tcp-ip-illustrated-2nd
Table of Contents
Chapter 01: Introduction
Introduction
- 不同厂家生产的操作系统不一的计算机都可以使用TCP/IP来相互通信
Layering
- 网络协议总是被设计成许多的层次.每个层次负责一个方面的通信
- TCP/IP不仅仅是两个协议,而是一组活动在不同层次的协议的总称.
- TCP/IP通常被认为是一个四层协议, 不同层次的名字和代表协议如下:
+-----------------+ | Application | Telnet, FTP, e-mail, etc +-----------------+ | Transport | TCP, UDP +-----------------+ | Network | IP, ICMP, IGMP +-----------------+ | Link | device driver and interface card +-----------------+
- 每一层都有其特殊的任务:
- link层:也叫数据链路层, 包括操作系统中的驱动程序和驱动对应的网卡.它们合起 来处理所有的物理细节.
- network层:处理网络上的packet的活动,"路由"这个动作其实就发生在这一层.这一 层主要的协议有: IP, ICMP和IGMP
- transport层:主要为application层提供端到端的数据通信.transport层有两个重要
的协议:
- TCP: 提供端到端的"可靠(reliable)"的数据通信, 其为了保障可靠性,可能会用 到很多技术(比如数据分组, 设置超时等等). 由于在TCP协议中保证了数据的可靠 性,调用TCP的application层可以不用关心"可靠通信"的实现细节
- UDP: 提供"不可靠"的端到端的数据传输. 只是发送datagram到对方host.并不保 证对方一定能接受到.使用UDP的application层程序需要自己提供"额外的验证"来 达到数据传输的"可靠"
- application负责处理特定的应用程序的细节, 应用到TCP/IP的application有:
- 负责远程登录的Telnet
- 负责文件传输的FTP
- 负责邮件传输的SMTP
- 负责简单的网络管理的SNMP
- 假设我们有如下的两个host, 它们在同一个LAN里面,那么它们使用FTP程序传输文件的
时候,使用的协议如下所示
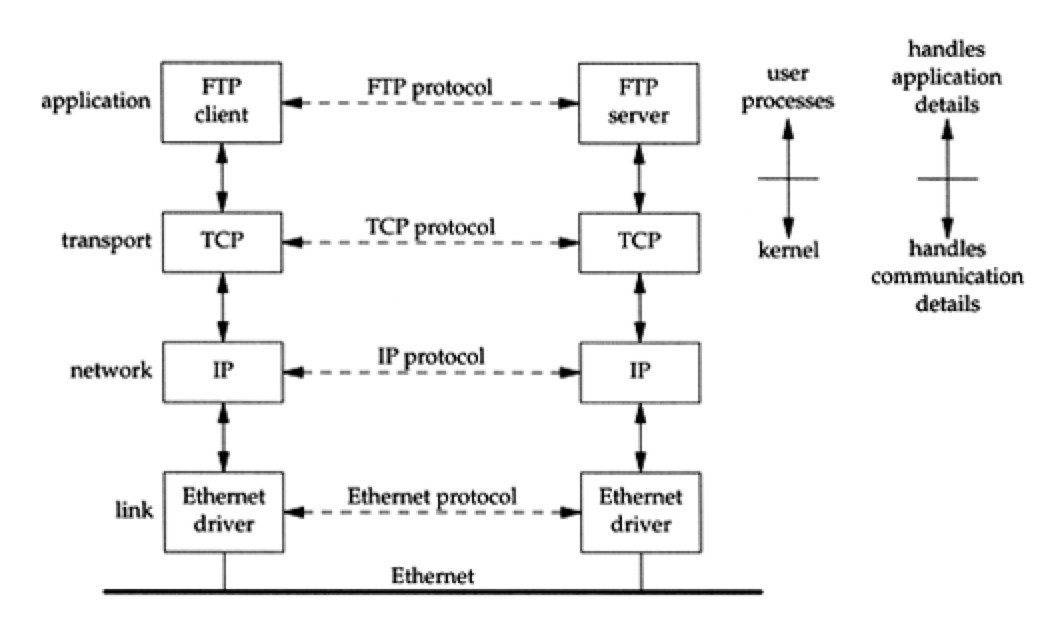
Figure 1: ftp.png
- 我们从图中可以发现:
- 每一层都会有对应的相同的协议进行通信.
- application层通常都是一个用户进程,而其他三层则都一般在kernel code里面(比 如Linux)
- application层处理process细节,而其他三层则是处理通信细节.
- link层和application层的区分非常显然:前者处理物理通信,而后者处理特定用户进程.
