the-linux-programming-interface
Table of Contents
- Chapter 02: Fundamental Concepts
- The Core Operating System: The Kernel
- The Shell
- Users and Groups
- Single Directory Hierarchy, Directories, Links, and Files
- File I/O Model
- Programs
- Processes
- Memory Mappings
- Static and Shared Libraries
- Interprocess Communication and Synchronization
- Signals
- Threads
- Process Groups and Shell Job Control
- Sessions, Controlling Terminals, and Controlling Process
- Pseudoterminals
- Date and Time
- Client-Server Architecture
- Realtime
- The /proc File System
- Chapter 03: System programming concepts
- Chapter 04: File I/O: The Universal I/O Model
- Chapter 05: FILE I/O: Further Details
- Atomicity and Race Conditions
- File Control Operations: fcntl()
- Open File Status Flags
- Relationship Between File Descriptors and OpenFiles
- Duplicating File Descriptors
- File I/O at a Specified Offset: pread() and pwrite()
- Scatter-Gathr I/O: readv() and writev()
- Truncating a File: truncate() and ftruncate()
- Nonblocking I/O
- I/O on Large Files
- The /dev/fd Directory
- Creating Temporary Files
- Chapter 06: Processes
- Chapter 07: Memory Allocation
- Chapter 08: Users and groups
- Chapter 09: Process credentials
- Chapter 10: Time
- Chapter 11: System Limits and Options
- Chapter 12: System and Process Information
- Chapter 13: File I/O Buffering
- Chapter 14: File System
- Device Special Files(Devices)
- Disks and Partitions
- File Systems
- I-nodes
- The Virtual File System (VFS)
- Journaling File Systems
- Single Directory Hierarchy and Mount Point
- Mounting and Unmounting File Systems
- Advanced Mount Features
- A Virtual Memory File System: tmpfs
- Obtaining Information About a File System: statvfs()
- Chapter 15: File Attributes
- Chapter 16: Extended Attributes
- Chapter 17: Access Control Lists
- Chapter 18: Directories And Links
- Chpater 19: Monitoring File Events
- Chapter 20: Signals: Fundamental Concepts
- Chapter 21: Signals: Signal Handlers
- Chapter 22: Signals: Advanced Features
- Chapter 23: Timers and Sleeping
- Chapter 24: Process Creation
- Chapter 25: Process Termination
- Chapter 26: Monitoring Child Processes
- Chapter 27: Program Execution
- Chapter 28: Process Creation and program execution in more detail
- Chapter 29: Threads: Introduction
- Chapter 30: Threads: Thread Synchronization
- Chapter 31: Threads: Thready Safety and Per-Thread Storage
- Chapter 32: Threads: Thread Cancellation
- Chapter 33: Threads: Further Details
- Chapter 34: Process groups, sessions, and job control
- Chapter 35: Process priorities and scheduling
- Chapter 36: Process Resources
- Chapter 37: Daemons
- Chapter 38: Writing Secure privileged programs
- Chapter 39: Capabilities
- Chapter 40: Login Accounting
- Chapter 41: Funamentals of shared libraries
- Chapter 42: Advanced features of shared libraries
- Chapter 43: Interprocess communication overview
- Chapter 56: Sockets: Introduction
- Chapter 57: Sockets: Unix Domain
- Chapter 58: Sockets: Fundamentals of TCP/IP Networks
Chapter 02: Fundamental Concepts
The Core Operating System: The Kernel
- operating system通常来说有两种意思:
- 广义上来说,包括整个command-line解析器, GUI, 文件管理等等所有的软件
- 狭义上来说,就是管理和分配计算机资源(比如CPU, RAM, 设备等等)的系统
- 我们的Linux Kernel其实就是狭义上的os的意思.
- 裸机上面不安装os也是可以运行的,但是os的存在能够让计算机的使用更加简单,因为
os(也就是Linux Kernel)其实就是为计算机提供了一层管理有限资源的软件层.
Linux kernel通常是在/boot/vmlinuz,是一个压缩过的可执行文件,其意义是 virtual memory Linux Zipped binary
Task performed by the kernel
- 通常来说kernel的主要责任有如下:
- process scheduling: 现在的机器都是多核的,而Linux是preemptive
multitasking os, 换句话说就是Linux能够支持让不同的核运行不同的进程,而且
preemptive(抢占式)的意思是操作系统可以终止某个进程的运行
这也就把运行多久的权利抓在了kernel手里,而不是让process可以想运行多久就多久 - memory management: 内存也是一种稀缺资源,所以Kernel需要使用virtual memory
的方法让内存在不同process之间共享.所谓virtual memory有如下优点:
- process之间,process和kernel之间的内存是隔绝的,所以他们之间是无法共享 内存的
- process只有一部分"真正的存在于内存", 这样同等的内存能偶容纳更多的process (其实每个process都认为自己有4G内存空间,如果不是只有'一部分'存在于内存, 那么16G内存也才能放4个process). 因为内存里面同时能放的process数目多了, 这会提高CPU的利用率:因为CPU有更大的概率在内存里面找到一个process!
- provision of a file system: 为计算机提供文件系统,以使得文件可以增删改查
- creation and termination of process: kernel可以从"文件"中读取一个program 然后赋予这个文件resource(cpu, memory), 然后这个program就运行起来,变成一个 process了. 当process结束运行的时候,kernel也要收回process的资源.
- Access to devices: kernel会简化对设备的管理.也会裁定多个process对设备的 访问
- Networking: kernel还"代理"user process来进行传递和接受network message(packet) 的任务.
- Provision of a System call application programing interface (API): user process需要完成某种权限要求较高的的操作的时候,会要求kernel"代为效劳", 途 径就是system call API
- process scheduling: 现在的机器都是多核的,而Linux是preemptive
multitasking os, 换句话说就是Linux能够支持让不同的核运行不同的进程,而且
preemptive(抢占式)的意思是操作系统可以终止某个进程的运行
- 除了上面说的这些特性,Linux同时还是一个"多用户"的操作系统,也就是说,它为每一
个用户提供了"virtual private computer":
- 每个用户可以单独登陆
- 每个用户的操作相互不干扰
- 每个用户都可以运行自己的process,而相互不干扰的访问多个用户共同的资源: 设 备和网络
Kernel mode and user mode
- 现代的cpu技术都会支持CPU在两种模式下运行:
- user mode
- kernel mode
- 上述硬件结构上面的特点我们可以想象成是CPU上面有个开关:一开, cpu就进入kernel mode;一关,就进入user mode.这个开关的动作是使用hardware instruction完成的
- virtual memory系统为了适应cpu的硬件结构,把自己的全部内存空间分成了两种:
- user space
- kernel space
- cpu为kernel mode的时候,两个space都可以访问,cpu为user mode的时候, 只能访问
user space的内存地址,越界访问会导致hardware exception:
- Linux上面只有kernel code是运行于kernel mode的,所以它可以访问所有的4G(32 位情况下)内存
- 所有其他的进程都是运行于user mode的,所以只能访问前3G内存.
- 也就是说CPU自己会在自己内部设置一个status word来标示自己是在什么mode下运行,
而virtual memory系统也分别给自己的地址设置了哪些mode可以运行的限制,根据wiki
上的解释就是.
For example, a CPU may be operating in Ring 0 as indicated by a status word in the CPU itself, but every access to memory may additionally be validated against a separate ring number for the virtual-memory segment targeted by the access, and/or against a ring number for the physical page (if any) being targeted. This has been demonstrated with the PSP handheld system. From => https://en.wikipedia.org/wiki/CPU_modes
- 换句话说,由于Linux上面只有kernel code是在kernel mode运行的,所以其他任何程 序都不可能使用3G+的地址(32位)
- 这里我们想给大家区分一下kernel mode和root mode:
- kernel mode是一种CPU的构造所形成的mode
On Linux, only kernel code (including kernel modules) is running in kernel mode. Everything else is in user mode.
- root mode是Unix-like系统里面的管理员的概念,即便一个program code以管理员 的身份运行,它依然是运行在user mode的(需要system call和kernel进行通信)
- kernel mode是一种CPU的构造所形成的mode
Process versus kernel views of the system
- 如果对Linux的"kernel代理process进行有权限的操作"这个理念不了解的话,可能会
尝试从process-oriented的方式来理解Linux, 但是其实process能力很小:
- 一个运行的process不知道自己什么时候被抢夺cpu,不知道自己下次什么时候运行
- 对signal什么时候来到也不清楚
- process不知道自己是在"物理内存的哪里"或者是在swap里面.
- process不知道自己要访问的文件的位置,它只是知道它的名字而已
- process无法和其他process通信
- process无法创建新的process,甚至无法结束自己
- process无法和设备,比如输入输出打交道
- 相对的,如果你从Kernel的角度理解Linux的话:
- kernel可以决定process何时得到cpu,得到多久的cpu
- kernel维护复杂的数据结构,知道每个process实际存在的物理地址(或者swap)
- kernel维护复杂的数据结构,把process知道的名字转化为具体的物理地址
- 所有进程间的通信都是通过kernel
- kernel创建新的process,并结束老的process
- 和外界device的通信工作也是kernel来完成
- 后面我们会看到,我们会说"一个process可以创建另外一个process",或者"一个process 可以写入文件", 这里的可以是"可以请求kernel为其工作"的意思
The Shell
- shell是一种让用户来执行某个program的"特殊用途的program",由于登陆才能使用,也 叫login shell
- 某些系统中的shell是kernel的一部分,但是在Unix-like系统中shell是user process
- Unix-like系统中存在着非常多的shell:
- Bourne shell (sh): 最早的shell
- C shell (csh): 和sh不兼容, 仅提供了些新功能
- Korn shell (ksh): 引入了csh的新功能,并且和sh兼容!
- Bourne again shell (bash): GNU版本的Bourne shell, 最广泛应用,在很多系统中 sh其实就是bash的soft link
- shell不仅仅是用来和用户进行交互,而且其实是shell script的"解释器"
Users and Groups
- 一个系统中的user都是唯一的,但是可能属于不同的group
Users
- 每有一个user,就会在/etc/passwd里面由一行属于它,包括了如下的信息:
- login name
- User ID 也叫UID.
- Group ID: 也叫GID. 列出user所有group里面的第一个
- Home directory
- Login Shell
- 原来这个文件中还存有加密的密码,后来出于安全原因放入了另外一个只有root有权 限查看的文件/etc/shadow
Groups
- "人以群分", 在unix系统中,做同一件事情的,会加入同一个组,比如想要不使用sudo 就使用docker,那么就得加入docker group
- 历史上,unix-like系统曾经只允许一个用户在一个组,不过后来改变了这个策略改变了.
现在是某个用户只能属于一个"primary group", 也就是/etc/passwd里面的用户的第
一个group,可以使用group命令来看看你所有的group, 第一个列出的group就是primary
group
$ groups vagrant vagrant : vagrant adm cdrom sudo dip plugdev lpadmin sambashare docker
- 在/etc/group文件里面存储了所有的组信息, 包括:
- group name
- group id
- user list: 使用逗号隔开的用户名列表. (需要注意的是在/etc/passwd里面指明
了比如root的primary group是root, 那么在/etc/group里面group root列表里面
就不会再有用户root了)
~$ sudo cat /etc/passwd | grep root root:x:0:0:root:/root:/bin/bash $ sudo cat /etc/group | grep root root:x:0:
Superuser
- id 为0的user是超级用户root, 拥有一切权限.它可以访问一切的文件(不管文件的访 问权限是什么), 但我们说了root只是用户里面的最高权限, 它运行的program还是user mode process.
Single Directory Hierarchy, Directories, Links, and Files
- Linux是从root(/)开始的文件系统. 这个文件系统里面有很多的类型:
- File types: 也叫regular或者plain文件
- Directories and links:
- 文件夹其实就是link的一个集合.
- 所谓link其实就是文件名和"文件的位置"的组合. 一个"文件位置"可能有多个文件名
- "文件位置"也有可能是文件夹.
- 文件夹里面里面至少也有两个link: "."和".."
- Symbolic links:symbolic link是一种非常特殊的link:
- link里面的配置是"文件名" + "文件位置"
- symbolic link里面的配置是"文件名" + "文件位置" (而文件位置所在的硬盘空 间里面写了一个另外一个'文件名'), 这个后面的"文件名"就叫target
- device file
- pipe file
- socket file
Filenames
- 在Linux系统里面filename最长可以到255个character,但是取名还是有很多讲究:
- 文件名最好使用65-character set,也就是[-._a-zA-Z0-9].它们也叫portable filename character set
- 使用hyphen(-)作为文件名非常不好. 因为"-"很可能被认为是shell command里面 的option
Pathname
- 文件名分两种:
- absolute pathname: 以"/"开头
- relative pathname: 以"."或者".."或者当前文件夹里面的文件开头.
Current working directory
- current working directory是一个process的概念,每个process启动的时候都会从它 的parent process继承来了
- cwd可以使用cd更改
File ownership and permissions
- 每一个文件都有一个自己相应的user ID和group ID来表示自己的ownership
- 每一个文件的ownership分成三个类别:
- 文件的User ID的用户的'读写执行'
- 文件的Group ID里面所有用户的'读写执行'
- 所有其他用户的'读写执行'
- '读写执行'对于文件和文件夹的意义有所不同:
- 对文件来说:就是"读取", "写入", 把当前文件运行成process
- 对文件夹来说:就是"文件夹里面的内容可以列出", "可以往文件夹里面加文件", "可以访问文件夹里面的文件"
File I/O Model
- Unix-like系统中,有一个概念叫做"universality of I/O",也就是"一切皆文件",换句 话说,就是处理IO的system call (比如open(), read(), close())是适用于"所有文件" 的,包括directory文件, device 文件等
- 如果文件可以被random访问的话,就可以使用lseek(), 而不可以使用lseek()的文件类
型如下, lseek()会返回ESPIPE:
- pipe
- socket
- FIFO
- Unix-like系统的换行符为LF(linefeed),而windows文件系统的换行符是CR(carriage return) + LF
- Unix-like系统也没有EOF(end-of-file),而是以read()没有返回任何内容来判定文件 到头
File descriptors
- IO的system call打开文件以后返回的句柄叫做file descriptor,通常是一个非负整数.
- 一个process会从parent里面继承三个file descriptor:
- 值为0的 standard input
- 值为1的 standard output
- 值为2的 standard error
The stdio library
- C语言的stdio library正是包装了IO一系列的system call
Programs
- program通常以两种方式存在(script语言不再此列):
- source code: 人类可以理解的文本
- binary machine-language: 机器可以理解的格式
Filters
- 有那么一类的bash application,它们的任务是从stdin读取一些内容,经过"修饰"打
印到output, 它们叫做filter:
- cat
- grep
- tr
- sort
- wc
- sed
- awk
Command-line arguments
- c语言main里面的两个参数(argc, argv)就为了command line的参数准备的.
int main(int argc, char *argv[])
Processes
- 简单来说, process就是program的运行时状态.
- kernel运行一个program的步骤是:
- 把program导入virtual memory
- 为program的变量分配内存空间
- 建立一系列的bookkeeping data structure来记录process的信息, 比如:
- process ID
- termination status
- user ID
- group ID
- 从kernel的角度上来讲, process是要和kernel一起共享计算机资源的.对于内存这种 资源, kernel是一开始分配一小块,然后随着process的要求和整个系统的能力,再进行 分配.
Process memory layout
- 一个process在逻辑上被分成如下的segment:
- Text: 二进制代码
- Data: program使用的static variable
- Heap: program可以用来动态申请内存的位置
- Stack: 用来存放local variable和 function call的位置
Process creation and program exectuion
- 一个process肯定是由另外的process 调用system call fork()产生出来的:
- 调用fork()的process叫做parent process
- 新产生的process叫做child process
- kernel创建child process的办法,是复制parent process的如下字段:
- Data
- Heap
- Stack
- 而Text segment因为是只读的,所以只是"reference"一个地址让parent和child共享. 当然,child process也可能会"写入"这个"reference的地址",一旦写入就会再新的地 方创建Text Segment
- 而作为child process,它的选择有两个:
- 在继承来的四个segment的基础上,运行一些不同的function
- 更常见的做法,是调用execve()系列system call来破坏已有的四个segments,创建 新的四个segments
Process ID and parent process ID
- 每个process都有PID来标示自己, PPID来标示自己的parent process
Process termination and termination status
- process可以在两种情况下结束:
- 自己了断自己的: 通过exit()系列system call,然后会exit()会发送termination status
- 被signal中断: 也会根据signal的不同来设定termination status
- 一般来讲, termination status 为0表明程序正常结束. 其他值都不是正常结束
- 在命令行运行完process后,可以使用$?来取得上次运行process的termination status
vagrant@vagrant:~$ ls dot-files shell-files tmp vagrant@vagrant:~$ echo $? 0
Process associated User ID
- 一个process有如下三个类别的User ID:
- Real user ID: 某个program是被哪个User调用然后变成process然后运行的
- Effective user ID: 某个process拥有和effective User ID一样的权限, 通常情
况下, Effective user ID和Real user ID是相同的, 但是也会有特殊的情况:
hfeng@vagrant:/home/vagrant/tmp$ ls -al total 60 drwxrwxr-x 4 vagrant vagrant 4096 Jul 15 06:56 . drwxr-xr-x 7 vagrant vagrant 4096 Jul 2 07:16 .. -rwxrwxr-x 1 vagrant vagrant 8504 Jul 15 06:56 a.out vagrant@vagrant:~$ ps -eo ruser,euser,suser,comm | grep a.out hfeng hfeng hfeng a.out
- 某个process可能是被root启动的,所有Real User ID和Effective User ID都是 0, 也就是说它有"全部的权限", 也就可以更改自己的Real User ID为任意值.那 么两者就不一样了
- 某个process可能是被普通的用户启动的,但是可能拥有"不普通"用户的权限,
达到这种效果的办法是set-UID, 一旦设置了这个"域",如果某个二进制program
属于高权限用户A,那么无论使用哪个低权限用户B,都可以让这个process把高权
限用户A作为自己的Effective user ID(注意a.out的权限-rwsrwxr-x).
vagrant@vagrant:~/tmp$ chmod u+s a.out vagrant@vagrant:~/tmp$ ls -al total 60 drwxrwxr-x 4 vagrant vagrant 4096 Jul 15 06:56 . drwxr-xr-x 7 vagrant vagrant 4096 Jul 2 07:16 .. -rwsrwxr-x 1 vagrant vagrant 8504 Jul 15 06:56 a.out vagrant@vagrant:~/tmp$ su hfeng Password: hfeng@vagrant:/home/vagrant/tmp$ ./a.out vagrant@vagrant:~$ ps -eo ruser,euser,suser,comm | grep a.out hfeng vagrant vagrant a.out
- Saved UID: Saved UID是专门为set-UID设计的,原因如下:
- 如果一个属于root的program设置了set-UID,那么以其他用户hfeng启动这个
process的话,saved uid不是和real uid一样了,而是和effective uid一样了
root@vagrant:~$ ps -eo ruser,euser,suser,comm | grep a.out hfeng root root a.out
- 之所以这么设置是基于两点:
- 有时候会放弃高权限用户root权限,转到低权限用户hfeng权限. (如果是root 的话,可以转到任何其他用户权限)
- 但当我们从低权限的hfeng再想"直接"转到root的话,是不可能的.所以我们保 留了一个saved uid位置来记录之前"牛逼"的权限,让process可以从"低权限" 更改到"高权限"
- 如果一个属于root的program设置了set-UID,那么以其他用户hfeng启动这个
process的话,saved uid不是和real uid一样了,而是和effective uid一样了
- 一个process的Group ID也分三类:
- Real group ID: real user 所在的primary group
- Effective group ID: effective user 所在的primary group
- Supplementary group IDs: 从parent继承的"补充型"group
- 执行命令的用户为root,或者root拥有的program被设置了set-UID后被执行,都会产生 privileged process.所有其他process都是unprivileged process
Capabilities
- 从Linux 2.2开始,权限被详细的分成了很多类别. 某个process想要做什么样的事情, 必须拥有这个类别的权限. privileged process可以认为是拥有所有权限类别的进程.
The init process
- init process是所有process的parent(或者grand parnt).其program所在的位置是/sbin/init
- init的PID是1, 拥有superuser privilege
- init process只有在关机的时候才能被kill
- init 的主要责任是创建和监管一个running system所必须的一系列程序
- init 只是拥有privileged权限的process,它并不是kernel code.
Daemon processes
- 有一类process叫daemon process, 它们有如下特征:
- long-lived, 通常情况下,开机就启动,知道系统关机
- 在后台运行, 并且没有响应的controlling terminal来读取和写入
- 这样的process有Linux系统自带的, 也有非系统自带的:
- 系统自带
- 非系统自带
Environment list
- 每一个process都有一个environment list,里面是数个environment variable的列表
- 一个process会从它的parent里面继承environment variable的一份拷贝.这也看做是 parent和child通信的一种手段.
- exec()系列system call可以设置参数覆盖原来的environment variable,也可以不覆 盖继续使用原来的.
Resource limits
- 每个process都会消耗一定的资源,比如:
- open files
- memory
- CPU time
- 每个process都有两个数值来确定它们的limit:
- soft limit: 每个process能够拥有的资源量
- hard limit: 每个非privileged process的soft limit可以更改,但是上限是hard limit
Memory Mappings
- mmap() system call是创建新的msmory mapping到调用process的virtual address space
里面去的函数, 这种mapping有两种情况:
- file mapping: 就是把一个文件mapping到virtual address space
- anonymous mapping: 没有对应文件,只不过是创建内容为0的内存page而已
Static and Shared Libraries
- 所谓object library是一个含所有compiled object code(通常是一些代码会调用的函
数)的文件.现代操作系统都有两种object library:
- static library:
- 早期的object library都是static的. 使用static library的program最终会把 static library里面的响应代码编译到自己的binary里面
- 每个process都存一份static library到自己的binary里面是非常浪费硬盘空间, 而且会浪费内存空间:特别是多个process都调用了同一份static library代码,它 们都会要求一份内存地址.那么内存里面就由多份一样的代码.
- 如果library function做了更改,那么所有想使用最新版本library的程序都要重 新编译.
- shared library:
- 和static library不同的是, shared library会在编译的时候在executable里面 标明位置,而不会拷贝这段代码
- 在runtime,只要有一份library的代码运行,那么用到它的process都可以share, 这儿是shared名字的来历.
- 这样一来library升级的时候,使用这些library的代码也不需要进行重新编译.
- static library:
Interprocess Communication and Synchronization
- process有时候需要和其他的process进行配合,从而达到运行目的.最简单能达到"交流" 的方法是通过一个文件,但是这种方法太慢,也不方便.
- 所以,Linux发明了如下丰富的IPC(interprocess communication)手段:
- signals: 声明某件事情出现
- pipes(对shell用户来说,就是'|') and FIFO: 用处就是在process直接传递data
- sockets: 可以跨机器,在process直接传递data
- file locking: 允许process锁住文件的一部分,防止其他process更改
- message queues: 在process之间交换数据
- semaphores: 是用来"同步"多个process操作的
- shared memory: 让多个process共享一块内存空间.当一个process更改这个内存空间 内容的时候,其他process也都能看到
Signals
- Signal一般被称作"software interrupts"和硬件发出的"hardware interrupt"相对应.
- Signal可以由kernel, 其他process,或者本process发出.
Threads
- 在Linux里面共享资源的process就是thread.
Process Groups and Shell Job Control
- shell上的每一个命令都是启动一个新的process
- 主流的shell都提供了一个叫做job control的功能,用来让用户在一个shell里面允许 多个process运行. 这个命令叫做jobs
- jobs控制的当然是job, 在bash的概念里面. 运行在一个pipeline里面的命令是一个
process group(也叫job), 这个pipe里面第一个运行的process就是这个group的lead,
而groupId也是以这个process的PID来命名的. 比如下面的这个例子中, python和more
属于一个process group(job).它们的group id就是pipe里面先运行的python的id(1501).
vagrant@vagrant:~$ python test.py | more& [1] 1502 vagrant@vagrant:~$ jobs [1]+ Running python test.py | more & vagrant@vagrant:~$ ps -eo pid,pgid,comm PID PGID COMMAND 1501 1501 python 1502 1501 more 1503 1503 ps
- 如果没有使用pipe的话,这个process自己组成一个process group.成员是它自己(1507).
vagrant@vagrant:~$ python test.py& [2] 1506 vagrant@vagrant:~$ 1506 1506 vagrant@vagrant:~$ jobs [1]- Running python test.py | more & [2]+ Running python test.py & vagrant@vagrant:~$ ps -eo pid,pgid,comm PID PGID COMMAND 1501 1501 python 1502 1501 more 1506 1506 python 1507 1507 ps
- 需要说明一下的是[+]是最新运行的process, [-]是仅仅跟随[+]process的下一个运行 的process.
- 把一个process转到前台运行办法是fg %[num], 再放到后台是Ctrl+z
vagrant@vagrant:~$ jobs [1]+ Running python test.py & vagrant@vagrant:~$ fg %1 python test.py ^Z [1]+ Stopped python test.py
- 而Ctrl+z之后这个job就会变成Stopped的状态.而让一个后台stopped的proces在后台
running的办法就是bg %[num]
vagrant@vagrant:~$ jobs [1]+ Stopped python test.py vagrant@vagrant:~$ bg %1 [1]+ python test.py & vagrant@vagrant:~$ jobs [1]+ Running python test.py &
Sessions, Controlling Terminals, and Controlling Process
- session是一组process group(job)的组合.session leader是创建这个session的PID,
而这个leader的PID就成了session group的ID,所有的process group都属于创建它的
shell所在的session
vagrant@vagrant:~$ ps -eo pid,pgid,sid,comm PID PGID SID COMMAND 1487 1487 1487 bash 1510 0 0 kworker/0:0 1514 1514 1487 python 1516 1516 1487 ps
Pseudoterminals
- pseudoterminals在Linux中可以应用到X windows的terminal,或者是ssh创建的terminal
- 每当你创建一个pseudoterminal,就会在/dev/pts里面创建一个文件.比如我们有两个ssh
连接到vagrant虚拟机的时候,都会增加一个新的文件.比如我们有两个ssh连接到vagrant
vagrant@vagrant:~$ ls /dev/pts 0 1 ptmx
Date and Time
- 对于process来说,两种时间对它来说比较感兴趣:
- real time:在Unix-like系统中,就是计算从1970年1月1号开始的秒数.当然这个秒数 是根据你的时区不同而不同的.之所以选择这个时间,是因为这个是Unix系统诞生附近 的日子
- process time: 也叫CPU time,就是一个process从开始运行后使用的CPU时间,分成
两个部分:
- system CPU time: 就是kernel 为process工作的cpu时间
- user CPU time: 用户自己执行使用的cpu时间
Client-Server Architecture
- 通常来说client来和用户交流,而server负责提供服务
Realtime
- 注意和前面的real time(有空格)相区别
- realtime是指某种设备:这种设备对输入之后的反应时间有具体要求:一定要在某个时间 内对input做出反馈.
