mysql-cookbook-3rd
Table of Contents
- Chapter 1: Using the mysql Client Program
- Introduction
- Setting Up a MySQL User Accoutn
- Creating a Database and a Sample Table
- What to Do if mysql Cannot Be Found
- Specifying mysql Command Options
- Executing SQL Statements Interactively
- Executing SQL Statements Read from a File or Program
- Controlling mysql Output Destination and Format
- Using User-Defined Variables in SQL Statements
- Chapter 2: Writing MySQL-Based Programs
- Chapter 3: Selecting Data from Tables
- Specifying Which Columns and Rows to Select
- Naming Query Result Columns
- Sorting Query Results
- Removing Duplicate Rows
- Working with NULL Values
- Writing Comparisons Involving NULL in Programs
- Using Views to Simplify Table Access
- Selecting Data from Multiple Tables
- Selecting Rows from Beginning, End, or Middle of Query Results
- What to Do When LIMIT Requires the "Wrong" Sort Order
- Calculating LIMIT Values from Expressions
- Chapter 4: Table Management
- Chapter 5: Working with Strings
- Chapter 6: Working with Dates and Times
- Chapter 7: Sorting Query Results
- Chapter 8: Generating Summaries
- Basic Summary Techniques
- Creating a View to Simplify Using a Summary
- Finding Values Associated with Minimum and Maximum Values
- Controlling String Case Sensitivity for MIN() and MAX()
- Dividing a Summary into Subgroups
- Summaries and NULL Values
- Selecting Only Groups with Certain Characteristics
- Using Counts to Determine Whether Values Are Unique
- Grouping By Expression Results
- Chapter 9: Using Stored Routines, Triggers, and Scheduled Events
Chapter 1: Using the mysql Client Program
Introduction
- mysql数据库系统使用了cs架构:
- server端(二进制名字mysqld)在实际上管理着数据库
- client端(二进制名字mysql)用来和server进行通信,使用SQL语言来告诉server应该 怎样做
- client端也可以是用户自己开发的程序,但是其原理和client端(二进制名字mysql)一 样是发送sql给server来获取结果
- 二进制文件mysql一般安装在想要访问server的机器上,但是server却并不一定在本地, 可以安装在任意一个host上面,只要client可以ping到就可以了.
- 二进制文件mysql是默认的client程序,作为一个unix下面的program它完全可以像其他 的bash program一样用在script里面
- 这一章主要有如下例子:
- 为了使用cookbook数据库,设置Mysql账户
- 设置connection parater,使用多种方式,比如option file
- 使用interactively和batch两种mode来实行SQL语句
- 控制mysql输出格式
- 使用用户定义的变量来存储信息
- 本书例子基于如下三个事实:
- mysql server安装在localhost
- mysql 用户名cbuser,密码cbpass
- database的名字是cookbook
Setting Up a MySQL User Accoutn
Problem:
- 需要一个连接MySQL server的账号
Solution
- 使用CREATE USER和GRANT命令来建立,并且赋予账号权限
- 我们这里使用了docker来模仿多个数据库,所以port不一定是3306,而且host必须是
127.0.0.1,而不能是localhost(因为要使用tcp socket,而不是domain socket)
$ mysql -uroot -proot -h127.0.0.1 -P13306 mysql -uroot -proot -h127.0.0.1 -P13306 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.5.54 MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> use mysql; use mysql; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> SELECT Host, User, Password FROM user ; SELECT Host, User, Password FROM user ; +-----------+------+-------------------------------------------+ | Host | User | Password | +-----------+------+-------------------------------------------+ | localhost | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | | % | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | +-----------+------+-------------------------------------------+ 2 rows in set (0.01 sec)
Discussion
- mysql这个命令在命令行里面一般是作为client来使用的,如果不加参数的话,会传入 默认值,比如没有-h参数那么就默认host是localhost
- 我们使用root账号登录但是我们对不同的数据库最好有不同的用户,不同的权限.比如
我们这里就使用CREATE USER建立一个用户cbuer,密码是cbpass(我们这里还使用了`%`
来表示我们允许cbuser可以从任何的ip访问当前server,就像root一样,如果只允许本
机的ip访问,那么就要设置成localhost)
mysql> CREATE USER 'cbuser'@'%' IDENTIFIED BY 'cbpass'; CREATE USER 'cbuser'@'%' IDENTIFIED BY 'cbpass'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT Host, User, Password FROM user ; SELECT Host, User, Password FROM user ; +-----------+--------+-------------------------------------------+ | Host | User | Password | +-----------+--------+-------------------------------------------+ | localhost | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | | % | cbuser | *126CFB940B0843713B19A6C21B99C0F1F9F3AFB6 | | % | root | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | +-----------+--------+-------------------------------------------+ 3 rows in set (0.00 sec)
- 第二步就是使用GRANT来给这个user设置对于某个数据库的权限,这个权限可以通过SHOW
GRANTS FOR <user>来查询. "cookbook.*"代表cookbook数据库下面的所有的table
mysql> SHOW GRANTS for cbuser; SHOW GRANTS for cbuser; +-------------------------------------------------------------------------------------------------------+ | Grants for cbuser@% | +-------------------------------------------------------------------------------------------------------+ | GRANT USAGE ON *.* TO 'cbuser'@'%' IDENTIFIED BY PASSWORD '*126CFB940B0843713B19A6C21B99C0F1F9F3AFB6' | +-------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> GRANT ALL ON cookbook.* TO 'cbuser'@'%'; GRANT ALL ON cookbook.* TO 'cbuser'@'%'; Query OK, 0 rows affected (0.00 sec) mysql> SHOW GRANTS for cbuser; SHOW GRANTS for cbuser; +-------------------------------------------------------------------------------------------------------+ | Grants for cbuser@% | +-------------------------------------------------------------------------------------------------------+ | GRANT USAGE ON *.* TO 'cbuser'@'%' IDENTIFIED BY PASSWORD '*126CFB940B0843713B19A6C21B99C0F1F9F3AFB6' | | GRANT ALL PRIVILEGES ON `cookbook`.* TO 'cbuser'@'%' | +-------------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec)
- 设置完之后我们就可以使用新的用户登录啦,因为我们有权限的数据库cookbook还没
有建立,所以新的用户几乎没有什么权限
$ mysql -ucbuser -pcbpass -h127.0.0.1 -P13306 mysql -ucbuser -pcbpass -h127.0.0.1 -P13306 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.5.54 MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; show databases; +--------------------+ | Database | +--------------------+ | information_schema | +--------------------+ 1 row in set (0.00 sec)
Creating a Database and a Sample Table
Problem
- 创建数据库,并建立里面的表
Solution
- 使用CREATE DATABASE创建数据库,使用CREATE TABLE创建表格,使用INSERT插入数据
Discussion
- 前面为cbuser设计了权限,所以cbuser只能创建cookbook数据库
mysql> CREATE DATABASE diff_cookbook; CREATE DATABASE diff_cookbook; ERROR 1044 (42000): Access denied for user 'cbuser'@'%' to database 'diff_cookbook' mysql> CREATE DATABASE cookbook; CREATE DATABASE cookbook; Query OK, 1 row affected (0.00 sec)
- 使用create database创建数据库后,能看到有两个数据库了
mysql> show databases; show databases; +--------------------+ | Database | +--------------------+ | information_schema | | cookbook | +--------------------+ 2 rows in set (0.00 sec)
- 使用cookbook这个数据库,在里面创建一个使用CREATE TABLE创建一个table, limbs
mysql> use cookbook; use cookbook; Database changed mysql> CREATE TABLE limbs (thing VARCHAR(20), legs INT, arms INT); CREATE TABLE limbs (thing VARCHAR(20), legs INT, arms INT); Query OK, 0 rows affected (0.21 sec)
- 使用INSERT加入一些数据
mysql> INSERT INTO limbs (thing,legs,arms) VALUES('human',2,2); INSERT INTO limbs (thing,legs,arms) VALUES('insect',6,0); INSERT INTO limbs (thing,legs,arms) VALUES('squid',0,10); INSERT INTO limbs (thing,legs,arms) VALUES('fish',0,0); INSERT INTO limbs (thing,legs,arms) VALUES('centipede',100,0); INSERT INTO limbs (thing,legs,arms) VALUES('table',4,0); INSERT INTO limbs (thing,legs,arms) VALUES('armchair',4,2); INSERT INTO limbs (thing,legs,arms) VALUES('phonograph',0,1); INSERT INTO limbs (thing,legs,arms) VALUES('tripod',3,0); INSERT INTO limbs (thing,legs,arms) VALUES('Peg Leg Pete',1,2); INSERT INTO limbs (thing,legs,arms) VALUES('space alien',NULL,NULL); mysql> select * from limbs; select * from limbs; +--------------+------+------+ | thing | legs | arms | +--------------+------+------+ | human | 2 | 2 | | insect | 6 | 0 | | squid | 0 | 10 | | fish | 0 | 0 | | centipede | 100 | 0 | | table | 4 | 0 | | armchair | 4 | 2 | | phonograph | 0 | 1 | | tripod | 3 | 0 | | Peg Leg Pete | 1 | 2 | | space alien | NULL | NULL | +--------------+------+------+ 11 rows in set (0.00 sec)
What to Do if mysql Cannot Be Found
Problem
- 命令行里面打印mysql不起作用
Solution
- 把包含mysql的文件夹加入PATH
Specifying mysql Command Options
Problem
- 命令行里面打mysql,直接返回"access denied"
Solution
- 需要在mysql后面明确的指出option,或者把option写到文件里面
Discussion
- 在命令行里面写入参数有两种模式:
- short form: 比如`-h`
- long form : 比如`–host`
- 可以使用mysql –help来查看所有的参数
- mysql所有的参数对其他mysql的binary都合适,比如mysqldump(用来把cookbook里面
所有的的数据都导入到一个sql文件里面)
hfeng@ mysql_study (master) $ mysqldump -h127.0.0.1 -ucbuser -pcbpass cookbook > cookbook.sql mysqldump: [Warning] Using a password on the command line interface can be insecure. hfeng@ mysql_study (master) $ head cookbook.sql -- MySQL dump 10.13 Distrib 5.7.13, for osx10.11 (x86_64) -- -- Host: 127.0.0.1 Database: cookbook -- ------------------------------------------------------ -- Server version 5.6.31 /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */;
- 还可以把参数都写入到一个配置文件里面,mysql里面可以选的my.cnf的位置,以及调
用顺序如下
hfeng@ mysql (master) $ mysql --help | grep '~/.my.cnf' -C1 Default options are read from the following files in the given order: /etc/my.cnf /etc/mysql/my.cnf /usr/local/etc/my.cnf ~/.my.cnf The following groups are read: mysql client
- 我们个人的最佳设置位置肯定就是~/.my.cnf,我们来设置一下试试,就可使用mysql直
接运行client了
hfeng@ ~ $ cat ~/.my.cnf [client] host = 127.0.0.1 user = cbuser password = cbpass hfeng@ ~ $ mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 6 Server version: 5.6.31 MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
- 我们可以使用如下的两种方法看看自己以及设置了哪些的default
hfeng@ ~ $ mysql --print-defaults mysql --print-defaults mysql would have been started with the following arguments: --host=127.0.0.1 --user=cbuser --password=***** hfeng@ ~ $ my_print_defaults client mysqldump my_print_defaults client mysqldump --host=127.0.0.1 --user=cbuser --password=*****
- 一旦我们的~/.my.cnf设置了密码的话,我们要使用如下代码来屏蔽cnf文件的可见性
hfeng@ org (master) $ chmod go-rwx ~/.my.cnf chmod go-rwx ~/.my.cnf hfeng@ org (master) $ ls -al ~/.my.cnf ls -al ~/.my.cnf -rw------- 1 hfeng staff 66 Aug 18 19:22 /Users/hfeng/.my.cnf
Executing SQL Statements Interactively
Problem
- 你已经开启了mysql client,现在想开始运行命令
Solution
- 直接输入命令即刻,输入分号(;)等让mysql知道你输入完毕.或者使用-e参数不需要进 入client的交互平台'>',就在bash直接运行SQL
Discussion
- 当你进入mysql的client命令行的时候,它展示出'mysql>'来告诉你server准备好接受
你的命令了.你输入命令后加上1分号(;)2回车之后就表示可以运行了
mysql> SELECT NOW(); SELECT NOW(); +---------------------+ | NOW() | +---------------------+ | 2016-08-18 11:41:49 | +---------------------+ 1 row in set (0.00 sec)
- 仅仅有回车是不够的,因为mysql client还允许你用Enter换行,从而输入多行.所以分
号是必须的,当然了你可以使用\g完全替代分号(;)
mysql> SELECT -> NOW()\g +---------------------+ | NOW() | +---------------------+ | 2016-08-18 11:44:22 | +---------------------+ 1 row in set (0.00 sec) - `;`和`\g`不是statement的一部分,而是专门给mysql"分割"命令,并传给server时候 用的
- 遇到超长的表格,我们还可以使用`\G`来替代`;`或者`\g`来"横屏显示"
mysql> SELECT NOW()\G SELECT NOW()\G *************************** 1. row *************************** NOW(): 2016-08-18 11:52:18 1 row in set (0.00 sec)
- 如果让`\G`替代`\g`为默认,我们需要设置-E(or –vertical), 如果只是想让超过的 行使用`\G`,那么使用–auto-vertical-output
- 我们还可以在命令里面通过参数-e直接运行SQL语句,多行使用`;`进行分割
hfeng@ org (master) $ mysql -e "SELECT COUNT(*) FROM limbs;SELECT NOW()" cookbook mysql -e "SELECT COUNT(*) FROM limbs;SELECT NOW()" cookbook +----------+ | COUNT(*) | +----------+ | 11 | +----------+ +---------------------+ | NOW() | +---------------------+ | 2016-08-18 11:57:42 | +---------------------+
Executing SQL Statements Read from a File or Program
Problem
- 希望从一个文件中读取sql语句并且执行,而不是在client的>里面一个一个打印
Solution
- 从文件中读取,然后redirect到mysql的input
Discussion
- 最简单的办法就是使用Unix的redirect文件到mysql里面
mysql cookbook < file_name
- 还可以使用Unix里面的pipe,我们可以书写一个程序生成测试SQL语句,然后`|`之后进
行导入
generate-test-data | mysql cookbook
- 还有一个意想不到的方法是在'mysql>'里面使用source file_name.sql的方法就能直
接执行file_name.sql里面的语句
mysql> select * from limbs; select * from limbs; +--------------+------+------+ | thing | legs | arms | +--------------+------+------+ | human | 2 | 2 | | insect | 6 | 0 | | squid | 0 | 10 | | fish | 0 | 0 | | centipede | 100 | 0 | | table | 4 | 0 | | armchair | 4 | 2 | | phonograph | 0 | 1 | | tripod | 3 | 0 | | Peg Leg Pete | 1 | 2 | +--------------+------+------+ 10 rows in set (0.00 sec) mysql> source tmp.sql source tmp.sql Query OK, 1 row affected (0.03 sec) mysql> select * from limbs; select * from limbs; +--------------+------+------+ | thing | legs | arms | +--------------+------+------+ | human | 2 | 2 | | insect | 6 | 0 | | squid | 0 | 10 | | fish | 0 | 0 | | centipede | 100 | 0 | | table | 4 | 0 | | armchair | 4 | 2 | | phonograph | 0 | 1 | | tripod | 3 | 0 | | Peg Leg Pete | 1 | 2 | | space alien | NULL | NULL | +--------------+------+------+ 11 rows in set (0.00 sec)
Controlling mysql Output Destination and Format
Problem
- 你希望mysql的output不是打印到屏幕上,而是去到别的地方,比如文件里面.而且你希 望能够设置打印格式
Solution
- 可以使用'>'把结果导入到文件里面.