但是为什么要划分成network层和transport层,却不是很明显能够看出原因.需要一些
详细说明:
- 1980年代networking的迅速崛起是因为人们意识到一台电脑构成的"孤岛"没有意义, 所以有了局域网. 而1990年代,人们更是进一步的将更多的局域网联系记起来,组成 了"英特网"
- 将不同的局域网(LAN)联系起来的最好的办法是借助路由器,因为路由器可以连接两个
类型完全不同的局域网(LAN),下图就是一个通过路由器连接的两个LAN(一个是以太网,
另外一个是令牌网)里面的两个host
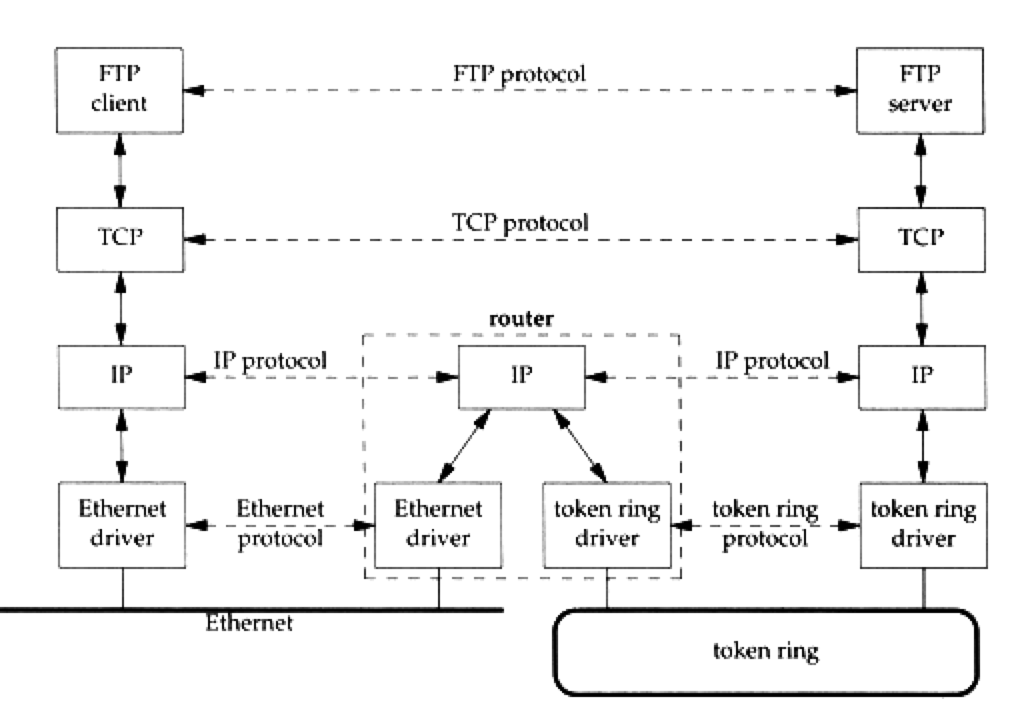
Figure 2: tcp-ip.png
- 从上图可以得到transport层和internet层必须分开的两个原因:
- 我们的FTP 客户端和FTP服务器端叫做end system. 而路由器则叫做intermediate system. 我们的TCP协议"仅仅"会被end system所使用(也就是client和server的 network层), 而我们的IP协议,则不仅仅被end system使用,还会被intermediate system所使用
- IP提供的是"不可靠"服务,它尽其所能的传输IP packet.而TCP则是通过超市重传, 发送和接受端到端的"确认分组"等机制来达到"可靠"传输的目的.所以两者的"智 能"是完全不同的.
- 下面区分两个概念:
- router(路由器)是连接两个LAN,两个LAN的类型可能不一样(一个是以太网,另一个可能是令牌网)
- bridge(网桥)是把同类的两个LAN组合成一个更大的LAN.
TCP/IP Layering
- 下图就是我们将要讨论的TCP/IP协议簇里面的协议
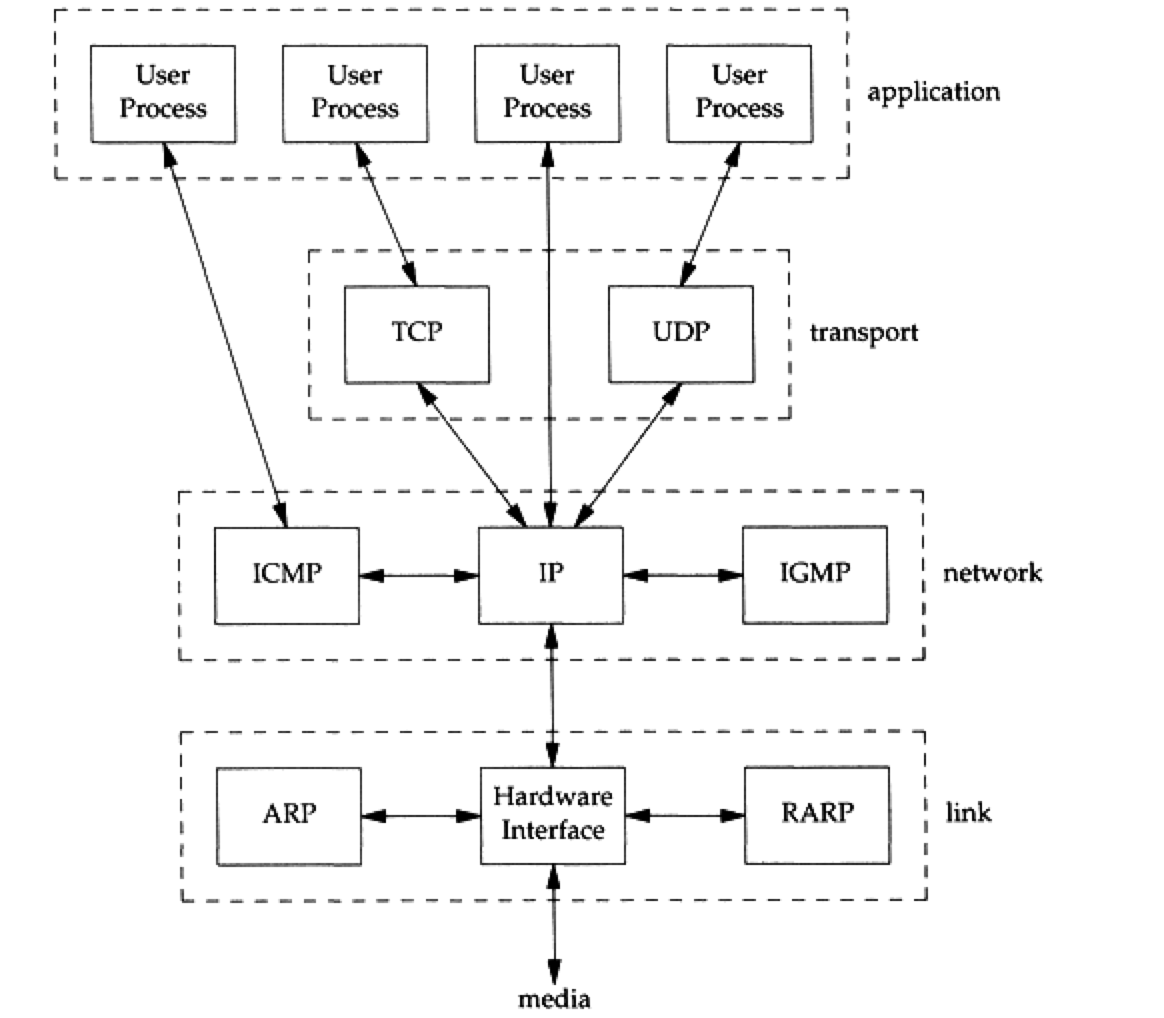
Figure 3: suite.png
- TCP和UPD是最主要的运输层协议, 它们都使用IP作为网络层协议
- IP是网络层上的主要协议,被TCP和UDP所使用.也有很少情况下用户进程会直接调用IP协议.