The /proc File System
- 和其他Unix系统一样, Linux提供了一个虚拟的文件系统/proc
- /proc里面其实是一些文件,这些文件里面包含了kernel的数据结构(当然也就包括process 的).
- 我们来看一个例子,某个process的很多内容可以在/proc/[pid-num]文件夹下看到
vagrant@vagrant:/proc$ jobs -l [1]+ 2004 Running python ~/test.py & vagrant@vagrant:/proc$ cat /proc/2004/comm python vagrant@vagrant:/proc$ cat /proc/2004/cmdline python/home/vagrant/test.py vagrant@vagrant:/proc$ ls /proc/2004/ attr/ coredump_filter gid_map mountinfo oom_score schedstat status autogroup cpuset io mounts oom_score_adj sessionid syscall auxv cwd/ limits mountstats pagemap setgroups task/ cgroup environ loginuid net/ personality smaps timers clear_refs exe map_files/ ns/ projid_map stack uid_map cmdline fd/ maps numa_maps root/ stat wchan comm fdinfo/ mem oom_adj sched statm
- 很多配置的bash命令其实就是读取和写入这里的值
Chapter 03: System programming concepts
System Calls
- system call 是一些由kernel控制的entry point, 普通的process可以通过它们来让
kernel为自己完成一些高权限的任务,比如:
- 创建新的process
- 访问IO
- 创建PIPE
- system call有如下"常识":
- system call会更改processor的state, 从user mode => kernel mode, 这样一来CPU 才能访问protected kernel memory(就是读取这些地址的数据到processor里面)
- system call的数目固定,每个system call都被分配了一个数字
- 每个system call都有一系列为这次操作准备的argument
- 从编程的角度上来看, system call看起来像是调用了c语言的一个函数,但是其实从内
部来讲,system call做了很多工作(下面以x86-32为例):
- application应用想调用system call,都是通过调用c语言写成的包裹system call的 所谓"wrapper function"
- 我们调用wrapper function的时候,是将argument通过stack压栈传入的,但是system call使用这些参赛的时候,是希望它们在相应的寄存器里面的.所以wrapper就负责将 参赛从stack拷贝到相应的寄存器.
- 对于kernel来说,system call的不同体现在它们的"ID",也就是system call number 不一样,而触发的方式一样.所以wrapper负责把system call number写入到%eax里面 然后"触发"system call
- 这个"触发"就是machine instruction(int 0x80, int是intrrupt的缩写,是一个机
器语言语句),这其实是一个软件中断(software interrupt), 中断分两种:
- 硬件中断(hardware interrupt)是一种在任意时刻都可能发生的事情,比如我们 从键盘输入数据给计算机. 计算机是无法判断这些中断是什么时候来的
- 软件中断(software interrupt)其实是计算机"自己发给自己"的中断. 其实就是 一种"逃避"的手段,比如上一条指令是中断的话,下一条指令就没法执行了,因为 遇到了中断,当前的环境处理不了.要"跳"到另外的地方去执行,这个"跳到其他地方" 其实就是system call想要的.因为代码再其他地方
- 在"跳到其他地方执行"的同时,也会进行如下操作.
- 将cpu从user mode转化成kernel mode
- 执行system trap vector里面0x80处的代码. (换个角度讲, Linux只不过选择了 x80作为system call的exception 入口地址, 其实完全可以写成int 0x90, 然后 初始化system trap vector的时候,在x90处布置相应的handler)
- 这个system trap vector是在机器初始化的时候被填满的, 在vector的第128(0x80)
的位置,填的正是system_call()的代码地址, system_call主要做的工作是:
- 将cpu当前寄存器的值都存入到kernel stack
- 检查system call number(也就是存到%eax里面的,区别不同system call的序列 号)是否合法
- 根据system call number的不同,查阅sys_call_table后调用相应的routine.然后 调用相应的routine.
- 把routine返回的返回值写入到stack,并且"恢复"刚才保存的所有的cpu原来的寄 存器值
- 通过和int相对应的机器语句iret, 返回wrapper function,同时cpu从kernel mode 变回user mode
- 通常来说,system call routine在出现错误的时候,会返回负数,比如-6. 而wrapper 作为c libray,只是会设置返回值为-1来表示失败(0表示成功),失败的原因则是把system call routine的负数取正,写入到errno里面.
- 上面的这一系列讨论,其实暗示了我们,system call其实在调用的时候,是有一定的 性能损耗的.比如调用1千万次的c语言函数返回integer需要0.11秒,而调用system call getppid()1千万次则需要2.2秒!
- 因为wrapper function(内部调用system call)和对应的system call在c语言看来其实 是一回事,当然wrapper function看起来更c语言,而system call则可能是汇编语言.我 们后面一旦说到system call,其实是说的wrapper function that calls system call!
Library Functions
- library Function是专指standard C library中的一部分函数,这些函数分两类:
- 内部不调用system call(也就是system call wrapper)的,比如字符串相关函数
- 内部调用system call(也就是system call wrapper),但是比system call来的更易 于使用(more caller-friendly)比如malloc()和free()就比system call brk()好用
The Standard C Library; The GNU C Library(glibc)
- 不同的Unix都有自己的standard C library,在Linux上面的版本是GNU C Library
- 我们可以使用ldd命令来处理一个"动态库"的executable文件,就会得到executable使用
的动态库(glibc)的位置
$ ldd a.out linux-vdso.so.1 => (0x00007fffc9547000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f7e8d6f0000) /lib64/ld-linux-x86-64.so.2 (0x00007f7e8dac4000) - 而取得glibc版本的手段则是使用如下函数(能够判断runtime available的glibc版本)
#include <gnu/libc-version.h> const char *gnu_get_libc_version(void); /************************************************************/ /* Returns pointer to null-terminated, statically allocated */ /* string containing GNU C library version number */ /************************************************************/
Handling Errors from System Calls and Library Function
- system call 和library function都会返回statu value来表明自己是否出现了问题, 要记得时刻检查这个返回值,很多错误都是从这里发生的.
System Call Wrapper
- 对于system call wrapper函数来说,除了返回值是-1外,还会给errno这个全局变量设置 一个值(通过前面的介绍我们知道,其实是system call返回-N, 然后wrapper把-1返回 然后把N赋值给errno)
- <errno.h>头文件里面声明了以E开头的这些错误
cnt = read(fd, buf, numbytes); if (cnt == -1) { if (errno = EINTR) { fprintf(stderr, "read was interrupted by a signal\n"); } }
- 成功的system call wrapper函数不会去将errno重置为0,所以一定要再返回值为-1的 时候errno的值才有意义.
- 有时候也会手动先设置errno为0:因为有些函数是-1表示成功(比如getpriority(), 其 优先级就是-1),这个时候通过先设置errno为0,然后再遇到返回值"碰巧"为-1的时候, 通过errno来辨别这个-1是表示"失败"还是一个"有意义的值"(比如优先级为-1)
- 打印错误信息可用perror()和strerror()两个函数
Library Function
- 对于library function来说,情况和system call wrapper稍有不同,可以分成三类:
- -1表示失败, errno写入原因: 这种library function多数是内部调用system call wrapper,所以其错误处理的方法也就是学习了system call wrapper
- 其他表示失败的方式, errno写入原因: 这种肯定也是内部使用了system call wrapper, 所以才能有errno,但是决定不使用-1来表示错误,比如fopen返回NULL表 示失败.
- 其他表示失败的方式,也不写入errno:这种通常没有使用system call wrapper,对 这种函数使用perror()或者strerror()来打印错误是不对的.
Notes on the Example Programs in This Book
- 通常来说传统的Unix都是使用一个'-'加一个字母的方式来表示参数
- GNU提供了新的一种方式就是一个'–'加一个单词的方式
- 我们通过getopt() library function来读取参数
TODO
Chapter 04: File I/O: The Universal I/O Model
Overview
- 所有I/O操作的system call都会使用一个比较小的正整数做为file descriptor. 打开 所有类型的文件都会返回这个file descriptor
- 而每个program在运行之前,都会在shell的帮助下自动打开三个文件(也就用了0,1,2三
个file descriptor). 子所以说是shell的帮助,是因为在shell启动的process,其parent
就是shell,shell一直开着这三个文件, process一启动也就继承了这三个文件
File descriptor Purpose POSIX name stdio stream 0 standard input STDIN_FILENO stdin 1 standard output STDOUT_FILENO stdout 2 standard error STDERR_FILENO stderr - 需要注意的是,fd 0, 1, 2并不是总是对应这三个文件的,如果使用了freopen()的话,可 能某个文件的fd会改变.
- 下面是最常见的跟文件相关的system call, 但是日常使用通常是使用"内部调用这些
system call"的library function:
- fd = open(pathname, flags, mode): 打开(没有的情况下也有可能创建)一个文件
- numread = read(fd, buffer, count): 最多读取count数目的内容到buffer,真正读 取的数目写入numread
- numwritten = write(fd, buffer, count): 和读取相反的写入操作
- status = close(fd): 和打开相反的关闭操作.
Universality of I/O
- Unix所谓"一切皆文件"的特性就是说,open(), read(), write(), close()四个system call可以作用于所有类型的文件,比如device.
Changing the File Offset: lseek()
- 文件打开的时候,kernel会记录一个叫做file offset的变量,其实就是记录文件读取到
哪里了.
#include <unistd.h> off_t lseek(int fd, off_t offset, int whence); /* Returns new file offset if successful, or –1 on error */
- 参数如下:
- fd是文件描述符
- offset是从whence开始的距离
- whence有三种值:
- SEEK_SET: 从文件头开始
- SEEK_CUR: 从刚才的kernel记录的offset开始
- SEEK_END: 从文件末尾开始
- lseek()并不是对所有文件都可以,如下文件不支持"随机读取",也就不能使用lseek():
- FIFO
- pipe
- socket
- terminal
TODO
Chapter 05: FILE I/O: Further Details
Atomicity and Race Conditions
- 所有的system call都是"原子操作",换句话说kernel保证system call所有的step看起 来就像是一个step一样,不可分割.也不会被其他process所interrupt
- system call的原子性并不能保证使用这些system call的用户也能无所顾忌的写出没有 race condition的代码.因为两次system call调用之间还是可能产生"进程调度",也就 存在了race condition的可能.
File Control Operations: fcntl()
- fcntl() system call 主要用来对已打开的文件描述符进行权限操作
#include <fcntl.h> int fcntl(int fd, int cmd, ...); /* Return on success depends on cmd, or –1 on error */
- cmd argument确定是什么操作
- …是可选参数,根据cmd的不同而不同
Open File Status Flags
- fcntl()的一个主要作用是"读取"和"更改"一个open file的:
- access mode
- status flag
- 读取的方法是把cmd设为F_GETFL
int flags, accessMode; flags = fcntl(fd, F_GETFL); if (flags == -1) errExit("fcntl");
- 如果我们想测试这个文件是不是设置了O_SYNC(保证在写入硬盘以前不返回)
if (flags & O_SYNC) printf("writes are synchronized\n");
- 读取access mode稍微麻烦一点:需要先和flags相与
accessMode = flags & O_ACCMODE; if (accessMode == O_WRONLY || accessMode == O_RDWR) printf("file is writable\n");
- 我们设置cmd为F_SETFL就可以写入啦
int flags; flag = fcntl(fd, F_GETFL); if (flags == -1) errExit("fcntl"); flags |= O_APPEND; if (fcntl(fd, F_SETFL, flags) == -1) errExit("fcntl");
Relationship Between File Descriptors and OpenFiles
- 一个file被打开一次就会创建一个open file, 一个file可以被打开多次,当然也就可 以有多个open file
- open file创建的过程会返回file descriptor,这让人很容易产生"file descriptor和 open file是一一对应的"这样的错觉.其实这是错误的想法:一个open文件可以对应多个 file descriptor, 而且这些file descrptor可以在不同的process里面
- 为了了解为什么会有这种机制,我们先看下图
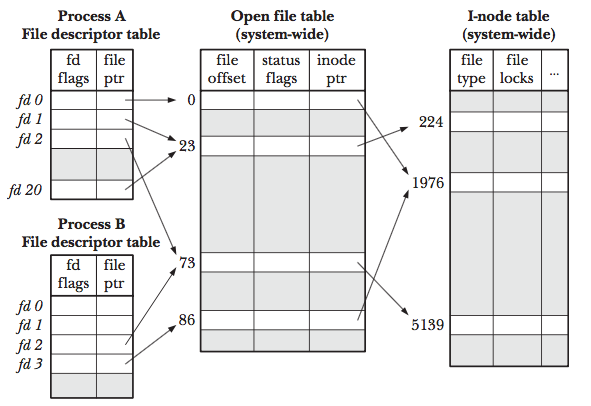
Figure 1: fd-ft-inode.png
- 对于每一个process,kernel都会维护一个open file descriptor table, 其中每个entry
都记录了单个file descriptor的信息, 包括:
- 这个file descriptor的 controlling flag
- 一个指向open file handler的指针
- 对于整个系统,kernel维护了一个open file table, 其中每个entry都记录了单个open
file的信息, 包括:
- current file offset(read(), write()会更新这个offset, 而lseek()可以设置任意的值)
- status flag:打开文件的时候设置的一些文件特性
- access mode: 可读,可写,还是即可读又可写
- signal-driven I/O的设置
- 一个指向i-node object的指针
- 对于每个file system(注意一个host上面可能有好几个文件系统, 一个分区就是一个
文件系统), 都会创建一个i-node table, 其中每个entry都是一个inode的信息.包括:
- file type and permission
- 指向文件拥有的所有的lock的列表
- file 的一系列属性
- 从上图中,我们也可以看到如下特别的地方:
- 在process A里面, descriptor 1和20都指向了同一个open file,这个可以通过调用 dup(), dup2(), fcntl()来实现
- 同样的process A里面的fd2和process B里面的fd2都指向了同一个open file handle 这种情况在fork的时候就会出现(还记得stdin stdout, stderr么)
- 再看process A的fd0和process B的fd3指向了不同的open file handle. 但是这两个 file handle指向了同一个i-node. 在不同进程中打开同一个文件,会出现上述情况.
- 从上面的讨论,我们可以得到如下结论:
- file descriptor自己的flag(比如close-on-exec flag是自己的)即便是fd被复制(通 过dup()等),但是更改其中一个fd的fd flag不会影响另外一个
- 但是open file的flag都是fd之间共享的,通过一个fd更改这些flag是会影响到其他
fd的,比如:
- access mode (O_WRONLY)
- status flag (O_SYNC)
- offset (write(), read(), lseek()等可以更改)
Duplicating File Descriptors
- bash里面有个"将stderr和stdout都redirect到同一个log文件里面的操作", 如下
i309511@ tmp $ cat print_12.py import sys sys.stdout.write('STDOUT\n') sys.stderr.write('STDERR\n') i309511@ tmp $ python print_12.py STDOUT STDERR i309511@ tmp $ python print_12.py > output.txt STDERR i309511@ tmp $ cat output.txt STDOUT i309511@ tmp $ python print_12.py > output2.txt 2>&1 i309511@ tmp $ cat output2.txt STDERR STDOUT
- 我们可以看到,再使用了"2>&1"之后,stderr也成功的进入了output2.txt, 这里用到的
技术其实就是duplicate一个file descriptor, 假设我们只有fd 0, 1, 2和output.txt
的fd3:
- stdout fd1肯定是指向open file handle for output.txt的(因为`>`指定了这个文件)
- 我们使用dup2()命令把stderr fd2也指向open file handle for output.txt
#include <unistd.h> dup2(1, 2);
- 如果用图形化表示,就是上图中process A的fd1和fd20共享open file handle.
- 我们处理这种fd"重新选择open file handle"的情况有三种function:
- dup: 只能保证用"尽可能小"的fd
- dup2: 可以先关闭newfd已有open file handle,然后重新联系就是先close然后dup
- fcntl: 更灵活的dup,不能自己close
File I/O at a Specified Offset: pread() and pwrite()
- 前面我们讲到,一个文件被打开就会创建一个open file的结构体,里面存着current
file offset(也就是read write到哪里了), 如果我们不想改动这个current file
offset, 额外的指定一个offset来读取和写入,那么就要用到
#include <unistd.h> ssize_t pread(int fd, void *buf, size_t count, off_t offset); /* Returns number of bytes read, 0 on EOF, or –1 on error */ ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset); /* Returns number of bytes written, or –1 on error */
- 所有调用pread()和pwrite()的函数,都必须支持lseek(),因为其实pread()就是等于如
下几个call的集合
off_t orig; orig = lseek(fd, 0, SEEK_CUR); /* save current offset */ lseek(fd, offset, SEEK_SET); s = read(fd, buf, len); lseek(fd, orig, SEEK_SET); /* restore original file offset */
- 这种不改动current file offset的读取system call对于multithread应用非常的重要:
- 一个process里面的thread都是共享fd的,也就共享了open file里面的current file offset.
- 多个thread使用pread()或者pwrite()就可以不用担心相互打扰,而产生race condition 了(如果在两个thread里面使用lseek(),则肯定会出现race condition)
Scatter-Gathr I/O: readv() and writev()
- 就是将文件内容读取(或者写入)到多个buffer
#include <sys/uio.h> ssize_t readv(int fd, const struct iovec *iov, int iovcnt); /* Returns number of bytes read, 0 on EOF, or –1 on error */ ssize_t writev(int fd, const struct iovec *iov, int iovcnt); /* Returns number of bytes written, or –1 on error */
- 其中的iovec是一个结构体
struct iovec { void *iov_base; /* Start address of buffer */ size_t iov_len; /* Number of bytes to transfer to/from buffer */ };
- 这两个写入或者读取操作都是在一个system call里面完成的, 我们也不会畏惧其他也 拥有这个fd的process(或者thread)在这期间对文件做什么(2.6开始, system call可以 被interrupt,如果readv()或者writev()被抢占的话,上述system call会失败)
- 将readv, writev和pread, pwrite结合就形成了批量写入(读取)文件的多线程版本
#define _BSD_SOURCE #include <sys/uio.h> ssize_t preadv(int fd, const struct iovec *iov, int iovcnt, off_t offset); /* Returns number of bytes read, 0 on EOF, or –1 on error */ ssize_t pwritev(int fd, const struct iovec *iov, int iovcnt, off_t offset); /* Returns number of bytes written, or –1 on error */
Truncating a File: truncate() and ftruncate()
- 更改文件的大小,多则增加,少则补零
#include <unistd.h> int truncate(const char *pathname, off_t length); int ftruncate(int fd, off_t length); /* Both return 0 on success, or –1 on error */
- truncate()是唯一一个可以不先调用open()就能做IO操作的system call
Nonblocking I/O
- 当我们打开一个文件的时候,可以设置一个flag为O_NONBLOCK,一旦设置有如下好处:
- 如果文件不能被马上打开,那么open()就返回error,而不是blocking在那里等待文件 相应.
- 一旦通过这次open()打开以后,这个open file handle就拥有了nonblocking属性,所 有在这个open file handle所指向的fd上做的其他IO操作,都是nonblocking的.
- O_NONBLOCK的设置对于如下文件类型都适用:
- device
- pipe
- FIFO
- socket
- 对于pipe和socket来说,由于其不是被open()所打开的,所以还要使用fcntl() F_SETFL 来设置这个域.
- 我们会发现上面列出的O_NONBLOCK设置所应用的范围不包括普通文件(regular file), 这是因为kernel buffer cache的机制保证了regular file永远不会fail
I/O on Large Files
- 32位机器上面的offset最大为2**31-1 bytes,大概是2GB,所以需要一些处理.
- 64位机器上,现阶段还没有遇到这些问题.
The /dev/fd Directory
- 对于每个process来说,kernel都为它提供了一个特殊文件夹叫做/dev/fd, 这个文件夹
里面的文件都是以fd的名字来命名的,比如0,1,2代表standard input, output,error
那么shell这个process的/dev/fd下面至少有这三个文件
vagrant@vagrant:/dev/fd$ ls -l total 0 lrwx------ 1 vagrant vagrant 64 Jul 28 04:25 0 -> /dev/pts/0 lrwx------ 1 vagrant vagrant 64 Jul 28 04:25 1 -> /dev/pts/0 lrwx------ 1 vagrant vagrant 64 Jul 28 04:25 2 -> /dev/pts/0 lrwx------ 1 vagrant vagrant 64 Jul 28 07:05 255 -> /dev/pts/0
- 我们可以把/dev/fd/FD_NUM,当成是文件来用.
- 还记得xargs么,它能把管道前面计算的值放到最后
vagrant@vagrant:~$ diff t1.txt t2.txt 10a11 > AGAIN vagrant@vagrant:~$ ls t2.txt | xargs diff t1.txt 10a11 > AGAIN
- 如果我们想比较的是diff t2.txt t1.txt 而不是diff t1.txt t2.txt怎么办呢,bash
有个特殊的符号叫做"-",代表standard output
vagrant@vagrant:~$ cat t2.txt | diff t1.txt - 10a11 > AGAIN vagrant@vagrant:~$ cat t2.txt | diff - t1.txt 11d10 < AGAIN
- 但是"-"广泛的使用于bash命令行,有很多解释,很容易出现解析失误的情况,这个时候
/dev/fd/FD_NUM就起作用了(但是比起xargs还是有差距,xargs是逐个的把结果提供
给后面的命令)
vagrant@vagrant:~$ cat t2.txt | diff - t1.txt 11d10 < AGAIN vagrant@vagrant:~$ cat t2.txt | diff /dev/fd/0 t1.txt 11d10 < AGAIN
- 还记得xargs么,它能把管道前面计算的值放到最后
Creating Temporary Files
- 我们可以通过如下的两个system call创建temp文件:
- mkstemp的参数template是会更改的,所以要使用character array
#include <stdlib.h> int mkstemp(char *template); /* Returns file descriptor on success, or –1 on error */
- tmpfile在打开文件的时候,设置了O_EXCL flag, 这个flag能够保证临时文件名不可 能存在, 也不会和'其他process同时创建的文件'重名.
- mkstemp的参数template是会更改的,所以要使用character array
Chapter 06: Processes
Processes and Programs
- process是program的executing状态.所以program里面就要包括所有描述process运行
时刻的信息, 这些信息包括:
- Binary format identification: 每个program都会采用一种meta格式,好让kernel
"有章可循"的解析文件,常见的类型有:
- assembler output (如今不常用)
- Common Object File Format(如今不常用)
- Executable and Linking Format(ELF). (当下默认的标准)
- Machine-language instructions: 机器语言其实就是汇编,程序的逻辑都是这部分 控制
- Program entry-pint address: 说明了文件从"汇编语言"的何处开始运行
- Data: 用来初始化变量的数字,以及literal constant(比如字符串)
- Symbol and relocation tables: 标记function, variable的位置和名字.这些信息 对于debug非常有用
- Shared-library and dynamic-linking information:列出需要链接的"动态链接库" 和linker的地址
- Other information: 还有其他一些信息
- Binary format identification: 每个program都会采用一种meta格式,好让kernel
"有章可循"的解析文件,常见的类型有:
- 一个program可以被运行多次,每次都是一个不同的process.
- 在前面介绍的这些知识的情况下,我们能给process一个更精准的定义:process其实是kernel
定义的一种抽象个体, 这种抽象个体用来存储运行一次program所需要的资源
A process is an abstract entity, defined by the kernel, to which system resources are allocated in order to execute a program
- 从kernel的角度去理解,所谓的process就是一系列的user-space的内存,这些内存包含
以下信息:
- program code
- program code使用的variable
- 一系列表示process状态的kernel data,比如:
- virutal memory table
- table of open file descriptors
- signal delivery and handling
- process resource usage and limit
- current working directory
Process ID and Parent Process ID
- 每一个process都有自己的ID叫做PID,pid作为唯一的标示,有其重要的作用,比如kill() 就是以specific process ID为参数,关闭那个process
- getpid() system call就是用来返回调用process的PID
#include <unistd.h> pid_t getpid(void); /* Always successfully returns process ID of caller */
- Linux系统中,只有init的ID为1这是不变的,其他process的ID为什么并不总是固定的
- Linux会限定本机创建的process的数目,这个数目为32767. 当这个数目用尽了以后,会 从300开始重新赋予新的process ID(当然这些ID是退出的process用剩下的)
- 从2.6版本开始,Linux把最大可使用的process的数目保存在了/proc/sys/kernel/pid_max
里面. 而且可以通过更改这个值来改变最大process的数目:
- 对于32bit系统来说,最大就是32768了,但是你可以选择一个较小的其他数目
- 对于64bit系统来说,最大是2**22(大概是4百万)
- 每个process都有自己的parent process,也就是创建自己的process,我们通过system
call getppid()来获取这个数值
#include <unistd.h> pid_t getppid(void); /* Always successfully returns process ID of parent of caller */
- process的parent有parent,最终的"root"是pid为1的init
- 如果一个child的parent在它运行之前就退出了,那么这个child的parent就会变成init
Memory Layout of a Processes
- 前面我们说了program的layout,当program运行起来以后,在内存中也有其相应的layout
这个layout由多个part组成,每个part叫做一个segment:
- text segment: 是保存着program里面的machine instruction. 这个segment是被标 记为read-only的,所以一个process不会不小心更改了"运行'自己的指令序列.因为 多个program可以多次运行成多个process,所以其实每个process里面的text segment 都是一样的,所以可以把一份program code的copy映射到多个process的virtual address space
- initialized data segment:保留着"代码中明确初始化了的"global 和 static的变 量,这个也是从program里面读取的.
- uninitialized data segment: 保留着"代码中没有明确初始化的"global 和 static 变量.这个不是从program里面读取的,program里面也没有.因为没有初始化,所以值都 是为0,从而program也不需要记录他们的值和位置.所以只有program在runtime变成 process的时候才真正分配"内存"给它们. 历史上这个区域叫做bss segment (block started by symbol)
- stack segment: stack是一种动态"生长"和"缩退"的segment. 每当为一个function "自动"分配虚拟内存的时候,其参数,local variable, 返回值也会"紧接着"分配虚拟 内存.当这个function调用完成后,这些内存又"自动"释放. stack segment是从"高 地址"向"低地址"生长的
- heap segment: 是在运行的时候,动态分配的内存. heap segment是从"低地址"向"高 地址生长"的,生长的终点就是stack segment的顶点.换句话说stack和heap是公用地 址的(相对生长),当然这个地址很大.