- 而如果希望设置打印格式的话,mysql提供了HTML,XML等格式,打印样式也有所不同
Discussion
- 如下命令会把你的结果写入到outputfile里面
mysql cookbook > outputfile
- 当然了,如果你懒得打字,还可以把文件使用'<'导入inputfile
hfeng@ tmp $ cat input.sql SELECT * from limbs; hfeng@ tmp $ mysql < input.sql > output.txt cookbook hfeng@ tmp $ cat output.txt thing legs arms human 2 2 insect 6 0 squid 0 10 fish 0 0 centipede 100 0 table 4 0 armchair 4 2 phonograph 0 1 tripod 3 0 Peg Leg Pete 1 2 space alien NULL NULL
- 上面打印出来的结果貌似不是很好看,如果想要client>里面的效果,需要设置参数`-t`
hfeng@ tmp $ mysql -t < input.sql > output.txt cookbook hfeng@ tmp $ cat output.txt +--------------+------+------+ | thing | legs | arms | +--------------+------+------+ | human | 2 | 2 | | insect | 6 | 0 | | squid | 0 | 10 | | fish | 0 | 0 | | centipede | 100 | 0 | | table | 4 | 0 | | armchair | 4 | 2 | | phonograph | 0 | 1 | | tripod | 3 | 0 | | Peg Leg Pete | 1 | 2 | | space alien | NULL | NULL | +--------------+------+------+
- 我们还可以导出其他格式:
- `-H`导出HTML格式
- `-X`导出XML格式
Using User-Defined Variables in SQL Statements
Problem
- 某次查询的结果想保留起来,以后可以多次使用
Solution
- 就像编程语言里面的变量:把value存储在user-defined的变量里面,后面可以使用
Discussion
- User variable是Mysql特有的特性(区别于standard SQL),在其他database engine上 面无法使用
- User variable的特点是使用@作为变量标识符
mysql> SELECT @max_limbs := MAX(arms+legs) FROM limbs; SELECT @max_limbs := MAX(arms+legs) FROM limbs; +------------------------------+ | @max_limbs := MAX(arms+legs) | +------------------------------+ | 100 | +------------------------------+ 1 row in set (0.00 sec) mysql> SELECT * FROM limbs WHERE arms+legs = @max_limbs; SELECT * FROM limbs WHERE arms+legs = @max_limbs; +-----------+------+------+ | thing | legs | arms | +-----------+------+------+ | centipede | 100 | 0 | +-----------+------+------+ 1 row in set (0.00 sec)
- Mysql里面变量的一个"神应用"是记录"函数":就像functional 语言里面的,把function
作为一个变量存储起来,以后来使用
mysql> SELECT @last_id := LAST_INSERT_ID(); SELECT @last_id := LAST_INSERT_ID(); +------------------------------+ | @last_id := LAST_INSERT_ID() | +------------------------------+ | 0 | +------------------------------+ 1 row in set (0.01 sec) mysql> SELECT @last_id; SELECT @last_id; +----------+ | @last_id | +----------+ | 0 | +----------+ 1 row in set (0.00 sec)
- 如果变量被赋予了'多个值',那么就等于这个变量被赋值了多次,最后一次的赋值才起
作用
mysql> SELECT @name := thing FROM limbs WHERE legs = 0; SELECT @name := thing FROM limbs WHERE legs = 0; +----------------+ | @name := thing | +----------------+ | squid | | fish | | phonograph | +----------------+ 3 rows in set (0.00 sec) mysql> SELECT @name; SELECT @name; +------------+ | @name | +------------+ | phonograph | +------------+ 1 row in set (0.00 sec)
- 如果变量被赋予的查询结果是空的话,那么变量的结果是NULL
mysql> SELECT @name := thing FROM limbs WHERE legs < 0; SELECT @name := thing FROM limbs WHERE legs < 0; Empty set (0.00 sec) mysql> SELECT @name; SELECT @name; +------------+ | @name | +------------+ | phonograph | +------------+ 1 row in set (0.00 sec)
- 如果需要把变量设置成"particular value"的话,那么不需要使用SELECT和`:=`,而要
使用SET和`=`
mysql> SET @sum = 4 + 7; SET @sum = 4 + 7; Query OK, 0 rows affected (0.00 sec) mysql> SELECT @sum; SELECT @sum; +------+ | @sum | +------+ | 11 | +------+ 1 row in set (0.00 sec)
- 也可以把SELECT的结果发送给`SET和=`的方式来进行设置
mysql> SET @max_limbs = (SELECT MAX(arms+legs) FROM limbs); SET @max_limbs = (SELECT MAX(arms+legs) FROM limbs); Query OK, 0 rows affected (0.00 sec) mysql> SELECT @max_limbs; SELECT @max_limbs; +------------+ | @max_limbs | +------------+ | 100 | +------------+ 1 row in set (0.00 sec)
- User variable也是不区分大小写的
mysql> SET @x = 1, @X=2; SELECT @x, @X; SET @x = 1, @X=2; SELECT @x, @X; Query OK, 0 rows affected (0.00 sec) +------+------+ | @x | @X | +------+------+ | 2 | 2 | +------+------+ 1 row in set (0.00 sec)
- User variable只能出现在expression出现在的地方,而不是constant活着literal
identifier该出现的地方
mysql> SET @tabl_name = CONCAT('tmp_bl_', CONNECTION_ID()); SET @tabl_name = CONCAT('tmp_bl_', CONNECTION_ID()); Query OK, 0 rows affected (0.00 sec) mysql> SELECT @tabl_name; SELECT @tabl_name; +------------+ | @tabl_name | +------------+ | tmp_bl_32 | +------------+ 1 row in set (0.00 sec) mysql> CREATE TABLE @tabl_name; CREATE TABLE @tabl_name; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '@tabl_name' at line 1
Chapter 2: Writing MySQL-Based Programs
Connecting, Selecting a Database, and Disconnecting
Problem
- 需要使用connection建立数据库连接,并且完成操作以后,关闭这些连接
Solution
- 一般使用编程语言连接mysql的步骤也很简单:
- 建立连接到mysql的连接
- 选择一个mysql里面的数据库
- 使用完成后,关闭这个数据库连接
Discussion
- 我们以python为例,看看这个程序如何写
#!/usr/bin/python # connect.py connect to the MySQL server import mysql.connector try: conn = mysql.connector.connect(database="cookbook", host="127.0.0.1", user="cbuser", password="cbpass") print("Connected") except: print("Cannot connect to server") else: conn.close() print("Disconnected") ################################################## # <===================OUTPUT===================> # # $ python connect.py # # Connected # # Disconnected # ##################################################
Checking for Errors
Problem
- 连接mysql的client程序出现问题
Solution
- 在代码中增加error checking的代码
Discussion
- 当一个error出现的时候,mysql会提供如下的三个值:
- MySQL-specific error code number
- MySQL-specific 错误说明message
- ANSI或者ODBC标准里面定义的"五个字母"的SQLSTATE
- 我们通过下面的代码来看看如何在出现问题的时候,暴露出这个三个值
#!/usr/bin/python # connect.py connect to the MySQL server import mysql.connector conn_params = { "database": "cookbook", "host": "127.0.0.1", "user": "baduser", "password": "badpass" } try: conn = mysql.connector.connect(**conn_params) print("Connected") except mysql.connector.Error as e: print("Cannot connecto to server") print("Error code number: %s" % e.errno) print("Error message: %s" % e.msg) print("Error SQLSTATE: %s" % e.sqlstate) ###################################################################################### # <===================OUTPUT===================> # # Cannot connecto to server # # Error code number: 1045 # # Error message: Access denied for user 'baduser'@'172.21.0.1' (using password: YES) # # Error SQLSTATE: 28000 # ######################################################################################
Writing Library Files
Problem
- 经常在不同地方重复一些操作,那么就要想着把这些操作写成library,而如果这些操 作跟mysql有关,那么就是mysql library而已
Solution
- 只需要把你的文件放入library file里面,然后其他程序可以访问这个library file, 那么你就成功了
Discussion
- 我们可以使用如下的代码提供一个python的library(这个library就叫做cookbook)
# cookbook.py: library file with utility method for connecting # to MySQL using the Connector/Python module import mysql.connector conn_params = { "database": "cookbook", "host": "127.0.0.1", "user": "cbuser", "password": "cbpass", } def connect(): return mysql.connector.connect(**conn_params)
- 使用的时候,方法如下
import cookbook conn = cookbook.connect()
- TODO
Chapter 3: Selecting Data from Tables
Specifying Which Columns and Rows to Select
Problem
- 我们都知道使用SELECT可以选择读取某些行,如何更具体的找到这些行,还需要其他技巧
Solution
- WHERE和SELECT配合就可以找到非常精确的,具体哪一行
Discussion
- 最简单的是`*`号啦,表示我们所有的列都想要
mysql> select * from mail; select * from mail; +---------------------+---------+---------+---------+---------+---------+ | t | srcuser | srchost | dstuser | dsthost | size | +---------------------+---------+---------+---------+---------+---------+ | 2014-05-11 10:15:08 | barb | saturn | tricia | mars | 58274 | | 2014-05-12 12:48:13 | tricia | mars | gene | venus | 194925 | | 2014-05-12 15:02:49 | phil | mars | phil | saturn | 1048 | | 2014-05-12 18:59:18 | barb | saturn | tricia | venus | 271 | | 2014-05-14 09:31:37 | gene | venus | barb | mars | 2291 | | 2014-05-14 11:52:17 | phil | mars | tricia | saturn | 5781 | | 2014-05-14 14:42:21 | barb | venus | barb | venus | 98151 | | 2014-05-14 17:03:01 | tricia | saturn | phil | venus | 2394482 | | 2014-05-15 07:17:48 | gene | mars | gene | saturn | 3824 | | 2014-05-15 08:50:57 | phil | venus | phil | venus | 978 | | 2014-05-15 10:25:52 | gene | mars | tricia | saturn | 998532 | | 2014-05-15 17:35:31 | gene | saturn | gene | mars | 3856 | | 2014-05-16 09:00:28 | gene | venus | barb | mars | 613 | | 2014-05-16 23:04:19 | phil | venus | barb | venus | 10294 | | 2014-05-19 12:49:23 | phil | mars | tricia | saturn | 873 | | 2014-05-19 22:21:51 | gene | saturn | gene | venus | 23992 | +---------------------+---------+---------+---------+---------+---------+ 16 rows in set (0.00 sec)
- 我们当然也可以在SELECT后面明确表示想要哪些'列'!
