unix-network-programming-3rd
Table of Contents
- Chapter 01: Introduction
- Chapter 2: The Transport Layer: TCP, UPD, and SCTP
- Chapter 3: Sockets Introduction
- Chapter 4: Elementary TCP Sockets
- Chapter 5: TCP Client/Server Example
- Introduction
- TCP Echo Server: main Function
- TCP Echo Server: str_echo Function
- TCP Echo Client: main Function
- TCP Echo Client: str_cli Function
- Normal Startup
- Normal Termination
- POSIX Signal Handling
- Handling SIGCHLD Signals
- wait and waitpid Function
- Connetion Abort before accept Returns
- Termination of Server Processs
- SIGPIPE Signal
- Crashing of Server Host
- Crashing and Rebooting of Server Host
- Shutdown of Server Host
- Summary of TCP Example
- Data format
- Chapter 6: I/O Multiplexing: The select and poll Functions
- Chapter 7: Socket Options
- Socket Options
- Introduction
- getsockopt and setsockopt Function
- Checking if an Option Is Supported and Obtaining the Default
- Socket States
- Generic Socket Options
- SO_BROADCAST Socket Option
- SO_DEBUG Socket Option
- SO_DONTROUTE Socket Option
- SO_ERROR Socket Option
- SO_KEEPALIVE Socket Option
- SO_LINGER Socket Option
- SO_OOBINLINE Socket Option
- SO_RECVBUF and SO_SNDBUF Socket Option
- SO_RECVLOWAT and SO_SENDLOWAT Socket Option
- SO_RCVTIMEO and SO_SNDTIMEO Socket Options
- SO_REUSEDADDR and SO_REUSEPORT Socket Options
- SO_TYPE Socket Option
- SO_USELOOPBACK Socket Option
- IPv4 Socket Options
- ICMPv6 Socket Option
- IPv6 Socket Options
- TCP Socket Options
- SCTP Socket Options
- fcntl Function
- Chapter 8: Elementary UDP Socket
Chapter 01: Introduction
Introduction
- Web server是长期运行的程序, 而Web client(比如浏览器)就是发出请求的程序.
- 一般来说,都是client端发送请求, 也有异步回调(asynchronous callback)通信,是 server端先发起的.
A Simple Daytime Client
- 下面是一个简单的请求时间和日期的client
/*************************/ /* intro/daytimectpcli.c */ /*************************/ include "unp.h" int main(int argc, char *argv[]) { int sockfd; int n; char recvline[MAXLINE + 1]; struct sockadr_in servaddr; if (argc != 2) { err_quit("usage: a.out <IPaddress>"); } if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) { err_sys("socket error"); } bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_port = htons(13); /* daytime server port */ if (inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0) { err_quit("inet_pton error for %s", argv[1]); } /**********************************************/ /* in unp.h, #define SA to be struct sockaddr */ /**********************************************/ if (connect(sockfd, (SA *) &servaddr, sizeof(servaddr)) < 0) { err_sys("connect error"); } while ((n = read(sockfd, recvline, MAXLINE)) > 0) { recvline[n] = 0; if (fputs(recvline, stdout) == EOF) { err_sys("fputs error"); } } if (n < 0) { err_sys("read error"); } return 0; }
- 使用方法:
~/test/unpbook/intro$ ./daytimetcpcli 127.0.0.1 Wed Nov 20 14:33:08 2013
- socket 函数创建一个socket, 其返回参数为sockfd, 其参数为AF_INET表示为IPv4, SOCK_STREAM表示为TCP socket
- 后面我们就创建一个socket的数据结构(类型为struct sockadr_in), 我们使用bzero 这个函数把整个数据结构全部清零.
- servaddr(类型为struct sockadr_in)是整个函数的重点, 在用bzero清零以后,后面
是给他的每个部分赋值的过程
- sin_family
- sin_port
- 使用inet_pton函数把一个AF_INET类型ip地址, 转换成合适的格式,然后赋值给sin_addr
- connect函数通过第二个参数来知道要连接哪个地址(第三个长度起辅助作用),然后把server 返回的结果都返回给第一个参数.
- 这个时候我们会发现一个有趣的问题, connect调用的时候,强制把struct sockadr_in
转换成了SA(struct sockaddr), 这两个address区别如下:
- sockaddr: 操作系统使用的数据结构, 使用14个字节表示sa_data
struct sockaddr { unsigned short sa_family; // 2 bytes address family, AF_xxx char sa_data[14]; // 14 bytes of protocol address };
- sockadr_in: 程序员使用的数据结构, 把14个字节细分成了port, addr和填充的空白
(为了和sockaddr对齐), 在sockaddr_in导入connect函数的时候,需要使用(SA*)来
强制转换类型(这也是为什么要填充8字节的空白的原因)
struct sockaddr_in { short sin_family; // 2 bytes e.g. AF_INET, AF_INET6 unsigned short sin_port; // 2 bytes e.g. htons(3490) struct in_addr sin_addr; // 4 bytes see struct in_addr, below char sin_zero[8]; // 8 bytes zero this if you want to }; struct in_addr { unsigned long s_addr; // 4 bytes load with inet_pton() };
- sockaddr: 操作系统使用的数据结构, 使用14个字节表示sa_data
- 通过read函数来读取connect带来的结果. daytime server的返回值都是26个bytes, 但是根据网络情况的不同,这些bytes可能通过不同数量的TCP segment返回., 所以我们得 用while来接收.然后把recvline最后一个赋值成0 (因为TCP里面的字符串不是c语言字符串, 没有以NULL结尾)
Protocol Independence
- 我们上面的例子使用的是IPV4的IP地址, 如果使用IPV6的IP地址,那么就用sockaddr_in6 替换上面例子的sockaddr_in
- 同时AF_INET ==> AF_INET6
- sin_family ==> sin6_port
- sin_port ==> sin6_port
- sin_addr ==> sin6_addr
Error Handling: Wrapper Function
- 老是测试返回值是不是0,太麻烦了,所以设计了wrapper function,特点是另外设计一些函数
首字母大写,里面测试返回值是不是0, 我们以socket函数为例.
sockfd = socket(AF_INET, SOCK_STREAM, 0); int Socket(int family, int type, int protocol) { int n; if ((n = socket(family, type, protocol)) < 0) { err_sys("socket error"); } return (n); }
- 在Unix函数里面如果出现了错误, 那么一个全局变量errno就会被设置成一个正数, 同时函数返回 负数-1. 我们的err_sys函数就是通过查看errno,并且打印error错误
A Simple Daytime Server
- 我们再来看看server端如何写:
/**************************/ /* intro/daytimetcpsrv.c */ /**************************/ #include "unp.h" #include <time.h> int main(int argc, char *argv[]) { int listenfd; int connfd; char buff[MAXLINE]; time_t ticks; listenfd = Socket(AF_INET, SOCK_STREAM, 0); bzeros(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(13); /* daytime server port */ Bind(listenfd, (SA*) &servaddr, siezeof(servaddr)); /**********************************************************/ /* LISTENQ is from unp.h, it specifies the maximum number */ /* of client connections that kernel will queue for this */ /* listening descriptor */ /**********************************************************/ Listen(listenfd, LISTENQ); for ( ; ;) { connfd = Accept(listenfd, (SA*)NULL, NULL); ticks = time(NULL); snprintf(buff, sizeof(buff), "%.24s\n\n", ctime(&ticks)); Write(connfd, buff, strlen(buff)); Close(connfd); } return 0; }
- Socket函数首先建立一个socket
- bzeros初始化socket的数据结构servaddr, 然后给各部分赋值, 和client程序一样, sin_family和sin_port被赋了AF_INET和htons(13)
- 而sin_addr.s_addr在client是仅仅赋值了目标server的值(通过a.out的第二个参数得到), 这里却赋值INADDR_ANY, 这是为了让server接受来自本机任意一个网卡的数据(因为一个host 可能有多个网卡)
- client的socket数据结构赋值完之后,就是connect,然后read, server的操作要多一点
- server端和client的connect相似的命令是bind: 都是把socket和socket数据结构联系 起来
- bind之后,就用listen函数,就把一个socket变成了listening socket
- TCP使用的是三次握手协议来建立连接, accept函数返回的时候,就是三次握手成功完成的时候, accept函数的返回值是一个新的descriptor,叫做connected descriptor. server会同时 接受多个client的请求,server会给每个client一个connected descriptor
- 时间经过字符串处理以后,通过Write发送给connfd
Chapter 2: The Transport Layer: TCP, UPD, and SCTP
Introduction
The Big Picture
- tcpdump: 是一个直接与datalink沟通的工具, Linux下面其实还有一种socket与 datalink练习的socket,叫做SOCK_PACKET
- traceroute: 用了两个sockets: 一个是IP,另一个是ICMP
- SCTP: 是一个新的网络协议, 可以用IPv4或者IPv6
- ICMP: 处理错误和控制信息
- IGMP: 处理multicasting的,已经不怎么用了
- ARP: IP地址–>MAC地址
- RARP: MAC地址–>IP地址
- ICMPv6: 是IPv6里面全面替代ICMPv4, IGMP, 以及ARP
User Datagram Protocol (UDP)
- UDP是网络层协议, 不能保证传输的成功,因为它没有保证传输可靠性的方法, 需要 应用层来保证
- TCP是一个byte-stream的协议,没有任何边界的概念, 但是UDP有,每个UDP都有长度, 都会最后传输给对方
- UDP比较自由,不要维护relation, 它可以发送一个socket给serverA, 然后马上发送 同一个socket给serverB.
Transmission Control Protocol (TCP)
- TCP提供了传输的可靠性: 并不是说用TCP一定能把数据传输给对方, 而是如果能传输数据 就传输,如果传输不成功,也能报错.
- TCP还有自己的算法来计算RTT(round-trip time) : 也就是client和server之间的 传输一次的时间.
- RTT这个时间是根据当前网络状况和距离而设定的, 并且是不停计算的
- TCP还会记录序列, 发送的时候可能序列是123, 到达的时候就乱了.接收方的TCP 会把所有 的TCP segment重新排列(如果有收到重传的segment,也会智能丢弃).