- 我们可以使用size命令来查看一个可执行文件的segment大小(只有text data bss大小)
剩下的dec是十进制,hex是十六进制表示的三个部分的总大小
vagrant@vagrant:~/tmp$ size a.out text data bss dec hex filename 1131 552 8 1691 69b a.out
- 理解这三个区域是'在process创建的时候就存在,且大小不变'这件事情是非常重要的.
这有助于让我们理解某些返回值为pointer的library function:
- 这些library function返回的pointer必须指向data或者bss的内存地址,因为只有这 两块地址是不跟随function消失而消失,同时也是可写的.
- 一个library function返回了'指向static分配的内存pointer'的话,就必然无法做到 reentrant(可重入). 因为static分配内存可能会被下一次的程序调用所覆盖
- 下面一个程序介绍了一个程序每个部分都属于哪个segment
#include <stdio.h> #include <stdlib.h> char globBuf[65535]; /* Uninitialized datat segment */ int primes[] = { 2, 3, 5, 7}; /* Initialized data segment */ static int square(int x) { /* Allocated in frame for square() */ int result; /* Allocated in frame for square() */ result = x * x; return result; /* Return value passed via register */ } static void doCalc(int val) { /* Allocated in frame for doCalc() */ printf("The square of %d is %d\n", val, square(val)); if (val < 1000) { int t; /* Allocated in frame for doCalc() */ t = val * val * val; printf("The cube of %d of %d is ", val, t); } } int main(int argc, char *argv[]) { static int key = 9973; /* Initialized data segment */ static char mbuf[10240000]; /* Uninitialized data segment */ char *p; /* Allocated in frame for main() */ p = malloc(1024); /* Points to memory in heap segment */ doCalc(key); return 0; }
- 下图则展示了一个典型的4G虚拟内存是如何在一个process里面映射的(注意灰色部分 是process无法使用的地址范围).
- 我们注意到0xC0000000以上到FFFFFFFF,是kernel的空间,虽然被映射到了process的virtual
memory,但是对于program来说,却不能访问(我们注意到这个区域大小是4G中的1G,因为
11占了00,01,10,11中的四分之一)
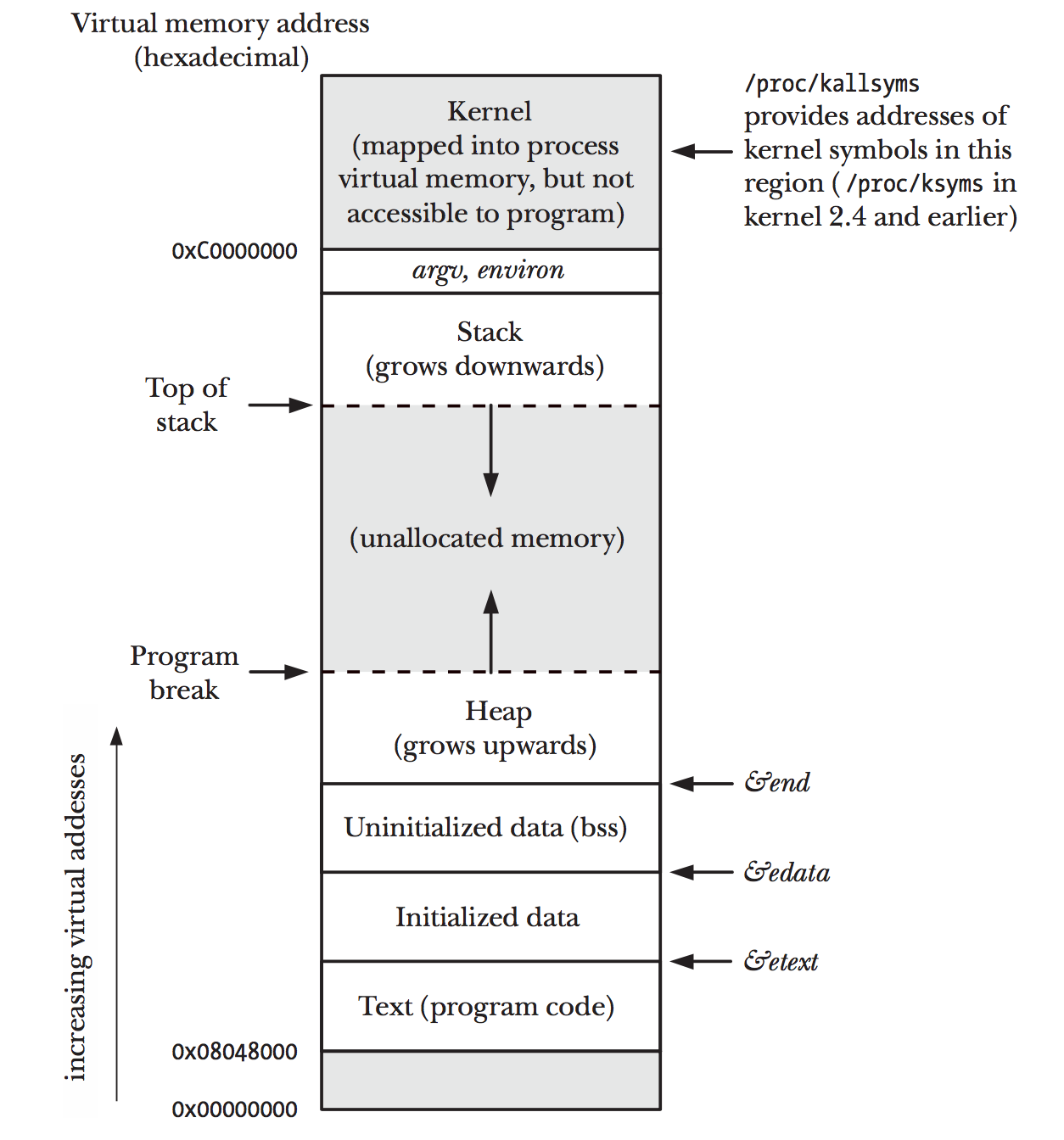
Figure 2: memory-layout-process.png
irb(main):013:0> "C0000000".to_i(16).to_s(2) "C0000000".to_i(16).to_s(2) => "11000000000000000000000000000000"
Virtual Memory Management
- 我们前面讨论的process的内存layout,其实是基于了virtual memory的系统.virtual memory系统的设计是基于提高CPU和RAM的利用率.
- 之所以virtual memory能够提高cpu和内存的利用率,是因为大多数的program在locality
(定位)方面有如下特点:
- spatial locality: program有很大可能访问"刚才访问的内存"附近的内存
- temporal locality: program有很大可能访问"刚才访问过的内存"
- 这两种locality决定了:当我们执行program的时候,其实我们只需要有一小部分address space真正的在内存里面就好了.
- virtual memory系统的要点如下:
- virtual memory就是把program使用的内存分成一个一个的小块(叫做page),同时RAM 也会把自己分成和page大小相同的单位,叫做page frame
- 在运行的时候只有一小部分的page是真正放在page frame里面的
- 如果process用到了一个page,但是这个page不在page frame里面,那么会触发page fault 一旦出现page fault,kernel就会停止当前的process运行,待它把相应内存page放入 page frame以后,再继续运行刚才的process
- 为了能将address space里面的page和RAM里面的page frame进行一一对应, kernel为
每一个process都配备了一个page table. page table里面,要么指明了page所在的page
entry,要么直接说明这个page还在硬盘上
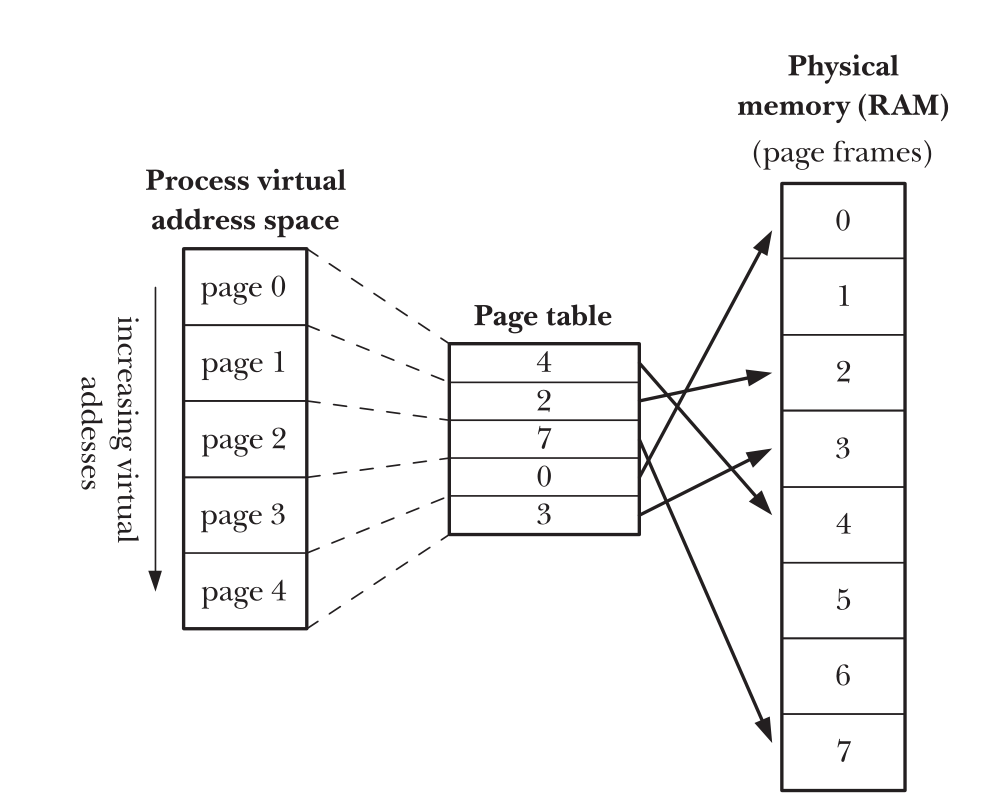
Figure 3: page-table.png
- 并不是process的每个address space都需要page table,因为大部分的address space 都没有使用,如果process试图访问一个没有page-table entry对应的address space的 时候会触发SIGSEGV signal. 需要注意出现了SIGSEGV肯定是地址访问的违法,如果地 址是新创建,还没有对应的page table, page fragment的话,kernel会"自动的"分配新 的page table给process. 而不会发出signal
- process valid的virtual address (也就是有page table entry的地址)是随着其运行
而不断改变的,改变的情况有如下:
- stack向下(低地址)生长的时候,到了一个自己原来从来没到过的低地址.(stack可能 先向下生长,然后回退)
- 通过system call brk(), sbrk(), malloc分配heap地址,并且把heap的最高地址program break提高到原来没到过的高地址(heap可能先向上生长,然后回退)
- System V shared memory合并和分离的时候
- 当使用mmap()和munmap()被调用的时候.
- Virtual memory机制将process的address和珍珠的RAM的物理内存进行了分割,这带来了
很多的好处:
- process之间相互隔离,process和kernel之间相互隔离.因为不同的process的page table entry指向不同的物理内存就可以做到
- 有些时候,process还希望共享一些内存,这个时候,让不同的process的page table
entry指向相同的物理内存,就做到了share内存.通常需要share的情况有如下:
- 多个process运行同一个program的时候,text segment可以share(而且是只读的)
- 多个process之间相互通过调用shmget()和mmap()system call分享内存进行通信 (其实也是Linux处理线程的方法)的时候.
- 内存的保护机制也变的容易,不同的process有不同的page table entry指向同一块 page fragment.可以在page table entry里面设置属性,那么对同一个RAM里面的内 容有些process可读,有些process可写就做到了.
- 编程人员和编译器链接器不必考虑program在内存中的物理映射了
- 因为只有一小部分program在内存里面,那么我们可以在内存中存更多的进程, 进程 使用内存的总量可以超过物理RAM大小.因为总有多个process在运行,计算机CPU的利 用率也就提高了.
The Stack and Stack Frames
- 对于Linux 32位机器来说(其他Unix-like的机器也差不多). stack从process可达的最 高地址处开始往下生长(朝着heap),每个processor都有一个专门的寄存器stack pointer 来记录stack fragment的最底处(current top of stack segment)
- 每当有新的function被调用,就会给stack分配额外的frame(增加page entry指向page entry),但是我们注意的是,当function调用完了之后,stack segment只是向回搜索(stack pointer变更),而已经分配给stack的page segment是不会回收的(下次再来到这个地方 直接使用)
- 因为存在着kernel stack这么一说,所以我们有时候会使用user stack来指代stack.kernel stack是非常特殊的一种stack,是kernel为每一个process准备的,保留system call(因 为system call其实也是function)运行信息的stack
- 好了,还是回到user stack,通常来说,user stack会保存如下的内容:
- function arguments and local variable: 调用一个function的时候.都会有些参数 而且函数内部会有一些local variable(在c语言里面local variable也叫automatic variable,因为它是自动分配内存的),这些都会自动被分配到stack frame里面.当然 了这些参数和local变量会随着函数调用的完成而丢失
- call linkage information: 每个function都会使用一些CPU寄存器(比如program
counter,指向下一条机器指令),每当一个function调用另外一个function的时候,当
前所有寄存器的值都要保存起来(到stack里面),因为被调用的function返回的时候,
我们能restore寄存器原来的值.比如我们前面main调用doCalc(),再调用square()的
例子,其stack如下
+----------------+ | Frame for | | main() | +----------------+ | Frame for | | doCalc() | stack ---> +----------------+ pointer | Frame for | | square() | +-------+--------+ | | Direction of | stack growth V
Command-Line Arguments(argc, argv)
- argc和argv我们都很熟悉了,是command line传过来的参数的个数和每个参数的字符串
需要注意的是command本身是占了数组的第一个位置
#include <stdio.h> int main(int argc, char *argv[]) { int j; for (j = 0; j < argc; j++) printf("agrv[%d] = %s\n", j, argv[j]); return 0; } /**************************************************/ /* <===================OUTPUT===================> */ /* $ ./necho hello world */ /* agrv[0] = ./necho */ /* agrv[1] = hello */ /* agrv[2] = world */ /**************************************************/
Environment List
- 除了参数字符串数组, 我们还有一个"环境变量字符串数组",只不过,环境变量字符串 数组的值是"name=value"的形式.
- 因为process在创建的时候,从parent那里获得了一份parent的环境变量,换句话说,这 也是一种parent和child进行通信的方式.
- shell是设置环境变量最常见的地方:
- 对于bash来说设置环境变量如下(移除是unset):
$ export SHELL=/bin/bash - c shell的设置方式如下(移除是unsetenv):
setenv SHELL /bin/bash
- 对于bash来说设置环境变量如下(移除是unset):
- c语言里面也设计了一个global变量environ字符串数组来存储所有的环境变量
#include <stdio.h> extern char **environ; int main(int argc, char *argv[]) { char **ep; for (ep = environ; *ep != NULL; ep++) puts(*ep); return 0; } /**************************************************/ /* <===================OUTPUT===================> */ /* SHELL=/bin/zsh */ /* TERM=dumb */ /* .... */ /**************************************************/
Performing a Nonlocal Goto: setjmp() and longjmp()
- 环境变量还有一个意想不到的作用就是为nonlocal jump保存环境.
- 所谓nonlocal jump是指的可以跳出当前的function环境而放弃中间调用的function直 接回到更上层(或者甚至是最上层main)的方法.而普通goto只能在本function jump
- nonlocal jump是依靠两个函数
#include <setjmp.h> int setjmp(jmp_buf env); /* Returns 0 on initial call, nonzero on return */ /* via longjmp() void longjmp(jmp_buf env, int val); */
- 用法是,在某处设置setjmp, 在调用longjmp的时候,返回到setjmp.就好像setjmp刚调
用过一样,只不过:
- setjmp第一次返回返回值为0
- setjmp给longjmp触发返回,返回值为longjmp设置的val(此val设置0无效,会自动设置 为1,因为setjmp第一次就返回0)
Chapter 07: Memory Allocation
Allocating Memory on the Heap
- heap区域是一块紧跟着bss segment的segment, process可以通过调整这个区域的limit: program break来增加或者减少heap大小
- C程序员一般都会使用malloc来获取heap memory, malloc是一个library function,它 是通过在内部调用system call brk()和sbrk()来实现的
Adjusting the Program Break: brk() and sbrk()
- 如果不考虑负责的情况,那么更改heap的大小,其实就是更改program break的值
- 一旦program break增加了,那么新增加区域的内存地址对于process来说就肯定可以访 问了,但是这些address page并没有对应的page table, 也就不可能存在对应的page fragment,只有真正的访问发生的时候出现了,kernel会自动的真正着手去创建相应的 page table,以及相应的page fragment
- Unix-like系统用来更改program break大小的两个system call 如下
#include <unistd.h> int brk(void *end_data_segment); /* Returns 0 on success, or –1 on error */ void *sbrk(intptr_t increment); /* Returns previous program break on success, or (void*) -1 on error */
- brk()会把program break设置到end_data_segment(注意end_data_segment在32位上
面就是一个32的地址)的位置, 当然了因为virtual memory 一般都是按照page分配的
,所以end_data_segment都会round up到page size的倍数.可惜的是,我们在mac和linux
平台上都实验过了,并不会round up
#include <unistd.h> #include <stdio.h> int main(int argc, char *argv[]) { void *p; int size = 1; p = sbrk(0); printf("size : %d, p : %p \n", size, p); p = sbrk(size); p = sbrk(0); printf("size : %d, p : %p \n", size, p); return 0; } /**************************************************/ /* <===================OUTPUT===================> */ /* size : 1, p : 0x106295000 */ /* size : 1, p : 0x106295001 */ /**************************************************/
- sbrk()就是把program break增加increment大小的位置, 在Linux上这是一个library function,它内部调用了brk().
- sbrk()的返回值是上次program break的位置,所以sbrk(0)就可以返回当前program break 的位置.
- 如果你试图把program break通过brk()设置到比原来的program break还小,那么着显 然会导致灾难(通常是segmentation fault,也就是SIGSEGV)
- 而program break可以设置的最大值,则是不固定的,因为这个值和很多其他的值相关,
比如:
- 每个process都有resource limit,resource limit里面也包含对data segment的大 小要求
- shared memory segment的大小,
- shared library的大小
- SUSv3开始, brk()和sbrk()已经退出历史舞台了.因为它们诞生于virtual memory之前 不太善于管理不连续的内存.
Allocating Memory on the Heap: malloc() and free()
- 一般来说C程序员都会使用malloc()和free()来获取heap内存的,因为它们有更多的优点:
- 是C语言标准的一部分
- 在多线程代码中更容易使用
- 提供了小额内存的申请方式
- deallocate的时候没有直接改动program break,而且维护一个未分配列表.性能更好
- malloc分配的最小单位为byte,声明如下
#include <stdlib.h> void *malloc(size_t size); /* Returns pointer to allocated memory on success, or NULL on error */
- malloc的返回值为void*,可以cast成任意类型的指针.
- malloc(0)在Linux返回一个可以被free()的最小的内存块, SUSv3规定也可以选择返 回NULL
- 如果memory不能够成功分配了(比如program break到了最大值),那么我们要返回NULL, 并且设置errno.所以检查返回值对malloc非常重要
- free是释放heap内存的命令,其参数ptr一定是malloc(或相同类型命令)返回的地址
#include <stdlib.h> void free(void *ptr);
- free()一般来说不会去真的把program break给降低,而是把这些内存放到free block
的list上去,等待下次被malloc分配.这么做有如下几点原因:
- 一般来说被free()的内存大部分都不是"紧挨着"program break的地址,所以降低program break并不现实
- 最大限度的降低sbrk()调用的次数,我们前面讲过了,system call还是比普通的c function要消耗更多的资源的.
- 因为程序通常来说会在一段时间内频繁的申请和释放
- free()的参数为NULL并没有事,但是其参数如果被free调用两次,那通常意味着大的灾 难.
- 下面的例子我们可以看到free的用法,其实free()会在大量连续的空间(通常是128KB
以上)被释放的情况,将program break下调(使用sbrk()). 下例中只有最后一种情况下
才会真正的更改program break
#define _BSD_SOURCE #include "tlpi_hdr.h" #define MAX_ALLOCS 1000000 int main(int argc, char *argv[]) { char *ptr[MAX_ALLOCS]; int freeStep, freeMin, freeMax, blockSize, numAllocs, j; printf("\n"); if (argc < 3 || strcmp(argv[1], "--help") == 0) usageErr("%s num-allocs block-size [step [min [max]]]\n", argv[0]); numAllocs = getInt(argv[1], GN_GT_0, "num-allocs"); if (numAllocs > MAX_ALLOCS) cmdLineErr("num-allocs > %d\n", MAX_ALLOCS); blockSize = getInt(argv[2], GN_GT_0 | GN_ANY_BASE, "block-size"); freeStep = (argc > 3) ? getInt(argv[3], GN_GT_0, "step") : 1; freeMin = (argc > 4) ? getInt(argv[4], GN_GT_0, "min") : 1; freeMax = (argc > 5) ? getInt(argv[5], GN_GT_0, "max") : numAllocs; if (freeMax > numAllocs) cmdLineErr("free-max > num-allocs\n"); printf("Initial program break: %10p\n", sbrk(0)); printf("Allocating %d*%d bytes\n", numAllocs, blockSize); for (j = 0; j < numAllocs; j++) { ptr[j] = malloc(blockSize); if (ptr[j] == NULL) errExit("malloc"); } printf("Program break is now: %10p\n", sbrk(0)); printf("Freeing blocks from %d to %d in steps of %d\n", freeMin, freeMax, freeStep); for (j = freeMin - 1; j < freeMax; j += freeStep) free(ptr[j]); printf("After free(), program break is: %10p\n", sbrk(0)); exit(EXIT_SUCCESS); } /**************************************************/ /* <===================OUTPUT===================> */ /* $ ./free_and_sbrk 1000 10240 2 */ /* */ /* Initial program break: 0x192b000 */ /* Allocating 1000*10240 bytes */ /* Program break is now: 0x22f3000 */ /* Freeing blocks from 1 to 1000 in steps of 2 */ /* After free(), program break is: 0x22f3000 */ /* $ ./free_and_sbrk 1000 10240 1 1 999 */ /* */ /* Initial program break: 0x1ad6000 */ /* Allocating 1000*10240 bytes */ /* Program break is now: 0x249e000 */ /* Freeing blocks from 1 to 999 in steps of 1 */ /* After free(), program break is: 0x249e000 */ /* $ ./free_and_sbrk 1000 10240 1 500 1000 */ /* */ /* Initial program break: 0x20bd000 */ /* Allocating 1000*10240 bytes */ /* Program break is now: 0x2a85000 */ /* Freeing blocks from 500 to 1000 in steps of 1 */ /* After free(), program break is: 0x25bf000 */ /**************************************************/
- 当一个process退出的时候,它所有的memory都会返回给系统(当然也包括申请的heap 里面的memory).所以如果程序运行时间短,理论上是可以不调用free()的,但是基于以 下原因还是最好调用free():明确的free()会让程序更易读
Implementation of malloc() and free()
- 虽然malloc()和free()的实现已经比brk()要好很多,但是依然非常容易用错,所以了解 其实现细节有一定积极作用.