mysql> SELECT srcuser, srchost, t, size FROM mail; SELECT srcuser, srchost, t, size FROM mail; +---------+---------+---------------------+---------+ | srcuser | srchost | t | size | +---------+---------+---------------------+---------+ | barb | saturn | 2014-05-11 10:15:08 | 58274 | | tricia | mars | 2014-05-12 12:48:13 | 194925 | | phil | mars | 2014-05-12 15:02:49 | 1048 | | barb | saturn | 2014-05-12 18:59:18 | 271 | | gene | venus | 2014-05-14 09:31:37 | 2291 | | phil | mars | 2014-05-14 11:52:17 | 5781 | | barb | venus | 2014-05-14 14:42:21 | 98151 | | tricia | saturn | 2014-05-14 17:03:01 | 2394482 | | gene | mars | 2014-05-15 07:17:48 | 3824 | | phil | venus | 2014-05-15 08:50:57 | 978 | | gene | mars | 2014-05-15 10:25:52 | 998532 | | gene | saturn | 2014-05-15 17:35:31 | 3856 | | gene | venus | 2014-05-16 09:00:28 | 613 | | phil | venus | 2014-05-16 23:04:19 | 10294 | | phil | mars | 2014-05-19 12:49:23 | 873 | | gene | saturn | 2014-05-19 22:21:51 | 23992 | +---------+---------+---------------------+---------+ 16 rows in set (0.01 sec)
- WHERE最简单的用法就是在WHERE后面进行condition判断来确定哪些行可以取, 这个
condition可以是等于,不等于
mysql> SELECT t, srcuser, srchost FROM mail WHERE srchost = 'venus'; SELECT t, srcuser, srchost FROM mail WHERE srchost = 'venus'; +---------------------+---------+---------+ | t | srcuser | srchost | +---------------------+---------+---------+ | 2014-05-14 09:31:37 | gene | venus | | 2014-05-14 14:42:21 | barb | venus | | 2014-05-15 08:50:57 | phil | venus | | 2014-05-16 09:00:28 | gene | venus | | 2014-05-16 23:04:19 | phil | venus | +---------------------+---------+---------+ 5 rows in set (0.00 sec)
- condition还可以是LIKE这种wildcard(`%`匹配所有的字符串)
mysql> SELECT t, srcuser, srchost FROM mail WHERE srchost LIKE 's%'; SELECT t, srcuser, srchost FROM mail WHERE srchost LIKE 's%'; +---------------------+---------+---------+ | t | srcuser | srchost | +---------------------+---------+---------+ | 2014-05-11 10:15:08 | barb | saturn | | 2014-05-12 18:59:18 | barb | saturn | | 2014-05-14 17:03:01 | tricia | saturn | | 2014-05-15 17:35:31 | gene | saturn | | 2014-05-19 22:21:51 | gene | saturn | +---------------------+---------+---------+ 5 rows in set (0.00 sec)
- WHERE的condition还可以进行condition逻辑运算
mysql> SELECT * from mail WHERE srcuser = 'barb' AND dstuser = 'tricia'; SELECT * from mail WHERE srcuser = 'barb' AND dstuser = 'tricia'; +---------------------+---------+---------+---------+---------+-------+ | t | srcuser | srchost | dstuser | dsthost | size | +---------------------+---------+---------+---------+---------+-------+ | 2014-05-11 10:15:08 | barb | saturn | tricia | mars | 58274 | | 2014-05-12 18:59:18 | barb | saturn | tricia | venus | 271 | +---------------------+---------+---------+---------+---------+-------+ 2 rows in set (0.00 sec)
- 另外值得一说的是,SELECT里面的数据,还可使用函数CONCAT进行字符串组合
mysql> SELECT t, CONCAT(srcuser, '@', srchost), size FROM mail; SELECT t, CONCAT(srcuser, '@', srchost), size FROM mail; +---------------------+-------------------------------+---------+ | t | CONCAT(srcuser, '@', srchost) | size | +---------------------+-------------------------------+---------+ | 2014-05-11 10:15:08 | barb@saturn | 58274 | | 2014-05-12 12:48:13 | tricia@mars | 194925 | | 2014-05-12 15:02:49 | phil@mars | 1048 | | 2014-05-12 18:59:18 | barb@saturn | 271 |
Naming Query Result Columns
Problem
- SELECT出来的column名字看起来不合适,希望自己改动一下
Solution
- 使用alias来选择自己的column名字
Discussion
- 如果你默认SELECT的话,那么MySQL就使用table column name来填充output column name
mysql> SELECT * from mail; SELECT * from mail; +---------------------+---------+---------+---------+---------+---------+ | t | srcuser | srchost | dstuser | dsthost | size | +---------------------+---------+---------+---------+---------+---------+ | 2014-05-11 10:15:08 | barb | saturn | tricia | mars | 58274 |
- 如果我想更改某个column name,那么就要使用关键字AS
mysql> SELECT t AS Title, size AS Size from mail; SELECT t AS Title, size AS Size from mail; +---------------------+---------+ | Title | Size | +---------------------+---------+ | 2014-05-11 10:15:08 | 58274 |
- 上一节,我们使用CONCAT的时候,会发现这个output column name很难看
mysql> SELECT t, CONCAT(srcuser, '@', srchost), size FROM mail; SELECT t, CONCAT(srcuser, '@', srchost), size FROM mail; +---------------------+-------------------------------+---------+ | t | CONCAT(srcuser, '@', srchost) | size | +---------------------+-------------------------------+---------+ | 2014-05-11 10:15:08 | barb@saturn | 58274 | | 2014-05-12 12:48:13 | tricia@mars | 194925 | | 2014-05-12 15:02:49 | phil@mars | 1048 | | 2014-05-12 18:59:18 | barb@saturn | 271 |
- 这个时候,使用AS是非常方便的
mysql> SELECT t, CONCAT(srcuser, '@', srchost) AS Sender, size FROM mail; SELECT t, CONCAT(srcuser, '@', srchost) AS Sender, size FROM mail; +---------------------+---------------+---------+ | t | Sender | size | +---------------------+---------------+---------+ | 2014-05-11 10:15:08 | barb@saturn | 58274 |
- 我们需要知道AS只是做了一个output column name而已,系统并不认识这个名字
mysql> SELECT t, size/1024 AS kilobytes FROM mail where kilobytes > 500; ERROR 1054 (42S22): Unknown column 'kilobytes' in 'where clause'
- 这种情况下,使用AS之前的`函数或者运算`是非常合理的
mysql> SELECT t, size/1024 AS kilobytest FROM mail where size/1014 > 500; SELECT t, size/1024 AS kilobytest FROM mail where size/1014 > 500; +---------------------+------------+ | t | kilobytest | +---------------------+------------+ | 2014-05-14 17:03:01 | 2338.3613 | | 2014-05-15 10:25:52 | 975.1289 | +---------------------+------------+ 2 rows in set (0.00 sec)
Sorting Query Results
Problem
- 你的query出来以后,顺序不是我想要的,要调整一下顺序
Solution
- 使用ORDER BY来调整顺序
Discussion
- 按照"正序"排列的话,那么就是直接ORDER BY就可以了
mysql> SELECT * from mail WHERE dstuser = 'tricia' ORDER BY srchost, srcuser; SELECT * from mail WHERE dstuser = 'tricia' ORDER BY srchost, srcuser; +---------------------+---------+---------+---------+---------+--------+ | t | srcuser | srchost | dstuser | dsthost | size | +---------------------+---------+---------+---------+---------+--------+ | 2014-05-15 10:25:52 | gene | mars | tricia | saturn | 998532 | | 2014-05-14 11:52:17 | phil | mars | tricia | saturn | 5781 | | 2014-05-19 12:49:23 | phil | mars | tricia | saturn | 873 | | 2014-05-11 10:15:08 | barb | saturn | tricia | mars | 58274 | | 2014-05-12 18:59:18 | barb | saturn | tricia | venus | 271 | +---------------------+---------+---------+---------+---------+--------+ 5 rows in set (0.00 sec)
- 按照"倒序"排列的话,那么就要在最后加上DESC
mysql> SELECT * FROM mail WHERE size > 50000 ORDER BY size DESC; SELECT * FROM mail WHERE size > 50000 ORDER BY size DESC; +---------------------+---------+---------+---------+---------+---------+ | t | srcuser | srchost | dstuser | dsthost | size | +---------------------+---------+---------+---------+---------+---------+ | 2014-05-14 17:03:01 | tricia | saturn | phil | venus | 2394482 | | 2014-05-15 10:25:52 | gene | mars | tricia | saturn | 998532 | | 2014-05-12 12:48:13 | tricia | mars | gene | venus | 194925 | | 2014-05-14 14:42:21 | barb | venus | barb | venus | 98151 | | 2014-05-11 10:15:08 | barb | saturn | tricia | mars | 58274 | +---------------------+---------+---------+---------+---------+---------+ 5 rows in set (0.00 sec)
Removing Duplicate Rows
Problem
- query的结果是包含重复的,所以你希望去重
Solution
- 使用DISTINCT关键字
Discussion
- 在查找一列的时候,出现重复的概率是很高的.
