir(subdir, n, fileSizes) } else { fileSizes <- entry.Size() } } } var sema = make(chan struct{}, 20) // dirents returns the entries of directory dir. func dirents(dir string) []os.FileInfo { sema <- struct{}{} defer func() { <-sema }() entries, err := ioutil.ReadDir(dir) if err != nil { fmt.Fprintf(os.Stderr, "du1: %v\n", err) return nil } return entries } var verbose = flag.Bool("v", false, "show verbose progress message") func main() { // Determine the initial directories. flag.Parse() roots := flag.Args() if len(roots) == 0 { roots = []string{"."} } // Traverse the file tree. fileSizes := make(chan int64) var n sync.WaitGroup for _, root := range roots { n.Add(1) go walkDir(root, &n, fileSizes) } go func() { n.Wait() close(fileSizes) }() var tick <-chan time.Time if *verbose { tick = time.Tick(500 * time.Millisecond) } // Print the results. var nfiles, nbytes int64 loop: for { select { case size, ok := <-fileSizes: if !ok { break loop } nfiles++ nbytes += size case <-tick: printDiskUsage(nfiles, nbytes) } } printDiskUsage(nfiles, nbytes) } func printDiskUsage(nfiles, nbytes int64) { fmt.Printf("%d files %.1f GB\n", nfiles, float64(nbytes)/1e9) } // <===================OUTPUT===================> // $ go run three.go . // 257079 files 6.2 GB
Cancellation
- 有一些情况下,我们想要"主动停止"goroutine.比如,一个client发起了一个计算请求, server会委任一个goroutine来去做,而且这个计算会很耗费时间,但是在这个时间内server 发现client"失联"了.这种情况下,server会倾向于关闭这个goroutine来节省计算资源
- 首先应该明确的是,没有一种方面来让一个goroutine去"直接结束"另外一个goroutine,
因为"直接结束"会让另外的goroutine的所有的shared variable处于一种undefined的
状态
There is not way for one goroutine to terminate another directly, since that would leave all its shared variables in undefined states.
- 不能"直接关闭",但是可以"间接"的处理,怎么个间接法呢?就是要求让"计算"的goroutine 在自己的逻辑里面,就"注射"进去退出机制:把火箭发射看成是一个"计算"goroutine的 话,在火箭发射的goroutine里面,就有"一旦发展abort channel有问题",我就自己"主动" 关闭的逻辑
- 这种"间接"处理的方法,有一个问题,那就是:只能一个goroutine发一个event到channel
上.这种"一一对应"很难精确:
- 如果有N个goroutine,你发送了N个event到channel上面,但是如果这个N个goroutine 有个几个由于其他原因已经关闭了,那么你的channel上面总有几个没有人fetch的event
- 如果有个N个goroutine,但是这N个goroutine里面还会产生其他的goroutine,你发送 N个event,就会不够用
- 相比于"一一对应"的channel发送,可能广播是一个比较好的解决手段:所有在特定区域 里面的goroutine都可以知道某个event发生了,而且可以在event发生之后回顾"发生过" 哪些event
- golang没有为我们直接提供一个broadcast feature,但是我们可以使用channel的一个
特性来做broeadcast: 一旦一个channel被关闭了以后,后续对这个channel的读取会马
上返回(不会block),获得zero value.所以我们只要设计一个channel,永远不会向这个
channel发送event,而只close这个channel.一旦close了这个channel,就是告诉所有的
能读取这个channel的goroutine:某些事情发送了
Recall that after a channel has been closed and drained of all sent values, subsequent receive operations proceed immediately, yielding zero values. We can exploit this to create a broadcast machanism: don't send a value on the channel, close it.