- ICMP是是IP的附属管理协议, IP层用来和其他IP层(可能来自其他host或者其他路由器)
交换错误报文,或者其他重要信息.应用程序可以直接使用ICMP,比较著名的两个程序是:
- Ping
- Traceroute
- IGMP被multicasting所使用: 发送一个UDP datagram到多个host.
- ARP和RARP是Link层所使用的协议,用来对IP地址和物理地址进行相互转换.
Internet Address
- 在互联网上,每个interface都必须有一个internet address(也叫IP地址).IP地址分为
五类:
7 bits 24 bits +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ A |0| netid | hostid | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ 14 bits 16 bit +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ B |1|0| netid | hostid | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ 21 bits 8 bits +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ C |1|1|0| netid | hostid | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ 28 bits +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ D |1|1|1|0| multicast group ID | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ 28 bits +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ E |1|1|1|1| reserved for future used | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ - 通常把32bit的地址每8个bit一组用dot隔开,就是常见的地址格式,而通过看第一位的
数字,就肯定可以看出这个地址属于哪一类地址.因为每类地址最开始的数字肯定是N个
1加8-N个零的组合.也就是
A => From 00000000.x.x.x = 0.x.x.x B => From 10000000.x.x.x = 2**7.x.x.x = 128.0.0.1 C => From 11000000.x.x.x = (2**7 + 2**6).x.x.x = 192.x.x.x D => From 11100000.x.x.x = (2**7 + 2**6 + 2**5).x.x.x = 224.x.x.x E => From 11110000.x.x.x = (2**7 + 2**6 + 2**5 + 2**4).x.x.x = 240.x.x.x
- 需要再次强调的是IP地址是每个网络接口一个,多接口主机就会有多个IP地址
- IP 地址不仅仅分了ABCDE五类,这五类中还会有一些的地址是做特殊用途的:
- 当前host所在网络里面的所有主机:multicast
- 某个网络里面的所有主机:broadcast
- 除了上述两种特殊用途的IP地址,其他的IP地址都是目的为单个host的制度:unicast
The Domain Name System
- 人类还是更喜欢使用英语,而不是数字来记忆网站,DNS正是这样一种分布式数据库
Encapsulation
- 当应用程序通过TCP发送网络信息的时候,从transport层开始,到link层结束,每一层都
encapsulate了一些信息.如下图
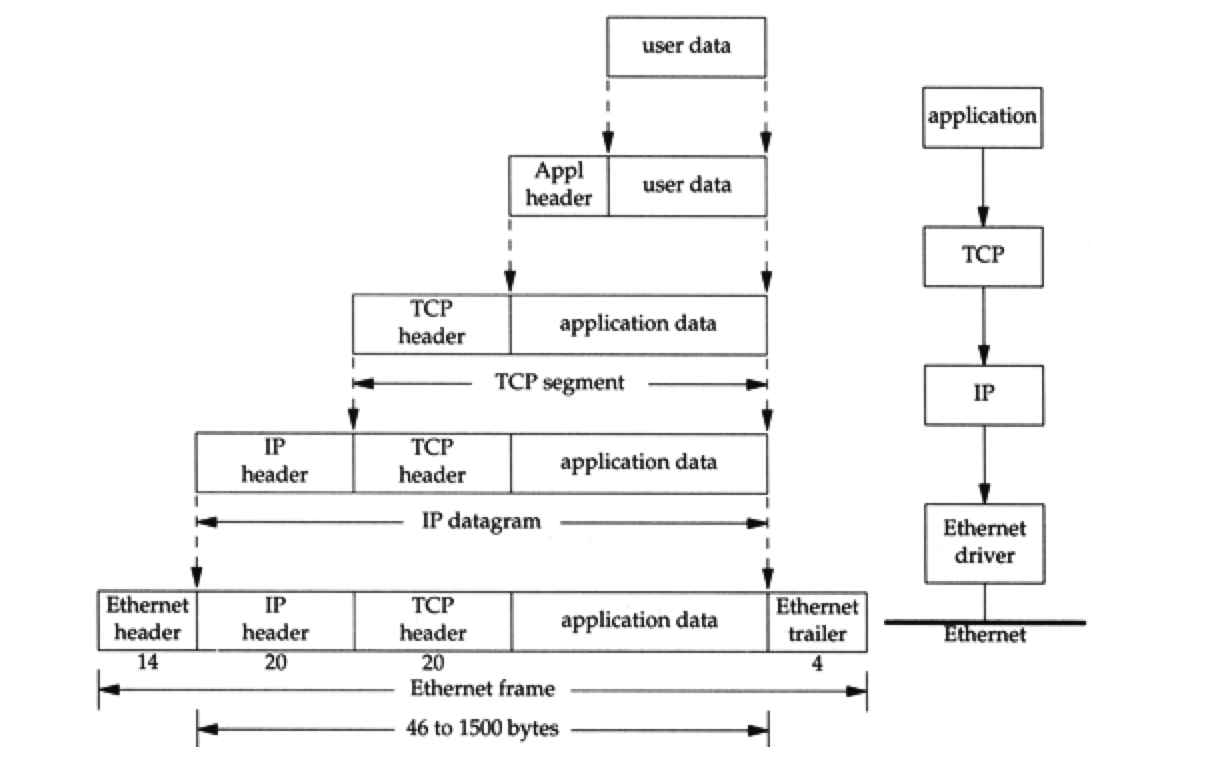
Figure 4: encapsulation.png
- 从图中我们可以看到从上到下,数据的名字发生了改变:
- TCP发送给IP的叫做TCP Segment
- IP发送给network interface的叫做IP datagram
- 在以太网上面相互传输的叫做Ethernet frame
- Ethernet的frame是在IP datagram的基础上封装了Ethernet header和Ethernet trailer
而组成的.IP datagram填充Ethernet frame的data部分,Ethernet协议规定了这个部分
的大小区间
46 bytes to 1500 bytes
- 如果我们画一个UDP的图,会和TCP的非常相似,不同的是UDP的传递给IP的数据叫做 UDP datagram.