mysql> SELECT srcuser FROM mail; SELECT srcuser FROM mail; +---------+ | srcuser | +---------+ | barb | | tricia | | phil | | barb | | gene | | phil | | barb | | tricia | | gene | | phil | | gene | | gene | | gene | | phil | | phil | | gene | +---------+ 16 rows in set (0.00 sec)
- 使用DISTINCT之后,就立马好了很多
mysql> SELECT DISTINCT srcuser FROM mail; SELECT DISTINCT srcuser FROM mail; +---------+ | srcuser | +---------+ | barb | | tricia | | phil | | gene | +---------+ 4 rows in set (0.00 sec)
- DISTINCT经常和COUNT一起作用,来查看不重复的个数
mysql> SELECT COUNT(DISTINCT srcuser) FROM mail; SELECT COUNT(DISTINCT srcuser) FROM mail; +-------------------------+ | COUNT(DISTINCT srcuser) | +-------------------------+ | 4 | +-------------------------+ 1 row in set (0.00 sec)
- DISTINCT还能"multiple-column",方法如下
mysql> SELECT DISTINCT YEAR(t), MONTH(t), DAYOFMONTH(t) FROM mail; SELECT DISTINCT YEAR(t), MONTH(t), DAYOFMONTH(t) FROM mail; +---------+----------+---------------+ | YEAR(t) | MONTH(t) | DAYOFMONTH(t) | +---------+----------+---------------+ | 2014 | 5 | 11 | | 2014 | 5 | 12 | | 2014 | 5 | 14 | | 2014 | 5 | 15 | | 2014 | 5 | 16 | | 2014 | 5 | 19 | +---------+----------+---------------+ 6 rows in set (0.00 sec)
Working with NULL Values
Problem
- 试图把column value和NULL进行`=`或者`<>'对比,发现没有结果
Solution
- 和NULL对比,要使用如下的操作符(而不是`==`):
- IS NULL
- IS NOT NULL
- <=>
Discussion
- 使用`=`或者`<>`对NULL进行比较是没有意义的
mysql> SELECT * FROM expt WHERE score = NULL; SELECT * FROM expt WHERE score = NULL; Empty set (0.00 sec) mysql> SELECT * FROM expt WHERE score <> NULL; SELECT * FROM expt WHERE score <> NULL; Empty set (0.00 sec)
- 正确的方法是使用IS NULL或者IS NOT NULL
mysql> SELECT * FROM expt WHERE score IS NULL; SELECT * FROM expt WHERE score IS NULL; +---------+------+-------+ | subject | test | score | +---------+------+-------+ | Jane | C | NULL | | Jane | D | NULL | | Marvin | D | NULL | +---------+------+-------+ 3 rows in set (0.00 sec) mysql> SELECT * FROM expt WHERE score IS NOT NULL; SELECT * FROM expt WHERE score IS NOT NULL; +---------+------+-------+ | subject | test | score | +---------+------+-------+ | Jane | A | 47 | | Jane | B | 50 | | Marvin | A | 52 | | Marvin | B | 45 | | Marvin | C | 53 | +---------+------+-------+ 5 rows in set (0.00 sec)
- mysql自己创造了一个operator来比较NULL,就是`<=>`,这个操作符只对MySQL起作用
mysql> SELECT NULL = NULL, NULL <=> NULL; SELECT NULL = NULL, NULL <=> NULL; +-------------+---------------+ | NULL = NULL | NULL <=> NULL | +-------------+---------------+ | NULL | 1 | +-------------+---------------+ 1 row in set (0.00 sec)
Writing Comparisons Involving NULL in Programs
Problem
- 当使用程序进行搜索column value的时候,遇到NULL就会很危险
Solution
- 根据值是不是NULL来决定使用什么operator,这种情况在写程序的时候,更容易出现,
因为写程序的时候,我们期望的值,比如下面的变量score,可能为空,其为空的时候,我
们比较的operator就要发生改变,下面是一段如何使用python根据value的不同,来"动
态"改变operator
#!/usr/bin/python # connect.py connect to the MySQL server import mysql.connector conn_params = { "database": "cookbook", "host": "127.0.0.1", "user": "cbuser", "password": "cbpass" } try: conn = mysql.connector.connect(**conn_params) cursor = conn.cursor() score = 'NULL' # score = '50' operator = "IS" if score == 'NULL' else '=' sql = ''' SELECT * FROM expt WHERE score %s %s ''' cursor.execute(sql % (operator, score)) rows = cursor.fetchall() for row in rows: print(row) except mysql.connector.Error as e: print("Error code number: %s" % e.errno) print("Error message: %s" % e.msg) print("Error SQLSTATE: %s" % e.sqlstate)
Using Views to Simplify Table Access
Problem
- 现有的表的column设置不太能满足你的要求,你需要使用COUNT等函数来创建一些output column name(更有可能使用AS设置了新的名字),但是你经常使用这样的表,你希望不要 每次都打一遍
Solution
- 解决的方法是创建一个"虚拟的table",叫做view.这个table并不是直接存在的,而是
存储了一个table的"一种常见output形式"
mysql> CREATE VIEW mail_view AS SELECT DATE_FORMAT(t, '%M %e, %Y') AS date_sent, size FROM mail; CREATE VIEW mail_view AS SELECT DATE_FORMAT(t, '%M %e, %Y') AS date_sent, size FROM mail; Query OK, 0 rows affected (0.03 sec) mysql> SELECT date_sent, size FROM mail_view WHERE size > 100000 ORDER BY size; SELECT date_sent, size FROM mail_view WHERE size > 100000 ORDER BY size; +--------------+---------+ | date_sent | size | +--------------+---------+ | May 12, 2014 | 194925 | | May 15, 2014 | 998532 | | May 14, 2014 | 2394482 | +--------------+---------+ 3 rows in set (0.00 sec)
Selecting Data from Multiple Tables
Problem
- 解决一个问题,需要从多张表上获取数据
Solution
- join表或者subquery
Discussion
- 先看join,join是连表查询的一个经典方法,而且常用的join有如下几种,看图就可以
了解不同join的区别.
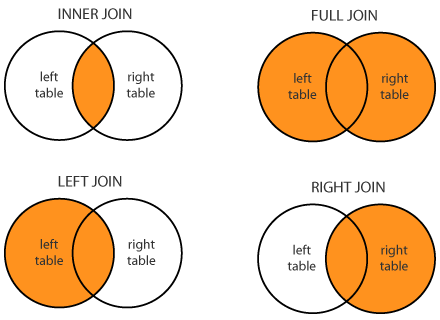
Figure 1: sql_joins.png
- 其实大部分情况下,都是inner join,比如,我们有如下两个表:
mysql> SELECT * FROM profile; SELECT * FROM profile; +----+---------+------------+-------+-----------------------+------+ | id | name | birth | color | foods | cats | +----+---------+------------+-------+-----------------------+------+ | 1 | Sybil | 1970-04-13 | black | lutefisk,fadge,pizza | 0 | | 2 | Nancy | 1969-09-30 | white | burrito,curry,eggroll | 3 | | 3 | Ralph | 1973-11-02 | red | eggroll,pizza | 4 | | 4 | Lothair | 1963-07-04 | blue | burrito,curry | 5 | | 5 | Henry | 1965-02-14 | red | curry,fadge | 1 | | 6 | Aaron | 1968-09-17 | green | lutefisk,fadge | 1 | | 7 | Joanna | 1952-08-20 | green | lutefisk,fadge | 0 | | 8 | Stephen | 1960-05-01 | white | burrito,pizza | 0 | +----+---------+------------+-------+-----------------------+------+ 8 rows in set (0.00 sec) mysql> SELECT * FROM profile_contact ORDER BY profile_id, service; SELECT * FROM profile_contact ORDER BY profile_id, service; +------------+----------+--------------+ | profile_id | service | contact_name | +------------+----------+--------------+ | 1 | Facebook | user1-fbid | | 1 | Twitter | user1-twtrid | | 2 | Facebook | user2-msnid | | 2 | LinkedIn | user2-lnkdid | | 2 | Twitter | user2-fbrid | | 4 | LinkedIn | user4-lnkdid | +------------+----------+--------------+ 6 rows in set (0.01 sec)
- 如果我们想取得"有社交网络的用户的详细信息",那么就是一个典型的取两个表"都有
位置"的行的信息
mysql> SELECT id, name, service, contact_name FROM profile INNER JOIN profile_contact ON id = profile_id; +----+---------+----------+--------------+ | id | name | service | contact_name | +----+---------+----------+--------------+ | 1 | Sybil | Twitter | user1-twtrid | | 1 | Sybil | Facebook | user1-fbid | | 2 | Nancy | Twitter | user2-fbrid | | 2 | Nancy | Facebook | user2-msnid | | 2 | Nancy | LinkedIn | user2-lnkdid | | 4 | Lothair | LinkedIn | user4-lnkdid | +----+---------+----------+--------------+ 6 rows in set (0.00 sec)
- 和JOIN非常像的一个特性叫做subquery:
- 相同点:都是从两个(或者多个)表中取得我们需要的信息
- 不同点:JOIN是取得"两个表"共同的部分,而subquery是做一个对A表的查询,发现 WHERE信息需要从B表中找
- 下面是一个subquery的例子,我们要查找nancy的profile_contact(A表)信息,但是
profile_contact表里面没有名字,只有id,所以WHERE需要借助profile表(B表)的帮助
mysql> SELECT * FROM profile_contact WHERE profile_id = (SELECT id FROM profile WHERE name = 'Nancy'); +------------+----------+--------------+ | profile_id | service | contact_name | +------------+----------+--------------+ | 2 | Twitter | user2-fbrid | | 2 | Facebook | user2-msnid | | 2 | LinkedIn | user2-lnkdid | +------------+----------+--------------+ 3 rows in set (0.00 sec)
Selecting Rows from Beginning, End, or Middle of Query Results
Problem
- 搜索结果太多,只想要其中一部分,比如最开始20个,最后20个,从第20个到第40个等等
Solution
- 使用LIMIT, 和ORDER BY配合更好
Discussion
- LIMIT的使用是非常容易理解的,就是截取输出的一部分
mysql> SELECT * FROM profile LIMIT 1; SELECT * FROM profile LIMIT 1; +----+-------+------------+-------+----------------------+------+ | id | name | birth | color | foods | cats | +----+-------+------------+-------+----------------------+------+ | 1 | Sybil | 1970-04-13 | black | lutefisk,fadge,pizza | 0 | +----+-------+------------+-------+----------------------+------+ 1 row in set (0.01 sec) mysql> SELECT * FROM profile LIMIT 3; SELECT * FROM profile LIMIT 3; +----+-------+------------+-------+-----------------------+------+ | id | name | birth | color | foods | cats | +----+-------+------------+-------+-----------------------+------+ | 1 | Sybil | 1970-04-13 | black | lutefisk,fadge,pizza | 0 | | 2 | Nancy | 1969-09-30 | white | burrito,curry,eggroll | 3 | | 3 | Ralph | 1973-11-02 | red | eggroll,pizza | 4 | +----+-------+------------+-------+-----------------------+------+ 3 rows in set (0.01 sec)
- 但是你的"前几个"通常是"有条件的"前几个,比如生日最早的前三个
mysql> SELECT * FROM profile ORDER BY birth LIMIT 3; SELECT * FROM profile ORDER BY birth LIMIT 3; +----+---------+------------+-------+----------------+------+ | id | name | birth | color | foods | cats | +----+---------+------------+-------+----------------+------+ | 7 | Joanna | 1952-08-20 | green | lutefisk,fadge | 0 | | 8 | Stephen | 1960-05-01 | white | burrito,pizza | 0 | | 4 | Lothair | 1963-07-04 | blue | burrito,curry | 5 | +----+---------+------------+-------+----------------+------+ 3 rows in set (0.01 sec)
- ORDER BY的帮助还可以体现在,我可以从后面找,比如找生日最晚的那一个
mysql> SELECT * FROM profile ORDER BY birth DESC LIMIT 1; SELECT * FROM profile ORDER BY birth DESC LIMIT 1; +----+-------+------------+-------+---------------+------+ | id | name | birth | color | foods | cats | +----+-------+------------+-------+---------------+------+ | 3 | Ralph | 1973-11-02 | red | eggroll,pizza | 4 | +----+-------+------------+-------+---------------+------+ 1 row in set (0.01 sec)
- 而使用两个LIMIT,可以起到"从中间某个位置开始的几个值返回"的目的
mysql> SELECT * FROM profile ORDER BY birth LIMIT 2, 3; SELECT * FROM profile ORDER BY birth LIMIT 2, 3; +----+---------+------------+-------+----------------+------+ | id | name | birth | color | foods | cats | +----+---------+------------+-------+----------------+------+ | 4 | Lothair | 1963-07-04 | blue | burrito,curry | 5 | | 5 | Henry | 1965-02-14 | red | curry,fadge | 1 | | 6 | Aaron | 1968-09-17 | green | lutefisk,fadge | 1 | +----+---------+------------+-------+----------------+------+
What to Do When LIMIT Requires the "Wrong" Sort Order
Problem
- LIMIT通常和ORDER BY配合的情况下,可以得到我们想要的结果.但是这个结果的顺序 不是我们想要的.
Solution
- 把LIMIT所在的语句作为一个subquery,然后包裹这个subquery的outer query再进行 一次排序
Discussion
- 比如,我们找到数据库里面最年轻的四个人
mysql> SELECT name, birth FROM profile ORDER BY birth DESC LIMIT 4; SELECT name, birth FROM profile ORDER BY birth DESC LIMIT 4; +-------+------------+ | name | birth | +-------+------------+ | Ralph | 1973-11-02 | | Sybil | 1970-04-13 | | Nancy | 1969-09-30 | | Aaron | 1968-09-17 | +-------+------------+ 4 rows in set (0.00 sec)
- 但是本着各种各样的原因,比如尊老爱幼,我们希望把年纪最大的放在最上面.于是就
可以把LIMIT放在subquery里面用了.