- 完成这个broadcast需要很多步骤:
- 首先就是我们broadcast channel啦,另外我们还专门为它设计一个utility函数来判
断"中断事件"的广播发生过没有
var done = make(chan struct{}) func cancelled() bool { select { case <- done: return true default: return false } }
- 我们要另外有一个goroutine来时刻监视命令行行为,等待用户是不是真的input了停
止的任何字符串
go func() { os.Stdin.Read(make([]byte,1)) // read a single byte close(done) }()
- 我们新增加了一个channel事件,select肯定是要新增一个case的,但是这个case里面
还要一个比较绝的地方,是它还会去drain fileSize channel,防止walkDir在退出
的过程中无法成功的向fileSize send数据
for { select { case <-done: // Drain fileSizes to allow existing goroutines to finish for range fileSizes { // Do nothing. } return case size, ok := <-fileSizes: // ... } }
- walkDir会在运行前去查看广播,如果发现了done广播关闭,那么就直接返回
func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) { defer n.Done() if cancelled() { return } for _, entry := range dirents(dir) { // ... } }
- 另外,我们通过profiling发现在dirents里面获取semaphore,所以我们加了一段select,
来让"获取semaphore"和"发现done broadcast"变成同等重要的活动,也就是说一旦done
广播了,可以就不用去获取semaphore了,这样可以大大的提高效率:
// before sema <- struct{}{} defer func() { <-sema }() // after select { case sema <- struct{}{}: // acquire token case <-done: return nil // cancelled } defer func() { <-sema }() // release token
- 首先就是我们broadcast channel啦,另外我们还专门为它设计一个utility函数来判
断"中断事件"的广播发生过没有
- 完整的代码如下
// The du4 command computes the disk usage of the files in a directory. package main // The du4 variant includes cancellation: // it terminates quickly when the user hits return. import ( "fmt" "os" "path/filepath" "sync" "time" ) //!+1 var done = make(chan struct{}) func cancelled() bool { select { case <-done: return true default: return false } } //!-1 func main() { // Determine the initial directories. roots := os.Args[1:] if len(roots) == 0 { roots = []string{"."} } //!+2 // Cancel traversal when input is detected. go func() { os.Stdin.Read(make([]byte, 1)) // read a single byte close(done) }() //!-2 // Traverse each root of the file tree in parallel. fileSizes := make(chan int64) var n sync.WaitGroup for _, root := range roots { n.Add(1) go walkDir(root, &n, fileSizes) } go func() { n.Wait() close(fileSizes) }() // Print the results periodically. tick := time.Tick(500 * time.Millisecond) var nfiles, nbytes int64 loop: //!+3 for { select { case <-done: // Drain fileSizes to allow existing goroutines to finish. for range fileSizes { // Do nothing. } return case size, ok := <-fileSizes: // ... //!-3 if !ok { break loop // fileSizes was closed } nfiles++ nbytes += size case <-tick: printDiskUsage(nfiles, nbytes) } } printDiskUsage(nfiles, nbytes) // final totals } func printDiskUsage(nfiles, nbytes int64) { fmt.Printf("%d files %.1f GB\n", nfiles, float64(nbytes)/1e9) } // walkDir recursively walks the file tree rooted at dir // and sends the size of each found file on fileSizes. //!+4 func walkDir(dir string, n *sync.WaitGroup, fileSizes chan<- int64) { defer n.Done() if cancelled() { return } for _, entry := range dirents(dir) { // ... //!-4 if entry.IsDir() { n.Add(1) subdir := filepath.Join(dir, entry.Name()) go walkDir(subdir, n, fileSizes) } else { fileSizes <- entry.Size() } //!+4 } } //!-4 var sema = make(chan struct{}, 20) // concurrency-limiting counting semaphore // dirents returns the entries of directory dir. //!+5 func dirents(dir string) []os.FileInfo { select { case sema <- struct{}{}: // acquire token case <-done: return nil // cancelled } defer func() { <-sema }() // release token // ...read directory... //!-5 f, err := os.Open(dir) if err != nil { fmt.Fprintf(os.Stderr, "du: %v\n", err) return nil } defer f.Close() entries, err := f.Readdir(0) // 0 => no limit; read all entries if err != nil { fmt.Fprintf(os.Stderr, "du: %v\n", err) // Don't return: Readdir may return partial results. } return entries } // <===================OUTPUT===================> // $ go run four.go . // 56523 files 3.9 GB // 108053 files 5.5 GB // d
- 好了,现在当我们在命令行输入任意一个字符,所有的background goroutine都会快速 结束,然后main goroutine也就返回了.当然了因为我们main返回了,所以很难去"证明" 我们的background的资源都返回了.一个可行的trick就是:我们的cancellation结束后 不是返回main,而是执行一个panic,这个panic dump打印所有的goroutine.如果只有main goroutine,说明我们的回收成功了.否则说明有泄露的goroutine