- malloc()的实现相对简单:
- malloc()首先从free()创建的memory block free list里面寻找"最合适大小的" block
- 如果能够找到跟期望的内存大小一模一样的当然更好
- 如果能找到比期望的内存大的,也可以.把这块内存split,"最合适大小"的返回给用 户.剩下的还是放到memory block free list
- 如果没有一个block能够大于期望内存大小,那么就要使用sbrk()来申请大块内存了, 这种情况下,malloc()不是需要多少就sbrk多少,而是会多分配很多(一般是page的 整数倍大小)的内存
- free()的实现细节就充满了"黑科技":
- 当我们的free()把一块释放的内存放到free list的时候,free()是怎么知道它的大
小的呢?答案在于malloc,malloc在分配内存的时候,在返回的内存的前面(紧挨着)
的部分,保留了一块内存写下了当前内存块的大小.如下:
+-----------+---------------------------------+ | Length of | | | | Memory for use by caller | | block(L) | | +-----------+---------------------------------+ ^ | | | Address returned by malloc() - 更"黑"的科技是free()如何把一块内存加入到freelist:它征用了紧挨着length后面
的内存,把两个指针写进去了一个pre,一个next
+-----------+------------+-------------+---------------------+ | Length of | Pointer to | Pointer to | | | | Prev free | Next free | Remaining bytes of | | block(L) | block(P) | block(N) | fre block | +-----------+------------+-------------+---------------------+ ^ | | | Address returned by malloc()
- 当我们的free()把一块释放的内存放到free list的时候,free()是怎么知道它的大
小的呢?答案在于malloc,malloc在分配内存的时候,在返回的内存的前面(紧挨着)
的部分,保留了一块内存写下了当前内存块的大小.如下:
- 鉴于malloc()和free()的设计是如此的精妙,我们在使用它们的时候,要遵循以下的规
则:
- 当我们从heap申请到内存的时候,记住不要动内存指定的范围以外的内容
- free()两次malloc返回的内存是错误的,有时候free两次会返回SIGSEGV,但其实这是 一个unpredictable behavior
- 永远不要free一个不是来自malloc的指针
- 如果是一个long-running program,每一次的heap内存申请,必须对应一次heap的释 放.否则就会造成内存泄露
Other Methods of Allocating Memory on the Heap
- 我们还可以使用calloc为数组类型申请heap内存
#include <stdlib.h> void *calloc(size_t numitems, size_t size); /* Returns pointer to allocated memory on success, or NULL on error */
- 使用realloc()来扩大malloc()原来分配的空间,但是由于很多时候,heap的连续可用
空间不大,其实realloc()经常是重新分配一块空间,所以效率不高
#include <stdlib.h> void *realloc(void *ptr, size_t size); /* Returns pointer to allocated memory on success, or NULL on error */
- 有时候,想分配一个heap空间,但是希望它的地址从一个boundary的整数倍开始,那么
就有了
#include <malloc.h> void *memalign(size_t boundary, size_t size); /* Returns pointer to allocated memory on success, or NULL on error */
- SUSv3规范对上述情况提供的官方函数的声明如下
#include <stdlib.h> int posix_memalign(void **memptr, size_t alignment, size_t size); /* Returns 0 on success, or a positive error number on error */
Allocating Memory on the Stack: alloca()
- 和heap对应的stack(高地址向地地址生长),申请的时候,是使用函数alloca
#nclude <alloca.h> void *alloca(size_t size); /* Returns pointer to allocated block of memory */
- 和heap地址不同,我们不需要free()我们alloca的地址
- 如果不听的调用alloca(),那么stack地址会用完,进而发生stackoverflow,此时的程序 行为也是unpredictable的(很多情况下会得到SIGSEGV)
- 通常来说alloca()都会被malloc()快,这是因为:
- alloca()通常都是以inline code实现的
- alloca()的任务简单,只是更改stack pointer, 而malloc则要维护一个block free list
- alloca()不仅仅比malloc()快,而且更容易使用,因为:每当function结束的时候,会restore 寄存器,从而自动的把stack pointer寄存器的值更改为调用前的值.也就顺便释放了内 存.使用alloca()不会导致内存泄露
Chapter 08: Users and groups
The Password File: /etc/passwd
- 一般来说/etc/passwd包含着如下面一行所显示的多行的信息
mtk:x:1000:100:Michael Kerrisk:/home/mtk:/bin/bash
- 下面来分析下":"分开的各个部分的意义:
- mtk: 也就是用户名,登录的时候,就是使用用户名,我们的ls加上参数-l就会显示某 个文件属于哪个用户名
- x: 也就是encrypted password:一般来说这里会有13个字符的加密密码,但是由于现 在多采用"shadow password",也就是把加密密码放到/etc/shadow里面去.所以这里 就使用一个x作为"占位符". 如果/etc/shadow对应的密码为空,那么这个x也是空,也 就意味着用户可以不使用密码登录
- 1000:第一个1000是用户的UID,如果这个数字为0的话,那么意味着是超级用户(通常 是root). Linux2.2以前UID是使用了16位存储,所以最多用户为65535,Linux2.6开始 使用32位存储,则最大用户数则多的多了
- 1000:第二个1000是用户的GID,这个Group是用户序列的"第一个"group,也叫primary group
- Michael Kerrisk: 这个域叫comment,其实就是对username的description
- /home/mtk:这个是home文件夹,登录以后,这个域就变成HOME环境变量
- /bin/bash:这个是默认的shell,登录以后,这个域变成SHELL环境变量
The Shadow Password File: /etc/shadow
- 历史上,Unix系统是把密码存到/etc/passwd里面的,但是/etc/passwd里面又含有了太
多的"非密码"的信息,所以很多"低权限"的用户,也要有read /etc/passwd的权限.这就
造成了很多漏洞:
因为基本上所有的用户都有权限读取/etc/passwd,权限较低的用户可 以读取/etc/passwd里面权限较高用户的encrypted password,然后采 取"撞库"的方法猜测高权限用户的密码 - 出现上面错误的原因在于/etc/passwd的初衷为"只存储password",但是后来存储了太多
information类的信息.所有最好的办法是把密码单独存储在/etc/shadow里面(文件名字
就有一点'文不对题'了,但是为了兼容性只能忍了), 所以/etc/shadow里面的一行大概
如下
root:$6$5/5YIHUd$vYsjnBgYda/v8BaFlzTnM9CmGxEbgTvuZmiz0whhIY8/ GGndpB7W8Dar0/30MLL3IGGrjpXrzohGltJMOFVV//:16554:0:99999:7:::
The Group /etc/group
- "人以群分",出于对共享资源,文件控制权限等的考虑,把用户分成不同的组是一个很好 的做法.
- 历史上,曾经一个用户只能属于一个group,也就是在/etc/passwd里面制定的group,但是
后来一个user可以属于多个group,所以把group分到两个文件里面去存储:
- /etc/passwd里面存储的,是以用户为index,会列出用户的primary group
vagrant@vagrant:~$ cat /etc/passwd root:x:0:0:root:/root:/bin/bash vagrant:x:1000:1000:vagrant,,,:/home/vagrant:/bin/bash
- /etc/group里面存储的是以group为index. 会列出组的所有成员(当然在/etc/passwd
里面列举过的就不再列举了,比如`vagrant:x:1000:`这一行后面就没有其他用户.
vagrant@vagrant:~$ cat /etc/group adm:x:4:syslog,vagrant cdrom:x:24:vagrant,hfeng sudo:x:27:vagrant dip:x:30:vagrant plugdev:x:46:vagrant vagrant:x:1000: lpadmin:x:117:vagrant sambashare:x:118:vagrant docker:x:998:vagrant,hfeng
- /etc/passwd里面存储的,是以用户为index,会列出用户的primary group
- groups命令可以列出某个用户的所有groups
vagrant@vagrant:~$ groups vagrant vagrant : vagrant adm cdrom sudo dip plugdev lpadmin sambashare docker
- 我们来看一个/etc/group里面的item
docker:x:998:vagrant,hfeng
- 通过和/etc/passwd对比,我们也大概猜出它们的作用:
- docker:是groupname
- x:原来是密码,现在存在/etc/gshadow
- 998:就是GID,一般来说,GID为0 group root的ID
- vagrant,hfeng: 剩下的就是username 列表了.
Retrieving User and Group Information
- 获取用户信息的函数为
#include <pwd.h> struct passwd *getpwnam(const char *name); struct passwd *getpwuid(uid_t uid); /* Both return a pointer on success, or NULL on error; s */ /* ee main text for description of the “not found” case */
- 获取group信息的函数为
#include <grp.h> struct group *getgrnam(const char *name); struct group *getgrgid(gid_t gid); /* Both return a pointer on success, or NULL on error; */ /* see main text for description of the “not found” case */
Password Encryption and User Authentication
- Unix系统的密码是以"不可逆的单向加密"的方法进行保存的,也就是和我们网站存储用 户密码的方法是一样的.验证密码的方式也是把用户输入的密码"加密"后和数据库中的 结果进行对比.
Chapter 09: Process credentials
Real User ID and Real Group ID
- real user ID 和 group ID是指的当前的process是属于哪个用户和group的.
- 一般我们的process都是从shell里面启动的.所以其real user ID和group ID都是从login shell里面获取的.
- 而login shell的real user ID和group ID都是从/etc/passwd里面的第三位(如下1000
为real user ID)和第四位(如下100为group id)获取的
mtk:x:1000:100:Michael Kerrisk:/home/mtk:/bin/bash
Effective User ID and Effective Group ID
- 对于大多数Unix系统来说(Linux有些许不同,因为引入了file User ID, file Group
ID的概念来处理文件访问权限), 用来决定一个process是否可以执行某些权限的操作:
- effective user ID
- effective group ID
- supplementry group ID
- 而一个process拥有的effective user ID为0的话, 这种process叫做privileged process 有很多system call只能被privileged process来调用
- 通常来说,effective user & group ID是和real user & group ID是一样的.但是我们
可以通过如下的两种方式改变:
- 调用system call, 这个可以在process启动以后用来改变自己的effective user &
group ID
int setuid(uid_t uid); int setgid(gid_t gid);
- 使用set-user-ID和set-group-ID,这个是要在process启动之前就得设置
- 调用system call, 这个可以在process启动以后用来改变自己的effective user &
group ID
Set-User-ID and Set-Group-ID Programs
- 更改process effective user&group ID的一种比较"受限制"的改法是使用set-User&Group-ID 因为它只能将effective user&group ID改成executive文件owner的ID和group ID.
- 像其他的文件一样, executive文件也有自己的user ID和group ID来表明自己的归属. 我们set-UID和set-GID的办法其实就是"set effective IDs with UID or GID".
- 因为是执行以前就可以设置的办法,那么一定可以在文件系统的权限中有所说明,说明
的的位置其实是和rwx里面的x相同,因为只有可执行文件才会去设置set UID或者set PID.
vagrant@vagrant:~/tmp$ ls -al a.out -rwxrwxr-x 1 vagrant vagrant 8600 Jul 31 08:05 a.out vagrant@vagrant:~/tmp$ chmod u+s a.out vagrant@vagrant:~/tmp$ ls -al a.out -rwsrwxr-x 1 vagrant vagrant 8600 Jul 31 08:05 a.out vagrant@vagrant:~/tmp$ chmod g+s a.out vagrant@vagrant:~/tmp$ ls -al a.out -rwsrwsr-x 1 vagrant vagrant 8600 Jul 31 08:05 a.out
- 通过设置set-UID, set-GID, 一般process都会得到"额外"的权限,特别是某个文件是
属于root的时候,一旦设置为set-UID,其effective UID就为0,也就变成了privileged
process. 所以有时候在一些权限不大的shell想运行root级别的操作的时候,就得依靠
set-UID, set-GID.比如
- passwd, 我们的普通用户也需要更改密码, 但是改密码是root级别的权限
- su, 我们普通用户要临时切换到其他用户shell, 但是切换用户是root级别的权限
Saved Set-User-ID and Saved Set-Group-ID
- saved set-uid, saved set-gid看名字就是为了set-uid, set-gid所准备的,它们的作
用是:
把effective User ID和effective Group ID的值都复制一遍存下来. - 存起来的作用是因为effective UID&GID只能在如下两个值之间变动,所以其实saved set
UID 和 saved set GID其实就是一个effective UID的"备份". 当然,这个备份的作用
只有在set UID&GID的时候才有作用,因为只有在那个时候real UID&GID和effective
UID&GID的值才不一样!
- real UID&GID
- saved UID&GID
File-System User ID and File-System Group ID
- 传统的Unix系统只有effective UID&GID来负责权限方面的操作,而Linux则是从这个权 限操作里面取了"文件相关操作"给予了一个新的ID File-System UID&GID.
- 而绝大多数的情况下file-system UID&GID和effective UID&GID的值是一模一样的,只
有在调用Linux专用的两个函数的时候,两个值才会有所不同, 这两个值是:
- setfsuid()
- setfsgid()
- 这个设置只是为了Linux 2.0之前的兼容性,现在通常不予考虑
Supplementary Group IDs
- 除了primary group, Linux还支持每个用户拥有supplementary group,而一个shell启 动的时候,就会从/etc/groups里面继承某个用户的supplementary group的设置,而从 这个shell启动的process也就自动拥有了这些个supplementary Group
- 可以使用如下命令来查看一个process的supplementary group
vagrant@vagrant:~$ ps -eo supgid,comm | grep python 24,998,1000 python
Chapter 10: Time
- 对于一个program来说,我们只对如下的两个时间感兴趣:
- real time: 从某一个固定时间算起,所经历的时间. 这对需要打时间戳的程序非常的 有用
- process time: 测量一个process所使用的CPU时间.检查和优化一个程序的时候,测量 cpu使用时间非常有用
Calendar Time
- 无论你的物理位置是什么(location设置了什么), Unix系统在内部是通过计算自己和 Epoch之间的"秒数"来记录时间的.
- 所谓的Epoch就是:格林尼治时间(UTC)的1970年1月1号午夜.
- Calendar time在Unix是SUSv3标准中是以time_t的类型存储的,在32-bit系统中,这是 一个signed integer, 其最大表示的时间是2038年的某一天,所以32位机器在那天会出 现问题.
- gettimeofday() system call会返回calendar time在tv里面
#include <sys/time.h> int gettimeofday(struct timeval *tv, struct timezone *tz); struct timeval { time_t tv_sec; /* Seconds since 00:00:00, 1 Jan 1970 UTC */ suseconds_t tv_usec; /* Additional microseconds (long int) */ };
- 我们还会看到这个函数"似乎"还返回了表示timezone的tz, 但这是为了历史兼容性,这 个值一直会是NULL的
- 还有一个精度比较低的返回从Epoch到现在"秒数"的system call,只返回秒,没有毫秒
#include <time.h> time_t time(time_t *timep);
- 这个函数会从1返回值2timep两个地方返回"秒数",而常用的方法是"直接给一个NULL指
针"
t = time(NULL);
Time-Conversion Functions
- "秒数"毕竟不容易读,glibc还为我们提供了一系列的library function来把"秒数"转化 为人类可读的字符串
Converting time_t to Printable Form
- ctime()函数是把time_t 值转化成printable的样式
#include <time.h> char *ctime(const time_t *timep); /* Returns pointer to statically allocated string terminated by */ /* newline and \0 on success, or NULL on error */
- 使用方法如下,下面的例子你必须得小心的是ctime返回的是statically allocated
string, 而且这个static的字符串还会被"重复利用", 也就是说下次调用ctime()的
时候,这个static内存还会被"重复"使用.
#include <time.h> #include <stdio.h> int main() { time_t ptr = 0; time(&ptr); char *readable1 = ctime(&ptr); printf("Reaable1: %s\n", readable1); sleep(2); time(&ptr); char *readable2 = ctime(&ptr); printf("Reaable2: %s\n", readable2); printf("readable add is: %p \n" , readable1); printf("readable add is: %p \n" , readable2); printf("Reaable1: %s\n", readable1); printf("Reaable2: %s\n", readable2); } /**************************************************/ /* <===================OUTPUT===================> */ /* Reaable1: Fri Aug 7 06:57:17 2015 */ /* */ /* Reaable2: Fri Aug 7 06:57:19 2015 */ /* */ /* readable add is: 0x7f4776a49c80 */ /* readable add is: 0x7f4776a49c80 */ /* Reaable1: Fri Aug 7 06:57:19 2015 */ /* */ /* Reaable2: Fri Aug 7 06:57:19 2015 */ /**************************************************/
- 也就是说ctime是"不可重入"的.新的可重入的ctime()版本是ctime_r()
Converting Between time_t and Broken-Down Time
- 还可以把time_t转化成broken-down time, 所谓broken-down time其实就是把这个时
间分成详细的时间,broken-down time如下
struct tm { int tm_sec; int tm_min; int tm_hour; int tm_mday; int tm_mon; int tm_year; int tm_wday; int tm_yday; int tm_isdst; };
- 转化函数有两个
#include <time.h> struct tm *gmtime(const time_t *timep); struct tm *localtime(const time_t *timep); /* Both return a pointer to a statically allocated */ /* broken-down time structure on success, or NULL on error */
Timezones
- timezone非常的多,而且善变,所以不适合写到库里,而是保存在文件里面,在文件夹
/usr/share/zoneinfo/下面
vagrant@vagrant:~$ ls /usr/share/zoneinfo/ Africa Chile Factory Iceland MET posix UCT America CST6CDT GB Indian Mexico posixrules Universal Antarctica Cuba GB-Eire Iran MST PRC US Arctic EET GMT iso3166.tab MST7MDT PST8PDT UTC Asia Egypt GMT0 Israel Navajo right WET Atlantic Eire GMT-0 Jamaica NZ ROC W-SU Australia EST GMT+0 Japan NZ-CHAT ROK zone.tab Brazil EST5EDT Greenwich Kwajalein Pacific Singapore Zulu Canada Etc Hongkong Libya Poland SystemV CET Europe HST localtime Portugal Turkey
- 比如我们的上海的timezone信息为
vagrant@vagrant:~$ ls -al /usr/share/zoneinfo/Asia/Shanghai lrwxrwxrwx 1 root root 6 Jun 25 13:24 /usr/share/zoneinfo/Asia/Shanghai -> ../PRC
- 获取本机timezone的函数是tzset(), tzset()首先其实是先查看environment variable TZ
Locales
- locales其实和timezone相似,是在/usr/share/locale
vagrant@vagrant:~$ ls /usr/share/locale aa byn en_CA gez kk ml pl sr@latin ug ace ca en_GB gl km mn ps sr@Latn uk af ca@valencia eo gu kn mr pt sv ur am ce es gv ko ms pt_BR sw uz an chr et haw kok mt ro szl ve ar ckb eu he ku my ru ta vec ary crh fa hi kw nb rw ta_LK vi as cs fa_AF hr ky nds sa te wa ast csb fi ht lb ne sc tg wal az cv fil hu ln nl sd th wo be cy fo hy lo nn se ti xh be@latin da fr ia locale.alias nso shn tig zh_CN bg de fr_CA id lt oc si tk zh_HK bn dv frp is lv om sk tl zh_TW bn_IN dz fur it mg or sl tr zu bo el fy ja mhr os so trv br en ga jv mi pa sq tt bs en_AU gd ka mk pam sr tt@iqtelif
Updating the System Clock
The Software Clock (Jiffies)
Process Time
- process time说的是process从创建开始到现在为止,所使用的CPU时间,kernel把CPU时
间分成两种:
- User CPU time: 在user mode流逝的时间
- System CPU time: 在kernel mode流逝的时间
- 我们可以使用bash里面的time命令来在某个程序运行的时候来查看两个cpu时间各自(以
及一共)用去了多少秒.
vagrant@vagrant:~/tmp$ time ./a.out Done! real 0m3.996s user 0m0.756s sys 0m1.236s
- 其各个时间意义如下
- user就是user cpu time.
- sys就是system cpu time.
- real是指从开始到结束用了多少时间,就是我们这一章最开始讲的real time.而user+sys 的时间其实有可能超过real, 因为会有多个线程同时运行,cpu时间用的多于real time
Chapter 11: System Limits and Options
System Limits
- Unix-like系统总会有些限制,比如文件最大为多少,消息队列有多少个级别等等
- 但是不同的Unix实现总有自己的想法,SUSv3不能强制要求不同实现使用同一种限制,但
是可以给这个限制一个"最低值",这种"最低值"一般都会设置在<limits.h>里面以_POSIX_
开头,然后以_MAX结尾:
- _POSIX_MQ_PRIO_MAX(值为32): SUSv3设置队列的级别最多为32个. 但是Linux认为 这个需要多一点,所以设置了自己的MA_PRIO_MAX为32768
- _POSIX_NAME_MAX(值为14): Linux当然定义了一个更长的文件名长度
Chapter 12: System and Process Information
The /proc File System
- 早期Unix实现如果想知道当前kernel的一些"属性"(atributes),是非常困难的,这些属
性包括:
- 系统有多少的process在运行
- 一共process打开了多少文件
- 有哪些文件被锁,用的锁是哪些
- 系统使用了哪些socket
- 为例这些值,是因为早期Unix系统是使用一些privileged program来进入kernel的memory 来获取这些内存里面的值,从而了解kernel当前的"属性".但是这样做很麻烦,因为你必 须知道kernel的内部存储结构,而且随着内核的升级,你的privileged program也要更改 因为内核的数据结构会升级
- 新的Unix系统(比如Linux)为了让这个过程更加简单,设计了一个叫做/proc的文件系统 这个文件夹下的文件,披露了当前kernel的属性信息,你只需要"读写"这些文件就可以了 解kernel,甚至更改kernel的"属性".
- /proc文件系统是virtual的,它是由kernel在runtime维护的,并不保存到文件系统.
- SUSv3并没有定义/proc系统,下面的介绍只适用于Linux
Obtaining information about a Process: /proc/PID
- 对于每一个process, /proc都提供了/proc/PID的这个文件夹来保存这个process的信 息,其中status是总览.
System Information under /proc
- /proc下面还有很多的"系统级"的参数
Directory Information exposed by files in this directory /proc Various system information /proc/net Status information about networking and sockets /proc/sys/fs Settings related to file systems /proc/sys/kernel Various general kernel settings /proc/sys/net Networking and sockets settings /proc/sys/vm Memory-management settings /proc/sysvipc Information about System V IPC objects
Chapter 13: File I/O Buffering
Kernel Buffering of File I/O: The Buffer Cache
- 我们前面学到过处理disk读写的system call(read(), write()), 但是在实际情况下,
这两个system call并不是去处理disk,而是:
- read(): 从kernel buffer cache读取到user-space buffer
- write(): 把user-space buffer写入到kernel buffer cache
- 下面是一个write()的例子
write(fd, "abc", 3);
- write()是在user space和kernel space拷贝,所以其实就是内存级别的操作,会非常的
快的完成,然后返回.kernel会过"一段时间"才把更改写入到disk. 如果在这"一段时间"
里面,有其他的read()请求,那么kernel就直接把buffer cache里面的内容返回即可,这
样一来:
- 减少了一次disk操作
- 并且read(), write()返回速度明显提升.
- 因为这种buffer cache极大的提高了效率,所以Linux只要有空闲的内存,总是会将它们 改装成buffer cache来提高IO的效率.当然如果当前内存不是很足.kernel会把一部分 的内容先写入disk,从而解放出一部分的buffer cache
- NOTE: 虽然我们buffer cache叫的很欢,但是其实Linux里面已经没有一个数据结构叫
做buffer cache了:
- 在2.2版本以前存在这buffer cache和page cache两个概念.page cache我们说过用 来"映射"process使用的virtual memory的.buffer cache是用来加速IO操作,提升IO 效率的
- 从2.4版本开始, buffer cache不存在了.转而是page cache 起两种作用:即用来"映 射"virtual memory,又用来加速IO
Buffering in the stdio Library
- 再来回顾一下读取和写入的system call 的原型
#include <unistd.h> ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count);
- 我们会发现read(), write()都使用了buf, 而这个buf通常是在user-space里面创建的
automatic变量(也就是在stack上面的变量), 比如下面这个模拟copy的例子. buf[BUF_SIZE]
就是user-space buffer
#include <sys/stat.h> #include <fcntl.h> #include "tlpi_hdr.h" #ifndef BUF_SIZE /* Allow "cc -D" to override definition */ #define BUF_SIZE 1024 #endif int main(int argc, char *argv[]) { int inputFd, outputFd, openFlags; mode_t filePerms; ssize_t numRead; char buf[BUF_SIZE]; if (argc != 3 || strcmp(argv[1], "--help") == 0) usageErr("%s old-file new-file\n", argv[0]); /* Open input and output files */ inputFd = open(argv[1], O_RDONLY); if (inputFd == -1) errExit("opening file %s", argv[1]); openFlags = O_CREAT | O_WRONLY | O_TRUNC; filePerms = S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH | S_IWOTH; /* rw-rw-rw- */ outputFd = open(argv[2], openFlags, filePerms); if (outputFd == -1) errExit("opening file %s", argv[2]); /* Transfer data until we encounter end of input or an error */ while ((numRead = read(inputFd, buf, BUF_SIZE)) > 0) if (write(outputFd, buf, numRead) != numRead) fatal("couldn't write whole buffer"); if (numRead == -1) errExit("read"); if (close(inputFd) == -1) errExit("close input"); if (close(outputFd) == -1) errExit("close output"); exit(EXIT_SUCCESS); }
- user-space buffer大小的选择有技巧,可以想到的有如下两个极端:
- BUF_SIZE为1, 那么拷贝1千万bytes就需要调用1千万次system call read&write
- BUF_SIZE为1000, 那么拷贝1千万bytes只需要1万次system call read&write
- 那么显然是后面的这次调用更加的合理,因为:
- 虽然有buffer cache的存在,kernel可以把1千万bytes暂存起来统一进行一次disk操 作
- 但是system call也是非常耗费系统资源的操作,所以我们BUF_SIZE要"尽可能的大" 到system call所用时间比起"搬运1千万bytes到磁盘的操作"已经可以忽略的程度.
Buffering in the stdio Library
- 调用system call的时候,尽可能多的设置buffer size从而减少system call调用次数,
提高调用效率,是一种很常见的手段.library function也会调用system call,所以也会
提高自己的buffr size.
对于stdio来说,它会自己创造一个buffer,等这个buffer满了以后,才去调用read&write system call - 而对一个文件使用何种buffer size是由下面的函数确定的.
#incude <stdio.h> int setvbuf(FILE *stream, char *buf, int mode, size_t size); /* Returns 0 on success, or nonzero on error */
- 来分析一下这个函数:
- 参数buf:
- 这个参数可以是NULL, 如果是NULL的话, stdio library会使用automatic的内存 (也就是stack上面的内存)创建一个buffer,大小可以由参数size指定,也可以忽略 size. SUSv3就是直接忽略size的
- 如果这个参数不为NULL,那么这个参数指向的内存必须是static的,或者是dynamic 的地址(也就是heap上的), 因为stdio要使用这个地址,所以其地址必须明确(automatic 内存可能在函数退出的时候被压出栈). 这段内存的开始地址为buf,长度为size 单位为bytes
- 参数mode:buf确定了以后,并不是每次都把buffer"用尽", 需要看mode是什么:
- _IONBF: 如果是这个参数,那么buffer不会被使用.每一个stdio library call 之 后就立刻调用read&write() system call(当然了kernel还是会使用buffer cache 进行一下等待的, 这里讨论的是stdio的二次缓冲buffer), stderr就是使用这种 方式,所以可以尽可能快的打印错误
- _IOLBF: 要么是stdio的buffer满了,要么是遇到了换行,两者满足其一就会返回.
- _IOFBF: 只有stdio的buffer满了,才会调用read&write system call
- 参数buf:
- 当然了,我们也可以在任何时候,把当前的buffer里面的内容flush给read&write system call(请注意区别,我们只能强制library function去调用system call, 但是我们不能 强制kernel什么时候进行disk操作)
- flush buffer内容到read&write system call的函数是
#incude <stdio.h> int fflush(FILE *stream); /* Returns 0 on success, EOF on error */
- 如果stream是NULL的话fflush()会flush所有的stdiio buffer
- 当某个stdio buffer对应的stream关闭的时候,会自动进行一次flush
Controlling Kernel Buffering of File I/O
- 前面我们将的fflush其实是"flush user buffer的内容到kernel buffer", 而具体kernel 什么时候把自己的内容flush到disk上,则是我们下面要讨论的内容(不是fflush()能做的到的!)
- 如果一个app需要确认我们的内容已经真正的写入到了disk(而不是只是传给kernel),那 么我们需要force flush kernel buffer
Synchronized I/O data integrity and synchronized I/O file integrity
- SUSv3把kernel的内容是否写入到disk,设计了两类的synchronized I/O completion:
- synchronized I/O data integrity completion: 简言之,就是不影响后续的读取
和写入.:
- synchronized I/O的读取: 一定会确认pending的write都进行完,才读取,而且 (函数返回时)一定是从硬盘读取的.
- synchronized I/O的写入: (函数返回时)一定是写入了disk, 并且相应的meta data也已经都写入disk.