mysql> SELECT * FROM (SELECT name, birth FROM profile ORDER BY birth DESC LIMIT 4) AS t ORDER BY birth; SELECT * FROM (SELECT name, birth FROM profile ORDER BY birth DESC LIMIT 4) AS t ORDER BY birth; +-------+------------+ | name | birth | +-------+------------+ | Aaron | 1968-09-17 | | Nancy | 1969-09-30 | | Sybil | 1970-04-13 | | Ralph | 1973-11-02 | +-------+------------+ 4 rows in set (0.00 sec)
Calculating LIMIT Values from Expressions
Problem
- 希望使用expressions来表达LIMIT(无法开始就确定)
Solution
- 很抱歉,你的愿望是不现实的,LIMIT必须是`literal integers`,甚至如下的简单加分
都不行
mysql> SELECT * FROM profile LIMIT 5+5; SELECT * FROM profile LIMIT 5+5; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '+5' at line 1
Chapter 4: Table Management
Cloning a Table
Problem
- 我们有一个table A,然后我们要创建一个structure和table A完全一样的table B
Solution
- 使用CREATE TABLE…LIKE
- 使用INSERT INTO…SELECT
Discussion
- 只会复制table structure
CREATE TABLE new_table LIKE mail;
- 不仅仅复制table structure,还会复制table里面的内容
INSERT INTO mail2 SELECT * FROM mail WHERE srcuser = 'barb';
Saving a Query Result in a Table
Problem
- 希望把SELECT的结果存储到table里面,而不是把结果打印出来
Solution
- 如果table存在,那么就直接INSERT INTO … SELECT
- 如果table不存在,那么就CREATE TABLE … SELECT
Creating Temporary Tables
Problem
- 你只是临时需要一个table,你希望它一会就自动消失
Solution
- 那么推荐你使用TEMPORARY关键字
Discussion
- 当然可以每次创建table,然后退出前DROP掉,但是MySQL有个特性TEMPORARY,这种特性
申请的table,都可以在当前session退出之前,自动帮你把临时table给删除掉,其使用
方式有如下:
- 和普通table一样,从明确的column定义来创建
CREATE TEMPORARY TABLE tbl_name (...column definitions...);
- 从已有的table里面创建table
CREATE TEMPORARY TABLE new_table LIKE original_table;
- 可以从result set里面开始创建table
CREATE TEMPORARY TABLE tbl_name SELECT ...;
- 和普通table一样,从明确的column定义来创建
- 因为Temporary table是session-specific的,所以,多个client可以各自创建一个名字 完全一致的temporary table
- Temporary table还可以和"已有的table"名字,完全一致!这主要是用来"hide" permanent
table,这种情况下DELETE语句删除的是temporary table里面的内容
mysql> CREATE TEMPORARY TABLE mail SELECT * FROM mail; CREATE TEMPORARY TABLE mail SELECT * FROM mail; Query OK, 16 rows affected (0.11 sec) Records: 16 Duplicates: 0 Warnings: 0 mysql> SELECT COUNT(*) FROM mail; SELECT COUNT(*) FROM mail; +----------+ | COUNT(*) | +----------+ | 16 | +----------+ 1 row in set (0.00 sec) mysql> DELETE FROM mail; DELETE FROM mail; Query OK, 16 rows affected (0.02 sec) mysql> SELECT COUNT(*) FROM mail; SELECT COUNT(*) FROM mail; +----------+ | COUNT(*) | +----------+ | 0 | +----------+ 1 row in set (0.00 sec) mysql> DROP TEMPORARY TABLE mail; DROP TEMPORARY TABLE mail; Query OK, 0 rows affected (0.02 sec) mysql> SELECT COUNT(*) FROM mail; SELECT COUNT(*) FROM mail; +----------+ | COUNT(*) | +----------+ | 16 | +----------+ 1 row in set (0.00 sec)
- 从上面的例子也可以看出DROP TEMPORARY TABLE tbl_name是"明确"删除temporary table的方法
Generating Unique Table Names
Problem
- 创建一个table,要保证其name原来不在数据库中存在
Solution
- 只有temporary table才是跟session相关的,从而可以重名,而普通的table都是不能 重名的.
- 不重名的方法,就是把client的信息加入到命名过程中
Discussion
- 比如我们把process id的信息写入到名字里面
import os tbl_name = "tmp_tbl_%d" % os.getpid()
Checking or Changing a Table Storage Engine
Problem
- 你想查看你的table使用的什么storage引擎
- 你想更改你的table的storage引擎
Solution
- storage引擎信息存储在INFORMATION_SCHEMA.TABLES里面
- 可以使用ALTER TABLE来更改存储引擎
Discussion
- 在information_schema这个数据库里面,tables这个表存储有很多的信息,就包括storage
引擎
mysql> SHOW COLUMNS FROM information_schema.tables; SHOW COLUMNS FROM information_schema.tables; +-----------------+---------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------------+---------------------+------+-----+---------+-------+ | TABLE_CATALOG | varchar(512) | NO | | | | | TABLE_SCHEMA | varchar(64) | NO | | | | | TABLE_NAME | varchar(64) | NO | | | | | TABLE_TYPE | varchar(64) | NO | | | | | ENGINE | varchar(64) | YES | | NULL | | | VERSION | bigint(21) unsigned | YES | | NULL | | | ROW_FORMAT | varchar(10) | YES | | NULL | | | TABLE_ROWS | bigint(21) unsigned | YES | | NULL | | | AVG_ROW_LENGTH | bigint(21) unsigned | YES | | NULL | | | DATA_LENGTH | bigint(21) unsigned | YES | | NULL | | | MAX_DATA_LENGTH | bigint(21) unsigned | YES | | NULL | | | INDEX_LENGTH | bigint(21) unsigned | YES | | NULL | | | DATA_FREE | bigint(21) unsigned | YES | | NULL | | | AUTO_INCREMENT | bigint(21) unsigned | YES | | NULL | | | CREATE_TIME | datetime | YES | | NULL | | | UPDATE_TIME | datetime | YES | | NULL | | | CHECK_TIME | datetime | YES | | NULL | | | TABLE_COLLATION | varchar(32) | YES | | NULL | | | CHECKSUM | bigint(21) unsigned | YES | | NULL | | | CREATE_OPTIONS | varchar(255) | YES | | NULL | | | TABLE_COMMENT | varchar(2048) | NO | | | | +-----------------+---------------------+------+-----+---------+-------+ 21 rows in set (0.00 sec)
- 我们要想看到具体哪个table的存储情况,就得如下了
mysql> SELECT engine FROM information_schema.tables WHERE table_schema = 'cookbook' AND table_name = 'mail'; SELECT engine FROM information_schema.tables WHERE table_schema = 'cookbook' AND table_name = 'mail'; +--------+ | engine | +--------+ | InnoDB | +--------+ 1 row in set (0.00 sec)
- 当然了,每次都去information_schema数据库里面查cookbook数据库里面的表的情况,
是不太正常,正常的做法是如下, SHOW TABLE STATUS,然后用LIKE起到类似grep的作用
mysql> SHOW TABLE STATUS LIKE 'mail'\G SHOW TABLE STATUS LIKE 'mail'\G *************************** 1. row *************************** Name: mail Engine: InnoDB Version: 10 Row_format: Compact Rows: 16 Avg_row_length: 1024 Data_length: 16384 Max_data_length: 0 Index_length: 16384 Data_free: 0 Auto_increment: NULL Create_time: 2016-08-24 09:15:03 Update_time: NULL Check_time: NULL Collation: latin1_swedish_ci Checksum: NULL Create_options: Comment: 1 row in set (0.00 sec)
- 还有一种方法是看如何"创建"当前table的SQL语句,从SQL创建语句里面,我们就能观
察到,原来storage engine是create table的一部分!
mysql> SHOW CREATE TABLE mail\G SHOW CREATE TABLE mail\G *************************** 1. row *************************** Table: mail Create Table: CREATE TABLE `mail` ( `t` datetime DEFAULT NULL, `srcuser` varchar(8) DEFAULT NULL, `srchost` varchar(20) DEFAULT NULL, `dstuser` varchar(8) DEFAULT NULL, `dsthost` varchar(20) DEFAULT NULL, `size` bigint(20) DEFAULT NULL, KEY `t` (`t`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
- 那也就是说,我们ALTER TABLE的时候,就可以改动storage engine
ALTER TABLE mail ENGINE = MyISAM;
Copying a Table Using mysqldump
Problem
- 希望在一个server的不同数据库,或者多个server的不同数据库之间拷贝tables
Solution
- 使用mysqldump
Discussion
- mysqldump是一个和mysql client命令行在一起的,在bash里面运行的可执行文件,最
原始的用法如下:把cookbook数据库里面的mail table导入到mail.sql文件里面
% mysqldump cookbook mail > mail.sql
- mail.sql里面就包含了CREATE TABLE和INSERT数据等,你可以在任意的其他server(或
者是本机)上面使用如下的命令来重新创建mail table
% mysql cookbook < mail.sql
- 如果是在一个server下面的不同数据库之间copy table,那么有如下几种情况:
- 把一个table拷贝到不同的数据库
% mysqldump cookbook mail > mail.sql % mysql other_db < mail.sql
- 把一个数据库里面所有的表都拷贝到另外的数据库
% mysqldump cookbook > cookbook.sql % mysql other_db < cookbook.sql
- 如果拷贝到其他数据库里面,想改名,可以使用RENAME
% mysqldump cookbook mail > mail.sql % mysql other_db < mail.sql % mysql other_db mysql > RENAME mail to mail2;
- 在同一台server上面我们甚至可以使用pipeline,而不必借助另外的sql文件
% mysqldump cookbook mail | mysql other_db % mysqldump cookbook | mysql other_db
- 把一个table拷贝到不同的数据库
- 如果是在不同的server之间传递table,那么就需要把sql文件通过网络传递,也可以使
用pipeline,但是就是麻烦了一点
mysqldump cookbook mail | mysql -h other-host.example.com other_db
Chapter 5: Working with Strings
Introduction
- 和大多数的date type一样,string value也是可以比较,和排序的.但是string有着更
多更加特殊的特性,如下:
- 一个string可以是binary的,或者是nonbinary的.Binary string是用来对付image, music file这种raw data的. Nonbinary string是用来对付text这种字符的
- 对于non binary string来说,就有不同的character set的区别.比如你用中文,那就 得用特定的character set,否则中文字符就不会被认为是nonbinary string
- 对于non binary string来说,还有collation属性来决定其如何排序
- 对于binary string来说,有如下几种data type:
- BINARY
- VARBINARY
- BLOB
- 对于nonbinary string来说,有如下几种data type, 而且每种data type都有自己的
CHARACTER SET和COLLATE属性:
- CHAR
- VARCHAR
- TEXT
String Properties
- 在mysql里面,string可以分成两大类:
- binary string: 它可以包含任何的信息,比如image, mp3, compressed data,其相 互比较的时候,就是使用`01`的二进制比较,所以其没有"文字意义",不和character set 有联系.也不需要让"人"看明白
- nonbinary string: 它就有"文字意义"了,需要
- 让人"看明白",所以要转码成各种国家的文字,而且存入的时候,还要看看当前支 不支持这个文字,其需要的属性就是character set
- 而且需要比较,进而排序.所以就需要collation属性
- 可以使用如下的方法来查看available的character set
mysql> SHOW CHARACTER SET; SHOW CHARACTER SET; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | tis620 | TIS620 Thai | tis620_thai_ci | 1 | | euckr | EUC-KR Korean | euckr_korean_ci | 2 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | utf16 | UTF-16 Unicode | utf16_general_ci | 4 | | utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | utf32 | UTF-32 Unicode | utf32_general_ci | 4 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | +----------+-----------------------------+---------------------+--------+ 40 rows in set (0.00 sec)
- mysql默认的character set是latin1,如果你需要存储多种语言文字,那么utf8,ucs2是
非常好的选择,而这两种都是multibyte character set有着不同的特点:
- utf8是varying length,每个字符可能使用1byte或者3byte来存储
- ucs2是定长的,每个字符都是2byte存储
- 如果你懂Unicode,就会知道,Unicode其实是32-bit的规范,所以utf8和ucs2其实是仅 仅包括了Basic Multilingual Plane(BMP),所以如果想包括更多,请使用utf16,utf32
- 我们原来在golang的学习中知道,utf8这种multibyte的Unicode编码,其核心思想就是用
到的字符是ASCII的,就用一个byte(大部分都是ASCII),否则则根据需要,选择增加一个
或者两三个byte来存储多余的部分,所以如果有multibyte的情况,一定是byteSize大于
字符长度.在mysql里面,分别使用如下的两个函数来判断:
- byteSize => LENGTH()
- 字符长度 => CHAR_LENGTH()
- 虽然使用了utf8编码,但是因为其是变长的,所以即便是ASCII的'abc',还是不会浪费存
储空间,还是使用了3个byte,而中文`严`,则就一个字,使用了3个byte
mysql> SET @s = CONVERT('abc' USING utf8); SET @s = CONVERT('abc' USING utf8); Query OK, 0 rows affected (0.01 sec) mysql> SELECT LENGTH(@s), CHAR_LENGTH(@s); SELECT LENGTH(@s), CHAR_LENGTH(@s); +------------+-----------------+ | LENGTH(@s) | CHAR_LENGTH(@s) | +------------+-----------------+ | 3 | 3 | +------------+-----------------+ 1 row in set (0.00 sec) mysql> SET @s2 = CONVERT('严' USING utf8); SET @s2 = CONVERT('严' USING utf8); Query OK, 0 rows affected (0.00 sec) mysql> SELECT LENGTH(@s2), CHAR_LENGTH(@s2); SELECT LENGTH(@s2), CHAR_LENGTH(@s2); +-------------+------------------+ | LENGTH(@s2) | CHAR_LENGTH(@s2) | +-------------+------------------+ | 3 | 1 | +-------------+------------------+ 1 row in set (0.01 sec)
- 而ucs编码就有点浪费时间,它所有情况下'每个字'都使用2个byte
mysql> SET @s = CONVERT('abc' USING ucs2); SET @s = CONVERT('abc' USING ucs2); Query OK, 0 rows affected (0.00 sec) mysql> SELECT LENGTH(@s), CHAR_LENGTH(@s); SELECT LENGTH(@s), CHAR_LENGTH(@s); +------------+-----------------+ | LENGTH(@s) | CHAR_LENGTH(@s) | +------------+-----------------+ | 6 | 3 | +------------+-----------------+ 1 row in set (0.00 sec)
- nonbinary string的另外一个属性是collation.使用SHOW COLLATION来查看所有
available的collation,使用LIKE来'grep'
mysql> SHOW COLLATION like 'latin1%'; SHOW COLLATION like 'latin1%'; +-------------------+---------+----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +-------------------+---------+----+---------+----------+---------+ | latin1_german1_ci | latin1 | 5 | | Yes | 1 | | latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 | | latin1_danish_ci | latin1 | 15 | | Yes | 1 | | latin1_german2_ci | latin1 | 31 | | Yes | 2 | | latin1_bin | latin1 | 47 | | Yes | 1 | | latin1_general_ci | latin1 | 48 | | Yes | 1 | | latin1_general_cs | latin1 | 49 | | Yes | 1 | | latin1_spanish_ci | latin1 | 94 | | Yes | 1 | +-------------------+---------+----+---------+----------+---------+ 8 rows in set (0.00 sec)
- 我们可以看到latin1默认的collation是latin1_swedish_ci, 这个结尾很有意思,相似
的结尾有三种:
- ci: case insensitive
- cs: case sensitive
- bin: 使用二进制的`01`去比较大小和binary string比较的方法类似
Chossing a String Data Type
Problem
- 你希望使用string data type来存储你的数据,但是你不太了解该用哪个string data type来存储
Solution
- 使用什么样的data type取决于如下的几点:
- Are the strings binary or nonbinary?