- TCP还提供流量控制: TCP一直告诉对方自己能够接受多少的数据,这叫advertised window.
- 这个windows就是接收方能够提供的最大的内存空间.这个数字是不停改变的,刚接受来肯定 数字变小, 处理一会肯定数字变大. 窗口数字也是可以变成0的,如果接收方处理不过来,当然 要停止你的传输
- TCP是全双工的,也就是说,传输是双方向的,并不是叫server就不接受,叫client就不发送. 当然某个方向的传输停止也是可以自由决定的.
Stream Control Transmission Protocol (SCTP)
- SCTP提供了一种client和server之间的association, 之所以叫association而不是叫 connection是因为:因为connection是两个IP之间的联系,而SCTP是两个系统之间的联系 不仅仅是两个IP
- 在消息传递上面,SCTP更像UDP,它把每个记录的长度都传输给了对方
- SCTP支持两个端之间的多个stream, 其中一个stream如果丢失了一个数据的话,不会影响 其他stream. 这个和TCP不一样,TCP一个byte丢失就要影响以后的传输(因为要重新排序)
- SCTP特性还有:单个SCTP端点支持多个IP地址. TCP也可以在其他路由协议的支持下获得 这种特性
TCP Connection Establishment and Termination
- TCP建立连接的时候通常有如下的过程:
- 服务器必须首先准备好, 通过socket, bind和listen这三个函数,我们把这三个函数的 过程叫:被动打开(passive open)
- 客户端自然就是主动打开(active open) : 客户发送一个没有数据的SYN segment, 里面只有一个序列号, 就是三次握手建立以后客户端发送的第一个数据的序号(假设为J)
- 服务器必须确认(ACK)序号为J的SYN, 同时发送自己在这次握手后发送的第一个数据的 序号(假设为K), 这个ACK和SYN都是在一个segment中发送的
- 客户端要确认服务器的序号为K的SYN
- 因为 2,3,4三步中要有三个segment才能完成连接的建立,所以这个过程叫做三次握手
- 三次握手图解, 我们可以看到ACK返回的是J+1这是因为SYN本身会占用一个序列号, J是当前
序列号,那么等连接建立,下次发送的就是J+1了
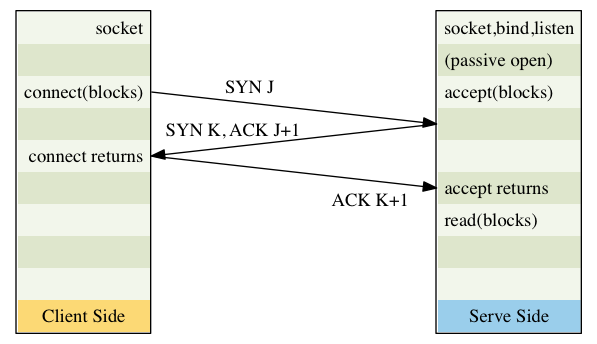
Figure 1: three-way.png
TCP Options
- MSS: 在传输SYN的同时,发送自己的最大segment的大小(Maximum Segment Size)
- Windows scale: TCP向对方展示的最大窗口数目为65535(相应的头部只有16bit), 但是 现在的网络速度要远远大于这个数目, 所以需要一个新的参数Windows scale来成倍扩展 窗口大小. scale是0到14,表示窗口数目左移多少位最大窗口数目现在是1GB(65535*2^14)
- Windows scale是一个新的选项,老的TCP实现不支持,所以只有client发送了这个选项, 并且对方server回应了这个选项,我们才能使用. 同样的,server端只有在client发给了 你这个选项,你才能回应这个选择.
- Timestamp: 这个选项对于高速传输时可能产生的数据破坏修复(比如迟到的segment,重复的 segment)很有意义.
TCP Connection Termination
- 建立一个连接需要三次握手, 终止一个连接则需要四次挥手:
- 某个应用(服务器端或者客户端都可以, 全双工嘛,两边都一样)首先调用close, 我们称之为 主动关闭(active close). 这边的TCP主动发送一个FIN segment,表示自己传完了
- 接受到FIN的对端执行被动关闭(passive close), 这个FIN会被TCP确认(发送一个ACK) 同时还会把收到FIN的消息(在当前所有数据之后,加上EOF的方式)传送给上层应用程序
- 过了一段时间以后,刚才接受FIN的端,也没有啥东西可传了,就会发送自己的FIN给对方
- 对方TCP接受到这个最后的FIN之后,也会发送一个ACK给对方确认的.
- 四次挥手只是"最多四次", 有些情况下用不了四次:
- 上面的1FIN可能随着数据一块发过去
- 上面的2ACK,3FIN可能会在一个segment发过来
- 上面2和3之间, 被动关闭的那一端还是可以传数据给主动关闭那一端的,只是反过来不行了, 这个叫做半关闭(half close)
- TCP四次挥手图解(close()可以释放FIN,同时exit或者非正常中断也会发送)
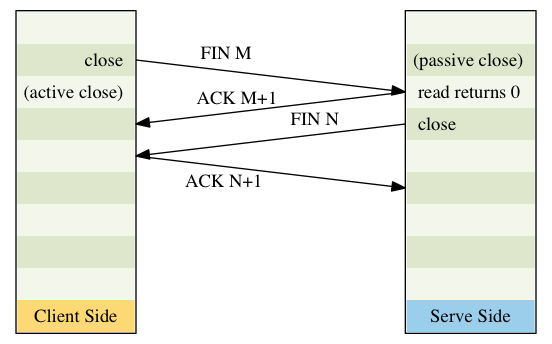
Figure 2: four-way.png
TCP State Transitiion Diagram
- 如下的为TCP的状态转换图—为客户端,===为服务器端
starting point +------------+<==========================================================+ | CLOSED |=====================================+ | +-----+------+ appl:active open | ^ | appl:passive open send:SYN v | v send:nothing | ^ recv:SYN send:SYN,ACK +------------+ v | +-------------------------------------| LISTEN | | ^ | +=================================>+------------+ | | v | recv:RST v ^ +------------+ recv:SYN +------------+ appl:close | | SYN_RECVD |<===========================================================================| SYN_SENT |=============>+ +------+-----+ send:SYN, ACK +-----+------+ or timeout | send: | recv:ACK [[simultaneous open]] recv:SYN, ACK | ^ nothing| +==================+ | | | send:ACK ^ | +------------+<=================+ +------------+ | +------------------------------------>| ESTABLISHED|------------------------------>| CLOSE_WAIT | ^ +------------+ recv:FIN send:ACK +------------+ | appl:close send:FIN | |appl:close ^ +===========================================+ |send:FIN | | | ^ v [[simultaneous close]] v | +------------+ recv:FIN send:ACK +------------+ +------------+ recv:ACK ^ | FIN_WAIT_1 |==============================>| CLOSING | |LAST_ACK |------------->+ +------+-----+==========+ +-----+------+ +------------+ send:nothing | | | | ^ v recv ACK |recv:FIN, ACK | recv:ACK | | send nothing |send:ACK | send:nothing ^ v | | | +------------+ +===================>+-----+------+ 2*MSL timeout ^ | FIN_WAIT_2 |==============================>| TIME_WAIT |==========================================================>+ +------------+ recv:FIN send:ACK +------------+ - 上面的各种state就是netstat能够显示的状态,其中有两种很少见的情况我们从没有讨论过:
- 同时打开(simulataneous open) : 两端几乎同时发送SYN
- 同时关闭(simulataneous close): 两端几乎同时发送FIN
Watcing the Packets
- 我们把客户端和服务器都在一起考虑,就会得到下面的图例
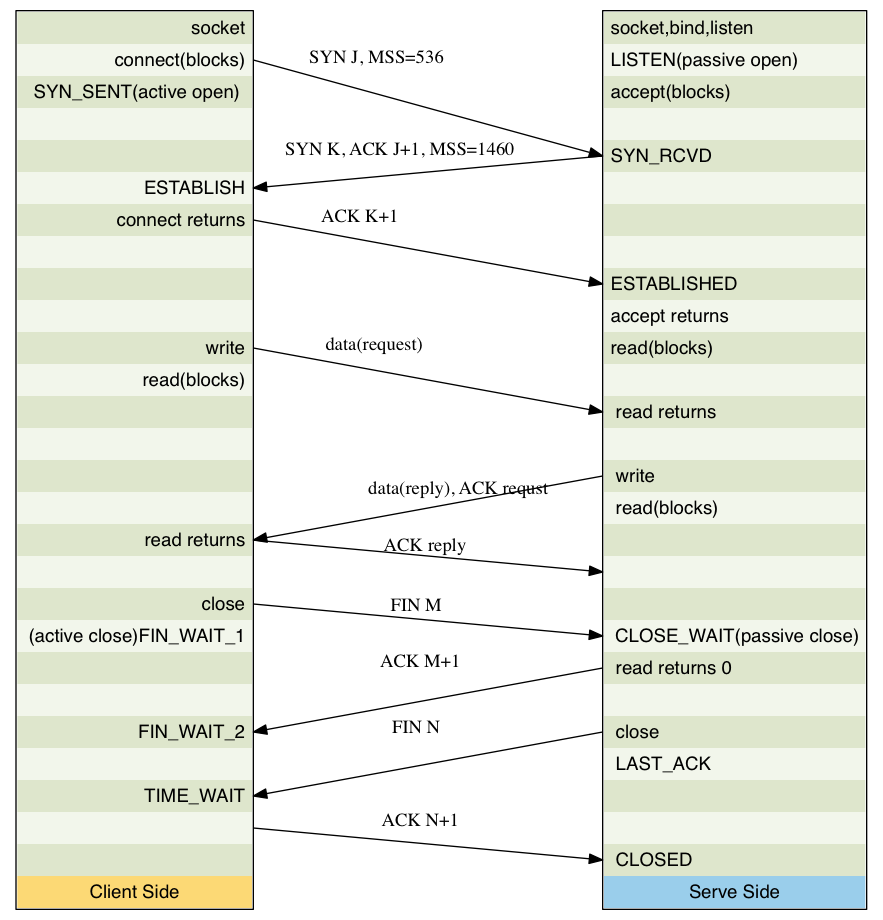
Figure 3: three-four-way.png
- 客户端的MSS是536,而服务器是1460, 两边的窗口不一样大是没问题的
- 上面传输数据的时候,服务器的对客户端数据请求的应答,是和数据一块传给客户端的 ,这个叫做piggybacking(捎带应答), 这个是因为server在200ms以内就处理了请求, 所以第一个返回的segment里面就ACK了request, 如果时间太久,那就会让segment 先走,在后面的segment里面来ACK
- 发起主动关闭(active close)的端(这里是客户端)最后进入了TIME_WAIT,因为它要 保证最后一个ACK(N+1)丢失了能够重发,所以要等待2MS的时间
TIME_WAIT State
- 在上图中最令人迷惑的状态就是TIME_WAIT, 它要经过两倍的MSL(maximum segment lifetime)的时间才能转成关闭状态
- 我们先来看看MSL,他是一个ip数据报能够在网络上存活的时间,ip数据报有一个跳跃 极限(hop limit): hop字段的长度为255bit,也就是说ip在路由器间传递超过255次 就自动被丢弃了(有可能有循环产生).