- synchronized I/O file integrity completion: 是上面synchronized I/O data integrity completion的超集,不仅仅不影响读取和写入,而且要求全部的meta信 息都完全准备好了.比如文件的大小会影响下次的写入,但是文件的timestamp却不 会影响.所以文件大小是data integrity level的,而timestamp则是file integrity level的
- synchronized I/O data integrity completion: 简言之,就是不影响后续的读取
和写入.:
System calls for controlling kernel buffering of file I/O
- data integrity completion state级别的flush to disk
#include <unistd.h> int fdatasync(int fd); /* Returns 0 on success, or –1 on error */
- file integrity completion state级别的flush to disk
#include <unistd.h> int fsync(int fd); /* Returns 0 on success, or –1 on error */
Make all write synchronous: O_SYNC
- 当我们open一个文件的时候,如果设置了O_SYNC flag(如下),那么所有对此文件的write()
都是自动的flush kernel buffer到disk的.所以会明显的影响性能!
fd = open(pathname, O_WRONLY | O_SYNC);
- 下面就是我们对flush的一个总结,注意flush的两层意思:'从user buffer到kernel buffer'
和'从kernel buffer 到disk'
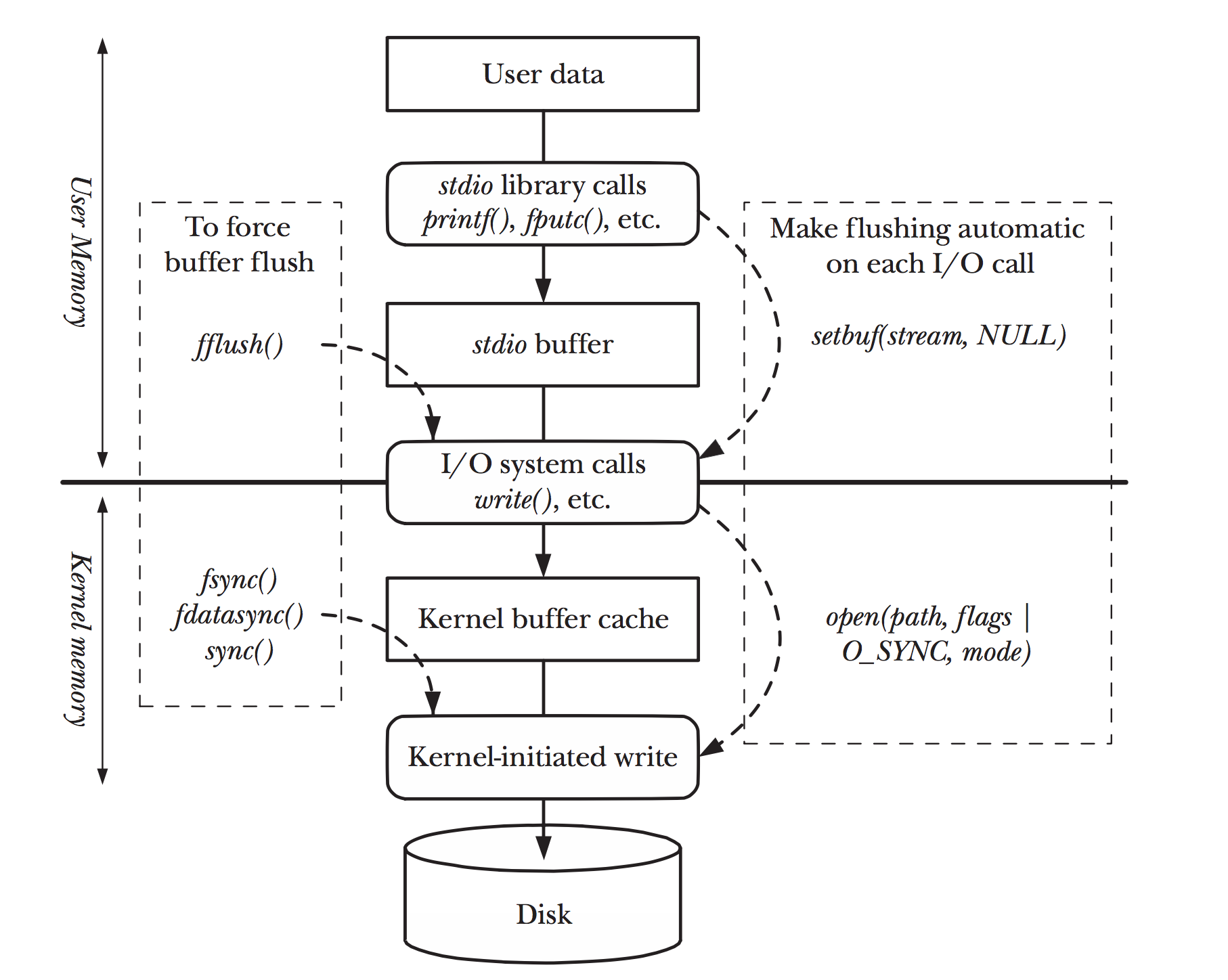
Figure 4: two-flush.png
Chapter 14: File System
Device Special Files(Devices)
- 系统中的device都会对应一些"特殊"的文件叫做device special file
- 在kernel内部,每一类文件才会有一个device driver. 所谓device driver是指的kernel 内部一段"专门处理设备input output"的代码
- device driver处理input output的结果是: 在外看来所有的文件都是一样的拥有相应 的system call: open(), close(), read(), write()
- device可以被分成两个类型:
- character device: 以一个character为单位来处理, terminal和键盘是常见的character device
- block device: 以block为单位(通常位512 byte)来处理, disk和tape是常见的block device
- device在文件系统里面的表示就是device file,他们都再/dev文件夹下面. system call 是super user用来创建/dev下面的device file的命令
- 早起版本中, /dev下面包含了系统所有可能的device, 即便这个device根本没有连接 到系统. udev命令可以很好的解决这个问题,找到真正连接且在使用的设备
- 每一个device file都有一个major ID和一个minor ID:
- major用来确定device file类型
- minor用来确定specific device
- 使用ls -l会列出device file的major和minor id
- device file的major id和minor id其实是存在i-node里面的
- device的名字并不重要,kernel只需要通过major和minor id就可以确定了.
Disks and Partitions
- regular files 和 directory一般都是存在hard disk里面的(当然还会有存在CD, flash memory card的文件).
- hard disk的学名叫做HDD (Hard Disk Drive)是一种机械类的设备,有多个platter(盘 片)组成.
- read/write head是负责读取"存储在platter表面的信息", 而这些信息最小的读取和写 入的单位是512bytes
- 虽然现在硬盘的速度很快,但它毕竟是一个机械动作,其一次读取的时间单位为毫秒级别, 而cpu可以在一毫秒的时间内做百万次的操作.
- 一块硬盘通常会分成多个partition,而每一个partition都在/dev下面被看成是一个独 立的device.
- 我们可以通过fdisk -l来查看机器上面的分区情况
vagrant@ ~ $ sudo fdisk -l Disk /dev/sda: 40 GiB, 42949672960 bytes, 83886080 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x00034370 Device Boot Start End Sectors Size Id Type /dev/sda1 * 2048 83886079 83884032 40G 83 Linux
- 而linux特有的/proc/partitions其实里面就特别详细的记录了这些信息
vagrant@ ~ $ cat /proc/partitions major minor #blocks name 8 0 41943040 sda 8 1 41942016 sda1
- disk partition通常有三种类型:
- file system: 保持regular file, directory的常见"文件"系统
- data area: 数据库会使用的,保持raw-mode的设备
- swap area: kernel 管理memory的时候,会用到.
File Systems
- file system是指用来组织regulaer files和directory的, 可以使用mkfs来创建一个文件系统
- Linux的强项是它支持很广泛的文件系统, 比如:
- ext2
- Unix文件系统,Minix, SystemV, BSD file system
- Microsofts' FAT, FAT32, NTFS
- ISO 9660 CD-ROM file system
- Apple Macintosh's HFS
- 一系列的journaling files system: 包括ext3, ext4, JFS, XFS, Btrfs
- ext2 file system在很多年间都是Linux默认的文件系统,其是最早的Linux文件系统ext 的继承者
- 文件系统里面的最小"allocate"单位叫做logical bolck
- logical block通常是多个连续的physical block, physical block通常为512bytes(这 是因为历史上,一个sector的大小是512Bytes, 虽然最近disk已经有比较大的sector,比 如4096bytes,但是为了兼容性, hard disk还是会通过一些设置让操作系统看起来自己 依然是512bytes一个block, 而使用这种技术的hard disk会把512叫做hardware logic block size, 而把4096叫做hardware physical bloack size非常有趣)所以logical block在ext2上面通常是1024, 2048或者4096bytes
- 下图简单描述了disk partition和file system的关系
+------------------+-----------------------------+---------------+ Disk | partition | partition | partition | | + | | +------------------/-----------------------------\---------------+ / \ / \ / \ / \ / \ / \ / \ / \ +-----+-----+------+----------------------------+ |boot |super|i-node| data blocks | File System |block|block|table | | +-----+-----+------+----------------------------+ - 上图各个部分的说明如下:
- boot block: 这永远都会是file system的第一个block. boot block是不会被file system所使用的.但是它却包含了如何启动操作系统的信息.虽然操作系统只需要一个 boot block.但是所有的file system都保留了一个boot block(大部分都没有使用)
- superblock: 是单独的一个block, 紧接着boot block, 包含了如下的数据:
- i-node table的大小
- 每一个logical block的大小
- 有多少的logical block
- i-node table: 每一个文件或者文件夹又在i-node里面对应了一个entry
- data blocks: 大部分的file system就是data blocks,用来存储文件和文件夹.
I-nodes
- i-node table为每一个当前partition的文件或者文件夹都准备了一个entry,而且这个
entry是有序列号的.使用ls -li就可以得到这个序列号
vagrant@ testCode (master) $ ls -li total 12 1244565 -rw-rw-r-- 1 vagrant vagrant 182 Aug 12 18:57 README.md 1731792 drwxrwxr-x 3 vagrant vagrant 4096 Aug 12 18:57 daily 1731796 drwxrwxr-x 4 vagrant vagrant 4096 Aug 12 18:57 prev
- i-node里面包含了很多的信息,包括:
- file type: regular file, directory, symbolic link, character device
- Owner for the file
- Group for the file
- Access permissions for owner, group, and other. 需要注意的是root通常被认
为是拥有一切的权限.所以一个不能运行的hello.c在root看来也是rwx的,只不过在
执行的时候,会出现command not found错误而已.
vagrant@ tmp $ ls -al hello.c -rw-rw-r-- 1 vagrant vagrant 167 Aug 16 19:39 hello.c vagrant@ tmp $ ./hello.c bash: ./hello.c: Permission denied vagrant@ tmp $ sudo ./hello.c sudo: ./hello.c: command not found
- 三个时间戳
- time of last access to the file (ls -lu: 打开文件的操作,不一定要改动)
- time of last modification of the file(ls -l: 上次改动文件的操作的时间)
- time of last status change(ls -lc: 上次改动i-node的时间: 改动文件内容 "一定"改动i-node.但是改动i-node"不一定"改动文件内容)
- 指向文件的hard link的数目
- 文件以byte记的大小
- "真实"所分配的block的数目.(block的大小为512byte), 这个数目和"以byte记的文 件的大小"两者并不是严格的512倍数的关系,因为file可以有holes
- 指向文件block的指针
- 和其他的Unix文件系统一样, ext2文件系统并不会把文件存储在"连续"的block里面.因 为如果"连续"的存储,会造成空间的浪费(某些文件减小后,会由hole留下)
- ext2的做法是在inode里面保留了15个pointer的空间:
- 前12个指向一个block
- 第13个指向一个block,这个block里面的所有数据都是指针(一个指针4Bytes,根据block size的不同,可以存储数目不同的指针)
- 第14个指向两层block指针数组
- 第15个指向三层block指针数组
- 示例如下:
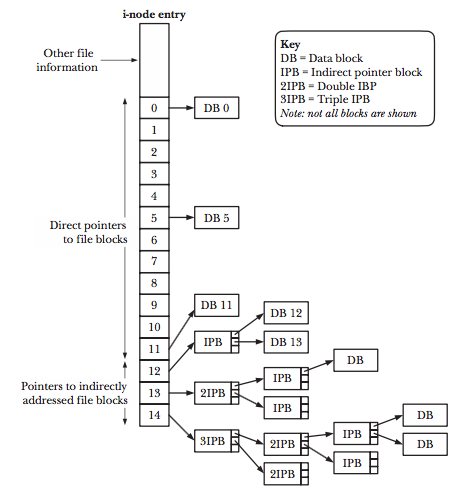
Figure 5: i-node-block.png
The Virtual File System (VFS)
- Linux支持这么多文件系统,靠的是一种万金油的做法:在实际支持的文件系统的上面再
"加一层"Virtual File System. 具体就是两点:
- VFS提供了一系列的接口,比如open(), read(), write(), lseek(), close()等等, Linux上面的应用只需要知道这些接口就可以了
- 每种具体的file system就提供VFS接口的实现就可以了.(如果有些接口无法实现,比 如Microsoft VFAT就不支持symlink(), 这种情况下,VFAT直接返回error code给VFS 层)
- 整个体系的结构图如下
+-----------------+ | Application | +--------+--------+ | | | +--------------------+---------------------+ | Virtual File System (VFS) | +--------------------+---------------------+ | +-------------+------------+------------+------------+ | | | | | | | | | | +---------+ +----+----+ +----+----+ +----+----+ +----+----+ | ext2 | | ext3 | | Reiserfs| | VFAT | | NFS | +---------+ +---------+ +---------+ +---------+ +---------+
Journaling File Systems
- ext2是传统Unix文件系统的榜样,但是它同时也有传统Unix文件系统的问题:
在系统崩溃之后,必须做一次file-system consistency check(fsck). - fsck的必要性在于, 系统崩溃是一种突然事件,很可能在崩溃的同时,正在进行一个文件 的update.由于crash的中断,这次update可能只完成了一部分.file-system的meta data 也会处于一种inconsistent的状态.fsck正是检查并修复这种inconsistent状态的方法
- fsck的问题在于它要检查整个的文件系统,这在大的文件系统上需要长达数小时的时间 进行修复,这是不可接受的.
- 针对fsck的这种缺点, Journaling file system应运而生,其主要的特点,就是
- 把所有的meta update行动,都在真正行动之前先log下步骤.
- 真正行动起来进行update的时候如果遇到了crash,可以从log里面读取信息进行修复
- 这样重启以后的修复就可以保证马上知道错误地点,而不需要全盘检查.所以修复时间 也大大减小到只有几秒(即便是大型文件系统)
- Journaling file system的缺点是file update的时间明显增加.
Single Directory Hierarchy and Mount Point
- 在Linux上面,所有的文件系统都是mount到root(/)下面,作为root的子文件夹而存在的,
mount的方法是命令mount
$ mount device directory
- 而mount命令自己,则可以看已经mount的文件系统和文件夹的对应
vagrant@ ~ $ mount sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime) proc on /proc type proc (rw,nosuid,nodev,noexec,relatime) udev on /dev type devtmpfs (rw,relatime,size=4083864k,nr_inodes=1020966,mode=755) devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000) tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size=817584k,mode=755) /dev/sda1 on / type ext4 (rw,relatime,data=ordered)
Mounting and Unmounting File Systems
- mount()和umount() system call可以允许privileged的进程(CAP_SYS_ADMIN)来mount 和unmount文件系统.大多数的Unix系统都提供了这两个系统调用,但是他们都不是SUSv3 标准里面的.
- 有三个配置文件,保存了"当前已经mounted的文件系统"和"有可能被mount的文件系统"
的配置信息:
- 已经被mount的文件系统的信息可以从Linux特有的/proc/下面读取,具体文件是/proc/mounts /proc/mounts是一个kernel 数据结构的interface.所以这里面的信息是最为准确的
- mount(8)和umount(8)这两个命令本身会自动更新的文件是/etc/mtab, 这个文件里面 的内容和/proc/mounts里面的内容是相似的,但是更加详细.但是不够准确,因为mount() 和umount()系统调用(和mount(8)不一样)是不会更新这个文件的
- /etc/fstab文件,由系统管理员更新,保存了"可以被"mount的文件系统(不再是"已经 被mount的系统"了),这个文件还是被mount(8), umount(8), fsck(8)命令所使用.
- 这三个配置文件/proc/mounts, /etc/mtab, /etc/fstab, 都共享一种format
/dev/sda9 /boot ext3 rw 0 0
- 这一行的信息包括:
- 被mount的device
- mount point
- file-system type
- mount flag: 上面的例子表示这个文件系统是可读可写的
- dump(8)用来控制file-system operation的数字./proc/mounts和/etc/mtab不使这 个数字,所以一直为0
- fsck(8)用来控制file-system order的数字/proc/mounts和/etc/mtable不使用这个 数字,所以一直为0
Mounting a File System: mount()
- mount()系统调用把source表示的文件系统,mount到target表示的directory下面
#include <sys/mount.h> int mount(const char *source, const char *target, const char *fstype, unsigned long mountflags, const void *data); /* Returns 0 on success, or –1 on error */
Unmounting a File System: umount() and umount2()
- umount()是unmount在target所指定的文件系统
#include <sys/mount.h> int umount(const char *target); /* Returns 0 on success, or –1 on error */
- umount2()是umount()的加强版本可以指定一个flag参数
#include <sys/mount.h> int umount2(const char *target, int flags); /* Returns 0 on success, or –1 on error */
Advanced Mount Features
- TODO
A Virtual Memory File System: tmpfs
- 前面我们讲的所有的信息都是讲一个disk在文件系统里面怎么映射,而Linux还提供了 一种叫做virtual memory file system的技术:就是把内存映射到文件系统里面
- 对于application来说,virtual memory file system里面的文件和普通文件没有区别 但是速度更快,因为文件是在内存里面的.
- 在众多的内存文件系统里面,最出名的就是tmpfs:其特点是不仅仅使用内存,有时候还 会使用swap space
- 创建一个tmpfs文件系统的方法如下
# mount -t tmpfs source target
- 其中source只是一个符号,其地位和/dev/sda1相同, 但是和/dev/sda1不同的是,它不需
要使用mkfs先创建(当然target point还是要先mkdir的).
vagrant@precise32:~$ mkdir /tmp/workspace vagrant@precise32:~$ sudo mount -t tmpfs newtmp /tmp/workspace vagrant@precise32:~$ cat /proc/mounts | grep newtmp newtmp /tmp/workspace tmpfs rw,relatime 0 0 vagrant@precise32:~$ cat /proc/mounts rootfs / rootfs rw 0 0 sysfs /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0 proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0 /dev/sda1 /boot ext2 rw,relatime,errors=continue 0 0 newtmp /tmp/workspace tmpfs rw,relatime 0 0 - tmpfs名字的由来是:一旦我们unmount 这个tmpfs,或者宕机,那么这个文件系统里面所 有的东西都会不见了
- tmpfs最大可以使用内存的为当前内存的一半.当然,你也可以在/etc/fstab里面设置最
大可用内存的大小.比如下面设置最大可用内存为8G, 当然也可以在mount的时候指定
size=8G
tmpfs-hfeng /tmp tmpfs nodev,nosuid,size=8G 0 0
Obtaining Information About a File System: statvfs()
- statvfs()和fstatvfs()两个library function的作用是获取已经mount的文件系统的
信息
#include <sys/statvfs.h> int statvfs(const char *pathname, struct statvfs *statvfsbuf); int fstatvfs(int fd, struct statvfs *statvfsbuf); /* Both return 0 on success, or –1 on error */
- 两者的主要区别就是如何确定文件:通过文件名?还是通过file descriptor
- 返回的参数在一个statvfs结构体里面
struct statvfs { unsigned long f_bsize; /* File-system block size (in bytes) */ unsigned long f_frsize; /* Fundamental file-system block size (in bytes) */ fsblkcnt_t f_blocks; /* Total number of blocks in file system (in units of 'f_frsize') */ fsblkcnt_t f_bfree; /* Total number of free blocks */ fsblkcnt_t f_bavail; /* Number of free blocks available to unprivileged process */ fsfilcnt_t f_files; /* Total number of i-nodes */ fsfilcnt_t f_ffree; /* Total number of free i-nodes */ fsfilcnt_t f_favail; /* Number of i-nodes available to unprivileged process (set to 'f_ffree' on Linux) */ unsigned long f_fsid; /* File-system ID */ unsigned long f_flag; /* Mount flags */ unsigned long f_namemax; /* Maximum length of filenames on this file system */ };
Chapter 15: File Attributes
- TODO
Chapter 16: Extended Attributes
- TODO
Chapter 17: Access Control Lists
- TODO
Chapter 18: Directories And Links
- TODO
Chpater 19: Monitoring File Events
- TODO
Chapter 20: Signals: Fundamental Concepts
Concepts and overview
- 所谓的signal就是通知process有event发生了。
- 通知cpu有外部event发生的情况叫做hardware interrupt. signal由于其和hardware interrupt有异曲同工之妙(都是打扰了正常的程序执行), 所以signal也被叫做software interrupt.
- 一个process可以发送signal给另外一个process,也就是在process之间传递了信息,
既然这样我们可以把signal看做是:
- synchronizatoin technique
- primitive form of IPC (interprocess communication)
- 同时,一个process也可以发送signal给自己,但是其实最常见的情况是kernel发送signal
给普通的process。 kernel发送signal的情况主要有:
- kernel观察到了hardware exception.比如除以0, 访问了不能访问的内存地址。
- 用户输入了特殊的键盘组合。比如Ctrl+C, Ctrl+Z
- software envent,比如timer时间到了。process CPU时间用完了
- Signal有很多种类型,每种类型都被define了一个integer,其variable名字是SIGxxx 格式的。因为integer在不同的系统中是不一样的,所以我们只能依靠SIGxxxx
- Signal大体可以分成两类:
- traditional signal:从1到31,被kernel用来通知process有event发生
- realtime signal
- 既然signal是来通知process有event发生的,所以一个signal必定跟随着一个event:
- signal把event通知到process了,叫做delivered
- event发生和delivered之间叫做pending
- 有的时候,我们不希望被signal所打扰.这个时候,process可以mask out一些signal.方 法是把相应的signal的id添加到process自己的signal mask
- 当process received到signal的时候,一定要采取一些动作.根据signal类型的不同,可
能采取以下几种default动作(所谓default,就是说动作是由signal决定的):
- ignored: 有些signal直接就不能被process察觉
- killed: signal默认杀死process
- killed,并且产生core dump file: core dump file是process崩溃时刻的virtual memory image
- stopped: process进入suspended状态
- resumed: process得到signal又可以从suspended重新开始运行
- 当然了process也不是只能等待signal的"宰割", 其也是可以采取一些行动来应对signal
的default action的:
- 运行signal handler
- ignore signal: 是process发出"对策"ignore,并不是default行为就是ignore的signal 对于那种default行为是杀死process的signal, ignore的"对抗"很重要
- default action should occur: 如果signal的行为被process在之前改过,我们想reset 回signal的default behavior的时候,就可以用到这个.
- 所谓的signal handler,是program里面的一个函数,用来更改signal的default behavior.
Signal Types and Default Actions
- TODO
Chapter 21: Signals: Signal Handlers
Designing Signal Handlers
- 通常来说,signal handler要短小,这是因为短小的handler更可能避免race condtion,
为了达到这种效果,有两种常见的设计实践:
- signal handler设置了global flag后就马上退出了.然后由main函数每过一段时间 就去check这些flag,并继续处理
- signal handler做"一定程度上"的cleanup,然后要么"直接关闭这个process",要么 使用"全局goto":放弃一部分stack压榨的结果,到main以下的"原来定好"的一层stack 里面去处理.(细心的人会发现这其实就是exception)
Signals Are Not Queued(Revisited)
- 我们知道,当类型为signalA, S1的handler在执行的时候, 相同类型signalA的S2的来 临并不能被同时处理,而只能被标记为block,从而等待上次的处理完成后再进行处理.
- 同时我们知道,signal只有一个mask来表示是否block,没有数组来保存多次的signal 来临,也就是说,在S2被block的时候,再来一个signalA类型的S3只会被丢弃.
Reentrant and Async-Signal-Safe Functions
- 我们先来看看reentrant的概念:一个function如果能够在多个thread共同访问的情况
下,仍然能够保证其安全性,那么就说这个function是reentrant的
A function is said to be reentrant if it can safely be simultaneously executed by multile threads of execution in the same process.
- 这里所说的"安全性"其实就是"能够得到expected的结果"
- 虽然handler不是"明确调用"的thread.但是由于handler有可能在任何时刻中断main 函数当前的操作,而进行自己的handler(handler其实就是一个函数). 所以从这个特 点上来看. main函数和handler函数其实就是两个竞争的thread.
- 一个函数成为nonreentrant的原因主要有:
- 更改global 或者 static data structure. 比如malloc(), free()更改全局的free heap memory 链表.如果两个thread里面同时调用malloc()则有可能把链表搞坏
- 返回statically allocated memory.比如crypt(). 两个thread同时返回statically allocated memory.则内存地址可能被覆盖.
- 使用static data structure 作为内部的bookkeeping> 比如stdio library里面的 printf(), scanf().
- signal handler里面"不能"调用nonreentrant的函数!
- 换句话说,只要是reentrant的函数,都可以被signal handler调用,如果这个函数不是reentrant
函数,但是它不会被signal handler所interrupt,那么也可以被signal handler调用.
所以
async-signal-safe函数就包括1)reentrant函数和2)不会被signal handler 所interrupt的函数
Chapter 22: Signals: Advanced Features
Core Dump Files
- 某些signal可以使得process在terminate之前创建一个core dump 文件。
- 而这个core dump文件就是memory image of the terminated process(被关闭进程结束时候的内 存镜像)
- core dump还可以被load进debugger来模拟terminate时期的状态
- core文件生成需要的signal可以在程序运行的时候在命令行发送quit(Contrl+\)
- 首先,我们得确认系统允许我们创建corefile文件与否(因为core文件往往比较大,
默认是不允许创建core文件的,比如下例)
hfeng@hfeng-laptop:~/tmp/tt$ ulimit -c 0 hfeng@hfeng-laptop:~/tmp/tt$ ulimit -c 10000000 hfeng@hfeng-laptop:~/tmp/tt$ ulimit -c 10000000 hfeng@hfeng-laptop:~/tmp/tt$ sleep 30 ^\退出 (核心已转储) hfeng@hfeng-laptop:~/tmp/tt$ ls core
- core文件默认的名字就是core,可以在/proc/sys/kernel/core_pattern里面进行修改
Special Cases for Delivery, Disposition, and Handling
- SIGKILL的默认行为是terminate process,不可改变默认行为.
- SIGSTOP的默认行为是stop process, 不可改变默认行为.
- 而且上述两个signal也是不可以被block的,也就是说"任何时刻"都肯定可以使用这两个 signal来起到kill和stop的作用.