Example: Chat Server
- 最后我们来看一个chat server的例子,这是个简单例子,每个接入chat server的client 都会收到所有其他人的信息,相当于微信里面的群聊
- 除了main goroutine以外,例子中的每个client都会单独有一个goroutine,另外我们还 创建了一个broadcaster goroutine来管理来自不同channel的event
- main goroutine的工作比较简单,就是先起一个broadcaster goroutine,然后在for循环
里面等待tcp链接,给每个进来的tcp链接都创建一个handleConn
func main() { listener, err := net.Listen("tcp", "localhost:8000") if err != nil { log.Fatal(err) } go broadcaster() for { conn, err := listener.Accept() if err != nil { log.Print(err) continue } go handleConn(conn) } }
- broadcaster()就是来负责群发的啦.go里面和goroutine里面打交道的方法就是通过channel
群发的话,肯定也是通过channel. broadcaster()处理的不只有各个client的信息,还有
各个成员进入群聊和退出群聊的信息.每一类信息都是使用一个channel来完成的,所以
我们的broadcaster()也就需要select来同时处理不同的channel
type client chan<- string // an outgoing message channel, each client has one client var ( entering = make(chan client) leaving = make(chan client) messages = make(chan string) // all incoming client messages ) func broadcaster() { clients := make(map[client]bool) // all connected clients for { select { case msg := <-messages: // Broadcast incoming message to all,even itself for cli := range clients { cli <- msg } case cli := <-entering: clients[cli] = true case cli := <-leaving: delete(clients, cli) close(cli) } } }
- broadcaster()是从global的message channel里面读取的信息,那可以想到,每个client
都是把:
- 自己进入群聊的event写入到global的entering channel
- 自己离开群聊的event写入到global的leaving channel
- 自己聊天的信息写入到global的message channel
- 所以client的代码里面充斥着全局变量
func handleConn(conn net.Conn) { ch := make(chan string) // outgoing client messages go clientWriter(conn, ch) who := conn.RemoteAddr().String() ch <- "You are " + who message <- who + " Has arrived" entering <- ch input := bufio.NewScanner(conn) for input.Scan() { message <- who + ": " + input.Text() } // Note: ignoring potential errors from input.Err() leaving <- ch messages <- who + " has left" conn.Close() } func clientWriter(conn net.Conn, ch <-chan string) { for msg := range ch { fmt.Fprintln(conn, msg) } }
- 这段代码有一个地方不太好理解,就是ch.不好理解的原因在于entering和leaving这两 个全局channel其实是"channel的channel",所以ch只是传入到这里面而已,传进去以后 ch就变成了clients这个map的一个成员."并没有读取ch里面的值!"
- 所以我们可以另外起一个goroutine clientWriter,源源不断的读取ch,然后写入到conn 里面.理解"channel的channel"比较重要
- 完整代码如下
// Chat is a server that lets clients chat with each other. package main import ( "bufio" "fmt" "log" "net" ) //!+broadcaster type client chan<- string // an outgoing message channel var ( entering = make(chan client) leaving = make(chan client) messages = make(chan string) // all incoming client messages ) func broadcaster() { clients := make(map[client]bool) // all connected clients for { select { case msg := <-messages: // Broadcast incoming message to all // clients' outgoing message channels. for cli := range clients { cli <- msg } case cli := <-entering: clients[cli] = true case cli := <-leaving: delete(clients, cli) close(cli) } } } //!-broadcaster //!+handleConn func handleConn(conn net.Conn) { ch := make(chan string) // outgoing client messages go clientWriter(conn, ch) who := conn.RemoteAddr().String() ch <- "You are " + who messages <- who + " has arrived" entering <- ch input := bufio.NewScanner(conn) for input.Scan() { messages <- who + ": " + input.Text() } // NOTE: ignoring potential errors from input.Err() leaving <- ch messages <- who + " has left" conn.Close() } func clientWriter(conn net.Conn, ch <-chan string) { for msg := range ch { fmt.Fprintln(conn, msg) // NOTE: ignoring network errors } } //!-handleConn //!+main func main() { listener, err := net.Listen("tcp", "localhost:8000") if err != nil { log.Fatal(err) } go broadcaster() for { conn, err := listener.Accept() if err != nil { log.Print(err) continue } go handleConn(conn) } } //!-main
Chapter 09: Concurrency with Shared Variables
- 前面一章,我们展现了使用goroutine和channel来处理并发问题.这种处理方式自然而直 接,但是在处理的过程当中,我们也发现了一些重要的注意事项,需要我们的程序员来注意
- 本章,我们会更进一步的学习并发的机制.特别的,我们会处理"多个goroutine共享变量" 的问题.