- 根据前面的背景知识,我们至少有两个理由来维持两倍的MSL:
- 假设我们在12.106.32.254:1500 和206.168.112.219:21之间建立了一个TCP 连接,之后关闭它. 过一段时间后,我们用同样的IP和端口对再建立一次连接, 后 一个连接称之为前一个连接的化身(incarnation), TCP必须避免新的连接受到老 的连接重复分组(lost duplicate, 也就是超时重传后,丢失的又通过路由修复 传回来了)的干扰,我们设置了两倍MSL,保证老的重复分组已经在网络上丢弃了
- 我们上一节说道了主动close的客户端会保留TIME_WAIT长达2MS的时间,因为如果 最后一个ACK(N+1)丢失了的话,server端超市会重发FIN(N), 客户端要保证自己 还在这个connection, 然后重新发送ACK(N+1)
Chapter 3: Sockets Introduction
Introduction
- socket address structure是最基础的socket数据结构,通常有两个方向的传递:
- 从process到内核
- 从内核到process
- 在网络上传递的数据必须是binary, text类型是网络地址转换成binary的形式,使用的
函数是下面两个:
- inet_addr & inet_ntoa (for IPv4)
- inet_pton & inet_ntop (for IPv4 and IPv6)
Socket Address Structure
- 不同的协议都有自己的socket结构体, 以sockaddr_开头,加上不同的字符串以区别协议
IPv4 Socket Address Structure
- IPv4 socket address structure, 一般叫做"Internet socket address structure"
在<netinet/in.h>里面创建了一个叫做sockaddr_in的数据结构
struct in_addr { in_addr_t s_addr; /* 32-bit IPv4 address */ /* network byte ordered */ }; struct sockaddr_in { uint8_t sin_len; /* length of structure (16) */ sa_family_t sin_family; /* AF_INET */ in_port_t sin_port; /* 16-bit TCP or UDP port number */ /* network byte ordered */ struct in_addr sin_addr; /* 32-bit IPv4 address */ /* network byte ordered */ char sin_zero[8]; /* unused */ };
- 这个例子中有如下需要了解的:
- sin_len是后加上去的,之前最开始的成员变量是sin_family (unsigned short). 因 为来的晚,所以不是所有的实现都支持它
- uint8_t是Unsigned 8-bit integer
- len虽然列在这里,但是我们用来不去设置或者使用它(唯一的例外是我们处理routing socket 的时候)
- 有四个函数把socket address structure从进程拷贝到kernerl,他们是bind, connect, sendto, sendmsg. 他们四个都是通过sockargs函数, 而sockargs函数,则会设置sin_len. 不幸的是,sockargs是Berkeley的实现方法,其他实现有没有设置这个sin_len就无法判断了, 但是IPv6确是明确要求设置SIN6_LEN这个域的
- POSIX规范只要求了sin_family, sin_port和sin_addr,但是所有的实现都加上了sin_zero 这样所有的socket address structure都至少有16 bytes
- TCP UDP的 port number和IP地址都必须是用网络比特顺序存储的(network byte order)
- 因为我们的IP地址在这里是使用了in_addr这个结构体,所以一个IP地址的表示就有
两种方式, 如下(serv表示一个sockaddr_in类型数据):
- serv.sin_addr.s_addr 是 in_addr_t类型的IP地址(通常就是unsigned 32-bit integer)
- serv.sin_addr是 struct in_addr类型的IP地址
- 历史上struct in_addr的设计比这个复杂,里面曾经可以通过union的成 员让, A类, B类地址来取得自己的网络部分, 随着subnet的出现, struct in_addr 就开始只有一个成员变量啦
- sin_zero全部都是零.
- socket address structure是每个host有自己的,相互之间不交流的. 虽然某些数 据,比如sin_addr用来指导数据交换
Generic Socket Address Structure
- socket address structure总是以pass by reference的方式传入到socket function 当中去的,但是问题是socket function要处理多种协议,而每种协议都有自己的socket address structure.
- 放到1989年以后,我们可以使用void* 来指代所有的指针. 但是socket function诞生于1982
年.所以它不得不为所有的socket address structure创造了一个generic 的socket address
structure.
struct sockaddr { uint8_t sa_len; sa_family_t sa_family; /* address family: AF_xxx value */ char sa_data[14]; /* protocol-specific address */ };
- 我们可以看到多有的socket function都是用的generic的socket address structure
作为其函数的参数的
int bind(int, struct sockaddr*, socklen_t);
- generic指针的坏处就是每次某个协议的socket address structure一定要进行一次
类型转换(casting)
struct socketaddr_in serv; /* IPv4 socket address structure */ /* fill in serv{} */ bind(sockfd, (struct sockaddr *)&serv, sizeof(serv));
IPv6 Socket Address Structure
- IPv6在<netinet/in.h>里面定义了自己的socket address structure
struct in6_addr { uint8_t s6_addr[16]; /* 128-bit IPv6 address */ /* network byte ordered */ }; #define SIN6_LEN /* required for compile-time tests */ struct sockaddr_in6 { uint8_t sin6_len; /* length of this struct (28) */ sa_family_t sin6_family; /* AF_INET6 */ in_port_t sin6_port; /* transport layer port# */ /* network byte ordered */ uint32_t sin6_flowinfo; /* flow information, undefined */ struct in6_addr sin6_addr; /* IPv6 address */ /* network byte ordered */ uint32_t sin6_scope_id; /* set of interfaces for a scope */ };
- 上面例子需要了解的是:
- 如果系统支持socket address structure的长度, 那么就要设置SIN6_LEN
- 这个布局是惊喜设计的,可以达到64-bit aligned的效果,在64位处理器上效果好
- sin6_flowinfo分成两部分:
- low-order 20 bits 是 flow lable
- high-order 13 bits是保留字
- sin6_scope_id用来指示scope zone
New Generic Socket Address Structure
- 为了迎合新的IPv6协议,一个新的generic socket address structure也就设计出来了
struct sockaddr_storage { uint8_t ss_len; /* length of this struct (implementation dependent) */ sa_family_t ss_family; /* address family: AF_xxx value */ /*******************************************************************/ /* implementation-dependent elements to provide: */ /* a) alignment sufficient to fulfill the alignment requirement of */ /* all socket address types that the system supports */ /* b) enough storage to hold any type of socket address that the */ /* system supports */ /*******************************************************************/ };
Comparison of Socket Address Structures
- 下面用一个图来对比所有的socket address structure
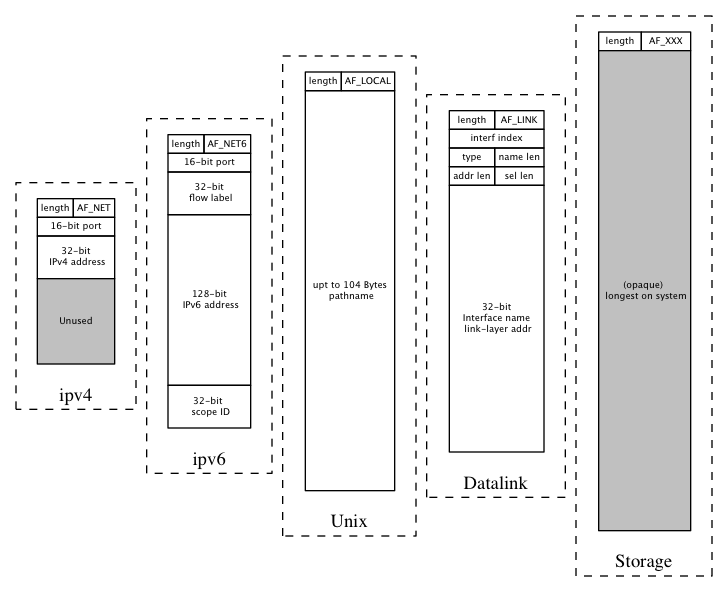
Figure 4: socket-address-structure.png
- 我们原来总是看到socket函数的第三个参数为socket address structures的size,比
如第一章的例子中(如下). 如果length field 不是在4.3BSD reno中引入,而是第一个
版本(设计bind的时候)就引入, 那么,我们可能就不需要每次都多加一个参数了
Bind(listenfd, (SA*) &servaddr, siezeof(servaddr));
Value-Result Arguments
- 我们刚才已经讨论过了socket address structure, 他们主要是在process和kernel之
间传递.传递的方向不同,导致length of the structure的使用方法不同.