- 我们前面写过, TCP, UDP, ICMP, IGMP都会发送数据给IP. 所以IP必须在IP header里
面添加识别信息.这个识别信息长度为8bit,在IP header里面叫做protocol field:
- ICMP 为 1
- IGMP 为2
- TCP 为 6
- UDP 为 17
- 和IP一样, TCP/UDP也必须在自己的header里面设置识别application层的信息, 也就 是识别不同的process. 这个识别信息就是port number(而且是source和destination port number)
- network interface可以为IP和ARP,RARP提供服务,它们识别IP, ARP,RARP的方法是16-bit 的 frame type field
Demultiplexing
- 和封装(encapsulation)相对的就是分用(demultiplexing): 也就是把"底层"的Ethernet
数据"层层去掉首部"然后发送给application. 如下图
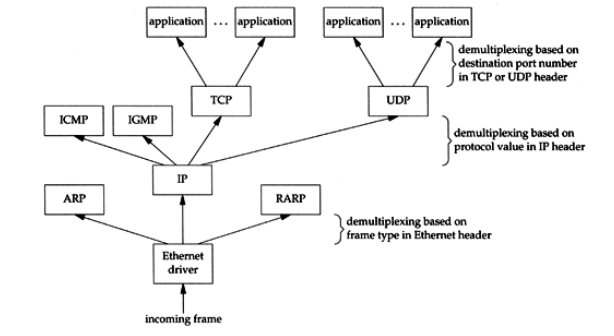
Figure 5: tti-ch1-demultiplexing.png
- 从图中我们可以看到.如果从dmultiplexing的角度讲:
- 本来在network层的IGMP和ICMP现在上移到了transport层,因为它们都是被network层 的IP协议封装的.换句话说,IGMP和ICMP和TCP/UDP的待遇一样,在IP头部中有type域 来进行标示.(ICMP为1, IGMP为2, TCP为6, UDP为17)
- 本来在link层的ARP, RARP现在上移到了network层. 因为它们都是被link层的Ethernet 协议所封装的.换句话说,ARP,RARP和IP的待遇一样,都是在Ethernet头部有type域来 进行标示(0800为IP, 0806为ARP, 0835为RARP)
Client-Server Model
- 大部分网络应用都自然的把通信的两端设置为一端为client,另一端为server. server 为client提供某种服务.
- 而根据server端是否能同时处理多个client请求,把server分成两种:
- iterative server:每次只能处理一个client请求
- concurrent server:通过把任务分配给另外一个process(或者thread), 可以同时处理多个client请求
- 在大多数情况下TCP server是一concurrent的,而UDP server是iterative的
Port Numbers
- 我们说过,TCP和UDP区分不同application的方法是port number. 它们的header中都有 一个16bit的field来存储这个port number(也就是0~65535)
- 对于port number的态度, client和server也是有所不同的:
- 某个应用的server端口的number相对固定:
- 如果是多种操作系统都支持的Internet-wide应用,一般server端的端口通常在1~255
- 如果仅仅是Unix系统中支持的Unix-specific应用,一般server端的端口通常在256~1023
- 某个应用的client端口的选择是每次都不一样的,所以会从1024~5000里面随便选择一 个数字,这个端口号也叫ephemeral port
- 某个应用的server端口的number相对固定:
- 大于5000的端口号会用作不太著名的应用
- 在大部分的Unix系统中, /etc/services都会保留well-known的 number和使用它的应用
之间的对应关系
% grep domain /etc/services domain 53/udp # Domain Name Server uses UDP port 53 domain 53/tcp # Domain Name Server uses TCP port 53
- Unix有一种概念叫做reserved port.就是把1到1023之间的某个port指定为自己使用,只 有superuser权限的process才有指定reserved port的权利.
Standardization Process
- TCP的标准化机构有:
- ISOC
- IAB
- IETF
- IRTF
RFCs
- internet community的正式规范或者重要信息都是以RFC的方式出版.
Standard, Simple Services
- 一些常用的application和端口号对应如下
Name TCP port UDP port RFC Description echo 7 7 862 Server returns whaetever the client sends discard 9 9 863 Server discards whatever thec client sends daytime 13 13 867 Server returns time and date chargen 19 9 864 TCP sends continual stream of characters, until the connection is terminated by client. UDP sends a datagram containing a random number of characters each time client sends a datagram time 37 37 868 Server return the number of seconds from 1900
The Internet
- 小写internet指多个LAN连起来, 首字母大写Internet指整个互联网
Implementations
Application Programming Interfaces
- 网络编程主要由两种API, socket和TLI, 后者已被淘汰
Chapter 02: Link Layer
Introduction
Ethernet and IEEE 802 Encapsulation
- Ethernet(以太网)是1982年DEC,Intel,施乐公司联合发明的一个协议.是当今世界上事 实上的默认LAN协议.