- SIGCONT是用来continue刚才被stop的process(除了不能被block的SIGSTOP,还有如下 的几个signal都可以起到stop process的目的:SIGTSTP,SIGTTIN, SIGTTOU).
- 和SIGKILL,SIGSTOP一样,SIGCONT是"任何时刻"都起作用的signal:
- 如果不是这样的话,有些process则永远无法被唤醒.
- 一个stopped的process被SIGCONT唤醒了以后.如果有其他pending的要stop它的signal 一概被忽略,否则如果一直有stop signal在stop期间pending,那么永远都continue不了.
Interruptible and Uninterruptible Process Sleep States
- 很多时候kernel会让process去sleep, 而sleep其实是分成两种状态的:
- TASK_INTERRUPTIBLE: process正在等待某个event发生.假设这个为eventA.如果这 时候由于eventB产生了signal的话. sleep的process是会被"伪唤醒"的:也就是wake up了以后马上处理eventB.由于不是自己要等待的那个eventA. 在handle了eventB之 后要马上再去sleep. 此状态在ps(1)下显示为S
- TASK_UNINTERRUPTIBLE: process在等待eventA发生,并且其会block"所有的signal"这 个所有"甚至包括SIGKILL(修正一下前面对SIGKILL过分肯定的描述)". 由于block了 所有其他的signal,这个process必须等到自己的eventA发生,handle了之后,才可能被 关闭. 此状态在ps(1)下显示为D.
- TASK_UNINTERRUPTIBLE是一个SIGKILL都无法"触及"的sleep状态,所以再使用的时候要很 小心,尽快缩短存在的时间.当然如果由于某种硬件问题(比如NFS挂了),那么这个process 就永远无法被kill掉了,只能重启解决问题.
- 为了解决只能靠重启来kill的, 硬件出错的TASK_UNINTERRUPTIBLE进程.Linux新发明了 第三个sleep状态,也就是TASK_KILLABLE:这个新的状态其实就是把TASK_INTERRUPTIBLE 的"屏蔽零"和TASK_UNINTERRUPTIBLE的"屏蔽所有",简化成了"屏蔽非fatal(比如SIGKILL)"
Chapter 23: Timers and Sleeping
Interval Timers
- 设置timer是一种process给自己"在未来的某个时间"发送signal的一种方式
- system call setitimer()是一个非常精细的发送"未来signal"的函数
#include <sys/time.h> int setitimer(int which, const struct itimerval *new_value, struct itimerval *old_value); /* Returns 0 on success, or –1 on error */
Chapter 24: Process Creation
Overview of fork(), exit(), wait() and execve()
- 这四个函数都是有变体的,但是主体功能差不多,分别是:
- fork() system call: 允许一个process(通常是parent process)来创建新的child process,其创建方式是:让新的process完全拷贝一下自己的parent.所谓fork其实就 是一个"分叉"成两个一样的.
- exit(status): 这并不是一个system call(_exit()是), 调用这个函数的进程自动 放弃自己的一切资源(内存, open file descriptors), 然后这些资源都还给kernel kernel可以分配给其他进程.status是退出的信息说明,如果有这个process的parent 在wait它,那么parent可以得到这个status
- wait(&status) system call: 如果调用wait()的process有child还没有通过调用 exit()结束, 那么wait()就会一直的suspend, 直到自己child里面有一个exit()的. 这个&status就是exit(status)的那个参数status
- execve(pathname, argv, envp) system call:
- 把pathname指向的program调入入内存的text segment,而当前已有的text被抛弃. 同时, 内存中data (both initialized and bss), heap, stack区域都重新根据 新的text segment来进行调整
- 内存中stack上面的argv和env list布局依靠从argv, envp中传入的参数进行重 新设定
- 有很多execve()的变体的library function(内部都是调用的execve()),它们统 称为exec(), 但是并没有一个system call叫做exec,这只是一个统称.
Creating a New Process: fork()
- fork()是process"克隆"一个完全一样的自己.新process只有很少的一些id不一样
#include <unistd.h> pid_t fork(void); /* In parent: returns process ID of child on success, or -1 on error; */ /* in successfully created child: always returns 0 */
- 理解fork()的关键在于意识到当fork完成的时候:
- 有两个process存在了
- 而且在每个process里面都从fork()完成的下一条语句继续运行
- 这两个process会使用同一份text segment(反正也是只读的可以共享), 但是会创建不 同的data(init&bss), heap, stack segments.
- 而这些segments里面的内容也是"完全"一致的.当然后面根据运行的不同,这些segment 里面内容就会马上不一致了.
- 这里就会涉及到一个Linux引入的叫做Copy-On-Write的技术.
- parent和child的内容是完全一致的,但是我们知道内容一致是可能发生的. 如果是 两普通的个process, 他们也有可能是所有segment内容一致,但是他们的"虚拟内存" 地址不一样,所以还是要映射到不同的物理地址,也就会在"两块不同的物理地址上存 储相同的一些内容"
- 前面描述的普通的两个process所有segment相同的情况,毕竟是少数.而fork则是最 经常发生的.每一次fork, parent和child的所有segment都一致.我们就会在想是不 是可以让他们的"虚拟内存地址"指向的物理地址也一样.这样一来,就可以减少一半的 物理内存使用, 这就是所谓的COW
- COW当然还有另外一半,那就是共享的这些物理内存,一旦有一个bytes被改动,那么意 味着parent和child已经完成了分家,这个时候,要重新分配物理内存让child的虚拟 内存地址来使用.
- COW说完了,再来讨论下COW的影响:共享物理内存的改动,可以是child改,也可以是parent
改.区别如下:
- parent改的话,那么parent一改,就要复制当前的segment信息,重新创建一份物理 内存给child. 而child很大可能性会调用exec(), 这样一来所有的复制出来的物 理内存就要再次被"刷入"新的内容.
- child改的话,很大可能就是马上调用exec(), 那么就不需要再把共享物理内存的 内容再拷贝一遍,然后再"刷入"新的内容.可以马上"刷入"新的内存,提高了COW的 效率.
- 所以在调度的时候, Linux scheduler更倾向于让child先运行.但是要记住这并不 是绝对的.parent也有可能先运行!
- fork()在不同的process里面返回不同:
- 返回-1表示没有创建process成功
- 返回newly created child process id表示当前的进程是parent
- 返回0,表示当前的进程是child
File Sharing Between Parent and Child
- 当fork()发生的时候, parent会使用dup()复制一遍自己所有的descriptor,然后给child 用. 前面我们讲过dup()之后产生的新的descriptor是和老的descriptor共享一个open file descriptor的.而open file descriptor里面包含了file offset和open file status flag. 这两个信息parent也会跟child进行共享.
- 跟child分享自己的open file descriptor的做法是有一定理由的.因为如果不告诉child 自己的offset在哪里, child可能从头开始写,一下子就把你的内容给overwrite了
- 分享open file descriptor的缺点是可能两者同时从一个地点写的话,可能会相互影响, 这个时候就需要synchronized以下. shell的做法是使用wait(),等待child退出以后 自己再来写入stdout等共有的file.
- 所以如果child不需要parent的open file descriptor,一定要明确的关闭,如下图.
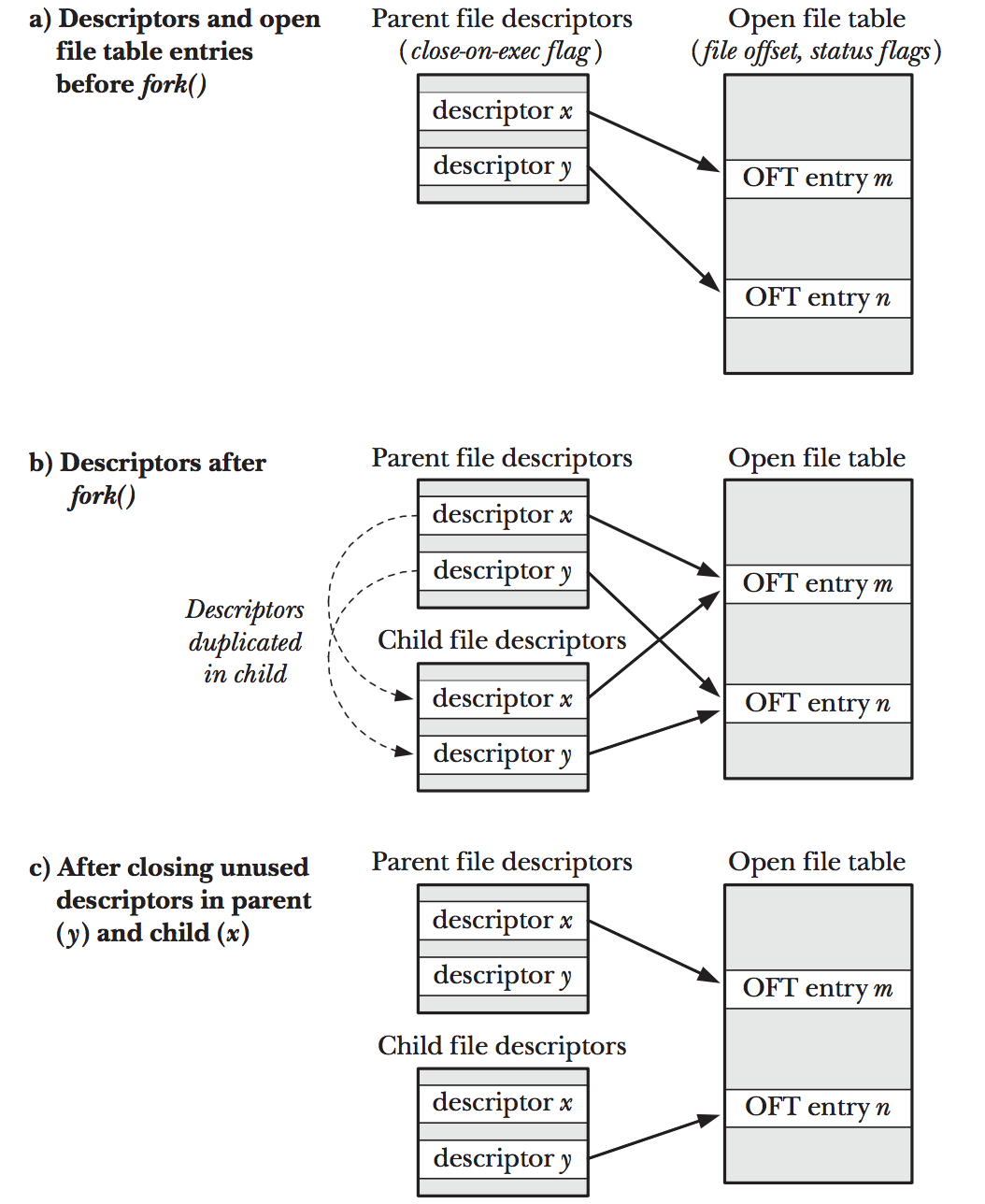
Figure 6: fork-descriptor.png
Memory Semantics of fork()
- parent和child的内存segment几乎一致这一特点催生了Unix-like两项节省内存的方法:
- kernel把text segment设置成read-only, 这样一来,fork()以后,kernel直接创建 新的child的page table entry, 然后把这些entry指向parent text segment的 page entries指向的,read-only的这些page frame
- copy-on-write技术,其实也是和text segment一样,把其他几个segment的page frame
都利用起来(被child的page entries指向),只不过,这些segment不是read-only的,
所以有任何一方写入,都会导致重新创建新的page frame.
Figure 7: copy-on-write.png
The vfork() system call
- 原来的BSD系统没有COW技术,所以fork()后在child里面紧接着执行exec()的情况下,效
率比较差.所以BSD设计了一种叫做vfork()的system call来提升fork()的效率, 在vfork
使用的情况下:
- child不会创建新的page或者page table,而是直接的和parent共享内存空间,直到child 调用了exec(),或者_exit()直接退出
- 在vfork()返回之后, parent一直是suspend的状态,直到child调用了exec()或者_exit (也就是说scheduler肯定会先让child运行)
- vfork()的奇特逻辑会导致如下问题:
- 如果在child的fork()和exec()之间改动了内存,那么当parent的fork()可以return 的时候,也会看到这些改动.这是非常危险的.
- child总是会先被调度
- vfork()已经被标记为obsolete,不应该再使用.
Race condition after fork()
- fork()之后, child或者parent谁先运行是一个"不确定的"问题,如果assume某一个先 运行,然后据此写逻辑的话,会造成race condition
- 前面已经讲了为了提高COW的效率,而让child先运行的理论.而最新的研究表示, parent
先运行,也有助于提高效率,因为
After a fork(), the parent’s state is already active in the CPU and its memory-management information is already cached in the hardware memory management unit’s translation look-aside buffer (TLB).
Avoiding Race Conditions by Synchronizing with Signals
- fork() 结束的时候,通常来说都是parent要wait child完成(但是其实也可以反过来:child
来等待parent完成).无论怎样:
- wait的一方其实是处于等待signal的状态,suspend当前的process.
- active的一方会在自己任务都完成后,发送signal给wait的一方.
Chapter 25: Process Termination
Terminating a Process: _exit() and exit()
- 一个process可以有两种terminate的方式:
- abnormal termination: 收到了一个signal,而且这个signal的defualt action是terminate 当前process
- normal termination:使用_exit() system call来达到的termination
#include <unistd.h> void _exit(int status);
- _exit()函数的参数status是会通过signal发送给parent的(如果parent调用了wait的话) 一般来说status为0表示child顺利完成了自己的任务正常退出
- _exit()是一个system call,而程序更经常使用的是library function exit()
#include <stdlib.h> void exit(int status);
- exit()是对_exit的包裹,其主要的工作是:
- 退出handers
- stdio stream buffer被清空
- 调用_exit() system call
- main函数里面return n的效果和exit(n)的效果是一样的
- 如果main函数没有在最后return:
- C89会返回任意值
- C99会返回exit(0)
Details of Process Termination
- 不管是normal还是abnormal的process termination,都需要执行下面的步骤:
- 关闭1.open file descriptor, 2.directory stream, 3.message catalog descriptors 还有4.conversion descriptors
- 所有的file lock都会被release
- System V shared memory segment都会被detach
- 如果关闭的是terminal的controlling process. 那么就会发送SIGHUP signal给所有 的foreground process
- 所有的open的POSIX named semaphore都关闭
- 所有的memory lock都relase
- 所有使用mmap()建立的memory mapping都unmap
Exit handlers
- 所谓的exit handler就是:
- 要在正常运行的时候进行注册handler
- 在normal exit(也就是调用exit()函数)的时候就会运行这个handler
- 调用_exit()或者被signal关闭的process不会调用exit handler
Interactions Between fork(), stdio Buffers, and _exit()
- TODO
Chapter 26: Monitoring Child Processes
Waiting on a Child Process
- 很多时候,parent process都会等待child process结束,从而记录child"何时",以及"为 什么"结束.
- parent process使用wait()来达到这个目的
#include <sys/wait.h> pid_t wait(int *status); /* Returns process ID of terminated child, or -1 on error */
- wait() system call做了如下的工作:
- 如果没有一个child process结束,那么wait()就会一直block, 直到有一个process 结束. 如果在wait()调用之前以及有child结束了,那么wait()就会立马返回
- status是表示child 如何terminate的信息
- wait()会返回结束的child的PID
- wait()不是那么的方便,接口更加实用的是waitpid
#include <sys/wait.h> pid_t waitpid(pid_t pid, int *status, int options); /* Returns process ID of child, 0, or -1 on error */
- waitpid是依靠id的不同来决定不同的使用方法
Orphans and Zombies
- parent和child的lifetime是不同的:
- 如果parent在child结束之前就结束了.那么child的parent就变成了init
- 如果child在parent调用wait之前就结束了.那么这个child就会变成zombie进程.因为 zombie进程还是会占用一点点的资源(child process ID, termination status, resource usage statistics), 其他的资源都可以被其他process所使用了.
Chapter 27: Program Execution
Executing a New Program: execve()
- execve() system call 会把一个新的program load到当前process的memory里面.在这 个operation过程中, 老的program被丢弃. process的stack, data, heap segment都 会被替换.
- fork()返回到child process之后,通常都会调用execve()来运行一个新的program
#include <unistd.h> int evecve(const char *pathname, char *const argv[], char *const envp[]); /* Never returns on success; returns -1 on error */
Chapter 28: Process Creation and program execution in more detail
- TODO
Chapter 29: Threads: Introduction
Overview
- thread和process有一个"共同的初衷":两者都是希望"同时运行"多个task
- thread是存在于process内部的一个概念, thread其实是program里面相互独立运行的 不同部分
- 一个program里面的不同的thread会share global memory的如下部分包括:
- initialized data segment
- uninitialized data segment
- heap segment
- 我们可以发现thread唯一不share的segment就是stack segment啦,其实是每一个thread
都有一个自己的stack(如下图, 需要说明的是pre-thread stack的具体位置可能根据
不同的Linux发行版而有所不同)
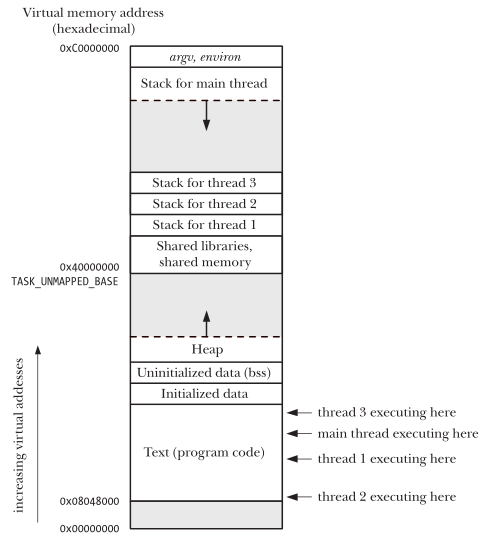
Figure 8: thread-memory-layout.png
- multi-thread相比于multi-process肯定是有其优点的,我们先来看一个multi-process
的例子: 有一个network server为了能够处理多个client发送来的请求.在每个client
来的时候都单独fork一个child process来"应付"新的client.这样做肯定是可以的,但
是这种multi-process有如下的局限性:
- 各个process的之间share information非常困难.必须使用interprocess communication
- 使用fork()来创建process是非常耗费资源的.
- 而multi-thread比较完美的解决了这个问题:
- thread之间因为共享了大部分的内存空间(除了stack), 所以share information变得 很容易.但是为了防止多个thread竞争资源的情况出现,我们必须使用"同步手段"
- thread creation相比于fork来说速度快了有十倍.(在linux上面 thread的创建其实 是只有clone()步骤,而没有fork()步骤. clone()步骤之后,大部分的内存空间都共享 了,所以明显比fork()后再遇到写入然后创建新的page table要快)
- 除了内存映射, thread之间还分享了如下的attribute:
- processID and parent processID
- process group ID and session ID
- controlling terminal
- process credentials
- open file descriptors
- record locsk created using fcntl()
- signal dispositions
- file system
- interval timers
- System V semaphore undo values
- resource limts
- CPU time consumed
- resources consumed
- nice value
- 当然了一个process里面的thread之间还是有如下的不同:
- threadID
- signal mask
- thread-specific data
- alternate signal stack
- the errno variable
- floating-point environment
- realtime scheduling policy and priority
- CPU affinity
- capabilities
- stack
Background Detail of the Pthreads API
- 在1980年代, thread的库有很多, 在1995年的时候,thread的行业标准POSIX诞生了.
- 在traditional 的UNIX API中, errno是一个global integer variable,
- 也就是说errno在initialized segment,是被不同的thread所共享的. 一个thread调用 function call得到的errno可能会迷惑"也能看到这个值的其他thread"
- 所以POSIX做了非常精细的设计:
- 一方面保证了traditional Unix代码的兼容性(依然使用errno作为全局变量)
- 另一方面,在用户使用thread的情况下(引入了errno.h), 通过把errno重新定义为 macro的方式,让errno变成一个threadLocal的变量(脑补java里面的threadLocal定义)
- 传统的system call在被调用的时候,返回0表示成功, -1表示失败.而错误原因在errno 里面.
- 在POSIX里面,无法做到把错误写入到errno里面(因为errno在errno.h里面被定义成了 threaLocal的变量,所以只有每个thread自己才能设置,函数调用的时候,只能设置global 的内存区域). 所以POSIX的函数调用,都是返回0表示成功.返回一个非零的正整数表示 错误,而在出错的时候,把这个正整数写入到自己的errno里面.就达到了和traditional function call失败时候一样的效果.
- 在Linux上面使用Pthread程序在编译的时候要使用cc -pthread option.其效果有两点:
- _REENTRANT preprocessor macro会被定义, 这会让一些reentrant function显示出 来
- 程序会和libpthread库一起编译(和-lpthread效果一样)
Thread Creation
- 当一个program开始运行的时候,最开始总是最少有一个thread叫做main thread(或者
initial thread).而创建额外的thread则需要如下的函数
include <pthread.h> int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start)(void *), void *arg); /* Returns 0 on success, or a positive error number on error */
- 下面来看看这个函数的几个参数:
- 新的thread是运行“一小部分的program”,就是由`start`所指定的function所在的
区域.这个`start`函数是一个返回值为void*的函数. void*是一种神奇的类型,可以
通过类型转换来变成最常见的类型,比如int
int j == (int)((void*)k)
- 新的thread运行所需要的参数写在`arg`里面. 一般来说arg指向global或者heap 变 量,当然也可以为空.arg的类型,也是上面说的"全能类型"void*
- `thread`指向一个类型为pthread_t的结构体, 这个结构体里面存储着唯一标示thread 的信息.会在pthread_crate()返回前拷贝完毕.
- `attr`指向一个类型为pthread_attr_t的结构体.如果`attr`为NULL,那么thread就会 安装很多默认属性创建.
- 新的thread是运行“一小部分的program”,就是由`start`所指定的function所在的
区域.这个`start`函数是一个返回值为void*的函数. void*是一种神奇的类型,可以
通过类型转换来变成最常见的类型,比如int
- 需要说明的是,pthread_create()调用完之后,是无法判断哪一个thread先被调用的.
Thread Termination
- thread 结束的方式有如下:
- thread的start function自己调用了return,换句话说就是thread自己觉得自己的使 命完成了,自动选择了退出
- thread调用pthread_exit()退出.其作用和start function调用return一样,但是调用 pthread_exit()又有其特点因为pthread_exit()可以隐藏在start function调用的 其他函数里面.
- 可以使用pthread_cancle()来结束线程
- 任意一个thread(包括main thread)调用exit都会结束process,同样也会结束属于这 个process的所有的thread.main函数调用return也是一样的效果.所以如果想让main 函数结束后其他thread还继续运行,那么main thread里面需要调用pthread_exit()而 不是exit()或者return.
- 我们来看下pthread_exit的函数定义
#include <pthread.h> void pthread_exit(void *retval);
- retval里面装的是thread的返回值, 这个指针不能指向一个thread stack内存地址,因 为thread返回以后,这个地址就不存在了.
Thread Ids
- 在process内部,不同的thread依靠threadId来进行区分.pthread_create()返回的第一
个参数`thread`里面就有thread_id但是有时候thread会在pthread_create()返回之前
就开始运行,这种情况下,使用如下的pthread_self()来获取thread自己的id
#include <pthread.h> pthread_t pthread_self(void); /* Returns the thread ID of the calling thread */
- 如果我们想比较两个thread_id是否相同,也不能使用`==`因为thread_t并不一定是long
很多系统是使用的pointer来实现thread_t的,所以就有了thread_id比较函数
#include <pthread.h> int pthread_equal(pthread_t t1, pthread_t t2); /* Returns nonzero value if t1 and t2 are equal, otherwise 0 */
- 虽然Linux系统上面的thread是整个系统唯一的,但是在其他Unix系统上面thread id只 能保证在process内部唯一.
Joining with a Terminated Thread
- pthread_join()函数的作用是等待`thread`指定的thread结束并使用`retval`来记录
返回值.
#incude <pthread.h> int pthread_join(pthread_t thread, void **retval); /* Returns 0 on success, or a positive error number on error */
- 如果`thread`指定的thread已经结束了,那么pthread_join会马上返回
- 如果`thread`指定的thread已经之前被join过了,再次join的结果未知
- pthread_join是和parent process wait有相似的功能,如果一个thread结束了,但是没
有join,就会变成zombie thread(在linux里面process和thread是使用相同数据结构)
从而老是占据某些资源.但是pthread_join其实和wait() system有两个显著的区别:
- process有parent和child之分,只能是parent wait child.但是thread没有parent和 child的区别. 一个threadA创建了threadB,但是threadB也可以join threadA
- process parent可以wait"任意一个child"(通过waitpid(-1, &status, option),但 是thread不能.(因为thread是平等的, join'任意一个thread',可能会join一个library function创建的thread)
Detaching a Thread
- 有时候,我们不关心thread的返回值,那么就希望系统自动清理这个thread(在thread完
成工作以后),而不需要我们再去join.那么这个时候,可以detach这个thread
#include <pthread.h> int pthread_detach(pthread_t thread); /* Returns 0 on success, or a positive error number on error */
Thread Attributes
- 前面我们的pthread_create()里面有个参数`attr`(类型为pthread_attr_t), 其可以
用来标示创建thread所需要的属性参数. 这个信息比较复杂,简单列一下其中的内容有:
- thread stack的地址和大小
- thread的scheduling policy
- thread的priority
- thread是否joinable或者detached
Threads Versus Processes
- multi-thread 方案的优点是:
- thread间的数据分享特别的容易
- thread的创建非常简单.切换也快速
- multi-thread方案的缺点如下:
- 我们要保证我们thread里面调用的函数是thread-safe的(或者in a thread-safe manner)
- 一个thread里面的bug可以摧毁所有本process其他的threads, 因为process的thread 分享地址空间
- 多个thread是会竞争virtual memory的,而多个process每人都有一个地址空间.
- multi-thread方案还有很多注意事项:
- 不要在多线程环境下使用signal
- thread还会分享file descriptor, current working directory等其他资源.这即可 能是优势,又可能是劣势.
Chapter 30: Threads: Thread Synchronization
Protecting Accesses to Shared
- thread的一个重要特性就是可以通过"global variable"来在不同的thread之间分享数
据.但是简单的分享是有代价的:
我们必须让不同的thread不要在同一时间修改同一个变量(或者一个修改, 其他读取) - 术语critical section是用来表示一段代码.这段代码访问了多个thread共同拥有的 shared resource,然后我们必须保证这段代码的执行是atomic的:也就是说critical setction的执行不能被其他thread(也能访问这些shared resource的线程)所中断.