- 从process到kernel:例子有, 函数bind, connect, sendto, 由于被告知了指针地址,
和数据长度.所以,内核知道要从进程拷贝多少东西
struct sockaddr_in serv; /* fill in serv{} */ connect(sockfd, (SA *)&serv, sizeof(serv));
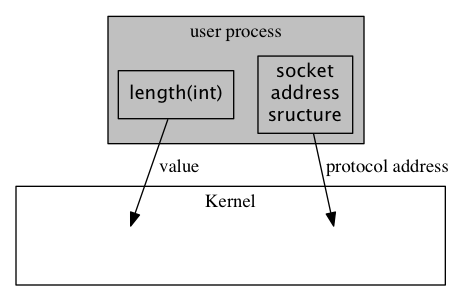
Figure 5: process-to-kernel.png
- 从kernel到process:例子有accept, recvfrom, getsockname, getpeername.这些函数
里面的len不再是一个int,而是pointer to int. 其目的有两点
struct sockaddr_un cli; /* Unix domain */ socklen_t len; len = sizeof(cli); /* len is a value */ getpeername(unixfd, (SA *) &cli, &len); /* len may have changed */
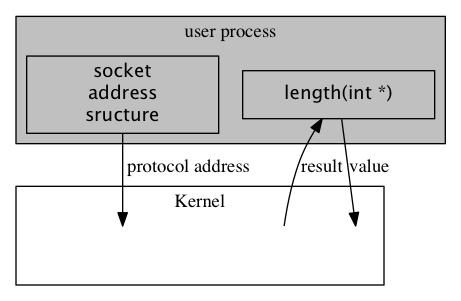
Figure 6: kernel-to-process.png
- 能够返回到底拷贝了多少的值(这个很显然,因为是copy by reference嘛)
- len在做参数之前,是有原来的值的(通过sizeof取得), 为的是告诉kernel界限在 哪里,不要拷贝数据到process的时候越界. 如果socket address structure是 长度不变,那么返回值一定:比如16 for IPv4 sockaddr_in, 28 for IPv6 sockaddr_in6. 对于长度可变的socket address structure,比如sockadr_un, 可能会改变len的值
- 从process到kernel:例子有, 函数bind, connect, sendto, 由于被告知了指针地址,
和数据长度.所以,内核知道要从进程拷贝多少东西
- 除了kernel 到process拷贝时候的returned socket address structure, 会出现
value-result argument, 另外会出现value-result argument的函数有:
- select
- getsockopt
- recvmsg
- ifconf
- sysctl
Byte Ordering Functions
- 假设一个Integer是16bit,那么就是由两个bytes组成的.在计算机里面有两种放置方式:
- big-endian : with the high-order byte at the starting address:
- 网络数据使用的就是这个endian, 其兼容性不好:,所以下面的例子只能在integer 为4bytes的
时候,成立啦,哪天换了64位cpu,integer成了8bytes,下面的代码两个s的值额就不相等了
// i MUST be 4bytes, as we have to fetch the last byte short s = (short)i; short s = ((short*)&i)[1];
- 另外,摩托罗拉的power cpu使用的是big endian, 因为big endian会产生更好看
的hex dumps, 对的,你没看错.摩托罗拉的工程师认为,这个比兼容性更重要.为了更
好的读dump,因为程序崩溃的时候不是用printf读取数据的,直接是把内存内容打印
出来,如下,内存内容排列的顺序跟我们输入的顺序0x01020304是一样的:
#include <stdio.h> int main(int argc, char *argv[]) { int ii = 0x01020304; int i = 0; char* ptr = ⅈ for (i = 0; i < 4; i++) { printf("%x\n", *ptr); ptr++; } return 0; } /***********************************/ /* ===Result== */ /* lvtest@auto-inst:~/tmp$ ./a.out */ /* 1 */ /* 2 */ /* 3 */ /* 4 */ /***********************************/
- 网络数据使用的就是这个endian, 其兼容性不好:,所以下面的例子只能在integer 为4bytes的
时候,成立啦,哪天换了64位cpu,integer成了8bytes,下面的代码两个s的值额就不相等了
- little-endian : with the low-order byte at the starting address,
- 英特尔设计的x86 cpu都是使用little endian, 因为little-endian在cast
的时候,不需要知道原型的长度,所以有很好的向后兼容性, 下面两条在x86上面的
结果一致.
// i can be 4 byte int, can ALSO be 8 bytes int. We just fetch the first byte short s = (short)i; short s = *(short*)&i;
- little endian里面地址最小的byte,也同时是数据最小的一个byte,如果不用
printf(coredump的时候)打印出来的顺序和人类写入的顺序是不同的
#include <stdio.h> int main(int argc, char *argv[]) { int ii = 0x01020304; int i = 0; char* ptr = ⅈ for (i = 0; i < 4; i++) { printf("%x\n", *ptr); ptr++; } return 0; } /***********************************/ /* ===Result== */ /* lvtest@auto-inst:~/tmp$ ./a.out */ /* 4 */ /* 3 */ /* 2 */ /* 1 */ /***********************************/
- 英特尔设计的x86 cpu都是使用little endian, 因为little-endian在cast
的时候,不需要知道原型的长度,所以有很好的向后兼容性, 下面两条在x86上面的
结果一致.
- big-endian : with the high-order byte at the starting address:
- 下面是一个简单的测试endian的代码:小的"地址"取出来的,是"数据"的较小部分的就
是little endian, 这样我们每次取"数据"最"小"的部门,也就是地址为的部门,
肯定可以是casting的结果.
int main(int argc, char *argv[]) { union { short s; char c[sizeof(short)]; } un; un.s = 0x0102; printf("%s: ", CPU_VENDOR_OS); if (sizeof(short) == 2) { if (un.c[0] == 1 && un.c[1] == 2) { printf("big-endian\n"); } else if (un.c[0] ==2 && un.c[1] == 1) { printf("little-endian\n"); } else { printf("unknown\n"); } } else { printf("sizeof(short) = %d\n", sizeof(short)); } return 0; }
- 之所以讲到endian,是因为在网络上传输的数据必须是network byte order的. 比如TCP 里面的16-bit端口号和32-bit IP地址都得是network byte order的才能认识.
- 按说,可以把endian的实现封装起来,由api内部在传输前从内部order转换成network order
然后收到数据的时候,再反向转换回来. 但是由于历史的原因,包括POSIX规范都要求socket address
structure的某些部分,一定要以network order存储.所以我们就不多考虑这个问题了,转而研究
转换order的函数
#includ <netinet/in.h> // Both return: value in network byte order uint16_t htons(uint16_t host16bitvalue); uint32_t htonl(uint32_t host32bitvalue); // Both return: value in host byte order uint16_t ntohs(uint16_t net16bitvalue); uint32_t ntohl(uint32_t net32bitvalue);
- 名字也都好理解h代表host, s代表short, l代表long
Byte Manipulation Functions
- 和c语言里面的字符串不一样, socket里面的数据通常有很多0, 所以也无法做到"\0"
结尾.于是我们还要有很多的其他函数来处理字符串:
- 一类来自4.2bsd,以b开头
#include <strings.h> // sets the specified number of bytess to 0 in the detination void bzero(void *dist, size_t nbytes); // const means the memory point by the "void *" can not (and will not) // be changed. void bcopy(const void *src, void *dest, size_t nbytes); int bcmp(const void *ptr1, const voi *ptr2, size_t nbytes);
- 另外一类来子ANSI C standard, 以mem开头
#include <string.h> // specified number f bytest to the value c in the destination void *memset(void *dest, int c, size_t len); // copy nbytes from src to dest void *memcpy(void *dest, const void *src, size_t nbytes); // return 0 if equal, otherwise unequal int memcmp(const void *ptr1, const void *ptr2, size_t nbytes);
- 一类来自4.2bsd,以b开头
inet_aton, inet_addr, and inet_ntoa Funtions
- IP地址的host-network转换,在IPv4时代主要依靠下面两个函数
#include <arpa/inet.h> // 1] converts c character pointed to by strptr into it2 32-bit // binary network byte order value stored in addrptr // 2] if string was valid return 1, otherwise return 0 // 3] if addrpter is NULL, the function still performs the validation int inet_aton(const char* strptr, struct in_addr* addrptr); // return pointers to dotted-decimal string // use static memory in inet_ntoa implementation and thus NOT reentrant char *inet_ntoa(struct in_addr inaddr);
- 值得一说的是inet_ntoa这个函数返回的是一个char*, 返回一个char *,那么肯定函数
里面使用了static变量,否则函数返回了,auto 变量都回收了,如何返回值.既然inet_ntoa
使用了static变量,那么就肯定不是reentrant函数了.更无法实现threadsafe, 所以这个
函数已经被放弃了,取而代之的是一个reentrant版本
char * inet_ntoa_r(struct in_addr in, char *buf, socklen_t size) { (void) inet_ntop(AF_INET, &in, buf, size); return (buf); }
- 还有一个问题更多被放弃的函数inet_addr,它的问题主要是返回值如果是255.255.255.255 的话,其实是-1.一遍函数用-1代表出问题. 加之可以用inet_aton代替,所以早已被废弃
inet_pton and inet_ntop Functions
- 上一节介绍的函数都可以用下面两个函数代替,而且这两个函数还支持IPv6
#include <arpa/inet.h> int inet_pton(int family, const char *strptr, void *addrptr); const char* inet_ntop(int family, const void *addrptr, char *strptr, size_t len);
- family可以是AF_INET或者AF_INET6, 如果family不支持,会返回错误同时set errno 为EAFNOSUPPORT
- 注意inet_ntop的返回值是char *但是并不是和上一节的inet_ntoa一样是返回内部的 static 内存.而是重复返回strptr而已(上面的inet_ntoa_r也一样)
- inet_ntop还有一个len参数来保证strptr的buffer不溢出.如果len过小的话, errno 会被设为ENOSPC
sock_ntop and Related Function
- inet_ntop的一个缺点是要求传入一个pointer(指向某个binary address), 而且我们
要实现知道这个地址的类型, 为了适应ipv4和ipv6的两种情况,我们设计了下面这个函数
sock_ntop,他会探测好pointer指向的地址类型,然后调用对应的inet_ntop, 下面只
列举了AF_INET的情况