- Does case sensitivity matter?
- What is the maximum string length?
- Do you want to store fixed - or variable-length values?
- Do you need to retain trailing spaces?
- Is there a fixed set of permitted values?
Discussion
- 我们先来看看不同的data type的最大值,注意,这个最大值的单位是byte.而因为有些
nonbinary string是multibyte的,所以最大值很有可能会小于其'字符'的个数,因为
一个'字符'要用多个byte嘛
Binary data type Nonbinary data type Maximum length BINARY CHAR 255 VARBINARY VARCHAR 65535 TINYBLOB TINYTEXT 255 BLOB TEXT 65535 MEDIUMBLOB MEDIUMTEXT 16777215 LONGBLOB LONGTEXT 4294967295 - 对于BINARY和CHAR来说,一旦你设置了其大小,比如BINARY(10)或者CHAR(10)后(因为10 比255小,所以是合理值),MySQL就分配了10个byte给你,你就算用不完这个10个byte, 系统也"不会"去回收剩下的,而且全部都"填充0"!
- 注意CHAR不会保留traling space!BINARY会保留(因为对于它来说,也不知道其文字意 义)
- 对于VARBINARY,VARCHAR, BLOB和TEXT这个四种存储方式,MySQL不会去填充零(因为也 这样做的话,太浪费了)
- 前面说了CHAR是不保存"traling space"的,如果你想保存traling space,那么就请选
择VARCHAR或者TEXT,下面的例子就证明了这一点,而且可以看到存储到CHAR里面的traling
space已经被删除了
mysql> CREATE TABLE t(c1 CHAR(10), c2 VARCHAR(10)); CREATE TABLE t(c1 CHAR(10), c2 VARCHAR(10)); Query OK, 0 rows affected (0.19 sec) mysql> INSERT INTO t(c1, c2) VALUES('abc ','abc '); INSERT INTO t(c1, c2) VALUES('abc ','abc '); Query OK, 1 row affected (0.03 sec) mysql> SELECT c1, c2, CHAR_LENGTH(c1), CHAR_LENGTH(c2) FROM t; SELECT c1, c2, CHAR_LENGTH(c1), CHAR_LENGTH(c2) FROM t; +------+------------+-----------------+-----------------+ | c1 | c2 | CHAR_LENGTH(c1) | CHAR_LENGTH(c2) | +------+------------+-----------------+-----------------+ | abc | abc | 3 | 10 | +------+------------+-----------------+-----------------+ 1 row in set (0.00 sec)
- 一个table里面也可以包含两种不同的string data type,这肯定是没问题的
- 如果你不专门指出自己想使用的character set和collate的话,那么default的值就会 赋给你新建的表了,分别是latin1, latin1_swedish_ci
- 如果你设置了character set,那么那个character set默认的collate就会起作用
- 如果你设置了默认的collate,collate字符串前面的character set就会起作用.
Setting the Client Connection Character Set
Problem
- 我们的字符串不使用mysql默认的character set
Solution
- 使用SET NAMES来设置character set
Discussion
- 如果已经连接好了的话,那么使用SET NAMES来设置当前的character set, 还可以同
时设置collate
mysql> SET NAMES 'utf8'; SET NAMES 'utf8'; Query OK, 0 rows affected (0.00 sec) mysql> SET NAMES 'utf8' COLLATE 'utf8_general_ci'; SET NAMES 'utf8' COLLATE 'utf8_general_ci'; Query OK, 0 rows affected (0.00 sec)
- my.cnf里面可以设置属性来支持每一个connection的character set
[mysql] default-character-set=utf8
- 编程语言的interface(而不是使用client去更改数据库的值)是语言自己的更改数据
的方法,所以即便你对client设置了character set, 也不会对它起作用.比如JAVA连
接mysql的方法是MySQL Connector/J, 如果想使用utf8的方法连接mysql数据库那么
其connection URL应该如下
jdbc:mysql://localhost/cookbook?characterEncoding=UTF-8
Writing String Literals
Problem
- 你需要在SQL里面书写literal string
Solution
- 重点需要学习string literal在mysql里面特殊的地方
Discussion
- 在MySQL里面,单引号和双引号都是可以用来书写字符串,但是我们推荐大家使用单引 号,因为如果设置了ANSI_QUOTES模式的话,mysql会把双引号里面的内容认做是quoting 字符串(类似于python里面的''')
- 我们还可以使用hex的样式来写字符串,不过这种字符串会被认为是binary string,比
如下面三个字符串都是表示的'abcd'
0x61626364 X'61626364' x'61626364'
- 你还可以加一个"前缀"(类似python里面的u), 来表示当前的字符串的编码
_latin1 'abcd' _ucs2 'abcd'
- 对付特殊的字符串一般有如下的方法:
- 双引号,单引号嵌套
mysql> SELECT "I'm asleep", 'He said, "Boo!"'; SELECT "I'm asleep", 'He said, "Boo!"'; +------------+-----------------+ | I'm asleep | He said, "Boo!" | +------------+-----------------+ | I'm asleep | He said, "Boo!" | +------------+-----------------+ 1 row in set (0.00 sec)
- 反斜线
mysql> SELECT 'I\'m wide awake', 'path is C:\\mysql on Windows'; SELECT 'I\'m wide awake', 'path is C:\\mysql on Windows'; +----------------+-----------------------------+ | I'm wide awake | path is C:\mysql on Windows | +----------------+-----------------------------+ | I'm wide awake | path is C:\mysql on Windows | +----------------+-----------------------------+ 1 row in set (0.00 sec)
- 重复`'`,或者重复`"`
mysql> SELECT 'I''m asleep', "He said, ""Boo!"""; SELECT 'I''m asleep', "He said, ""Boo!"""; +------------+-----------------+ | I'm asleep | He said, "Boo!" | +------------+-----------------+ | I'm asleep | He said, "Boo!" | +------------+-----------------+ 1 row in set (0.00 sec)
- 还可以使用hex来写哦
mysql> SELECT 0x49276D2061736C656570; SELECT 0x49276D2061736C656570; +------------------------+ | 0x49276D2061736C656570 | +------------------------+ | I'm asleep | +------------------------+ 1 row in set (0.01 sec)
- 双引号,单引号嵌套
- TODO
Chapter 6: Working with Dates and Times
Chossing a Temporal Data Type
Problem
- 你想存储时间数据,但是不知道最合适的data type是什么
Solution
- 选择什么样的data type取决于你需要什么样的信息粒度
Discussion
- 在存储时间的时候,我们需要首先问自己如下几个问题:
- 你是只需要time,还是只需要date,还是date, time都需要
- 你的时间存储的range是多少
- 你是否希望"自动初始化"你当前的时间的column
- 对于时间,MySQL有的类型是:
- 只存储日期的DATE类型
- 只存储时间的TIME类型: 注意MySQL的时间类型的range并不是24小时,它甚至可以 小于24小时,或者大于24小时.
- 同时存储时间和日期的DATETIME, TIMESTAMP类型
- DATETIME和TIMESTAMP都是把日期和时间联合起来存储,但是它们有明显的区别:
- DATETIME支持的range是(1000-01-01 00:00:00, 9999-12-31 23:59:59)但是TIMESTAMP 的range是(1970, 2038)
- DATETIME和TIMESTAMP都有auto-initialization和auto-update的功能,但是DATETIME 直到5.6.5版本才支持这个功能
- 当client希望插入TIMESTAMP值的时候,server会把当前time zone的时间转换成UTC 存储起来, 当client希望读取TIMESTAMP值的时候,server会把UTC的时间转换成client希望的 time zone的时间,然后转回给client
- 下面就是time, date, 和datetime三种类型的表的例子
mysql> SELECT t1, t2 FROM time_val; SELECT t1, t2 FROM time_val; +----------+----------+ | t1 | t2 | +----------+----------+ | 15:00:00 | 15:00:00 | | 05:01:30 | 02:30:20 | | 12:30:20 | 17:30:45 | +----------+----------+ 3 rows in set (0.00 sec) mysql> SELECT d from date_val; SELECT d from date_val; +------------+ | d | +------------+ | 1864-02-28 | | 1900-01-15 | | 1999-12-31 | | 2000-06-04 | | 2017-03-16 | +------------+ 5 rows in set (0.00 sec) mysql> SELECT dt FROM datetime_val; SELECT dt FROM datetime_val; +---------------------+ | dt | +---------------------+ | 1970-01-01 00:00:00 | | 1999-12-31 09:00:00 | | 2000-06-04 15:45:30 | | 2017-03-16 12:30:15 | +---------------------+ 4 rows in set (0.00 sec)
Using Fractional Seconds Support
- 说白了就是mysql存储时间的粒度,可以从second上升到microsecond
- 下面例子就可以看出不同的时间粒度得到的存储值不同
mysql> SELECT CURTIME(), CURTIME(2), CURTIME(6); SELECT CURTIME(), CURTIME(2), CURTIME(6); +-----------+-------------+-----------------+ | CURTIME() | CURTIME(2) | CURTIME(6) | +-----------+-------------+-----------------+ | 22:29:51 | 22:29:51.69 | 22:29:51.691839 | +-----------+-------------+-----------------+ 1 row in set (0.00 sec)
Changin MySQL's Date Format
Problem
- 你不想使用MySQL ISO format
Solution
- 实话说,你不可以改动mysql的存储ISO format,但是可以像使用UTC一样使用ISO format
在存储时间之前,把时间的格式转换成ISO时间类型,然后存储到mysql里面,等读 取的时候再把ISO转换成你想要的时间格式
Discussion
- 创造不同的mysql的函数可以帮助我们把ISO格式转换成"各种纷繁的样式"
mysql> CREATE FUNCTION time_ampm(t TIME) -> RETURNS VARCHAR(13) # mm:dd:ss {a.m.|p.m.} format -> DETERMINISTIC -> RETURN CONCAT(LEFT(TIME_FORMAT(T, '%r'), 9), -> IF(TIME_TO_SEC(t) < 12 * 60 * 60, 'a.m.', 'p.m.')); IF(TIME_TO_SEC(t) < 12 * 60 * 60, 'a.m.', 'p.m.')); Query OK, 0 rows affected (0.01 sec) mysql> SELECT t1, time_ampm(t1) FROM time_val; SELECT t1, time_ampm(t1) FROM time_val; +----------+---------------+ | t1 | time_ampm(t1) | +----------+---------------+ | 15:00:00 | 03:00:00 p.m. | | 05:01:30 | 05:01:30 a.m. | | 12:30:20 | 12:30:20 p.m. | +----------+---------------+ 3 rows in set (0.00 sec)
Setting the Client Time Zone
Problem
- client connection的time zone和server的不一样,那么就会出现错误的UTC值的情况
Solution
- client需要在连接server以后,设置自己的time_zone
Discussion
- 我们来深入的分析一下这个问题的来源,为什么client connection的time zone要和
server一样:
- 我们先来看看server处理TIMESTAMP的过程:
- client发过来一个时间,想要存储, server检查一下client的time zone,然后把 client发过来的时间转换成UTC,然后存储起来.
- client想要取之前存储的之间,发送请求给server, server会把UTC的时间再转换 成client time zone 的时间.这样看来似乎client的time zone不太重要
- 问题出现在如果有另外一个client,比如这个client是clientAnother,它和client 不在一台机器上,在太平洋的另一端,clientAnother也想取得client存储的那个 时间, server会把UTC的时间按照clientAnother的time zone更改以后传递给 clientAnother.