- 以太网的核心技术是CSMA/CD也就是
Carrier Sense, Multiple Access with Collision Detection 带冲突检测的载波侦听多路接入
- 事情的复杂性在于IEEE提供了一系列和Ethernet协议不太相同的规范, 为了区分,我们
把他们分别称作:
- Ethernet协议 (当今世界事实上的标准)
- IEEE 802协议
- 在TCP/IP的世界里面,IP datagram也有两个不同的RFC来对应Link层的不同协议:
- Ethernet协议的IP datagram: RFC894(也是当今世界事实上的标准)
- IEEE 802协议的IP datagram: RFC1042
- 下图就是Ethernet协议和IEEE 802两个标准对应的图
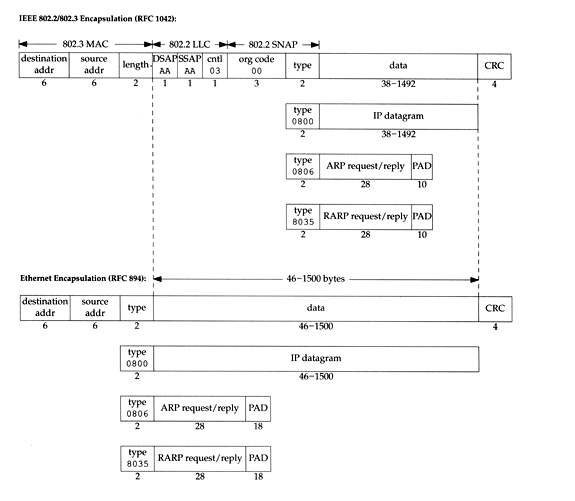
Figure 6: ch2-ethernet-ieee802.png
- 从图中我们可以发现:
- 两个协议都使用了48bit的源地址和目的地址. 这个48bit的地址就是我们常说的硬 件地址(hardware address): ARP和RARP就是用来将32bit IP地址以及48bit硬件地 址进行相互转换的
- 两个48bit地址之后的2个byte,对于不同协议解释不同:
- Ethernet协议: 用作type: 表明接下来的network层数据的类型:
- 0800: IP datagram
- 0806: ARP request/reply
- 0835: RARP request/reply
- IEEE 802协议里面: 用做length. 幸运的是这个length最大为1500bytes, 而network 层最小的表示IP datagram的type是0x0800(也就是32768)bytes. 所以我们可以通 过这两位来分辨不同的协议.
- Ethernet协议: 用作type: 表明接下来的network层数据的类型:
- 再两个byte后:
- Ethernet协议:就是数据部分了
- IEEE 802协议:还有两个部分的数据:
- 3 byte的802.2 LLC
- 5 byte的802.2 SNAP(其中最后一个部分是和Ethernet协议一样的type)
- 两种协议最后都是CRC的校验码
- 对两种协议来说,都有最小长度的要求, 如果data部分没那么多,需要填充到零来达
到最小长度:
- Ethernet协议: 46bytes
- IEEE 802协议: 38bytes
Trailer Encapsulation
- 尾部封装是已经被淘汰的技术,我们不再进行讨论
SLIP: Serial Line IP
- SLIP也是被PPP协议所取代的过时技术,我们不再讨论
Compressed SLIP
- 压缩SLIP的技术.不讨论
PPP: Point-to-Point Protocol
- PPP协议是Point-to-Point协议的简称, 其功能和SLIP相同:都是在串行链路上面传输 IP datagram.当使用电话线来接入互联网的时候,在电话线这种串行链路上面传输IP datagram的任务,就交给了PPP.
- PPP优于SLIP的地方有很多,主要的是除了IP协议,还支持其他协议,所以可以用来初始化 线路,并且做用户验证.
Loopback Interface
- 大部分的操作系统中,会支持一个叫做loopback interface的接口.让本机的client和 server application在本机内部相互通信.
- 一般来说,都会使用A类地址里面的127.0.0.1来作为环回地址
- 如果以IP datagram的目的地址是loopback interface,那么它只能存在于本机,绝无可 能出现在任何网络的传输里面!
- 一般我们都会想到,如果transport层检测到了IP地址为127.0.0.1.那么剩下的部分transport
层的工作和全部的network层的工作.都可以省略.但是实际的实现却不是这样:实际的
实现是在"封装"的过程中即便检测到目的IP为127.0.0.1也是会继续封装. 目的为127.0.0.1
的IP datagram也会形成.只不过,这个IP datagram不会传给Link层,而是返回给了network
层. 下图是loopback工作的模式图
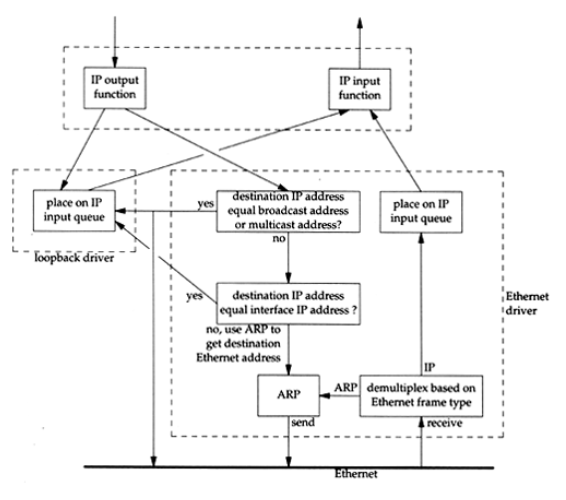
Figure 7: tti-ch2-loopback.png
- 从上图中,我们可以得到如下结论:
- 从本机发送到loopback interface地址(127.0.0.1)的datagram都要进入loopback driver 的ip input queue
- 从本机发送到multicast和boardcast的datagram在放入Ethernet之前,也要放入一个 到loopback driver的ip input queue
- 从本机发送到本机任意一个interface的datagram(一个机器可能有多个interface) 也是发送到loopback driver的ip input queue
- 看起来loopback这种走完transport层和network层的做法效率不是很高.但是它却极大
的简化了设计. loopback driver(实际上是个软件)可以看做是一种特殊的link层driver
只不过:
- 其他link层driver(比如Ethernet Driver)是往Ethernet层发送数据
- 而我们的link层driver(也就是loopback driver)是往ip input queue发送数据
MTU
- 前面我们介绍link层的时候,都介绍了data的大小有限制.具体来说:
- Ethernet协议: 1500 bytes
- IEEE 802协议: 1492 bytes
- 链路层协议限制数据大小的这个特性叫做MTU(Maximum Transmission Unit). 每种Link
层协议的MTU不同
Network MTU(bytes token ring (IBM) 17814 FDDI 4352 Ethernet 1500 IEEE 802.3/802.2 1492 Point-to-Point(low delay) 296 - IP datagram的大小如果超过了MTU的限制,那么就要进行分片(fragmentation)操作.
- MTU的大小设计通常是为了权衡1通信效率和2传输延迟而选取的值.
Path MTU
- 如果两台机器在同一个网络中通信,那么MTU比较重要.如果两个机器的通信要通过多个 不同的网络,那么重要的就是这多个网络MTU里面最小的那个MTU.