char * sock_ntop(const struct sockaddr* sa, socklen_t salen) { char portstr[8]; static char str[128]; /* unix domain is largest */ switch (sa->sa_family) { case AF_INET: { struct sockaddr_in *sin = (struct sockaddr_in *)sa; if (inet_ntop(AF_INET, &sin->sin_addr, str, sizeof(str)) == NULL) { return (NULL); } if (ntohs(sin->sin_port) != 0) { snprintf(portstr, sizeof(portstr) ":%d", ntohs(sin->sin_port)); strcat(str, portstr); } return (str); } //..... } }
- 我们还写了以下一系列的函数来一次性处理ipv4和ipv6
int sock_bin_wild(int sockfd, int family); int sock_cmp_addr(const struct sockaddr *sockaddr1, const struct sockaddr *sockaddr2, socklen_t addrlen); int sock_cmp_port(const struct sockaddr *sockaddr1, const struct sockaddr *sockaddr2, socklen_t addrlen); int sock_get_port(const struct sockaddr* sockaddr, socklen_t addrlen); char *sock_ntop_host(const struct sockaddr* sockaddr, socklen_t addrlen); void sock_set_addr(const struct sockaddr *sockaddr, socklen_t addrlen, void *ptr); void sock_set_port(const struct sockaddr *sockaddr, socklen_t addrlen, int port); void sock_set_wild(struct sockaddr *sockaddr, socklen_t addrlen);
readn, writen, and readline Functions
- 通常情况下在socket编程中read和write的结果通常比我们要求的要少, 这是因为读取 写入已经超过了buffer limit,需要再次读取或写入(特殊情况下read可以超过这个limit, 但是write只有在nonblocking的情况下才能超过这个lilmit)
- 我们自己设计了一系列函数,在一次不成功读取写入要求的byte的情况下,多次去读取和写入
- readn: Read "b" bytes from a descriptor
ssize_t readn(int fd, void *vptr, size_t n) { size_t nleft; ssize_t nread; char *ptr; ptr = vptr; nleft = n; while (nleft > 0) { if( (nread = read(fd, ptr, nleft)) < 0) { if (errno == EINTR) { nread = 0; /* and call read() again */ } else { return (-1); } else if (nread == 0) { break; /* EOF */ } } nleft -= nread; ptr += nread; } return (n - nleft); /* return >= 0*/ }
- writen: Wirte n bytes to a descriptor
ssize_t writen(int fd, const void *vptr, size_t n) { size_t nleft; ssize_t nwritten; const char *ptr; ptr = vptr; nleft = n; while(nleft > 0) { if ((nwritten = write(fd, ptr, nleft) <= 0)) { if (nwritten < 0 && errno == EINTR) { nwritten = 0; } else { return (-1); } } nleft == nwritten; ptr += nwritten; } return (n); }
- readline : PAINFULLY SLOW VERSION
ssize_t readline(int fd, void *vptr, size_t maxlen) { ssize_t n, rc; char c, *ptr; ptr = vptr; for (n = 1; n < maxlen; n++) { again: if ((rc == read(fd, &c, 1)) == 1) { *ptr++ = c; if (c == '\n') { break; } } else if (rc == 0) { *ptr = 0; return (n-1); } else { if (errno == EINTR) { goto again; } return (-1); } } *ptr = 0; return (n); }
- readn: Read "b" bytes from a descriptor
- 上面的readline在每个byte上面调用read,非常的没有效率,下面是我们实现的一个较
为高效的readline版本
static int read_cnt; static char *read_ptr; static char read_buf[MAXLINE]; static ssize_t my_read(int fd, char *ptr) { if (read_cnt <= 0) { again: if ((read_cnt == read(fd, read_buf, sizeof(read_buf))) < 0) { if (errno == EINTR) { goto again; } return (-1); } else if (read_cnt == 0) { return (0); } read_ptr = read_buf; } read_cnt--; *ptr = *read_ptr++; return (1); } ssize_t readline(int fd, void *vptr, size_t maxlen) { ssize_t n, rc; char c, *ptr; ptr = vptr; for (n = 1; n < maxlen; n++) { if ((rc = my_read(fd, &c)) == 1) { *ptr++ = c; if (c == '\n') { break; } } else if (rc == 0) { *ptr = 0; return (n-1); } else { return (-1); } } *ptr = 0; return (n); } ssize_t readlinebuf(void **vptrptr) { if (read_cn) { *vptrptr = read_ptr; } return (read_cn); }
- my_read是读取MAXLINE的char才退出
- readline函数这次没有调用read,而调用了my_read,就搞笑了很多
- 一个新的函数redlinebuf暴露了内部buffer的state,所以调用者可以check这个state, 然后确定是否有新数据.
- 鉴于使用了static变量,所以reentrant是做不到了,threadsafe更不可能.
Chapter 4: Elementary TCP Sockets
Introduction
- 这一章主要介绍基础的来完成TCP client和server所必须要用到的socket function,
下图就是整个交互过程中使用到的函数关系图

socket Function
- 所有网络IO的开始,都是首先使用socket函数,创建的时候,就要指定通信协议的类型
#include <sys/socket.h> int socket(int family, int type, int protocol);
- family 参数有如下选择 (AF_LOCAL是POSIX名字,原来的名字较AF_UNIX)
family Description AF_INET IPv4 protocol AF_INET6 IPv6 protocol AF_LOCAL Unix domain protocol AF_ROUTE Routing sockets AF_KEY Key socket - type 参数有如下选择
type Description SOCK_STREAM stream socket SOCK_DGRAM dtagram socket SOCK_SEQPACKET sequenced packet socket SOCK_RAW raw socket - protocol 参数有如下选择
protocol Description IPPROTO_TCP TCP transport protocol IPPROTO_UDP UDP transport protocol IPPROTO_SCTP SCTP transport protocol - socket函数成功以后会返回一个socket descriptor(非负数), 得到socket descriptor 我们只需要指定IPv4或IPv6,和socket type(stream, datagram), 还没有指定protocol address
AF_XXX Versus PF_XXX
- AF_代表 address family, PF_代表 protocol family. 历史上这样取名的原因是:一个 protocol family设计成可以支持多个address families. 所以PF_用来在socket()函数 里面, 而AF_用在socket address structure.
- 但实际的情况是在<sys/socket.h>里面,所有的PF_都是一一对应AF_的,所以我们在unpbook 里面我们只用AF_,而不用PF_, 虽然POSIX里面是使用PF_
connect Function
- TCP client使用connect来连接远方的TCP server
#include <sys/socket.h> int connect(int socfd, const struct sockaddr *servaddr, socklen_t addrlen);
- connect开始了TCP三次握手,成功了或者error出现,才返回,典型的错误有如下:
- 如果TCP client发出的SYN没有接收到回应,那么ETIMEDOUT就会返回. 比如connect 建立的时候会发出一个SYN, 6秒之后会重发, 24秒之后再重发,如果75秒之后依然 没有反应的话,那么ETIMEDOUT就会返回了
- 如果server给予的返回是reset(RST),那就说明server端虽然机器在线,但是没有相应 的服务开启(我们要求的那个端口号没有开启), 这个时候一个ECONNREFUSED就返回了. 这个错误被看作是一个hard error在RST被收到的同时就马上返回
- 如果SYN产生的反应是ICMP "destination unreachable"(通常是从路由器返回的),那 么这个会被认为是一个soft error.因为destination unreachable通常情况下只是一个 暂时的情况(比如路由器错误).对付ICMP destination unreachable的方法和上面的 条款1一样:重发SYN多次如果75秒以后依然不成功,那么就返回EHOSTUNREACH.(需要注意 的是ENETUNREACH是被弃用的errno,如果出现,其应当做EHOSTUNREACH处理.
- 从状态图上来看, connect在发送完SYN之后就从CLOSED到了SYN_SENT, 在接收成功的ACK 之后就到了ESTABLISHED.
- 如果connect 失败了,我们一定要close()这个socket, 然后重新从socket调用开始.
bind Function
- bind functio是把当前的local protocol address付给socket. 所谓local protocal
address 就是一个IP地址(IPv4或者IPv6) + 一个TCP或者UDP 端口号
#include <sys/socket.h> int bind(int sockfd, const struct sockaddr *myaddr, socklen_t addrlen);
- 首先明确一点: bind的作用,是设置自己的socket的地址, server可以设置,同样client 也可以使用bind!
- bind的作用有亮点:
- 明确的指出了需要socket和哪个端口号进行"合作", 其实如果你不调用bind的话,内核 会自动赋予你一个临时端口号: client通常都这么做,随便那个端口就好了,但是server 通常都都会调用bind函数,因为server需要让大家知道自己的端口后(端口号一般是某种 服务专有某一个号码), server通常也可以不调用bind,那样的话,其使用了哪个端口,就 随机了.
- 明确的指出了需要socket和哪个IP进行"合作",如果不调用bind的话,内核会自动把当前 数据流出的网卡地址(如果有多个网卡,那就要看哪个能够到达remote server地址, 这个 地址是connect的时候设置的)赋予给socket. 一般来说client端都是不主动bind的,所以 IP地址是kernel赋予的. 而Server端虽然bind,但是一般都是默认不填具体的IP地址(用 0.0.0.0),这个时候kernel会把client端connect设置的目标IP作为server所拥有的socket 的source IP
- 用一个表来描述谁来负责设置具体的数据(IP和端口)
IP address port Result Wildcard 0 Kernel chooses IP address and port Wildcard nonzero Kernel chooses IP address, process specifies port Local IP address 0 Process specifies IP address, kernel chooses port Local IP address nonzero Process specifies IP address and port - bind函数最常见的错误代码是EADDRINUSE("Address already in use")
listen Function
- listen 函数就是只有server端才会调用的了, 有如下两个作用:
- 当socket被socket()创建的时候,它是一个active socket(一个将要调用connect发 起通信的候选者), listen()的作用,就是把它变成一个passive socket: kernel 要允许外来的通信来连接它. 用TCP state 图表的话说就是把state从CLOSED变成了 LISTEN.