- "多goroutine共享变量"这个问题难还在于,我们需要特殊的方法来分析出这种问题的存 在.也就是analytical techniques for recoginzing theose problems
- 我们会还会列举解决"多goroutine共享变量"的经典pattern
- 最后,我们还会列举一下goroutine和操作系统thread之间的技术上的不同(technical difference)
Race Conditions
- 在线性的程序里面(线性的程序,sequential program, 就是只有一个goroutine的程序), 程序允许的顺序是严格的安装logic来的,容易被人所理解.
- 但是当程序里面出现多个goroutine的时候,每个goroutine内部还是按照它们的logic顺 序执行,但是我们无法判断来自两个goroutine的event的运行先后顺序.比如eventX发 生在goroutine1里面, eventY发生在goroutine2里面.我们是无法判断这两个event谁 先运行,谁后运行的
- 当我们无法自信的说出两个event哪个先运行,哪个后运行的时候,我没说这两个event是
并行的
When we cannot confidently say that one event happens before the other, then the events x and y are concurrent.
- 一个在线性程序里面正确运行的程序,如果并行的被调用(called concurrently,就是说
在没有额外的同步手段的情况下,从多个goroutine里面来调用这个函数)的时候,依然能
够正确的运行,那我们说这个function是线程安全的
Function is concurrency-safe if it continues to work correctly even when called concurrently, that is, from two or more goroutine with no additional synchronization.
- 对一个function的线程安全判断可以扩展到一个type.如果一个type的所有的可以接触 到的method和operation都是线程安全的,那么这个type就是线程安全的
- 注意type的线程安全是一个比较模糊的判断,并不是像function这么具体,type的线程 安全与否很多时候都是体现在文档里面
- 我们可以通过很多的"同步手段"来让我们的程序编程线程安全的,使用这个"同步手段" 是因为很多function或者type本身不是线程安全的.换句话说,一个程序可以做到线程 安全,即便组成这个程序的type或是function有些不是线程安全的
- golang里面比较特殊的是,它还有package level的函数.这种函数因为其特殊性,所以
一般来说都是要求线程安全的.因为这些函数都是会被多个goroutine引用的.而package
level的variable就更麻烦了,因为没有function的包裹,所以无法做到线程安全,而这
些变量还可能会被多个goroutine所引用.所以,我们约定更改package-level变量的function
一定要加互斥(获取锁才能访问这个变量)
Since package-level variables cannot be confined to a single goroutine, functions that modify them must enforce mutual exclusion
- 正常的发布的go library应该不会暴露可以更改的package-level变量,暴露的肯定也是 const的
- 一个在普通模式下正常,但是在多线程下工作不正常的function变得不正常的原因常见
的有以下几个:
- deadlock: 用英语简单描述就是"Me first, Me first"
- livelock: 用英语简单描述就是"You first, You first"
- starvation: 用英语简单描述就是"Some first, Otehr never"
- race condition: 用英语的简单描述就是"race to write the global variable"
- 对于deadlock(死锁)和livelock(活锁)问题可以用哲学家吃面条(两个叉子)问题来解释:
五位哲学家在一个圆桌吃面条,每次吃面条的时候,都要拿起两个叉子 死锁:每个哲学家都拿起左手的叉子,永远等待右手的叉子(系统永远 不会进行到下一个状态) 活锁:每个哲学家同时拿起左手的叉子,等待五分钟后又同时放下左手 的叉子,并且再过五分钟同时再尝试.这种方法消除了死锁(系统总会 进入到下一个状态),但是这种状态也只是空空浪费资源,所以叫活锁 - 我们可以看到,活锁很多时候是为了解决死锁而产生的问题
- 至于starvation就比较好理解了,是某些个运行的process被调度器(scheduler)完全忽 略的情形.虽然某些process完全可以运行,但是它永远不会被调度器选中.某些情况下 共同运行的thread里面,有些个greedy thread从来不给其他thread运行的机会,就会造 成其他thread的starvation