- 由于A到B的路由和B到A的路由可能不同,所以两个方向上的MTU也不一定一样.
Chapter 03: IP: Internet Protocol
Introduction
- IP是TCP/IP协议簇里面最重要的协议,TCP,UDP,ICMP,IGMP都是包裹成IP datagram然后 在网络上传输的.
- 但是IP协议却是一个unreliable的协议: 它会尽自己最大努力去传输. 如果遇到实在
是传输不过去的情况(比如中间的路由坏了),那么它的处理方式简洁而有效:
- 丢弃当前的datagram
- 发送ICMP message给source
- 如果你需要reliable的协议,那么需要IP上层的TCP协议来保证.
- 我们把IP协议称作是connectionless的,意思是IP协议并不会去保留任何关于后续其他 datagram是否成功等信息.因为每个datagram都是独立传输的(路径也有可能不同),所以 发送的时候序列是A先B后,但是最后收到的时候,可能是B先A后.
IP Header
- 下图就是一个典型的IP datagram,header, 其大小(在没有选项字段的情况下, 也就是
大小最小的情况下)为20bytes
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 Unit: bit +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |version|length | TOS | total length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | identification |flags| fragment offset | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | time to live | protocol | header checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | source IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | destination IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | | options(multiple of 32 bits) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 需要注意的是左边的version是较小的地址,同时,也放置了most significant bit(值 为1不为0的话,越往左,值越大),所以对于IP datagram来说(其实其他网络数据也一样), 它们都是big-endian的布局.
- 为了让大家忘记big, little等"模糊"的名称,我们把big endian称之为network order, 每个数据在传输之前,一定要先转换成network order.
- 好了,我们下面来一一看看header里面各个域的作用:
- version:标示IP协议的版本,普遍使用的是版本4
- length: 其实是header length的缩写,其代表的是整个header在单位为32-bit word
情况下的长度.因为这个域为4个bit,所以header length最长为 60bytes, 如果没有
option,那么这个域内容就是20 / (32 / 8) = 5
(2**3 + 2**2 + 2**1 + 2**0) * (32 / 8) = 60 bytes
- TOS:Type of Service为8个bit, 其中:
- 3个bit为precedence field(已经弃用)
- 4个bit位TOS: 分别为(同时只能有其中一个bit被设置), 都不设置为normal service:
- minimize delay
- maximize throughput
- maximize reliability
- minimize monetary cost
- 1个bit没有使用
- total length:就是整个ip datagram的长度啦,单位是bytes,由于这个字段是16bit 那么ip datagram的最大值就是2**16 - 1 = 65535.但是没有人会发送这么大的字段 因为link层由于MTU的存在,如果有这么大的datagram, 大多数的link层协议会对它 进行分片(fragment).为了照顾大多数的link层协议,一般规定ip datagram最大不要 超过576,这不是一个硬性的规定,但是大多数情况下适用.
- total length这个域很重要,因为link层的好多协议,比如Ethernet对其fragment大小 有个最低要求,是46bytes.但是IP datagram可能不到46bytes,所以link层的协议要 pad(填充0)到最小的46bytes.这个时候,必须知道total length的值才知道IP datagram 的大小
- identification:每发送一个datagram就加1, BSD的实现是kernel来加1,也就是说TCP 发送了123,那么紧接着发送的UDP就发送了124(虽然UDP也发送124也没有关系的)
- flag:用来控制fragment, 一共三个bit:
- bit 0: 保留,必须是零
- bit 1: DF (Don't Forget) : 设置了以后,这个datagram就不被允许进行fragment, 如果你实在要fragment,那么这个datagram就只有丢弃
- bit 2: MF (More Fragments) : 被分片的前N-1个fragment都要设置这个域,说 明我们在被fragment
- fragment offset:
- TTL: time-to-live,可以经过的router的个数(一般为32或者64),每经过一个router, 就会减一,一旦到零,这个域就被抛弃了(然后会发送IGMP给sender)
- protocol: 用来标示上一层的协议
- header checksum: 仅仅用来对IP头部进行校验. 接收端checksum计算结果不符的话, 会把datagram直接丢弃(但并不会发送ICMP给发送方,这就需要上层协议发现少了datagram 后要求发送端重发)
- IP address: 后面是两个32-bit的source和destination IP address
- options: 固定header后面是一系列不常用的options,大小是32bit的整数倍.
IP Routing
- IP 路由寻找destination,在如下两种情况下是非常简单的:
- 目的地址和本机是通过PPP(point-to-point)连接的
- 目的地址和本级在一个局域网内(以太网或者令牌网)
- 如果不符合以上两种情况,那么datagram都会发送数据到一个指定的路由器,让这个路 由器去处理剩下的工作.
- 其实每一台路由器只不过是配置比较低的host而已,所以host配置成一个路由器毫无压
力,我们从理论上区分路由器和host的地方是
A host never forwards datagrams from one of its interfaces to another, while a router forwards datagrams.
- 换句话说,IP层在路由器和host上面都有,但是host上面的IP层不应该再做转发的工作.
- 我们来看看IP层的工作流程:当本机(host或者router)从某个网口接受到一个datagram
的时候,IP层首先来检查目的地址的IP是不是本机的"IP地址之一",或者是本机的广播地
址"之一":
- 如果是的话,这个IP datagram就会交由其header里面的protocol指定的协议(比如TCP 或者UDP)模块去处理
- 如果不是的话:
- 如果IP层所在的机器是配置成路由功能的(router),那么就"通过路由表"转发这 个datagram
- 如果IP层所在是机器是配置成host功能的,那么就直接丢弃这个datagram
- 上面说了,如果IP层所在机器是配置成路由器功能的话,它需要知道这个datagram要"转
发"到哪里去,依靠的是路由表.路由表有下面几个字段:
- Destination IP address: IP层寻找处理datagram的方法第一个关心的问题肯定是
"如何对付某个IP", 这个"某个IP"就是这里标示的.表示"某个IP"有两种方法:
- 完整的IP地址. network address + host address,能够"精确"匹配一个"某IP"
- 只有network address, host address则全是0. 比如192.168.188.0(这种地址叫 做"默认路由",代表这个一个network address全体成员,所以不能分配给某个host)
- IP address of a next-hop router: IP层寻找处理datagram的方法再匹配到"某IP"
以后,肯定是想知道对于"某IP"的datagram,我要"forward"到哪里?这个forward到的
地方肯定和本网络相互connect."而且"这个网络可以引导我们走向最终的目的地址.