- listen的第二个参数表达了kernel允许最多有多少connection可以排队等待当前socket 的眷顾
#include <sys/socket.h> int listen(int sockfd, int backlog);
- 为了理解所谓的"排队"等候被socket眷顾,我们要知道kernel为一个listening的socket
准备了两个队列(queue):
- incomplete connection queue: 从client端已经传过来SYN了,但是server socket 还没有回应. 这些server socket都是在SYN_RCVD状态
- completed connection queue: 已经给client返回了ACK,而且client的ACK也已经 收到(三次握手完成). 这些server socket已经是在ESTABLISHED状态了.
- 当一个SYN从client端传来的时候,TCP会在incomplete queue里面创建一个新的entry, 然后SYN(server) + ACK(for client SYN)给client.
- 当ACK(for server SYN)传回来的时候,entry就可以进入completed queue里面最后一位 开始等待啦.
- 当server开始accept()的时候,从completed queue里面的第一个就会被server锁定啦.当 然,如果completed queue这个时候是空的,那么server就会sleep,直到有entry出现.
- 这个两个queue的设计如此独特,以至于我们对它有如下的条目需要说明:
- 历史上backlog指的是两个queue里面entry的总数
- Berkeley的TCP实现会把backlog加个系数1.5,也就是说如果backlog是5的话, 最多 可以有entry的个数是5*1.5 = 7.5个,也就是8个
- 不要设置backlog为0, 因为有些实现可能认为这个是无限大–并不是拒绝client,拒绝 client的最好方法是close the listening socket
- entry呆在incomplete queue的时间是完成一次三次握手的时间,假设这个三次握手进行 的很顺利(没有丢失segment,没有重传), 那么这个时间就是一次RTT.一般来说RTT的中 位数时间是187ms
- 历史上backlog的设置一直是5,这个数字显然不能适应今天的server. backlog的大小
是一个很敏感的数字,如果我们希望根据不同的情况来动态的调整这个数字,那么在代码
中设置读取"环境变量"是个好主意,因为这样就可以不用重新编译我们的源代码,而且实
现了动态改变backlog的值,我们自己实现的Listen做到了这一点
void Listen (int fd, int backlog) { char *ptr; /* can override 2nd argument with environment variable */ if ((ptr = getenv("LISTENQ")) != NULL) { backlog = atoi(ptr); } if (listen(fd, backlog) < 0) { err_sys("listen error"); } }
- 设置backlog为一个比较大的值的原因比较复杂:
- 历史上的原因通常是因为让server不至于在accept的时候太busy, 也就是说会有 更多的entry在completed queue里面
- 当前的web server则是另外一种情况, 大部分的entry在incomplete queue, 因为 有大量的SYN来访,等待着三次握手的成功.
- 如果queue都已经满了的话, TCP就会直接丢弃后面的来访的SYN, 并且不发送RST. 这是 因为queue满的情况只是一种暂时的状态. 不发送RST的话, client会超时重发SYN,很 可能下一次就会占到地方了. RST是"server不再对应port"的一种反应,而不是"server端 的queue已经满"了的反应
- 在三次握手之后, 但是在server调用accept之前接受的数据,应该被conneted socket的 buffer缓存.
- 所有上述的backlog的猜想都是在unpbook的某一种TCP实现之中的. 在POSIX规范里面,对 上述所有的实现都是加上了"may", 也就是说可以如此实现.但是不强制.我们了解这些backlog 的知识,但是还是要具体事具体分析.
accept Function
- TCP server调用accept函数来得到自己的completed connection queue里面最开始的
那个socket connection. 如果completed queu是空的, 那么process就会进入sleep
(如果我们的socket的blocking socket的话)
#include <sys/socket.h> int accept(int sockfd, struct sockaddr *cliaddr, socklen_t *addrlen);
- 如果accept调用成功,那么返回值就是一个崭新的kernel自动创建的descriptor.这个新 的descriptor叫做connected socket, 而accept第一个参数sockfd代表的socket叫做 listening socket.
- 区别这个两个socket很重要,一般来说server只会创建一个listening socket(负责从 completed queue里面取的entry), 而且会为每一个client创建一个connected socket, 传输完毕的时候,关闭的也是connected socket.
- sockfd是listening socket的fd, 唯一一个输入,输出则是三个(如果不关心后两个,可以
把他们设置为NULL, 第一章的例子很明显了):
- 返回值是一个connected socket descriptor
- cliaddr返回client process的protocol address
- addrlen返回client process的protocol address的长度
- 下面一个例子展示了我们如何使用后两个参数来得到对方client的信息
#include "unp.h" #include <time.h> int main(int argc, char *argv) { int listenfd, confd; socklen_t len; struct sockaddr_in servaddr, cliaddr; char buff[MAXLINE]; time_t ticks; listenfd = Socket(AF_INET, SOCK_STRAM, 0); bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(13); /* daytime server */ Bind(listenfd, (SA*)&servaddr, sizeof(servaddr)); Listen(listenfd, LISTENQ); for ( ; ;) { len = sizeof(cliaddr); connfd = Accept(listenfd, (SA *) &cliaddr, &len); printf("connection from %s, port %d\n", Inet_ntop(AF_INET, &cliaddr.sin_addr, buff, sizeof(buff)), ntohs(cliaddr.sin_port)); ticks = time(NULL); snprintf(buff, sizeof(buff), "%.24s\r\n", ctime(&ticks)); Write(connfd, buff, strlen(buff)); Close(connfd); } //listening socket will be close at last with exit() }
fork and exec Functions
- 在Unix-like系统中创建process的唯一方法就是fork
#include <unistd.h> pid_t fork(void);
- fork这个函数很有意思,会返回两次(通过返回值是不是0,就可以判断是不是child):
- 在创建成功的child里面返回0, 因为child想知道自己的parent很简单,无论何时都 可以使用getppid()来得知
- 在parent里面返回新创建的child的process ID, 因为一个proces可以有很多child, fork的返回值是唯一可以知道自己child的机会.
- fork通常有两种用法:
- process制作自己的一个替身,去完成某项工作, server通常是这样做的
- process想运行另外一个program. 就要先fork(创建一份完全一样的内存映像),然后 exec来替代(主要是替代映像里面的运行代码),进而执行
- fork是把自己的资源重新复制一遍,只有一些参数和父进程不一样.通过这种方式来创
建新的进程.因为fork之后往往是进行exec()新的进程, 所以还有一个copy-on-write
技术:
- 所有的资源在fork之后都是只读的, 如果资源被写入了,那么就会有一份新的数据产生.
- 但是fork之后大部分是exec(), 所以就不用产生新的数据了.
- 这极大的提高了效率:因为fork的时候,资源不用完全赋值一遍了,只要让他只读就好.exec() 之后取消这个只读就行了,新的process会完全抛弃老的资源的
- exec系列函数一共有六个,只是参数不同,其实原理一样,就是在当前的process里面运行新的main
函数. 有错误,exec才会返回给caller.否则不返回.
#include <unistd.h> int execl(const char *pathname, const char *arg0, .../* (char*) 0 */); int execv(const char *pathname, char *const argv[]); int execle(const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */); int execve(const char *pathname, char *const argv[], char *const envp[]); int execlp(const char *filename, const char *arg0, .../* (char *) 0 */); int execvp(const char *filename, char *const *const argv[]);
Concurrent Server
- 下面我们就来看看用fork来组织的server
pid_t pid; int listenfd, connfd; listenfd = Socket(/*...*/); Bind(listenfd, /*...*/); Listen(listenfd, LISTENQ); for ( ; ;) { connfd = Accept(listenfd, ...); if ((pid = Fork()) == 0) { /* child closes listenindg socket as this listenfd is copied from parent, ref count will be 2, this close minus it to 1, and the parent copy will be used normally. */ Close(litenfd); doit(connfd); /* process the request */ Close(connfd); /* done with this client */ exit(0); /* child terminates */ } /* parent closes connected socket as this connfd is copied to child, ref count will be 2, this close minus it to 1, and the child copy close will finally cause the four-way wave */ Close(connfd); }
- 从上面的例子我们可以看到connfd被close了两次(其实listenfd也被close了两次,只 是不明显,而且原理和connfd一样). 那为什么第一次close不会导致tcp触发"四次挥手" 呢: 因为fork的时候会把socket descripto的reference加一. 四次挥手是在reference 为0的时候, 每次close减一,最后一次close的时候才会触发"四次挥手"
close Function
- close 函数是用来把socket标记成关闭, 然后马上返回. close一旦调用socket就无法
在read或者write了, 但是TCP会发送已经queued的数据给对方
#include <unisd.h> int close(int sockfd);
Descriptor Reference Counts
- 前面说了,如果你的descriptor的ref count依然大于0的话, close这个descriptor不 会马上开展"四次挥手", 要到ref count为0的那次close才会发生.