- 我们这一节主要介绍的就是race condition,race condition的发生原因在于两个thread
(在go里面就是goroutine啦)不加保护的共同访问全局变量.race condition不仅危害巨
大而且由于其是在特定的情况下才发生,所以非常不容易被察觉,下面就是一个go的race
conditon的例子
package main import ( "fmt" "os" ) var balance int func Deposit(amount int) { balance = balance + amount } func Balance() int { return balance } func main() { ch := make(chan int, 2) go func() { Deposit(200) fmt.Println("A=", Balance()) ch <- 0 }() go func() { Deposit(100) fmt.Println("B=", Balance()) ch <- 0 }() <-ch <-ch fmt.Println("R=", Balance()) os.Exit(0) } // <===================OUTPUT===================> // A= 200 // B= 300 // R= 300 // <===================OUTPUT===================> // A= 300 // B= 100 // R= 300 // <===================OUTPUT===================> // B= 100 // A= 300 // R= 300 // <===================OUTPUT===================> // B= 300 // A= 200 // R= 300
- 从结果的多变性来看,多线程环境下的变数就很多了.但是看起来却真的没有什么错,因
为首先结果都是300,只不过先运行A还是先运行B会导致中间的结果不一样.但是前面说
了,race condition的问题在于非常多次的运行才会有一次的发生.我们做了个实验在
运行了上面的程序1000次以后,终于有一次错误的输出
// <===================OUTPUT===================> // A= 200 // B= 100 // R= 200
- 这种错误的来源在于什么呢,在于A读取数据之后,和A写入数据之前,如果B写入了数据,
那么B的写入就会被A的写入所覆盖.换句话说,B在race中,输给了A,它的写入没有算数
B's deposit occurs in the middle of A's deposit, after the blance has been read but before it has been updated, causing B's transaction to disappear. A's deposit operation is really a sequence of two operation, a read and a write. We should keep the whole transaction run without being interrupted
- 我们使用下面的图标来表示下
Action Balance Code A read 0 … = balance + amount B read&write 100 A write 200 balance = … Final 200 - 这种由于多个线程访问内存引起的race condition有一个特别的名字,叫做data race,
而且data race有其严格的定义: data race 发生在两个goroutine并发的访问同一个
变量,并且其中一个访问是write
A data race occurs whenever two goroutines access the same variable concurrently and at least one of the access is a write
- 当data race涉及的variable比一个machine word(如果64位计算机,就是64bit),的话 问题会更加的严重,因为一次机器一次只能处理一个word,在处理不同word之间的间隙 数据是不完整的,在不完整的数据基础上进行的操作,只会带来更严重的危害
- 下面的例子中我们的x开始的时候,是not define的状态,后面我们使用另外的两个goroutine
来进行分别初始化.但是我们知道,我们的slice是由三个部分组成的(pointer, length,
capacity)make一次会完成三个操作,但是在make进行中的时候,x可能会进行赋值
因为这两个动作是同步的,可以同时发生:
var x []int go func() { x = make([]int, 10) }() go func() { x = make([]int, 100000) }() x[9999] = 1 // NOTE: undefined behavior; memory corruption possible!