- 创建critical section的方法是mutex(注意,只有lock了mutexA的threadB,才能release
这个mutex):
- 在访问shared resource之前locak the mutex for the shared resources
- 访问shared resource
- 在使用shared resource之后, unlock the mutex
Statically Allocated Mutexes
- mutex可以使用静态或者动态的方法来创建. 静态创建的方法如下. 刚刚创建好的mutex
是处于unlocked状态的
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
Locking and Unlocking a Mutex
- unlock和unlock的函数如下
#include <pthread.h> int pthread_mutex_lock(pthread_mutex_t *mutex); int pthread_mutex_unlock(pthread_mutex_t *mutex); /* Both return 0 n success, or a positive error number on error */
- lock一个mutex的时候:
- 如果mutex是处于unlock的状态,那么lock成功,并且快速返回
- 如果mutex是处于被其他thread lock的状态,那么pthread_mutex_lock函数会block, 一直到它能够拿到这个mutex
- 如果mutex是处于被自己thread lock的状态(之前lock过一次),那么thread就会deadlock
- unlock一个mutex的时候:
- 如果mutex是自己的原来lock的,那么正确返回
- 如果mutex是其他thread lock的,那么就会发生错误
- 如果mutex是unlock的状态的,再去unlock,也是会发生错误.
- 多个thread都等待某一个thread释放mutex,那么,谁能得到这个mutex是indeterminate的
- 除了pthread_mutex_lock,POSIX还提供了两种默认行为不是block的lock:
- pthread_mutex_trylock: 如果获取mutex失败,那么就马上返回. error设置为EBUSY
- pthread_mutex_timedlock: 如果获取mutex失败,那么就sleep一段时间,醒来还是没 acquire mutex就直接返回.error设置为ETIMEDOUT
Performance of Mutexes
- 在大多数应用中,mutex所带来的performace影响并不大
Mutex Deadlocks
- 在多个thread都需要多个mutex来工作的时候,竞争可能会导致deadlock的情况,如下:
Thread A Thread B pthread_mutex_lock(mutex1) pthread_mutex_lock(mutex2) pthread_mutex_lock(mutex2) pthraad_mutex_lock(mutex1) - 解决的方法有两种:
- 最常见的就是mutex hierarchy啦,就是所有的thread都必须使用同一个"顺序"来访 问mutex
- 不太常见的做法是第一个lock使用pthread_mutex_lock,后面的lock都使用 pthread_mutex_trylock, 这样不会大家都block住,得不到mutex就直接返回了.
Dynamically Initializing a Mutex
- 除了静态创建mutex的方法,我们还有动态创建mutex的方法
#include <pthread.h> int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr); /* Returns 0 on success, or a positive error number on error */
- 必须使用动态方法来创建mutex的情况有:
- mutex不是一个全局的static variable,而是一个automatic variable,也就是存在 于stack上
- mutex不是一个全局的static variable,而是在heap上面的variable.
- mutex不希望使用默认的属性,希望通过`attr`变量来增加些特殊性
- 使用动态方法创建mutex有灵活性,也有缺点,就是必须要手动清除(注意!即便是在stack
上的mutex也要手动清除,还要再其stack没有被清除的情况下, heap上的必然是在free
之前清除mutex啦)
#include <pthread.h> int pthread_mutex_destroy(pthread_mutex_t *mutex); /* Returns 0 on success, or a positive error number on error */
Mutex Attributes
- `attr`可以指定dynamically创建的mutex的属性,其中最重要的属性就是type
Mutex Types
- mutex的type主要用来决断如下的三种情况:
- 一个thread lock了同一个mutex两次,会怎么样
- 一个thread unlock了一个不属于自己的mutex会怎样
- 一个thread unlock了一个根本不是lock状态的mutex会怎样
- mutex的类型有:
- PTHEREAD_MUTEX_NORMAL:
- lock一个mutex两次会永远block在哪里(因为自己也没法unlock,所以叫永远block 也就是deadlock)
- unlock一个不属于自己的mutex的结果未知(Linux上面会成功)
- unlock一个根本不lock的mutex的结果未知(Linux上面会成功)
- PTHREAD_MUTEX_ERRORCHECK: 上面三种情况全部返回错误,这种类型的速度较慢,但 是调试方便
- PTHREAD_MUTEX_RECURSIVE:
- lock一个mutex两次会成功,但是会计数在一个lock count变量里面, unlock一次 会减小这个计数. 真正的release是这个lock count变成0的时候
- unlock一个不属于自己的mutex会失败返回错误
- unlock一个根本不lock的mutex会失败返回错误
- PTHEREAD_MUTEX_NORMAL:
Signaling Changes of State: Condition Variables
- mutex起到的是"锁"的作用:防止多个thread同时改动同一个shared variable
- 而condition variable起到的是"通知"的作用:通知其他threads,某个shared variable 已经的change of state.
- 为了说明condition variable的作用,我们首先来看一个没有使用condition variable
的例子: consumer-producer example:
- 我们首先有很多的thread来produce一些东西(例子中是avail)
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; static int avail = 0; /* Code to produce a unit ommitted */ s = pthread_mutex_lock(&mtx); if (s != 0) { errExitEN(s, "pthread_mutex_lock"); } avail++; s = pthread_mutex_unlock(&mtx); if (s != 0) { errExitEN(s, "pthread_mutex_unlock"); }
- 然后我们会由一个consumer(比如是main thread)来消耗avail个"产品"
for (;;) { s = pthread_mutex_lock(&mtx); if (s != 0) { errExitEN(s, "pthread_mutex_lock"); } while (avail > 0) { /* Do somethign with produced unit */ avail--; } s = pthread_mutex_unlock(&mtx); if (s != 0) { errExitEn(s, "pthread_mutex_unlock"); } }
- 我们首先有很多的thread来produce一些东西(例子中是avail)
- 上面的例子可以工作,但是却非常的耗费CPU time.因为main thread总是不停的在check avail的值. condition variable就是为了避免这种"busy waiting"的消耗cpu的行为 而设计的.
- condition variable可以让原来需要busy waiting的thread进行sleep,当这个thread 需要的条件满足的时候,再去唤醒这个thread
- condition variable经常和mutex一起合作来完成很多的工作.
Statically Allocated Condition Variables
- 和mutex一样, condition variable也是可以"动态"或者"静态"的创建,"静态"创建的
方法比较简单
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
Signaling and Waiting on Condition Variables
- condition variable的操作简单的说起来(细节需要后面补充)是两个:
- signal: 这个signal和前面讨论的'信号"没有关系,只是一个简单的通知的意思,就 是通知一个或者多个waiting "特定condition variable"的thead.
- wait: 开始等待某个"特定的condition variable"
- 我们先来看看比较简单的signal,有两个函数分别是:
- 通知所有等待`cond`的threads;
#include <pthread.h> int pthread_cond_broadcast(pthread_cond_t *cond); /* Return 0 on success, or a positive error number on error */
- 另外一个是通知所有等待`cond`的threads中的一个.
#include <pthread.h> int pthread_cond_signal(pthread_cond_t *cond); /* Return 0 on success, or a positive error number on error */
- 通知所有等待`cond`的threads;
- 这两个等待各有特点:
- pthread_cond_broadcat在大多数情况下是首选,因为它肯定是正确的(因为所有thread 都通知到了么)
- pthread_cond_signal在某些特定的情况下效率更高.比如被通知的这些个thread只
需要有一个被唤醒工作就可以了(这很有可能,比如多个等待的thread其实是做相同
工作的,所以有一个起来就可以了). 这种情况下的pthread_cond_signal还能避免
下面的这种麻烦:
- 所有的thread(做同样工作的)都背唤醒了
- 其中一个thread得到了mutex,然后开始做工作,做完以后把锁release了
- 其他的thread也会得到了mutex,然后还会白白检查一遍,却发现自己什么都不需要做.
- wait操作的函数如下
#include <pthread.h> int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
- wait操作还和mutex有联系,原理不好解释,还是需要一个例子:
- 首先需要创建mutex和condition variable
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; static pthread_cond_t cond = PTHREAD_COND_INITIALIZER; static int avail = 0;
- 生产者是负责生产的,而且会把"产品"已经有了这条信息发送给所有等待`cond`的
其他thread,也就是消费者. (注意这里是先unlock mtx,然后signal,这样效率高于
先signal,然后unlock mtx)
s = pthread_mutex_lock(&mtx); if (s != 0) { errExitEn(s, "pthread_mutex_lock"); } avail++; s = pthread_mutex_unlock(&mtx); if (s != 0) { errExitEn(s, "pthread_mutex_unlock"); } /* Wake sleeping consumer */ s = pthread_cond_signal(&cond); if (s != 0) { errExitEn(s, "pthread_cond_signal"); }
- 下面就是消费者的代码.`cond`就是在这里被"等待"的.
for (;;) { s = pthread_mutex_lock(&mtx); /* Before wait something, obtain the mutex first */ if (s != 0) { errExitEN(s, "pthread_mutex_lock"); } while (avail == 0) { /* Wati for something to consume */ s = pthread_cond_wait(&cond, &mtx); if (s != 0) { errExitEN(s, "pthread_cond_wait"); } } while (avail > 0) { avail--; } s = pthread_mutex_unlock(&mtx); if (s != 0) { errExitEn(s, "pthread_mutex_unlock"); } }
- wait的参数还有mutex,同时我们也注意到wait是在lock了这个mutex以后,才调用了
wait函数.这是因为wait"自动"执行了如下的步骤(因为三个步骤是一个call完成的,
这样保证了不会被其他的thread所抢占):!!!IMPORTANT!!!
- unlock刚才获得的`mtx`
- block当前的thread,直到其他的thread通知当前的`cond`
- 在被唤醒的一瞬间再次lock`mtx`
- 首先需要创建mutex和condition variable
Testing a Condition Variable's Predicate
- 我们前面发现,在判断condition variable的值的时候,我们使用的是while而不是if
这是基于如下的几个原因:
- 其他thread可能会先wake up: 我们不能"假设"只有一个消费者,可能有多个消费者 的存在.如果是那样的话,可能其他消费者已经处理过了,当我们的wait返回的时候, 可能值又回到了0
- 这种使用while的做法可以得到和if一样的效果,但是又留有余地,适合多线程编程
- 可能会发生"假的wakeup(spurious wake-ups)".SUSv3允许这个情况出现,这种假的 wakeup很多时候是为了提高系统的效率
Dynamically Allocated Condition Variables
- 和mutex一样,我们也有dynamically allocated condition variable的方法,如下
#include <pthread.h> int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr); /* Returns 0 on success, or a positive error number on error */
- 复习一下需要dynamical方法的原因:
- 有些时候不能statically的创建condition variable. 还有stack和heap上的创建
- statically创建的时候,如果是原来的default方法,是没法带上attribute的
- 当然了dynammic创建的condition variable不再需要的时候,就只有destroy啦
#include <pthread.h> int pthread_cond_destroy(pthread_cond_t *cond); /* Returns 0 on success, or a positive error number on error */
*
Chapter 31: Threads: Thready Safety and Per-Thread Storage
Thread Safety(and Reentrancy Revisited)
- thread-safe的定义是:如果一个function可以被多个thread同时访问,却能正常工作, 那么我们就说这个function是一个thread-safe function.
- 而thread-不-safe的function则是被多个thread同时被使用就"可能"会出错的function,
看下例
static int glob = 0; sttic void incr(int loops) { int loc, j; for (j = 0; j < loops; j++) { loc = glob; loc++; glob = loc; } }
- 上例在多个thread同时调用的情况下, glob的值是unpredictable的.这也同时揭示了 thread-不-safe function的重要原因: 使用了被所有thread共享的global或者static variable
- 如果function必须要使用static或者global variable,那么:
- 一个显而易见的方法就是给function加mutex,当进入function的时候lock mutex,当 退出function的时候release mutex.这样做的坏处是如果threads大量的使用这些函 数,这些函数其实都是"线性"执行的,虽然获得了"安全性",但是失去了"并发性"
- 一个更加合理的做法:是减小mutex的作用域,原来是保护整个函数,现在,可以通过对 函数的分析,只保护函数中涉及到shared variable的部分(critical section),这样 一来只有在同时运行critical section的时候是"线性的"
- 为了支持多线程编程SUSv3里面大部分的函数都是thread-safe,只有下面一些不多的例外
asctime() getservbyport() nl_langinfo() basename() getservent() ptsname() catgets() getutxent() putc_unlocked() crypt() getutxid() putchar_unlocked() ctime() getutxline() putenv() dbm_clearerr() gmtime() pututxline() dbm_close() hcreate() rand() dbm_delete() hdestroy() readdir() dbm_error() hsearch() setenv() dbm_fetch() inet_ntoa() setgrent() dbm_firstkey() l64a() setkey() dbm_nextkey() lgamma() setpwent() dbm_open() lgammaf() setutxent() dbm_store() lgammal() strerror() dirname() localeconv() strsignal() dlerror() localtime() strtok() drand48() lrand48() system() encrypt() mblen() ttyname() endgrent() mbtowc() unsetenv() endpwent() mrand48() wctomb() endutxent() nftw()
- 因为有mutex的帮助,所以其实只要我们不怕麻烦,绝大多数的函数都可以做到"thread-safe" 但我们知道,thread-safe最少也是以lock critical section为代价的.
- 有时候这个代价也太大,我们不想要. 不想使用mutex而达到thread-safe的方法也是有 的,就是"不使用global或者static的变量". 通过这种方式来达到thread-safe的函数 叫做reentrant function
- reentrant function不使用任何的global或者static变量,所以返回值通常是让caller 自己申请好,然后把指针传入到函数参数里面
- 虽然reentrant function不使用global或者static变量的做法即"经济又安全",但是还
是有很多情况下,你无法将函数做成reentrant:
- malloc系列函数,必须访问global linked list of free blocks on the heap
- 还有一些"历史遗留"的函数,他们设计的时候,还没考虑那么多,直接就会使用一块static 的内存来返回值(下一次再调用这个函数,这个值又被改写了). 比如asctime()
- 对于第一种情况,malloc的实现设计到过多的细节,无法快速的改变其实现,让其变成reentrant 函数,但是对于第二种情况,只是因为"历史原因"选择了返回static variable,那么我们 可以再提供一个功能相同,但是用户可以"自己提供存储地址"的reentrant版本.比如 asctime_r(), 类似的还有ctime_r(), getgrgid_r(), getgrnam_r(), getlogin_r(), getpwnam_r(), getpwuid_r(), gmtime_r(), localtime_r(), rand_r(), readdir_r(), strerror_r(), strtok_r(), and ttyname_r().
- 最新版本里面的asctime()其实内部就是asctime_r()实现的.而代码还像我们展示了,
如何申请automatic variable,然后地址传入"收取"返回值
#define MAX_ASCTIME_LENGTH 26 char * asctime_r (const struct tm * tm, char * buf) { if (0 == strftime(buf, MAX_ASCTIME_LENGTH, "%a %b %e %H:%M:%S %Y\n", tm)) { return NULL; } return buf; } char * asctime (const struct tm * tm) { static char buffer[MAX_ASCTIME_LENGTH]; return asctime_r(tm, buffer); }
One-Time Initialization
- 有时候多线程应用需要保证一些initialization只能发生一次,无论有多少个thread调 用过这些initialization过程.
- 比如多个thread可能都会调用一次mutex创建的过程,但是只能第一次起作用,否则mutex
会被调用多次.:
- 如果我们从main函数里面调用thread,那么我们可以先创建mutex,然后再创建thread. 因为mutex在thread创建之前就有了,那么多个thread就不必担心,直接使用mutex就可 以了
- 但是如果我们先创建了thread,然后thread里面的代码开始创建mutex,由于thread有
多个,那么很可能创建mutex的代码执行了多次.我们需要一种
某段代码执行多次,但是只有第一次有作用的机制: one-time initialization
- library function可能会被多个thread同时调用,library function为了保护自己的critical
section,都会在执行代码之前,先one-time initialization一下mutex.使用
#include <pthread.h> int pthread_once(pthread_once_t *once_control, void (*init)(void)); /* Returns 0 on success, or a positive error number on erro */
- pthread_once的参数:
- once_control是一个指向变量的指针,而且必须如下statically initialized
pthread_once_t once_var = PTHREAD_ONCE_INIT;
- init是一个指向函数的指针,这个函数是用来初始化的
void init(void) { /* Function body */ }
- once_control是一个指向变量的指针,而且必须如下statically initialized
- pthread_once()的存在其实是因为早期的mutex无法statically initialization.所以 必须使用pthread_once().由于后来statically initialization mutex的诞生.如今 one-time initialization的存在只是为了历史兼容性
Thread-Specific Data
- 最有效率的把函数改成thread-safe的办法,就是不使用global,static变量(也就是把 函数变成reentran).但是有些老的函数接口已经定了,如果一定要把它们改成reentrant 的函数,那么就会破坏已有的使用这些接口的代码
- 如果想1即保留接口不变2又能把函数变成reentrant,那么可以选择使用thread-specific data.
- thread-specific data说来也很简单:原来使用global, static的变量的话,所有的调用
都是使用一个共同的空间.下次再调用的时候,这个空间就被"重新写入过"了.而如果我
们能保证每个thread调用函数的时候,都能被分配一块自己的内存,那么后面的调用也
就不会写入前面的地址了.
+----------------+ +--------+ | TSD bufer for | |ThreadA |---------->| myfunc() in | +--------+ | ThreadA | +----------------+ +----------------+ +--------+ | TSD bufer for | |ThreadB |---------->| myfunc() in | +--------+ | ThreadB | +----------------+ +----------------+ +--------+ | TSD bufer for | |ThreadC |---------->| myfunc() in | +--------+ | ThreadC | +----------------+
Thread-Specific Data from the Library Function's Perspective
- 为了能够理解TSD(thread-specific data)的好处,我们需要从library function的角
度来理解一下:
- 每个function都必须为调用它的"每一个"thread都分配一块block of storage. 而 "每一个"thread只能在第一次访问这个函数的时候申请这个storage,第二次再调用 的时候,就不能再申请空间了,而应该用自己上次申请过的.
- thread第二次及以后调用这个function的时候,就需要知道,我第一次调用这个function 的时候,申请的这个地址是哪里.因为我不能再次申请了,我得知道第一次的地址.这 个地址library function不能放到automatic变量里面,因为自动变量在function第 一次返回的时候,就失效了. static variable也不好使,因为是整个process唯一的, 无法为thread-specific级别提供服务.所以,我们必须从操作系统层面得到支持,也 就是需要Pthread API来支持我们的工作
- 这些thread第一次访问所申请的空间,对于library function来说是完全无法控制 的, 只要thread还在,就不能释放这些storage,而thread什么时候结束是不会通知 library function的.所以我们还是需要一些机制来在thread结束的时候,一并回收 这些storage
Overview of the Thread-Specific Data API
- library function为了使用TSD(thread-specific data)还得经过如下复杂的步骤:
- 首先function需要一个key,这个key不是为了不同的thread之间相互区别的,而是 不同的library function之间相互区别的.通过pthread_key_create()来创立. 只有"第一个thread第一次"访问这个library function才会创建.所以还得依靠 pthread_once()的帮助,防止多次创建key
- 调用pthread_key_create()还有一个作用,就是:允许caller为这个key确定一个 destructor function. 然后每当一个thread结束的时候,如果这个thread里面 有这个key,就自动调用destructor function来释放这个thread的keyX的区域.
- 每当有新的thread第一次访问library function的时候,就要动真格的了.开始使用 malloc等函数来创建thread-specific内存空间
- 创建的内存空间的地址,是不依靠变量存储的(原因前面说过). 操作系统层面的支
持是两个函数:
- pthread_setspecific()在第一次创建以后,存储这个地址
- pthread_getspecific()在非第一次访问的时候,取用这个地址.
Details of the Thread-Specific Data API
- pthread_key_create() 用来创建thread-specific data key. 返回值存储在下面的
`key`里面类型为pthread_key_t
#include <pthread.h> int pthread_key_create(pthread_key_t *key, void (*destructor)(void *)); /* Returns 0 on success, or a positive error number on error */
- 这个key会被所有的thread所使用, 所以这个key必须指向一个global variable
- `destructor`指向的一个函数指针,其定义如下
void dest(void *value) { /* Release storage pointed by 'value' */ }
- 一个thread,它可能会调用很多的library function,每个library function都为它准 备了一个key,当这个thread结束的时候,如果这个key有non-NULL的data(那肯定是某个 library function为这个thread申请的data啦), 那么destructor就会自动调用去释放 这个data.
- TODO
Chapter 32: Threads: Thread Cancellation
- 一般来说,多个thread会一直运行,直到如下两种情况(这两者情况都是thread主动自愿
的):
- pthread_exit()
- return from thread's start function
- 有些情况下,thread也需要能够"被动"的被其他thread关闭
Canceling a Thread
- 当前thread可以调用如下命令来cancel id为`thread`的线程
#include <pthread.h> int pthread_cancel(pthread_t thread); /* Returns 0 on success, or a positive error number on error */
- pthread_cancel()是立刻返回的,也就是说,它不会等待target thread terminate以后 再返回.
Cancellation State and Type
- 当一个thread接受到别的thread发送的cancel请求的时候,如何应对.是依靠如下的两
个函数来确定的
#include <pthread.h> int pthread_setcancelstate(int state, int *oldstate); int pthread_setcanceltype(int type, int *oldtype); /* Both return 0 on success, or a positive error number on error */
- pthread_setcancelstate是用来设置当前thread应对其他thread cancel时候,是否主
动放弃自己的运行(也就是state):
- PTHREAD_CANCEL_ENABLE: 默认设置,其他thread一旦要求自己cancel,那么就cancel
- PTHREAD_CANCEL_DISABLE: 即便其他thread要求自己的cancel,也不为所动,保持pending 状态.
- `oldstate`返回的是老的状态.
- 有些时候,将thread临时性的设置为PTHREAD_CANCEL_DISABLE是非常重要的.比如thread 正在执行一个"必须完成的step"
Chapter 33: Threads: Further Details
Thread Stacks
- 当thread被创建的时候,其stack的size是固定的:
- 如果thread是main thread,那么空间非常大(无限接近3G,在32bit机器上面)
- 如果thread不是main thread,那么stack的大小一般是固定的.32bit机器上面是2MB
- 有些情况下我们会想改变thread的默认stack大小:
- 如果想在每个thread里面多申请几个automatic 变量或者函数多嵌套几次的话,就需 要增加stack的大小
- 如果想让机器多运行几个thread,那么在虚拟内存空间有限(比如32bit机器是3G的情 况下,如果不改小thread stack的默认大小2MB的话,最多只可以有1500个thread同时 运行)
Threads and Signals
- Unix signal系统是为process设计的,和thread的配合有点格格不入
- TODO
Chapter 34: Process groups, sessions, and job control
Overview
- A process group是一类process的集合,这些process属于一个group的标志,是它们 共享一个相同的process group identifier(PGID)
- 每一个process group都有一个process group leader, 这个process group是由这个 leader创建的。process group的ID也就使用leader的process id。
- process group也有其lifetime,它的lifetime的定义为:
- 开始: leader创建这个group, 作为开始
- 结束: group里面所有的process都离开,作为结束(process离开group的定义是: 要么加入其他group,要么terminate)
- session又是一系列process group的集合。session也有自己的ID,其值也是创建这个 session的process的ID。
- session里面的process 共享同一个controlling terminal.而且一个controlling terminal 能且只能服务于一个session。
- 一个controlling terminal所控制的session里面,有多个process group,而这些process group里面有且只有一个是在“前台”的,叫做foreground process group. 而所有其他 的process group都是background process group.
- 只有foreground process group才能读取controlling terminal的input。而controlling
terminal的一些特殊input(如下)会产生不同的signal,然后这个signal会发送给foreground
process group里面所有的process发送这个signal:
- Control + C : SIGINT
- Control + \ : SIGQUIT
- Control + Z : SIGTSTP
- 我们举一个例子来说明上面的问题
$ echo $$ # Display the PID of the shell 400 $ find / 2> /dev/null | wc -l & # Create 2 process in background group [1] 659 $ sort < longlist | uniq -c # Create 2 processes in foreground group
- 这个例子可以说明的问题有:
- session 的id是session leader group的group id,为400
- session 的 session leadergroup 的id, 是这个process group的leader process 的pid为,也就是PID为400的bash
- session中第二个process group是find 和 wc,其中find是process group leader 其PID658作为这个process group的GID
- session中第三个process group是sort 和 uniq,其中sort是process group leader 其PID660作为这个process group的GID
- 这些process分成了两种,都被controlling terminal所控制:
- foreground: sort, uniq
- background: bash, find, wc
- 下图就是上面例子的解释
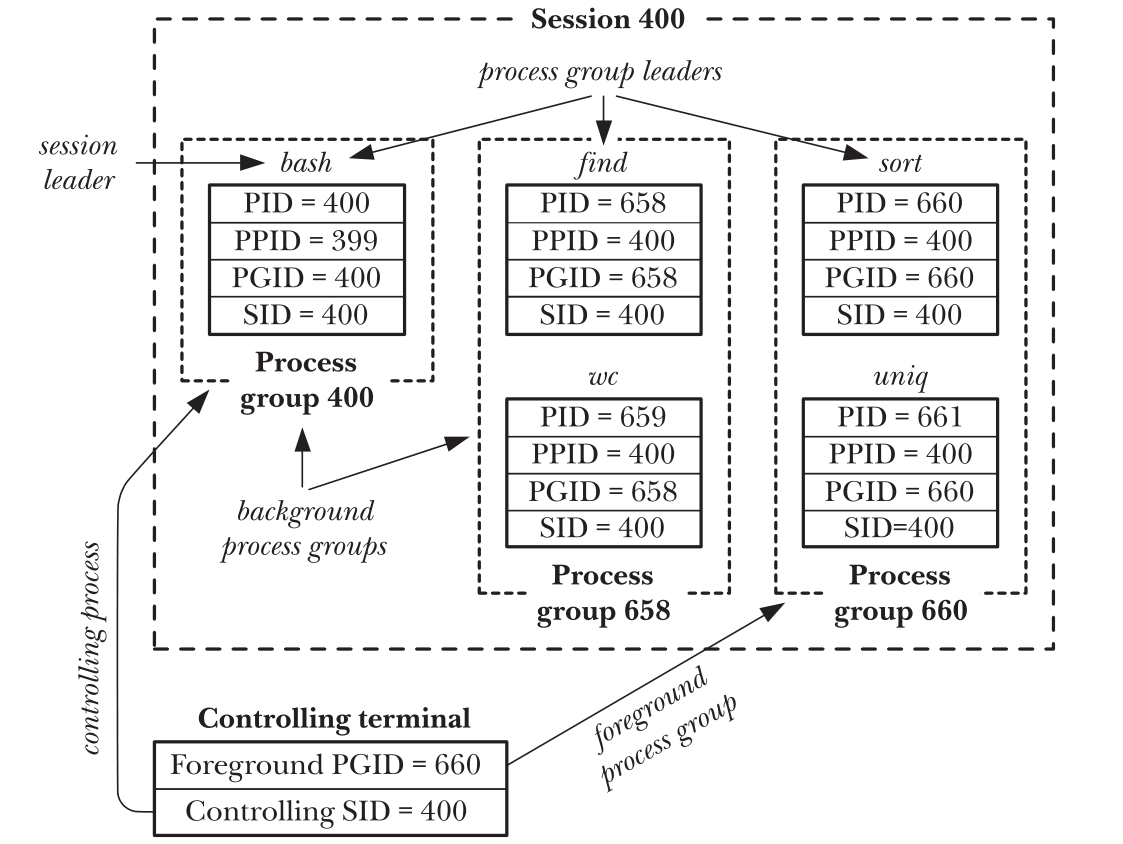
Figure 9: process-groups
- session 的id是session leader group的group id,为400
Chapter 35: Process priorities and scheduling
Process Priorities (Nice Values)
- Linux默认的调度策略是Round-robin,这个策略的优点是:
- 公平性:每个process都有机会使用CPU
- 响应性:每个process不需要等待太久
- round-robin策略里面,如果每个process都想"尽可能"的使用cpu,那么最终大家分到的 资源基本是平均的.但是unix提供给了方法,让process去放弃自己一部分的资源,这个 函数就是nice(),意思就是nice to other processes
- TODO
Chapter 36: Process Resources
Process Resource Usage
- 函数getrusage() system call可以返回详细的资源使用情况.返回的是当前调用这个
system call的process使用的资源,或者是它所有的child使用的资源.