- 如果你force想让"四次挥手"发生,那应该使用shutdown()
- 如果前面的concurrent的例子里面,parent忘了close connected socket,那么会发生
下面两种情况:
- parent会最终耗尽它的descriptor(这个东西操作系统是有限制的)
- 没有一个client connection会真的关闭.因为child close的结果,无非是ref count 从2变成了1.
getsockname and getpeername Function
- getsockname的作用是找到本地protocol address的内容
int getsockname(int sockfd, struct sockaddr* localaddr, socklen_t* addrlen);
- 比如client connect调用之后, 其一般不会调用bind,那么可以通过getsockname来获得己方 的local IP(有好几个IP的情况下,ifconfig不好使哦)和local port number
- 就算server一般会调用bind,但是如果port number指定为了0,那么可以通过getsockname来 获取自己到底用了那个port number
- 如果server一般调用了bind,但是IP设置成了wildcard, 那么可以通过getsockname来看看 自己到底使用了那个ip地址,需要注意的是,要用connected socket(调用accept之后的 descriptor)来做参数, 因为没有connect的话,无法确定使用了哪个IP
- getsockname还能获取socket的address family
#include "unp.h" int sockfd_to_family(int sockfd) { struct sockaddr_storage ss; socklen_t len; len = sizeof(ss); if (getsockname(sockfd, (SA*) &ss, &len) < 0) { return (-1); } return (ss.ss_family); }
- getpeername的作用是找到socket连接的另一方的protocol address的内容
int getpeername(int sockfd, struct sockaddr *peeraddr, socklen_t *addrlen);
- 常见的使用场景是在server端使用exec来调用新的process的时候.accept即便能返 回client的信息,但是这个时候所有的内存都被exec新引入的main函数锁替代了.所 以我们要自己去取得client socket的信息(当然connfd需要一直知道,一个可能的 做法是exec把connfd作为一个参数引入因的程序)
Chapter 5: TCP Client/Server Example
Introduction
- 这一章我们主要讲一个echo server的例子, 所谓echo several就是:
- client从标准输入读取一行话, 然后把这段话发给server
- server从网络上读取这段话,然后原封不动的传给client
- client收到话以后再传给标准输出
TCP Echo Server: main Function
- 下面就是我们server的main函数
#include "unp.h" int main(int argc, char **argv) { int listenfd, connfd; pid_t childpid; socklen_t clilen; struct sockaddr_in cliaddr, servaddr; listenfd = Socket(AF_INET, SOCK_STREAM, 0); bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(SERV_PORT); Bind(listenfd, (SA*)&servaddr, sizeof(servaddr)); Listen(listenfd, LISTENQ); for (; ;) { clilen = sizeof(cliaddr); connfd = Accept(listenfd, (SA*)&cliaddr, &clilen); if ((childpid = Fork()) == 0) { /* child process */ Close(listenfd); /* close listening socket */ str_echo(connfd); /* process the request */ exit(0); } Close(connfd); /* parent closes connected socket */ } }
TCP Echo Server: str_echo Function
- 具体的问题,是在str_echo里面处理的.
#include "unp.h" void str_echo(int sockfd) { ssize_t n; char buf[MAXLINE]; again: while ((n = read(sockfd, buf, MAXLINE)) > 0) { Writen(sockfd, buf, n); } if (n < 0 && errno == EINTR) { goto again; } else if (n < 0) { err_sys("str_echo: read error"); } }
TCP Echo Client: main Function
- client端的代码如下
#include "unp.h" int main(int argc, char **argv) { int sockfd; struct sockaddr_in servaddr; if (argc != 2) { err_quit("usage: tcp cli <IPaddress>"); } sockfd = Socket(AF_INET, SOCK_STREAM, 0); bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_port = htons(SERV_PORT); Inet_pton(AF_INET, argv[1], &servaddr.sin_addr); Connect(sockfd, (SA*) &servaddr, sizeof(servaddr)); str_cli(stdin, sockfd); /* do it all */ exit(0); }
TCP Echo Client: str_cli Function
- client main里面除了socket以外的实际工作都是在str_cli里面完成的
#include "unp.h" void str_cli(FILE *fp, int sockfd) { char sendline[MAXLINE], recvline[MAXLINE]; while (Fgets(sendline, MAXLINE, fp) != NULL) { Writen(sockfd, sendline, strlen(sendline)); if (Readline(sockfd, recvline, MAXLINE) == 0) { err_quit("str_cli: server terminated permaturely"); } Fputs(recvline, stdout); } }
Normal Startup
- 虽然我们的例子很小,但是却很完整,可以帮助我们了解一些边界情况: 比如客户端host 崩溃, 客户端process崩溃, 网络连接消失等等
- 首先我没在linux上面开启server(需要%的root权限), 开启的过程调用了socket, bind
listen, accept,然后就block在accept上面了,因为我们还没开client,不会有SYN来,
当然所有的connection queue都是空的
linux % tcpserv01 & [1] 17870
- 这个时候,我们可以用netstat 来查看当前的系统中所有的socket (必须用参数-a,才能看到
listening的socket): 正如我们所料, server建立在wildcard的IP和9877的端口上
linux % netstat -a Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 *:9877 *:* LISTEN
- 然后我们在同一台机器上面调用client, 地址设置为127.0.0.1(本机)
linux % tcpcli01 127.0.0.1
- client和server在接下来会发生的变化是:
- client会调用socket, connect, 这就会触发三次握手
- 三次握手结束, connect"先"在client中返回, accept"后"在server中返回,因为三次 握手第二次返回SYN+ACK的时候,client的connect就会返回. 而第三次返回ACK的时候, server的accept才会返回.
- client会调用str_cli, 然后会被block在str_cli调用的fgets里面
- server的accept返回后, server调用了fork:
- child会调用str_echo=>readline=>read, 最后read会block在从connected sock et里面读取数据
- parent会再次调用accept, 因为queue里面什么也没有,所以它还是会block住.
- 这个时候我们再次使用netstat来看看当前的socket情况如下, 第一个ESTABLSHED是代表
server的(因为local端口号是9877), 第二个ESTABLISHED是client的, 因为我们client
server在一个机器上,所以会共同显示.
linux % netstat -a Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 local host:9877 localhost:42758 ESTABLISHED tcp 0 0 local host:42758 localhost:9877 ESTABLISHED tcp 0 0 *:9877 *:* LISTEN
- 我们可以更详细的使用ps命令来查看当前的这些socket:
- PID 和PPID分别代表进程ID和父ID, 这就很容易看哪个是子,哪个是父了.
- STAT的S代表sleeping
- WCHAN表示condition(只在sleep的时候):
- wait_for_connect: block在accept或者connect
- tcp_data_wait: block在socket 输入输出
- read_chan: block在terminal的输入输出.
Normal Termination
- 紧接着上面的操作,建立好连接以后,我们的client端可以开始发送数据, 我们发送发
送什么, server就会返回什么.最后以control+D的方式来结束.
linux % tcpcli01 127.0.0.1 hello, world hello, world good bye good bye ^D
- 如果我们在以control+D结束之后马上开始netstat,会得到下面的结果, TIME_WAIT我们
十分熟悉,他是client端的最后一个state,设置它为两倍的MSL可以一来防止最后一个ACK
丢失,而来保证老的分组在网络上已经丢失.
linux % netstat -a | grep 9877 tcp 0 0 *:9877 *:* LISTEN tcp 0 0 localhost:42758 localhost:9877 TIME_WAIT
- 正常关闭的时候,有如下的情况发生
- 当我们输入EOF的时候, fgets 返回一个null pointer, 然后str_cli函数返回
- str_cli返回了以后,client的main函数也就返回了,通过exit()
- 所有main函数返回的时候,就会关闭这个process占有的open descriptor.这样
一来, client socket就被kernel所关闭了.这会导致client发送FIN到server,
server会返回ACK,至此TCP connection termination的第一部分完成了:
- client现在的状态是FIN_WAIT_2
- server现在的状态是CLOSE_WAIT(passive close的状态)
- 当server 收到FIN的时候, server child正在readline中block,收到之后,readline 直接返回0, 然后这导致str_echo直接返回child main函数了.
- server的子进程会推出,调用exit()
- server的子进程退出的时候,会关闭其所有的open的descriptor.当然包括connected
socket, 这个时候会完成TCP connection termination的后半部分,之后client就会
进入TIME_WAIT进行最后的等待:
- FIN从server到client
- ACK从client到server
- 最后,当sever的子进程结束的时候,一个SIGCHLD 信号会发送给其父进程.我们的parent
没有做什么处理,所以子进程最后会进入zombie状态,如下(z代表zombie)
linux % ps -eo pid,ppid,stat,wchan:14,comm | grep tcp PID PPID STAT WCHAN COMMAND 13320 13319 S inet_csk_accep tcpserv01 13338 13320 Z exit tcpserv01 <defunct>
POSIX Signal Handling
- 所谓signal,也叫做software interrupts就是通知process某个event发生了.
- signal是异步方式(asynchronously), 也就是说被signal的发生时间是随机的,process 无法预测
- signal可以向两个方向传播:
- 从process到另外一个process(或者自身)
- 从kernel到process
- 上一节我们讲到子进程在最后结束的时候,发送了SIGCHLD信号给parent,但是没有处理, 所以子进程的资源没有回收,变成了zombie
signal Function
- POSIX对于signal的标准处理方法是sigaction函数,但是这个函数有两个structure来
进行初始化,非常的麻烦.POSIX时代之前的做法是signal, 这个函数的参数就很友好.
但是每个系统的实现都不一样,所以我们做个折中:使用signal的接口,内部用sigaction
实现:
#include "unp.h" Sigfunc * signal(int signo, Sigfunc *func) { struct sigaction act, oact; act.sa_handler = func; sigemptyset(&act.sa_mask); act.sa_flags = 0; if (signo == SIGALRM) { #ifdef SA_INTERRUPT act.sa_flags |= SA_INTERRUPT; /* SunOS 4.x */ #endif } else { #ifdef SA_RESTART act.sa_flags |= SA_RESTART; /* SVR4, 4.4BSD */ #endif } if (sigaction(signo, &act, &oact) < 0) { return (SIG_ERR); } return (oact.sa_handler); }
- 常规的signal函数的声明就非常恐怖:返回值和其中一个参数都是"带一个int参数,返
回值为空的函数指针"
void (*signal(int signo, void(*func)(int)))(int);
- 为了简化,我们设计了下面的typedef
typedef void Sigfunc(int);
- sigaction的sa_handler成员是为了设置func参数的.
- 我们还通过sa_mask来设置我们的handler运行期间被block的其他signal: handler 自己处理的signal不需要block, 因为uinix无法queue signal.如果一个handler正 在处理某一类signal,相同类型的signal再出现N此就会被认为是只出现了一次.
- 如果处理的signal不是SA_RESTART,那么可以通过设置sa_flags为SA_RESTART(某些 老的系统为SA_INTERRUPT)来让某些被中断的(被handler中断的)system call继续运 行.