- 发现问题了么? time zone 问题的本质是要求"不同的client的Time zone,要一样", 但是你要么要求所有的client使用UTC(不现实), 要么要求所有的client的time zone 使用server的time zone(比较现实)!
- 我们先来看看server处理TIMESTAMP的过程:
- 既然已经理解了为什么server的time zone是一个"标杆",那么我们就要了解如何查询
和设置server和client的time zone:
- 查询和设置server session:
mysql> SELECT @@global.time_zone; SELECT @@global.time_zone; +--------------------+ | @@global.time_zone | +--------------------+ | +06:00 | +--------------------+ 1 row in set (0.00 sec) mysql> SET @@global.time_zone = 'Asia/Shanghai'; SET @@global.time_zone = 'Asia/Shanghai'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT @@global.time_zone; SELECT @@global.time_zone; +--------------------+ | @@global.time_zone | +--------------------+ | Asia/Shanghai | +--------------------+ 1 row in set (0.00 sec)
- 查询和设置client session:
mysql> SELECT @@session.time_zone; SELECT @@session.time_zone; +---------------------+ | @@session.time_zone | +---------------------+ | +06:00 | +---------------------+ 1 row in set (0.00 sec) mysql> SET @@session.time_zone='+04:00'; SET @@session.time_zone='+04:00'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT @@session.time_zone; SELECT @@session.time_zone; +---------------------+ | @@session.time_zone | +---------------------+ | +04:00 | +---------------------+ 1 row in set (0.00 sec) mysql> SELECT @@global.time_zone, @@session.time_zone; SELECT @@global.time_zone, @@session.time_zone; +--------------------+---------------------+ | @@global.time_zone | @@session.time_zone | +--------------------+---------------------+ | Asia/Shanghai | +04:00 | +--------------------+---------------------+ 1 row in set (0.00 sec)
- 查询和设置server session:
Shifting Temporal Values Between Time Zones
Problem
- 想在mysql里面做timezone的转换
Solution
- 使用CONVERT_TZ()函数
Determining the Current Date or Time
Problem
- 希望得到当前的date和time
Solution
- 获取当前日期,世界,日期和时间的办法:
- CURDATE()
- CURTIME()
- NOW()
- 获取UTC日期,世界,日期和时间的办法:
- UTC_DATE()
- UTC_TIME()
- UTC_TIMESTAMP()
Using TIMESTAMP or DATETIME to Track Row-Modification Times
Problem
- 你想记录一行(row)数据的改动(包括第一次创建)的时间
Solution
- 使用TIMESTAMP和DATETIME的auto-initialization属性来判断创建时间
- 使用TIMESTAMP和DATETIME的auto-update属性来判断创建时间
Discussion
- auto-update 和 auto-initialization是非常重要的特性,但是由于历史原因在5.6.5 之前这个属性只支持TIMESTAMP去使用, DATETIME是没有这个属性的
- 下面是一个例子,例子中的table就是一个使用auto-update, auto-initialization的
例子
CREATE TABLE tsdemo ( val INT, ts_both TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, ts_create TIMESTAMP DEFAULT CURRENT_TIMESTAMP, ts_upddate TIMESTAMP ON UPDATE CURRENT_TIMESTAMP );
- 我们可以看到ts_create就是创建的时间戳, ts_update就是更新的时间戳, ts_both 就是创建或者更新的时间戳.
Extracting Parts of Dates or Times
Problem
- 只想知道date或者time的一部分
Solution
- 当然还是借助于mysql内置的函数
Function Return Value YEAR() Year of date MONTH() Month number DAYOFMONTH() Day of month HOUR() Hour of time MINUTE() Minute of time SECOND() Second of time
Chapter 7: Sorting Query Results
Using ORDER BY to Sort Query Results
Problem
- row返回的顺序不是你想要的
Solution
- 当然是使用ORDER BY啦
Discussion
- 最简单的ORDER BY是single-column sort
mysql> SELECT * FROM driver_log ORDER BY name; SELECT * FROM driver_log ORDER BY name; +--------+-------+------------+-------+ | rec_id | name | trav_date | miles | +--------+-------+------------+-------+ | 1 | Ben | 2014-07-30 | 152 | | 9 | Ben | 2014-08-02 | 79 | | 5 | Ben | 2014-07-29 | 131 | | 8 | Henry | 2014-08-01 | 197 | | 6 | Henry | 2014-07-26 | 115 | | 4 | Henry | 2014-07-27 | 96 | | 3 | Henry | 2014-07-29 | 300 | | 10 | Henry | 2014-07-30 | 203 | | 7 | Suzi | 2014-08-02 | 502 | | 2 | Suzi | 2014-07-29 | 391 | +--------+-------+------------+-------+ 10 rows in set (0.01 sec)
- 我们按照名字排序,默认是升序(也就是默认加了ASC在行尾), 如果想要倒序,那么我
们就要使用DESC
mysql> SELECT * FROM driver_log ORDER BY name DESC; SELECT * FROM driver_log ORDER BY name DESC; +--------+-------+------------+-------+ | rec_id | name | trav_date | miles | +--------+-------+------------+-------+ | 2 | Suzi | 2014-07-29 | 391 | | 7 | Suzi | 2014-08-02 | 502 | | 10 | Henry | 2014-07-30 | 203 | | 8 | Henry | 2014-08-01 | 197 | | 6 | Henry | 2014-07-26 | 115 | | 4 | Henry | 2014-07-27 | 96 | | 3 | Henry | 2014-07-29 | 300 | | 5 | Ben | 2014-07-29 | 131 | | 9 | Ben | 2014-08-02 | 79 | | 1 | Ben | 2014-07-30 | 152 | +--------+-------+------------+-------+ 10 rows in set (0.00 sec)
- 详细查看以后,处女座会发现name是按照名字排序了,但是trav_date在某个名字(比如 Henry里面)并不是按照什么顺序排列的,这是因为Mysql如果你不告诉它,它不会把某 列排序的.
- 处女座的福音当然是通过在ORDER BY后面加入两个column name来解决的啦
mysql> SELECT * FROM driver_log ORDER BY name, trav_date; SELECT * FROM driver_log ORDER BY name, trav_date; +--------+-------+------------+-------+ | rec_id | name | trav_date | miles | +--------+-------+------------+-------+ | 5 | Ben | 2014-07-29 | 131 | | 1 | Ben | 2014-07-30 | 152 | | 9 | Ben | 2014-08-02 | 79 | | 6 | Henry | 2014-07-26 | 115 | | 4 | Henry | 2014-07-27 | 96 | | 3 | Henry | 2014-07-29 | 300 | | 10 | Henry | 2014-07-30 | 203 | | 8 | Henry | 2014-08-01 | 197 | | 2 | Suzi | 2014-07-29 | 391 | | 7 | Suzi | 2014-08-02 | 502 | +--------+-------+------------+-------+ 10 rows in set (0.00 sec)
- 注意,如果想DESC的话,需要在每个column name后面加上DESC, 如果只加一个,那么整
体的顺序就是Mixed的状态的:有些是升序,有些是降序
mysql> SELECT * FROM driver_log ORDER BY name DESC, trav_date; SELECT * FROM driver_log ORDER BY name DESC, trav_date; +--------+-------+------------+-------+ | rec_id | name | trav_date | miles | +--------+-------+------------+-------+ | 2 | Suzi | 2014-07-29 | 391 | | 7 | Suzi | 2014-08-02 | 502 | | 6 | Henry | 2014-07-26 | 115 | | 4 | Henry | 2014-07-27 | 96 | | 3 | Henry | 2014-07-29 | 300 | | 10 | Henry | 2014-07-30 | 203 | | 8 | Henry | 2014-08-01 | 197 | | 5 | Ben | 2014-07-29 | 131 | | 1 | Ben | 2014-07-30 | 152 | | 9 | Ben | 2014-08-02 | 79 | +--------+-------+------------+-------+ 10 rows in set (0.00 sec)
- ORDER BY也是可以理解alias的
mysql> SELECT name, trav_date, miles AS distance FROM driver_log ORDER BY distance; SELECT name, trav_date, miles AS distance FROM driver_log ORDER BY distance; +-------+------------+----------+ | name | trav_date | distance | +-------+------------+----------+ | Ben | 2014-08-02 | 79 | | Henry | 2014-07-27 | 96 | | Henry | 2014-07-26 | 115 | | Ben | 2014-07-29 | 131 | | Ben | 2014-07-30 | 152 | | Henry | 2014-08-01 | 197 | | Henry | 2014-07-30 | 203 | | Henry | 2014-07-29 | 300 | | Suzi | 2014-07-29 | 391 | | Suzi | 2014-08-02 | 502 | +-------+------------+----------+ 10 rows in set (0.00 sec)
Using Expressions for Sorting
Problem
- 我们sort的顺序不是已经有的column值,而是一个公式算出来的值
Solution
- 直接把expression放到ORDER BY后面就可以
Discussion
- ORDER BY后面就可以跟公式,但是为了让公式更清晰,我们可能会使用alias,会更加的
清晰
mysql> SELECT t, srcuser, FLOOR((Size+1023)/1024) AS kilobytes FROM mail WHERE size > 50000 ORDER BY kilobytes; +---------------------+---------+-----------+ | t | srcuser | kilobytes | +---------------------+---------+-----------+ | 2014-05-11 10:15:08 | barb | 57 | | 2014-05-14 14:42:21 | barb | 96 | | 2014-05-12 12:48:13 | tricia | 191 | | 2014-05-15 10:25:52 | gene | 976 | | 2014-05-14 17:03:01 | tricia | 2339 | +---------------------+---------+-----------+ 5 rows in set (0.00 sec)
Displaying One Set of Values While Sorting by Another
Problem
- 你想安装columnX的顺序排列,但是并不想显示columnX
Solution
- 不用担心,order by后面跟的不一定需要显示
Chapter 8: Generating Summaries
Basic Summary Techniques
Problem
- 你的命令行并不能显示所有的内容,你希望"统计"一下自己的SELECT结果:
- 计算一共有多少"行"
- 判断"最大值", "最小值"
- 计算平均值
Solution
- 使用mysql内置的函数来完成这些功能.
Discussion
- 使用COUNT()来计算个数
mysql> SELECT COUNT(*) FROM driver_log; SELECT COUNT(*) FROM driver_log; +----------+ | COUNT(*) | +----------+ | 10 | +----------+ 1 row in set (0.00 sec)
- COUNT(*)这种计算数目的方式,对于MyISAM来说,是非常快的.但是对于InnoDB来说却
是灾难性的慢(特别对于大的表), 对于InnoDB来说,求其row的长度可以使用下面的语
句:
mysql> SELECT TABLE_ROWS FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA='cookbook' AND TABLE_NAME = 'states'; +------------+ | TABLE_ROWS | +------------+ | 50 | +------------+ 1 row in set (0.00 sec)
- COUNT当然也是可以有condition的,比如我们可以确定Suzi有多少天驾驶记录
mysql> SELECT COUNT(*) FROM driver_log WHERE name = 'Suzi'; +----------+ | COUNT(*) | +----------+ | 2 | +----------+ 1 row in set (0.04 sec)
- COUNT(*)是用来求总行数,但是其实COUNT还有两种妙用:
- COUNT(columnName):这个是求某个column不为空(NULL)的个数
- COUNT(expr): 这个是求expr,如果为NULL就不计算结果,如果不为NULL(下面的例子
就是设置为1),那么就累加计算结果.比如我们计算"工作日"和"休息日"的驾驶记录:
- 周末,那么DAYOFWEEK算出来要么是1, 要么是7,满足的话,就设置为1.
mysql> SELECT COUNT(IF(DAYOFWEEK(trav_date) IN (1, 7), 1, NULL)) AS 'weekend trips' FROM driver_log; +---------------+ | weekend trips | +---------------+ | 4 | +---------------+ 1 row in set (0.00 sec)
- 周中,那么DAYOFWEEK算出来只要不是1,或者7就好了.
mysql> SELECT COUNT(IF(DAYOFWEEK(trav_date) IN (1, 7), NULL, 1)) AS 'weekday trips' FROM driver_log; +---------------+ | weekday trips | +---------------+ | 6 | +---------------+ 1 row in set (0.00 sec)
- 周末,那么DAYOFWEEK算出来要么是1, 要么是7,满足的话,就设置为1.