#include <sys/resource.h> int getrusage(int who, struct rusage *res_usage); /* Returns 0 on success, or –1 on error */
Process Resource Limits
- 每个process都有自己的资源使用限制.PID为<pid>的进程其limit会在/proc/<pid>/limits 里面找到.
- 可以通过下面两个API来设置这些limits
#include <sys/resource.h> int getrlimit(int resource, struct rlimit *rlim); int setrlimit(int resource, const struct rlimit *rlim); /* Both return 0 on success, or –1 on error */
Chapter 37: Daemons
Overview
- daemon是有如下特性的process:
- 它是long-lived的,一般来说daemon都是从机器启动就运行,然后直到机器关机才退出 的.
- 它是在后台运行的,而且"没有controlling terminal"(这一点决定了,我们加上'&'运
行的程序只是background process而不是daemon process).所以对于daemon来说,它
不会收到如下两类signal:
- job-control signal
- terminal-relative signal
- daemon的创造是为了实现一些特殊的task,比如:
- cron: 在特定的实现执行特定的command
- sshd: secure shell daemon, 允许用户从远程登录
- httpd:http server daemon,用来服务web页面
- inetd: Internet superserver daemon,会监听某些port上面的请求,并且服务于它.
- 一般来说,daemon的进程都是以d结尾.
- daemon是Unix的概念,而在Linux里面,有一些"既是daemon,又是kernel"的进程,叫做
kernel thread,它们的特点是:
- 在系统启动中同时被创建
- 在ps(1)里面显示的时候,名字被[]包围, 比如
vagrant@ elpa (master) $ ps -aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.1 37652 5756 ? Ss 11:11 0:01 /sbin/init root 2 0.0 0.0 0 0 ? S 11:11 0:00 [kthreadd] root 3 0.0 0.0 0 0 ? S 11:11 0:00 [ksoftirqd/0] root 4 0.0 0.0 0 0 ? R 11:11 0:02 [kworker/0:0] root 5 0.0 0.0 0 0 ? S< 11:11 0:00 [kworker/0:0H] root 6 0.0 0.0 0 0 ? S 11:11 0:00 [kworker/u4:0] root 7 0.0 0.0 0 0 ? S 11:11 0:01 [rcu_sched]
Chapter 38: Writing Secure privileged programs
- TODO
Chapter 39: Capabilities
- TODO
Chapter 40: Login Accounting
- TODO
Chapter 41: Funamentals of shared libraries
- shared library就是一种把library function放到一个unit里面,然后把这个unit在runtime 共享给多个process,这样一来既可以节省disk,也可以节省RAM.
- TODO
Chapter 42: Advanced features of shared libraries
- TODO
Chapter 43: Interprocess communication overview
Chapter 56: Sockets: Introduction
- Socket是IPC的一种,用来在application之间传递数据, 而这些不同的application可以 是在同一台机器上面,也可以是在不同的机器上面(但是必须在同一个network)
- 第一个版本的socker API是在1983发布的4.2BSD, 并且以后广泛的存在于各个版本的Unix 系统里面
Overview
- 常见的client-server系统中, 需要用到socket的场景如下:
- 每一个application都创建一个socket. socket是一种工具需要"沟通"双方都需要的 工具,所以每个application都需要一个socket
- server把自己的socket绑定到一个well-known port, 这样一来, client就可以通过 <IP>:<Port>
- socket的创建是通过socket() system call.这个system call会返回file descriptor
用来指代这个socket(一切皆文件)
fd = socket(domain, type, protocol);
- 我们逐一来看看这些参数:
- domain: 常见的domain有如下三种
Domain Communication preformed Communication between applications Address format Address Structure AF_UNIX within kernel on same host pathname sockaddr_un AF_INET via IPv4 on hosts connected via an IPv4 network 32-bit IPv4 + 16-bit port sockaddr_in AF_INET6 via IPv6 on hotts connected via an IPv6 network 128-bit IPv6+16-bit port sockaddr_in6 - type: 说的是socket type, 不同的domain都会提供如下两种socket type: Stream
和Datagram, 它俩的特点如下
Property Stream Datagram Reliable delivery? Y N Message boundaries preserved? N Y Connection-oriented? Y N - protocol一般都是0, 早期这个protocol是用来使用default protocol用的,但是现 在已经被废弃, 设置为0的意思就是不使用任何default protocol
- domain: 常见的domain有如下三种
- 这些参数里面,比较难以理解的是Stream这个概念, Stream socket(SOCK_STREAM) 提供
了reliable, bidirectional, byte-stream channel, 这些概念的意义如下:
- reliable:意味着要么,我们成功的把数据完整的传递给对方,要么,我传递的不完整的 话,我肯定知道,我要"警告对方"数据可能损坏
- bidirectional: 意味着数据都是双向传递的, client端有一个socket, server端有 另外一个socket, 这两个socket之间,无论哪个方向都是可以传递信息的(后面阅读有感)
- byte-stream: 就是没有message boundaries的概念
- 其实stream socket就像是network上的pipe(管道)传递
- stream socket总是在connected 的通道上活动,所以stream socket也叫做connection-oriented
- stream socket只能connect一个peer
- Datagram socket是让data以datagram(一种message)为载体进行传播的,所以datagram socket肯定是有message boundary的.
- message传播的特点不仅仅是以message为载体,还包括传输可能存在:
- out of order
- duplicated
- 根本没有传输到对方
- 和stream socket不一样的是, datagram socket都不需要建立connection之后才发送 它是一种connectionless socket
- socket领域的system call主要有:
- socket():创建new socket
- bind():bind一个socket到一个address,通常是server才需要这个步骤,因为server要 绑定一个well-known的 address,client才能找到. client就不需要一个特别著名的地址
- listen(): listen允许stream socket来接听incoming connection
- accept(): accept用来接受从peer application传来的connection请求, 必须首先是 一个listening socket,才能accept其他connection
- connect(): 就是client一端的socket,去拼命的联系server端的socket, 当然了,因 为"忙音"的存在,不一定能联系成功(后面阅读有感)
Creating a Socket: socket()
- 创建新的socket的system call
#include <sys/socket.h> int socket(int domain, int type, int protocol); /* Returns file descriptor on success, or -1 on error */
- 主要部分前面都介绍过了, 就是protocol比较特殊,其非0值不太常用
Binding a Socket to an Address: bind()
- 获得了新的socket之后,一般都要"配置"这个socket, 配置的第一步,就是把这个socket
"联系"上某个address. 通常这个动作也只有server会做, 因为server要做到地址为人
所知
#include <sys/socket.h> int bind(int sockfd, const struct sockaddr* addr, socklen_t addrlen); /* Returns 0 on success, or -1 on error */
- sockfd就是我们前面socket()后得到的fd
- addr是一个指向"well known地址的变量"的指针
- addrlen是这个"well known地址的变量"的长度
Generic Socket Address Structures: struct sockaddr
- 我们前面在socket()里面看到了,Linux上面存在不同的domain. 而不同的domain是使用 不同的address format的.比如, Unix domain socket就是使用pathname, Internet domain 就是使用IP加port
- bind()是system call,所以它要接受各种不同的address format. 为了让bind()可以
接受不同的address format, socket API定义了一个generic address structure,叫做
struct sockaddr, 其作用就是为了cast不同的address format
struct sockaddr { sa_family_t sa_family; char sa_data[4]; };
Stream Sockets
- stream socket的通信过程,是和telephone system非常相似的:
- socket() 是建立socket,这就和"安装电话"一样.为了让两个地方的人通信,两个地方 都必须安装电话. 为了让两个application通信,两个application也都必须create socket!!(这个是我第一次对socket有了正确的理解!!)
- 在真正的"打电话(传递数据)"之前,还是有一些工作要做:
- server端: 必须使用bind()把自己绑定在一个well-known 地址,然后listen()等待 新的connection来访问. 对比telephone就是为自己的电话申请一个well-known的 号码,比如123,然后还要把电话打开,这样其他电话才能打进来
- client端(首先也要socket()安装电话), 它在知道server端号码的情况下, 可以直接 拨打,也就是connect(), 然后就是等待接通啦
- server端的listen()在有其他incomming connection来临的情况下,会调用accept() 来接听connection,就好比我们听到电话响,就拿起电话和client对话. 注意,一旦 你接听了一个电话,另外其他像打进来的电话就是"忙音"了
- 一旦电话接通,那么就可以对话了,一旦两个socket建立了connection,那么就可以在 两个方向进行数据传输了.
- stream socket可以分成passive或者active两种:
- 使用connect()去主动联系其他socket的,叫做active open socket
- 使用listen()等待其他socket, 然后accept() block直到其他socket来临的socket叫做 passive open socket.
- 一般来说server是passive open, client是active open
Figure 10: socket-passive-active.png
Listening for Incoming Connections: listen()
- listen() system call 是把sockfd指向的socket变成passive的,然后这个socket后面
会被accept()调用来迎接incoming connection
#include <sys/socket.h> int listen(int sockfd, int backlog); /* Returns 0 on success, or -1 on error */
- 我们的listen只能调用"还没有connected"的socket, 如果这个socket已经和其他机 器上的别的socket建立过联系了,那么我们就不能再使用listen来把它变成passive了
- 这个函数有点诡异的地方在于参数backlog,这个参数的诞生是因为如下的场景:
- server在调用accept()之前,就已经收到client发过来的connect()了, 这是非常可
能的, 特别是在client有很多访问的时候:
- 从server端来看,accept()会block,直到有新的client访问,这是server"先准备 好"的情况
- 从client端来看,connect()会block,知道server忙完其他connection, 这是client 端"先准备好"的情况
- server端需要一个"缓冲取"来记录下"自己没有准备好"的情况下,进来的connection, 这个数目肯定是有上限的,我们不可能无限制的记录来不及处理的client connection 这个上限就是由backlog参数决定的.
- 当然了,操作系统也不是傻瓜,你把backlog设置成任何数它都认,它有一个最大的限度:
- 早期是5, immutable
- 后来到了128, immutable
- Linux 2.4.25以后可以通过/proc/sys/net/core/somaxconn来动态更改
- backlog设定的这个"缓冲"区,其实是为accept()准备的,每次accept()其实都来这个 "缓冲区(queue)"里面,寻找最老的一个connection
- server在调用accept()之前,就已经收到client发过来的connect()了, 这是非常可
能的, 特别是在client有很多访问的时候:
Accepting a Connection: accept()
- accept()其实就是从backlog设定的"缓冲区queue"里面寻找最老的一个connection,
如果有,就创建一个新的connected socket, 否则就block
#include <sys/socket.h> int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); /* Returns file descriptor on success, or -1 on error */
- 对于accept()理解的关键,在于这个system call创建了一个"新的socket",换句话说, 就是发现有新的电话进来以后,不是立刻接当前的电话,而是马上"创建"了一个分机,用 分机接电话.
- 当然了,当前的server还是不能相应其他的calling的. 除非,你创建一个新的process 去处理这个call,然后parent的accept()马上返回,就又可以受理其他calling的服务了
- 千万注意,fork()之后child会有自己的一份listening socket fd 和一份accepted
socket fd. 它在处理完之后都会马上关掉,但是parent里面的listening fd不能关掉
因为下一次的循环还会使用这个listening fd. 而"正是因为每次connection都创建
新的accept socket fd",所以parent里面的accept socket fd,也要关掉!
pid_t pid; int listenfd, connfd; listenfd = Socket( ... ); /* fill in sockaddr_in{} with server's well-known port */ Bind(listenfd, ... ); Listen(listenfd, LISTENQ); for ( ; ; ) { connfd = Accept (listenfd, ... ); /* probably blocks */ if( (pid = Fork()) == 0) { Close(listenfd); /* child closes listening socket */ doit(connfd); /* process the request */ Close(connfd); /* done with this client */ exit(0); /* child terminates */ } /* listenfd is still working, child only close its OWN open fd */ Close(connfd); /* parent closes connected socket */ }
- accept()剩下的两个参数是获取remote server的address和port信息的,当然可以值为 NULL和0. 因为这些参数还可以通过getpeername() system call 获取.
Connection to a Peer Socket: connect()
- connect() system call 是把sockfd所代表的socket和remote server上面处于listening
状态的socket联系起来. remote server的信息通过addr, addrlen来表示
#include <sys/socket.h> int connect(int sockfd, const struct sockaddr* addr, socklen_t addrlen); /* Returns 0 on success, or -1 on error */
- 如果connect()失败,我们"最好"close失败的本地socket,重新创建一个socket,然后 再次尝试连接
I/O on Stream Sockets
- 一旦socket connected起来以后,我们可以像使用fd一样,使用read(), write().我们 可以把写入connected socket理解为"写入remote机器上的一个文件",读取也一样
- 一个socket可以被关闭,通过close() system call, 而且关闭是两边不同的host可以 分别选择不同的时候关闭的.
- 这是个稍微诡异的地方,因为你一旦关闭了connected socket.是对方无法进行读取(会 返回EOF)你们的socket 文件了,因为你的close说明你没东西再写入了(如果你不小心 忘了刚才close了,并且再写入,也是会出错的). 而对方还没close,说明对方还有东西 要写入.所以你还是可以读取的.
Connection Termination: close()
- close()是关闭socket的方法,但是close()并不能保证对方收到我们的数据,这需要协 议层面的支持
Datagram Sockets
- 对于datagram的操作,可以解释成"老式的邮政系统":
- 如果两者希望通信,那么必须要通信双方都要有邮局(得通邮),所以通信双方都使用socket() 来各自建立一个邮局
- 为了让对方知道自己的地址,需要使用bind()来把自己的邮局和一个well-known的地 址联系起来.一般来收,只是server端需要bind(), 但是如果希望server回信给client 那么client也得进行bind()
- client端一般都会"发起"一次通信,通过sendto(), 当然了server端的回信也是sendto()
- server端读取client的通信是通过recvfrom()
- 当没有通信需求的时候,使用close()关闭socket
Figure 11: datagram-socket.png
Exchanging Datagrams: recvfrom() and sendto()
- 我们刚才看到了,在datagram的传输中,起到"实质性"传输作用的是recvfrom和sendto
#include <sys/socket.h> ssize_t recvfrom(int sockfd, void *buffer, size_t length, int flags, struct sockaddr *src_addr, socklen_t *addrlen); /* Returns number of bytes received, 0 on EOF, or -1 on error */ ssize_t sendto(int sockfd, const void *buffer, size_t length, int flags, const struct sockaddr *dest_addr, socklen_t addrlen); /* Returns number of bytes sent, or -1 on error */
- 前三个参数两者是一样的
- 第四个参数是一个bit mask flag
- 对于recvfrom来说src_addr, addrlen是发送者的"地址和长度"
- 对于sendto来说dest_addr, addrlen是对方的"地址和长度"
Using connect() with Datagram Sockets
- TODO
Chapter 57: Sockets: Unix Domain
UNIX Domain Socket Addresses: struct sockaddr_un
- socket里面如果domain设置为UNIX,那么说明这个是local的两个socket之间的通信,那
么domain-specific socket address structure定义如下
struct sockaddr_un { sa_family_t sun_family; /* Always AF_UNIX */ char sun_path[108]; /* Null-terminated socket pathname */ };
- 需要注意的是:
- AF_是family的前缀(ipv4, ipv6都用这个)意思是Address Family
- sun_意思是socket unix
- SUSv3并没有规定sun_path的长度,因为历史上有92, 104, 108等多种默认值
- sockaddr_un使用方法总结起来就是1清零2赋值3cast成sockaddr传入bind()
const char *SOCKNAME = "/tmp/mysock"; int sfd; struct sockaddr_un addr; sfd = socket(AF_UNIX, SOCK_STREAM, 0); /* create socket */ if (sfd == -1) errExit("socket"); memset(&addr, 0, sizeof(struct sockaddr_un)); /* Clear structure */ addr.sun_family = AF_UNIX; strncpy(addr.sun_path, SOCKNAME, sizeof(addr.sun_path) - 1); if (bind(sfd, (struct sockaddr *)&addr, sizeof(struct sockaddr_un)) == -1) errExit("bind");
- Unix domain总是会和一个pathname相关联.所有对这个socket的权限操作,其实都是对 这个文件的权限操作
- 创建Unix domain socket还需要注意如下几点:
- 不能bind 一个socket到existing pathname(bind() fails with the error EADDRINUSE)
- 最好bind一个socket到absolute pathname. 因为更不容易出错
- 一个socket只能bound to 一个pathname,一个pathname也只能对应一个socket
- 不能使用open()来打开一个socket
- 如果一个socket不再需要了, pathname entry可以使用unlink()来移除
- 我们的例子都是使用/tmp文件夹下的pathname,但是这并不是一个很好的选择
Stream Socket in the UNIX Domain
- 下面是一个在本机(和client同机)运行的iterative server(每次只能处理一个client
请求), 因为是在本机,所以使用Unix Domain就可以,传输介质使用的是stream socket
代码如下:
- 先是client和server都使用的header file
#include <sys/un.h> #include <sys/socket.h> #include "tlpi_hr.h" #define SV_SOCK_PATH "/tmp/us_xfr" #define BUF_SIZE 100
- UNIX domain下使用stream socket传递的server
#include "us_xfr.h" #define BACKLOG 5 int main(int argc, char *argv[]) { struct sockaddr_un addr; int sfd, cfd; ssize_t numRead; char buf[BUF_SIZE]; sfd = socket(AF_UNIX, SOCK_STREAM, 0); if (sfd == -1) errExit("socket"); /* Construct server socket address, bind socket to it, and make this a listeing socket. */ if (remove(SV_SOCK_PATH) == -1 && errno != ENOENT) errExit("remove-%s", SV_SOCK_PATH); memset(&addr, 0, sizeof(struct sockaddr_un)); addr.sun_family = AF_UNIX; strncpy(addr.sun_path, SV_SOCK_PATH, sizeof(addr.sun_path) - 1); if (bind(sfd, (struct sockaddr *)&addr, sizeof(struct sockaddr_un)) == -1) errExit("bind"); if (listen(sfd, BACKLOG) == -1) errExit("listen"); for (;;) { /* Hendle client connections iteratively */ /* Accept a connection. The connection is returned on a new socket, 'cfd'; the listening socket('sfd') remains open and can be used to accept further connections */ cfd = accept(sfd, NULL, NULL); if (cfd == -1) errExit("accept"); /* Transfer data from connected socket to stdout until EOF */ while ((numRead = read(cfd, buf, BUF_SIZE)) > 0) if (write(STDOUT_FILENO, buf, numRead) != numRead) fatal("partial/failed write"); if (numRead == -1) errExit("read"); if (close(cfd) == -1) errMsg("close"); } }
- client端代码如下
#include "us_xfr.h" int main(int argc, char *argv[]) { struct sockaddr_un addr; int sfd; ssize_t numRead; char buf[BUF_SIZE]; sfd = socket(AF_UNIX, SOCK_STREAM, 0); /* Create client socket */ if (sfd == -1) errExit("socket"); /* Construct server address, and make the connection */ memset(&addr, 0, sizeof(struct sockaddr_un)); addr.sun_family = AF_UNIX; strncpy(addr.sun_path, SV_SOCK_PATH, sizeof(addr.sun_path) - 1): if (connect(sfd, (struct sockaddr *)&addr, sizeof(struct sockaddr_un)) == -1) errExit("connect"); /* Copy stdin to socket */ while ((numRead = read(STDIN_FILENO, buf, BUF_SIZE)) > 0) if (write(sfd, buf, numRead) != numRead) fatal("partial/failed write"); if (numRead == -1) errExit("read"); exit(EXIT_SUCCESS); }
- 先是client和server都使用的header file
Datagram Socketin the UNIX Domain
- 前面,我们过对datagram socket的如下描述
Communication using datagram sockets is unreliable
- 上述描述的场景是基于AF_INET或者AF_INET6, 换句话说就是Internet上使用datagram socket传播才不可靠呢,在本机的AF_UNIX传输是经过kernel,是可靠的(而且是in order 并且undeuplicated)
- 我们来看看一个本机的Unix Domain的datagram socket例子
- 头文件
#include <sys/un.h> #include <sys/socket.h> #include <ctype.h> #include "tlpi_hdr.h" #define BUF_SIZE 10 #define SV_SOCK_PATH "/tmp/un_ucase"
- server端代码
#include "ud_ucase.h" int main(int argc, char *argv[]) { struct sockaddr_un svaddr, claddr; int sfd, j; ssize_t numBytes; socklen_t len; char buf[BUF_SIZE]; sfd = socket(AF_UNIX, SOCK_DGRAM, 0); /* Create server socket */ if (sfd == -1) errExit("socket"); /* Construct well-known address and bind server socket to it */ if (remove(SV_SOCK_PATH) == -1 && errno != ENOENT) errExit("remove-%s", SV_SOCK_PATH); memset(&svaddr, 0, sizeof(struct sockaddr_un)); svaddr.sun_family = AF_UNIX; strncpy(svaddr.sun_path, SV_SOCK_PATH, sizeof(svaddr.sun_path) - 1); if (bind(sfd, (struct sockaddr *)&svaddr, sizeof(struct sockaddr_un)) == -1) errExit("bind"); /* Eeceive messages, convertto uppercase, and return to client */ for (;;) { len = sizeof(struct sockaddr_un); numBytes = recvfrom(sfd, buf, BUF_SIZE, 0 (struct sockaddr *)&claddr, &len); if (numBytes == -1) errExit("recvfrom"); printf("Server received %ld bytes from %s\n", (long) numBytes, claddr.sun_path); for (j = 0; j < numBytes; j++) buf[j] = toupper((unsigned char) buf[j]); if (sendto(sfd, buf, numBytes, 0, (struct sockaddr*)&claddr, len) != numBytes) fatal("sendto"); } return 0; }
- client端代码
#incude "ud_ucase.h" int main(int argc, char *argv[]) { struct sockaddr_un svaddr, claddr; int sfd, j; size_t msgLen; ssize_t numBytes; char resp[BUF_SIZE]; if (argc < 2 || strcmp(argv[1], "--help") == 0) usageErr("%s msg...\n", argv[0]); /* Crate client socke; bindto unique pathname (Base on PID) */ sfd = socket(AF_UNIX, SOCK_DGRAM, 0); if (sfd == -1) errExit("socket"); memset(&claddr, 0, sizeof(struct sockaddr_un)); claddr.sun_family = AF_UNIX; snprintf(claddr.sun_path, sizeof(claddr.sun_path), "/tmp/ud_ucase_cl.%ld", (long)getpid()); if (bind(sfd, (struct sockaddr*)&claddr, sizeof(struct sockaddr_un)) == -1) errExit("bind"); /* Construct addressof server */ memset(&svaddr, 0, sizeof(struct sockaddr_un)); svaddr.sun_family = AF_UNIX; strncpy(svaddr.sun_path, SV_SOCK_PATH, sizeof(svaddr.sun_path) - 1); /* Send messages to server;echo responseson stdout */ for (j = 1; j < argc; j++) { msgLen = strlen(argv[j]); if (sendto(sfd, argv[j], msgLen, 0, (struct sockaddr*)&svaddr, sizeof(struct sockaddr_un)) != msgLen) fatal("sendto"); numBytes = recvfrom(sfd, resp, BUF_SIZE, 0, NULL, NULL); if (numBytes == -1) errExit("recvfrom"); printf("Response %d: %.*s\n", j, (int)numBytes, resp); } remove(claddr.sun_path); exit(EXIT_SUCCESS); }
- 头文件
Unix Domain Socket Permissions
- socket file其实就是一个文件,而其他process对这个这个文件的一些ownership 和
permission决定了哪些process可以和那个socket进行通信:
- 为了能够和一个Unix domain stream socket connect, process需要对这个file有 write permission
- 为了能够在一个Unix domain datagram socket上传输数据, process需要对这个file 有write permission
- 一个socket创建的时候,所有的owner和group和other都被授予了all permission, 如果 这个不是我们想要的,我们可以使用umask()来disable 这种permission
Creating a Connected Socket Pair: socketpair()
- 有时候,我们希望一个process创建两个socket,并且把这两个socket联系起来,当然可以
调用两次socket()等,我们还可以使用socketpair()来"一次性"调用这些system calls
#include <sys/socket.h> int sockepair(int domain, int type, int protocol, int sockfd[2]); /* Returns 0 on success, or -1 on error */
The Linux Abstract Socket Namespace
- Linux-specific有个特殊的feature叫做abstract namespace.就是可以bind一个Unix domain socket到一个pathname, 但是并不真正的创建这个pathname.