但是这个forward到的地方也有两种情况:
- forward到另外一个router
- forward到一个host (PPP协议通常会直接forward到某个主机)
- Flags: 我们前面说过两次不同的情况, 都需要这里的flag来标示:
- 一个是在destination ip address项里面写的是完整host地址,还是某个network 地址.
- 一个是在next-hop router项里面,forward到了另外一个router还是另外一个host
- network interface: router一般有很多网口,这次的转发要从哪个网口走需要从这里 指定
- Destination IP address: IP层寻找处理datagram的方法第一个关心的问题肯定是
"如何对付某个IP", 这个"某个IP"就是这里标示的.表示"某个IP"有两种方法:
- 在了解了路由表以后,我们来看看IP路由的过程:
- 首先当然是查询路由表,希望目的IP能够完全对应的,比如路由表里面地址是192.168
.188.123,我们datagram目的IP也是这个地址,那么:
- 如果next-hop是一个router,就发送到这个router
- 如果next-hop是一个ip地址,这种情况发生在PPP协议连接的情况下,路由表的下 一步是一个IP地址
- 如果没有完全对应,那么我们就寻找把我们datagram ip地址的网络地址取出来,然后
去路由表里面,寻找网络地址相同的item.对于192.168.188.123来说,就是去寻找路
由表中192.168.188.0这个network adddress.如果找到也是:
- 如果next-hop是一个router,就发送到这个router
- 如果next-hop是一个ip地址,这种情况发生在PPP协议连接的情况下,路由表的下 一步是一个IP地址
- 前两项都失败的情况下,通常都会有个叫default的item, 把datagram发送到datagram 指引下的next-hop router(这次肯定是router,而不可能是主机)
- 首先当然是查询路由表,希望目的IP能够完全对应的,比如路由表里面地址是192.168
.188.123,我们datagram目的IP也是这个地址,那么:
- 如果上面的三个步骤都失败的话,那么这个datagram就是undeliverable的,这种情况下 就要发送"host unreachable"或者"network unreachable"错误到source IP.
- 默认路由:也就是主机地址都为0的地址(比如192.168.188.0)代表了这个网络上的所有 的主机,只用了第一个ip地址.这极大的减小了路由表的规模
Example
- 我们先来看下面的例子
destination +---------+ +---------+ network | bsdi | | sun | 140.252.13.0 | | | | +----+----+ +---------+ .13.35| .13.33 ^ | | | | -----------+--------------------------------------------------------------------------+----- | Ethernet, 140.252.13 | | | | | | +--------------------------+---------------------+------------+ | +-->| link header | IP header | +--------+ | Enet of 140.252.13.33 | 140.25.13.33 | | +--------------------------+---------------------+------------+ - 主机bsdi有一个ip datagram发送给主机sun,其过程如下:
- bsdi的ip层从某个上层收到datagram以后,搜索路由表发现目的IP地址(140.252.13.33) 在一个直接相连的局域网(以太网)上.这种情况下,可以直接通过mac(物理地址进行传递)
- datagram被传送到以太网驱动程序,然后做为一个以太网frame:
- IP header的目的地址还是140.25.133.33
- Ethernet header里面的mac地址是通过ARP协议得到的对方网卡的地址
- 这是一个简单的例子,复杂的例子中Ethernet header里面的mac地址是next-hop的mac 地址,但是IP header里面的目的地址永远都不会变.
Subnet Addressin
- subnet是对原有IP地址分类的一种补充:因为A类和B类地址里面的host ID太多了(分别 是2**24-2和2**16-2, 全0的的为默认路由,全1的为boardcast地址),用户不会在一个 局域网里面连接这么多的host.
- 那么subnet的原理也就很简单了:在host ID里面划出一部分作为network ID
- 通常都是local admin来决定从host ID中划出多少作为subnet ID,因为B类地址比较常
见,我们以B类地址为例:通常是划出8个bit作为subnetID.说通常是因为这不是一定的.
只是8个bit作为subnetID的话,读写起来比较容易(和C类地址就很像了)
14 bits 8 bit +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ B |1|0| netId | subnetId | hostId | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ - 子网这种设置,对于外部路由器来说,是transparent(无法察觉到的),比如一个B类地址
140.252:
- 对于所有在这个B类地址之外的路由,都只是把它当做一个普通的B类地址而已
- 对于所有在这个B类地址之内的路由,就要了解它是如何分配子网的了.不然无法发送 datagram到正确的位置.
- 相比于30个C类地址,用一个包含30个C类地址的B类地址的好处,是可以极大的缩小Internet 路由表的规模.
Subnet Mask
- 一般来说host的IP地址都是存在某个文件里面,然后开机读取的.对于无盘工作站获取IP 地址的方法在第五章讲解
- 前面介绍了子网的概念,子网说白了就是从hostId里面划出一部分做为subNetId,到底 划出多少bit作为subNetId,是依靠子网掩码来实现的
- 子网掩码是一种"前面是1,后面是0"的二进制数. 1的部分就是Network和SubNetwork的
Id,而后面0则是hostId,下图就是两种划分subnet的方式
14 bits 8 bit 8 bit +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Class B |1|0| netId | subnetId | hostId | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Subnet mask 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 = 255.255.255.0 14 bits 10 bit 6 bit +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Class B |1|0| netId | subnetId | hostId | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Subnet mask 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 = 255.255.255.192 - 有了子网掩码并且"知道自己IP"的情况下,一个host就可以判断一个IP datagram是来
自:
- a host on its own subnet.
- a host on a different subnet on its own network.
- a host on a different network.
- "知道自己的IP"也很重要,因为知道IP的情况下,才能判断自己是A,B,C类地址的哪一类 (从开始的几个bit来判断), 才能知道networkId和hostId的边界,从而确定subnetId和 hostId的边界.