- 千万不要低估race condition带来的问题,要始终谨记,没有什么"温和的race condition" 只要是race contion都会带来巨大的危害.我们的中点要放在如何避免race condition
- 根据race condition的定义(当有两个goroutine同时访问同一个变量,并且其中一个是
写操作),我们可以有三种方法来避免race condition:
- 第一种是不要去写变量,这就是大部分的多线程程序都很喜欢read-only变量的原因
- 第二种方法着眼于不要让多个goroutine"看到"同一个变量,怎么限制呢?把某个
变量变成某个goroutine的local variable,这样一来,其他的goroutine想访问都访问
不到.通信就只能依靠channel啦(这就合了golang的心意啦)
Do not communicate by sharing memory; instead share memory by communicating
- 第三种方法着眼于不要让多个goroutine"同时"改变一个变量,而是一个一个的来,就 是所谓的mutual exclusion,这也是其他语言里面比较常见的做法
Mutual Exclusion: sync.Mutex
- 前面的章节中,我们使用过counting semaphore,也就是设置一个buffered channel的 大小为20,让它来作为其他goroutine访问某个变量的渠道.
- 限制了channel的大小为20可以让最多20个goroutine来访问一个变量,那么我们限制buffer 大小为1的情况下,不就可以做到同时只有一个goroutine访问变量了么(线性访问也就做到了)
- 其实这就是操作系统里面的"信号量"和"互斥锁"的概念,大小为1的"信号量"其实就是一
个"互斥锁".当然了,从语境上理解,还是稍有不同:
- 信号量好比餐厅里面有三文鱼,同时有n个厨子在做,是一个资源多少的形态
- 互斥锁好比餐厅某个米饭,只有一个公共的勺子,大家都"轮流"使用这个勺子
- 我们当然可以通过如下的代码来实现一个容量为1的semaphore,也叫binary semaphore
var ( sema = make(chan struct{}, 1) // a binary semaphore guarding balance balance int ) func Deposit(amount int) { sema <- struct{}{} // acquire token balance = balance + amount <-sema // release token } func Balance() int { sema <- struct{}{} // acquire token b := balance <- sema // release token return b }
- 但是由于互斥锁的概念特别常用,golang为我们准备了一个标准库的实现:sync.Mutex
var ( mu sync.Mutex // guards balance balance int ) func Deposit(amount int) { mu.Lock() balance = balance + amount mu.Unlock() } func Balance() int { mu.Lock() b := balance mu.Unlock() return b }
- 一旦一个mutex被某个goroutine所占据以后,其他的goroutine只能等待这个goroutine 释放以后,才能再次试图获取.
- 在习惯上,go代码每次声明一个mutex以后,需要在它后面紧接着声明那个mutex所要保护 的变量
- 被Lock和Unlock所包围的部分叫做critical section.因为其他goroutine在得不到lock 的情况下,不能访问critical section,所以每次goroutine完成它的工作以后,一定记得 释放这个goroutine,即便是非正常退出,也要记得(比如error path)
- 上面的代码非常容易记得Unlock,因为逻辑非常简单,但是在大型的函数里面,特别是要
考虑到error path的情况下,能够正确的找到所有退出的位置,并不容易.这也是为什么
我们go引入了defer,用来保证在程序退出前释放我们的资源(在这里mutex就是一个资源)
func Balance() int { mu.Lock() defer mu.Unlock() return blance }
- 上面的代码Unlock会在return之后运行,非常简洁,我们也省去了创建一个变量b
- defer的使用代价不菲(编译器会专门处理这个逻辑),但是能够保证正确性和可读性,我 们还是推荐使用的.特别是存在错误的情况下(有些还需要使用recover)
- 下面是这样一个例子,Withdraw是取钱的函数,但是如果账户余额不足,我们肯定是取不
成功的,这种情况下会把账户在再回来,如下
// NOTE: not atomic! func Withdraw(amount int) bool { Deposit(-amount) if Balance() < 0 { Deposit(amount) return false } return true }
- 这个函数会一直能够保证账目不出错,但是却有一个side effect,某个瞬间账户的余额 会变成负数,如果同一个瞬间这个账户想做一个小的减法操作就会失败.举个例子就是 Bob在试图买个车失败的瞬间,Alice想用同一张卡买杯咖啡(本来钱是够的)却被告知账 户数目是负的!