- MIN(), MAX()函数用来取得"极值"
mysql> SELECT MIN(t) AS earliest, MAX(t) AS latest FROM mail; SELECT MIN(t) AS earliest, MAX(t) AS latest FROM mail; +---------------------+---------------------+ | earliest | latest | +---------------------+---------------------+ | 2014-05-11 10:15:08 | 2014-05-19 22:21:51 | +---------------------+---------------------+ 1 row in set (0.00 sec)
- SUM(), AVG()用来求"和值"和"平均值":
mysql> SELECT SUM(size) AS 'total traffic', AVG(size) AS 'average message size' FROM mail; SELECT SUM(size) AS 'total traffic', AVG(size) AS 'average message size' FROM mail; +---------------+----------------------+ | total traffic | average message size | +---------------+----------------------+ | 3798185 | 237386.5625 | +---------------+----------------------+ 1 row in set (0.00 sec)
- 操作数据库还有"去重"的需求,一般来说数据库里面的值,没有两行是"完全相同的",
(因为有id).但是有两行某个值相同,比如name
mysql> SELECT name FROM driver_log ORDER BY name; SELECT name FROM driver_log ORDER BY name; +-------+ | name | +-------+ | Ben | | Ben | | Ben | | Henry | | Henry | | Henry | | Henry | | Henry | | Suzi | | Suzi | +-------+ 10 rows in set (0.01 sec)
- 如果我们想"去重",那么就要用到DISTINCT
mysql> SELECT DISTINCT name FROM driver_log ORDER BY name; SELECT DISTINCT name FROM driver_log ORDER BY name; +-------+ | name | +-------+ | Ben | | Henry | | Suzi | +-------+ 3 rows in set (0.00 sec)
- DISTINCT还可以和count相互配合,得到"某列不重复"的个数
mysql> SELECT COUNT(DISTINCT name) FROM driver_log; SELECT COUNT(DISTINCT name) FROM driver_log; +----------------------+ | COUNT(DISTINCT name) | +----------------------+ | 3 | +----------------------+ 1 row in set (0.00 sec)
Creating a View to Simplify Using a Summary
Problem
- 你希望summary的创建更加便捷
Solution
- 使用view就可以做到,其原理是view就是存储一个复杂select的变量.
Discussion
- 创建view的方法如下
mysql> CREATE VIEW trip_summary_view AS -> SELECT -> COUNT(IF(DAYOFWEEK(trav_date) IN (1,7), 1, NULL)) AS weekend_trips, -> COUNT(IF(DAYOFWEEK(trav_date) IN (1,7), NULL, 1)) AS weekday_trips -> FROM driver_log; FROM driver_log; Query OK, 0 rows affected (0.02 sec) mysql> SELECT * FROM trip_summary_view; SELECT * FROM trip_summary_view; +---------------+---------------+ | weekend_trips | weekday_trips | +---------------+---------------+ | 4 | 6 | +---------------+---------------+ 1 row in set (0.00 sec)
Finding Values Associated with Minimum and Maximum Values
Problem
- 你希望知道"按照某列排序",最大值的那一行.
Solution
- 使用MIN(),或者MAX(),结合subquery. 或者,使用join
Discussion
- MIN(), MAX()确实能够找到"最大值",但是它也只能显示最大值这"一列"的数据
mysql> SELECT MAX(pop) FROM states; SELECT MAX(pop) FROM states; +----------+ | MAX(pop) | +----------+ | 37253956 | +----------+ 1 row in set (0.00 sec)
- 但是如果我想要知道"最大值"这一行的数据,那么你不能把MAX()直接放到WHERE里面
去调用,如下
mysql> SELECT name FROM states WHERE pop = MAX(pop); ERROR 1111 (HY000): Invalid use of group function
- 原因很简单,MAX()的原理是从SELECT得到的数据里面去排序,在WHERE的时候,还不知 道MAX()是多少
- 改进的方法之一是使用subquery,在subquery里面取得最大值,然后让where语句等于
这个subquery获得的最大值
mysql> SELECT pop, name FROM states WHERE pop = (SELECT MAX(pop) FROM states); SELECT pop, name FROM states WHERE pop = (SELECT MAX(pop) FROM states); +----------+------------+ | pop | name | +----------+------------+ | 37253956 | California | +----------+------------+ 1 row in set (0.01 sec)
- 改进方法之二是使用jion(创建一个临时表,然后join),看起来有点麻烦
mysql> CREATE TEMPORARY TABLE tmp SELECT MAX(pop) as maxpop FROM states; CREATE TEMPORARY TABLE tmp SELECT MAX(pop) as maxpop FROM states; Query OK, 1 row affected (0.15 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> SELECT states.* FROM states INNER JOIN tmp ON states.pop = tmp.maxpop; SELECT states.* FROM states INNER JOIN tmp ON states.pop = tmp.maxpop; +------------+--------+------------+----------+ | name | abbrev | statehood | pop | +------------+--------+------------+----------+ | California | CA | 1850-09-09 | 37253956 | +------------+--------+------------+----------+ 1 row in set (0.01 sec)
Controlling String Case Sensitivity for MIN() and MAX()
- TODO
Dividing a Summary into Subgroups
Problem
- 你希望对某一部分的row进行summary,而不是所有的row
Solution
- 使用GROUP BY把row分开
Discussion
- summary一般是对所有的row进行的,比如下面的代码是计算所有mail的个数
mysql> SELECT COUNT(*) FROM mail; SELECT COUNT(*) FROM mail; +----------+ | COUNT(*) | +----------+ | 16 | +----------+ 1 row in set (0.00 sec)
- 如果我们希望"总结"不是针对全体的,而是针对"某种类型"的,那么我们就要使用GROUP
BY
mysql> SELECT srcuser, COUNT(*) FROM mail GROUP BY srcuser; SELECT srcuser, COUNT(*) FROM mail GROUP BY srcuser; +---------+----------+ | srcuser | COUNT(*) | +---------+----------+ | barb | 3 | | gene | 6 | | phil | 5 | | tricia | 2 | +---------+----------+ 4 rows in set (0.00 sec)
- group by甚至可以有"两个"
mysql> SELECT srcuser, srchost, COUNT(*) FROM mail GROUP BY srcuser, srchost; +---------+---------+----------+ | srcuser | srchost | COUNT(*) | +---------+---------+----------+ | barb | saturn | 2 | | barb | venus | 1 | | gene | mars | 2 | | gene | saturn | 2 | | gene | venus | 2 | | phil | mars | 3 | | phil | venus | 2 | | tricia | mars | 1 | | tricia | saturn | 1 | +---------+---------+----------+ 9 rows in set (0.00 sec)
Summaries and NULL Values
Problem
- 你的summary里面,有些值是有NULL,有些是没有NULL的
Solution
- 你需要知道COUNT(*)是把NULL算进去,而COUNT(expr)是不会计算NULL值的
Discussion
- 我们先来看看一个普通的table
mysql> SELECT subject, test, score FROM expt ORDER BY subject, test; SELECT subject, test, score FROM expt ORDER BY subject, test; +---------+------+-------+ | subject | test | score | +---------+------+-------+ | Jane | A | 47 | | Jane | B | 50 | | Jane | C | NULL | | Jane | D | NULL | | Marvin | A | 52 | | Marvin | B | 45 | | Marvin | C | 53 | | Marvin | D | NULL | +---------+------+-------+ 8 rows in set (0.00 sec)
- 我们如果使用COUNT(*),那么就会把所有的都总结进去
mysql> SELECT subject, count(*) FROM expt group by subject; SELECT subject, count(*) FROM expt group by subject; +---------+----------+ | subject | count(*) | +---------+----------+ | Jane | 4 | | Marvin | 4 | +---------+----------+ 2 rows in set (0.00 sec)
- 如果我们使用COUNT(score),那么就只会总结那些没有NULL值的行
mysql> SELECT subject, count(score) FROM expt group by subject; SELECT subject, count(score) FROM expt group by subject; +---------+--------------+ | subject | count(score) | +---------+--------------+ | Jane | 2 | | Marvin | 3 | +---------+--------------+ 2 rows in set (0.00 sec)
Selecting Only Groups with Certain Characteristics
Problem
- 想统计一些行,这些行需要满足一些特点.
Solution
- 使用HAVING 语句来规避group function无法再where里面使用的问题.
Discussion
- 我们前面说过了MAX()函数是无法在where语句中使用,因为MAX是对select的结果的一
个总结.同样的原因,COUNT()函数也没法再WHERE里面使用
mysql> SELECT COUNT(*), name FROM driver_log WHERE COUNT(*) > 3 GROUP BY name; ERROR 1111 (HY000): Invalid use of group function
- HAVING就是这么一种"对Group by以后"的结果,进行筛选的语句.所以HAVING一定是在
group by之后
mysql> SELECT COUNT(*), name FROM driver_log GROUP BY name; SELECT COUNT(*), name FROM driver_log GROUP BY name; +----------+-------+ | COUNT(*) | name | +----------+-------+ | 3 | Ben | | 5 | Henry | | 2 | Suzi | +----------+-------+ 3 rows in set (0.00 sec) mysql> SELECT COUNT(*), name FROM driver_log GROUP BY name HAVING COUNT(*) > 3; SELECT COUNT(*), name FROM driver_log GROUP BY name HAVING COUNT(*) > 3; +----------+-------+ | COUNT(*) | name | +----------+-------+ | 5 | Henry | +----------+-------+ 1 row in set (0.00 sec)
Using Counts to Determine Whether Values Are Unique
Problem
- 你希望测试下table里面的值是不是unique的
Solution
- 使用HAVING和COUNT()的组合
Discussion
- 前面的DISTINCT是把重复的去掉,但是你不知道它是"原本就是一个",还是"原本有很 多个,去重之后,就剩下一个了"
- 使用COUNT和HAVING的组合就可以:
- 发现"原本就是一个"的情况
mysql> SELECT trav_date, COUNT(trav_date) FROM driver_log GROUP BY trav_date HAVING COUNT(trav_date) = 1; +------------+------------------+ | trav_date | COUNT(trav_date) | +------------+------------------+ | 2014-07-26 | 1 | | 2014-07-27 | 1 | | 2014-08-01 | 1 | +------------+------------------+ 3 rows in set (0.00 sec)
- 发现"原本不止一"的情况
mysql> SELECT trav_date, COUNT(trav_date) FROM driver_log GROUP BY trav_date HAVING COUNT(trav_date) > 1; +------------+------------------+ | trav_date | COUNT(trav_date) | +------------+------------------+ | 2014-07-29 | 3 | | 2014-07-30 | 2 | | 2014-08-02 | 2 | +------------+------------------+ 3 rows in set (0.00 sec)
- 发现"原本就是一个"的情况
Grouping By Expression Results
Problem
- 希望group by的时候,可以根据更复杂的条件
Solution
- GROUP BY后面跟expression就可以.
Discussion
- GROUP BY后面可以跟expression,下面的例子就是把expression转换成alias,然后让
GROUP BY使用. 下面例子就是查看某一天有两个以上的state加入USA的日子
mysql> SELECT -> MONTHNAME(statehood) AS month, -> DAYOFMONTH(statehood) AS day, -> COUNT(*) AS count -> FROM states GROUP BY month, day HAVING count > 1; +----------+------+-------+ | month | day | count | +----------+------+-------+ | February | 14 | 2 | | June | 1 | 2 | | March | 1 | 2 | | May | 29 | 2 | | November | 2 | 2 | +----------+------+-------+ 5 rows in set (0.00 sec)
Chapter 9: Using Stored Routines, Triggers, and Scheduled Events
Introduction
- 这一章主要讨论了下面几个部分:
- Stored functions and procedures: 这两个东西都是用来包裹代码的,被包裹的代 码是用来运行各种operation, stored function是有返回值的,比如RAND(), NOW() 而stored procedure是没有返回值的
- Triggers: 当一个table呗INSERT, UPDATE, DELETE等改变的时候会运行的object, 这个类似于rails里面的before_filter和after_filter
- Scheduled events:在预先设定的的时间执行SQL语句,这个有点像mysql的cron job
- stored program是用户设定的,但是却存储在server side的database object. 因为存 储在server端,所以这个和从client端发送SQL命令有着本质的不同
- 下面就是一个简单的获取mysql版本的例子
mysql> CREATE PROCEDURE show_version() CREATE PROCEDURE show_version() -> SELECT VERSION() AS 'MySQL Version'; SELECT VERSION() AS 'MySQL Version'; Query OK, 0 rows affected (0.01 sec) mysql> CALL cookbook.show_version(); CALL cookbook.show_version(); +---------------+ | MySQL Version | +---------------+ | 5.6.31 | +---------------+ 1 row in set (0.00 sec) Query OK, 0 rows affected (0.00 sec)
- 当然了stored program还可以是非常复杂的组成,就是需要BEGIN END
CREATE PROCEDURE show_part_of_day() BEGIN DECLARE cur_time, day_part TEXT; SET cur_time = CURTIME(); IF cur_time < '12:00:00' THEN SET day_part = 'morning'; ELSEIF cur_time = '12:00:00' THEN SET day_part = 'noon'; ELSE SET day_part = 'afternoon or night'; END IF; SELECT cur_time, day_part; END;