- 下面举一个例子,比如我们host本机的ip地址为140.252.1.1, 然后我们的子网掩码是
255.255.255.0:
- 如果目的地址的IP为140.252.4.5,那么我们知道这个networkID地址是一样的,但是subnetID不一样
- 如果目的地址的IP为140.252.1.22,那么不仅仅networkID一样,subnetID也是一样的
- 如果目的地址是192.43.235.6,那么networkID不一样,subnetID也不一样
Special Case IP Address
- IP地址的特殊性还在于,它们保留了一些特殊的IP地址:0表示全部为0, -1表示全部为1,
空表示这个域没有设置
netID subnetID hostID Description Can be source or destination 0 0 this host on this net only Source 0 hostID specified host on this net only Source 127 anything loopback address Either Source or Destination -1 -1 limited broadcast(never forwarded) only Destination netid -1 net-directed broadcast to netid only Destination netid subnetid -1 subnet-directed broadcast to netid, subnetid only Destination netid -1 -1 all-subnets-directed broadcast to netid only Destination
A Subnet Example
- TODO
ifconfig Command
- 是用来显示计算机网卡信息的命令
vagrant@vagrant:~$ ifconfig eth0 Link encap:Ethernet HWaddr 08:00:27:49:73:4d inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fe49:734d/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:544 errors:0 dropped:0 overruns:0 frame:0 TX packets:423 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:64434 (64.4 KB) TX bytes:50869 (50.8 KB) eth1 Link encap:Ethernet HWaddr 08:00:27:06:18:18 inet addr:10.58.67.184 Bcast:10.58.67.255 Mask:255.255.254.0 inet6 addr: fe80::a00:27ff:fe06:1818/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:516 errors:0 dropped:0 overruns:0 frame:0 TX packets:20 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:61654 (61.6 KB) TX bytes:2664 (2.6 KB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:80 errors:0 dropped:0 overruns:0 frame:0 TX packets:80 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:6480 (6.4 KB) TX bytes:6480 (6.4 KB)
netstat Command
- 也可以使用netstat来查看interface的情况
vagrant@vagrant:~$ netstat -i Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 673 0 0 0 536 0 0 0 BMRU eth1 1500 0 2782 0 0 0 20 0 0 0 BMRU lo 65536 0 80 0 0 0 80 0 0 0 LRU
Chapter 04: ARP: Address Resolution Protocol
Introduction
- IP 地址只是对TCP/IP协议簇的协议才能理解,而我们真正要传输的层为link层,协议通 常为以太网或者令牌网协议,它们只有一个48-bit的物理地址,对32-bit的IP地址毫不 知情
- 而将IP地址转化为物理地址的协议就是ARP
An Example
- 我们来看一个ftp的例子
% ftp bsdi
- 上面的例子会以如下的步骤在网络上进行:
- ftp程序内部会调用函数gethostbyname把主机名bsdi转化成IP地址,这个过程通常 使用DNS,或者/etc/hosts来做到的
- ftp程序请求建立到bsdi的IP地址的连接请求
- TCP会发送一个request segment到remote host, 然后这个segment会被包装成一个 IP datagram
- 如果目的主机在local network,那么它会直接被发送到目的主机,否则则会发送到 一个路由器
- 假设目的主机在local network上面,那么我们只需要知道对方的物理地址,就可以 直接通过以太网协议发送这个数据了.ARP要来负责找到物理地址
- ARP是发送一个叫做ARP request的Ethernet frame给local network的每一个host ARP request包含了目的主机的IP地址,然后它的意义是"如果你是这个IP地址的拥有 者,请回答你的硬件地址"
- 目的主机收到ARP request,就把主机的物理地址和IP地址发送一个ARP reply给发 送方.
- 收到ARP reply之后, 刚才待发的IP datagram就可以发送了
- PPP协议不使用ARP,在建立PPP的时候就必须配置两端的IP地址
ARP Cache
- ARP并不是每次都会去广播一遍,它会维护一个cache列表,这个列表的值每20分钟更新
一遍. 使用arp -a可以看到这些cache
bsdi % arp -a sun (140.252.13.33) at 8:0:20:3:f6:42
ARP Packet Format
- ARP其实不仅仅可以解析IP地址,其实如果有其他XP地址,ARP也有可能是可以解析的,只 不过IP是事实上的标准,所以ARP看起来像是只解析IP
- ARP也不仅仅可以使用在以太网上,也是因为以太网是事实的标准,所以我们下面来看看
ARP在以太网frame上面的布局
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Ethernet | Ethernet | Misc settings | sender |sender | target |target | | dest addr| sour addr | | Ether addr|IP addr| Ether addr|IP addr| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ <--Ethernet header -----><-----28byte ARP request/reply----------------------------->
- 我们发现ARP使用了Ethernet frame,但是其信息有重复,比如source ethernet addr和 sender ethernet addr是一个意思.dest ethernet addr和target sender ethrnet addr是一个意思.
Chapter 05: RARP: Reverse Address Resolution Protocol
Introduction
- 对于有硬盘的host来说,其自己的ip地址可以记录在本机硬盘的config file里面,在开 机的时候读取就可以了.
- 对于"无盘工作站"来说,就需要其他的获取其自身IP地址的方法. 而RARP最开始就是为 了这种需求而设计的.
RARP Packet Format
- 对于RARP来说,其packet和ARP packet是基本相同的,不同的只是:
- 其frame type是0x8035用来表示其为一个RARP packet
- RARP request的op为3
- RARP reply的op为4
- 和ARP一样的是, RARP request也是一个ethernet的广播,而RARP reply是一个单播(unicast)
Chapter 06: ICMP: Internet Control Message Protocol
Introduction
- ICMP通常被认为是IP layer的一部分,通常包含一些错误或者通知类的信息
- ICMP通常被IP层或者更高的TCP&UDP层使用
- ICMP通常利用IP datagram来进行传输,如下图
<-------------------- IP datagram ------------------------> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | IP header(20 bytes) | ICMP message | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- ICMP message部分的分布如下
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | 8-bit type | 8-bit code | 16-bit checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | | contents depends on type and code | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- type有15种之多,每个type又可能通过code的不同来区分.