- 上述情景出现问题的原因,在于Withdraw是一个事情,但是却分成了三次操作,整个事情 没有做到atomic:每次都acquire并且release mutex lock,并没有在整个过程中lock
- 那么最直接想到的就是我们把整个Withdraw都lock嘛,但是下面的尝试将会失败
// NOTE: incorrect! func Withdraw(amount int) bool { mu.Lock() defer mu.Unlock() Deposit(-amount) if Balance() < 0 { Deposit(amount) return false // insufficient funds } return true }
- 失败的原因在于Deposit"试图"第二次获取一个互斥锁,但是mutex是不支持reentrant的,
换句话说,你不可以lock一个已经lock的mutex.一旦试图"两次"lock一个互斥锁,程序
会进入deadlock模式,永远的block
Deposit tries to acquire the mutex lock a second time by calling mu.Lock()
- 在不支持可重入(reentrant)互斥锁的系统上面,可以使用如下的方法来达到我们"全局
加锁"的目的,Deposit变成两个函数:
- 真正的业务逻辑deposit 函数,本身不加锁,也不export(免得用户用错)
- 把deposit加一次锁,然后export出去的Deposit函数
- 而Withdraw可以先加锁,然后调用deposit函数,因为说白了,Withdraw只是对deposit的
业务逻辑感兴趣
func Withdraw(amount int) bool { mu.Lock() defer mu.Unlock() deposit(-amount) if balance < 0 { deposit(amount) return false // insufficient funds } return true } func Deposit(amount int) { mu.Lock() defer mu.Unlock() deposit(amount) } func Balance() int { mu.Lock() defer mu.Unlock() return balance }
- 上面的例子通过封装(encapsulation)减少了"非预期交互",起到了很好的效果.其实对
于我们申请的mutex(以及它所包含的变量),我们也要做到对它的封装,它只能:
- 作为一个struct的field
- 或者是一个package level的变量
Read/Write Mutexes: sync.RWMutex
- 上次无故丢失了100块钱以后,Bob开始担心他的钱,于是写了一个程序不停的读取他的 账户的余额:每秒运行上百次
- 银行很快发现了自己的运营由于这个程序而出现了问题,因为对于balance的操作是线性 的,这个不停运行的检车余额的程序阻碍了其他程序的运行.换句话说,抢夺了其他goroutine 的资源
- 而由于Balance只是去读取余额的variable,所以它不会更改variable的state,因此我们 可以允许多个goroutine同时"读取"variable,当然也是有前提的.就是"写入"不能同时 进行
- 这种允许多个goroutine同时读取,而不允许同时有任何写入的情况下,适合使用另外的
lock: sync.RWMutex
var mu sync.RWMutex var balance int func Balance() int { mu.RLock() // readers lock defer mu.RUnlock() return balance }
- 这里,我们的读取,使用了readwrite lock.但是我们的写入,不需要改,还是使用mu.Lock 和mu.Unlock就可以了
- 只有在读取远大于写入,并且读取直接竞争非常激烈的情况下,才适合使用读写锁.因为 读写锁的机制要别普通的互斥锁要复杂,所以运行速度要慢于互斥锁
Memory Synchronization
- 读取的函数Balance()里面只有一个操作,所以其他的goroutine无法"在Balance()运行
期间运行",但是我们还是为它加了锁.这是基于如下两点考虑:
- 虽然不能再"读取"期间进行其他操作,但是我们也不想让读取发生在其他的操作之间
- 我们不能仅仅考虑goroutine,其实内存也有影响.特别是现代的计算机结构,大力的 发展了cache,我们强制为"读取"加锁的话,加锁这个过程会强制所有的cache实效
Lazy Initialization: sync.Once
- 为了lazy initialization的并发安全,sync package引入了Once这个特殊的锁,反正记
住这个锁可以做到多个goroutine访问,但是依然可以保证只初始化一次,并且并发安全
就可以了
func loadIcons() { icons = map[string]image.Image{ "spades.png": loadIcon("spades.png"), "hearts.png": loadIcon("hearts.png"), "diamonds.png": loadIcon("diamonds.png"), "clubs.png": loadIcon("clubs.png"), } } var loadIconsOnce sync.Once var icons map[string]image.Image // Concurrency-safe func Icon(name string) image.Image { loadIconsOnce.Do(loadIcons) return icons[name] }