POSIX Signal Semantics
- 一旦一个signal handler 被安装了,就一直是安装状态
- 某个类型A的signal在处理的话,相同类型的signal会被block, sa_mask设置的那些 signal也会block
- 如果被block的signal在block的时候出现了N此,只算一次.可以认为block 数组是 用的boolean类型,只能记住来没来过,不能记住来过几次
Handling SIGCHLD Signals
- zombie state存在的理由是它可以保存子进程的一些信息(父进程可能会想知道):
- 子进程的process ID
- 子进程的termination status
- 子进程的资源使用情况(CPU时间,内存)
Handling Zombies
- zombie不能总是留在系统里面,因为它会占据kernel的空间,如果不清理,会导致process
descriptor用尽,我们需要用wait来防止子进程变成zombie,并且用下面的代码来指定
其handler.下面的函数需要在listen()之后,fork()之前
Signal(SIGCHLD, sig_chld);
- 下面就是处理sig_chld的代码
#include "unp.h" void sig_chld(int signo) { pid_t pid; int stat; pid = wait(&stat); printf("child %d terminated\n", pid); return; }
Handling Interrupted System Calls
- accept被我们称作"slow system call", 因为它可能一直等待着connection queue里 面的成员,而一直不返回.相似的system call还有read
- 如果符合下面的几条,那么system call会返回一个错误代码EINTR:
- 进程block在一个slow system call
- 进程捕捉到一个signal A
- signal A的handler处理完成,然后返回了.
- 上述情况下返回错误代码EINTR看起来很突兀.要从系统的角度理解.
- slow system call可能永远都不返回的
- 进程处理了某个signal,而其signal handler()要比system call更优先运行.这个 时候,就要牺牲掉system call
- 但是我们这次的牺牲其实不是真正的错误,所以我们要告诉用户:通过把errno设置为
EINTR告诉用户,我们这次返回了负数,但是我们不是真的失败,我们是被interrupt了,
请再次调用我们吧!
for (; ;) { clilen = sizeof(cliaddr); if ( (connfd = accept(listenfd, (SA*)&cliaddr, &clilen)) < 0) { if (errno == EINTR) { continue; } else { err_sys("accept error"); } } }
- 上面的做法是让用户再次调用slow system call, 这样做很繁琐. 所以后来出现了一
种设置sgaction的sa_flags的方法来让刚才被中断的slow system call重新执行:
#include <signal.h> #include <stdio.h> #include <stdlib.h> #include <error.h> #include <string.h> #include <unistd.h> void sig_handler(int signum) { printf("in handler\n"); sleep(1); printf("handler return\n"); } int main(int argc, char **argv) { char buf[100]; int ret; struct sigaction action, old_action; action.sa_handler = sig_handler; sigemptyset(&action.sa_mask); action.sa_flags = 0; /********************************/ /* version 1: set this flag */ /* version 2: NOT set this flag */ /********************************/ action.sa_flags |= SA_RESTART; /**************************/ /* ctrl + c is for SIGINT */ /**************************/ sigaction(SIGINT, NULL, &old_action); if (old_action.sa_handler != SIG_IGN) { sigaction(SIGINT, &action, NULL); } bzero(buf, 100); ret = read(0, buf, 100); if (ret == -1) { perror("read"); } printf("read %d bytes:\n", ret); printf("%s\n", buf); return 0; }
- version 1: SA_RESTART 设置了,可以自动重启read
lvtest@auto-inst:~/tmp$ ./a.out ^Cin handler ^Chandler return in handler handler return ^Cin handler handler return read 0 bytes:
- version 2:没有设置SA_RESTART,无法重启read,直接返回
lvtest@auto-inst:~/tmp$ ./a.out ^Cin handler handler return read: Interrupted system call read -1 bytes:
- 虽然设置sa_flags为SA_RESTART的方法很好,但是却不能跨平台,因为有些平台是无法 重启某些system call的(更重要的是所有平台都无法重启connect,这个是特例,需要 select的帮助),所以需要跨平台的程序还是要用循环来重新调用system call
wait and waitpid Function
- 在Unix-like的系统中,使用wait和waitpid来处理已经结束了的子进程
#include <sys/wait.h> pid_t wait(int *statloc); pid_t waitpid(pid_t pid, int *statloc, int options);
- 这两个函数都有两个返回值:
- pid_t就是"等到"的刚刚结束的子进程的id
- *statloc会返回这个子进程的termination status, 返回的是一个int值(通过int指 针), 所以具体的信息肯定是这个int值的某个bit位表示的,使用"宏"来读取相应的bit 从而得知结束状态:WIFEXITED, WEXITSTATUS
- wait的功能比较简单,而且没有可定制的可能:
- 一个进程调用了wait,但是调用的时候没有子进程结束,那么它必须block,等待第一个返 回的子进程
- wait也只能等待第一个返回的子进程,如果有多个子进程的情况下,剩下的子进程就只有 变成zombie了
- waitpid的功能是wait的超集:
- 一个进程调用了waitpid,但是调用的时候没有子进程结束,那么它可以block,也可以把 options添加一个设置WNOHANG来让函数watipid马上返回.
- waitpid如果设置参数pid为-1,那么就和wait的行为一样:等待第一个返回的子进程.如 果pid设置为某个子进程的processID,那么就可以"专门"等待那个子进程
- 下面我们就看一个wait的例子,会衍生出很多问题
- client端一次就要求五个socket,server端也就要fork五次来满足
#include "unp.h" int main(int argc, char *argv[]) { int i, sockfd[5]; struct sockadr_in servaddr; if (argc != 2) { err_quit("usage: tcpcli <IPaddress>"); } for (i = 0; i < 5; i++) { sockfd[i] = Socket(AF_INET, SOCK_STREAM, 0); bzero(&servadr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_port = htons(SERV_PORT); Inet_pton(AF_INET, argv[1], &servaddr.sin_addr); Connect(sockfd[i], (SA*)&servadr, sizeof(servaddr)); } str_cli(stdin, sockfd[0]); exit(0); }
- 当我们传输结束的时候,差不多是5个FIN同时发送给server, 这也就意味着差不多在
同时,会有五个server的子进程结束, 也就意味着有五个SIGCHLD信号传递给server
父进程.因为Unix系统的信号是无法queue的, 这也就意味着,如果我们在"同一台机器"
上面做这个实现,五个SIGCHLD的效果跟一个SIGCLD是一样的.
linux % tcpserv03 & [1] 20419 linux % tcpcli04 127.0.0.1 hello hello ^D child 20426 terminated
- 因为只wait到了一个子进程,所以剩下的子进程就全部都zombie了.
- 不能仅仅是产生zombie的问题,这个程序会因为环境的不同,产生不同的结果.
- 这个例子 我们是在同一台机器运行client和server,所以五个SIGCHLD几乎是同 时产生的,这才造成了handler只运行一次
- 如果我们是在两台机器上运行这个例子,那么由于五个FIN在网络上传输的时间不同 最后可能只有有部分SIGCHLD被catch到. 只需要记住造成这种状况的原因是unix 的signal无法queue.
- client端一次就要求五个socket,server端也就要fork五次来满足
- wait的问题,很多时候要靠waitpid来解决.
- waitpid的解决方案如下, 需要注意的是waitpid等到所有子进程的方法是busy waiting
所以,你一定要设置waitpid的option为WNOHANG,来让waitpid在没有当前退出进程的子
进程的时候, 马上退出
#include "unp.h" void sig_chld(int signo) { pid_t pid; int stat; while((pid = waitpid(-1, &stat, WNOHANG)) > 0) { printf("child %d terminated\n", pid); } return; }
- server端调用这个新的waitpid版本的sig_chld,同时还要处理EINTR的"正常的"errno,
所以就有了下面的最"正确"的版本:
#include "unp.h" int main(int argc, char *argv[]) { int listenfd, connfd; pid_t childpid; socklen_t chilen; struct sockaddr_in cliaddr, servaddr; void sig_chld(int); listenfd = Socket(AF_INET, SOCK_STREAM, 0); bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(SERV_PORT); Bind(listenfd, (SA*)&servaddr, sizeof(servaddr)); Listen(Listenfd, LISTENQ); Signal(SIGCHLD, sig_chld); /* must call waitpid() */ for (;;) { clilen = sizeof(cliaddr); if ((connfd = accept(listenfd, (SA*)&cliaddr, &clilen)) < 0) { if (errno == EINTR) { continue; } else { err_sys("accept error"); } } if ((childpid = Fork()) == 0) { /* child process */ Close(listenfd); /* close litening socket */ str_echo(connfd); exit(0); } Close(connfd); } return 0; }
- waitpid的解决方案如下, 需要注意的是waitpid等到所有子进程的方法是busy waiting
所以,你一定要设置waitpid的option为WNOHANG,来让waitpid在没有当前退出进程的子
进程的时候, 马上退出
Connetion Abort before accept Returns
- 前面说过,为了给handler让路所以system call会return, 让handler运行. 这种 interrupted system call 的情况其实不是fatal的错误,所以会设置errno为EINTR, 我们可以捕捉这个errno,然后忽略它,重新开启system call
- 和上面情况是,三次握手完成后,在server端调用accept值钱, client发送了一个RST, 这种情况下,我们的accept()调用会失败. 如果我们检查errno发现是ECONNABORTED(" softeare caused connection abor")的话.说明这不是一个fatal的错误,我们可以 捕捉这个错误,然后重新调用accept()
- 这里说说FIN和RST的区别:
- FIN: "我已经不想和你说什么了,但是我依然愿意想听你把你的话说完"
- RST: "我们的谈话结束了,我不会跟你再废话,也不会听你说任何事情了"
Termination of Server Processs
- 首先开启client和server, 然后kill掉server的一个子进程.这就模仿了"server进程"
崩溃的情况(注意这里是"server进程"崩溃, "server的主机"并没有崩溃):
- 开启client和server,然后确认echo都是ok的
- 找到某个server的子进程,然后kill掉它,随之而来的就是所有的descriptor都关闭了, 一个FIN发送到client, client会回应一个ACK. 半关闭完成了.
- SIGCHLD会发送到server的parent,然后被handle了
- client这边并不知道server是怎么回事,只是知道"对方不想发数据给我了", client 这个时候,是block在那里的.等待用户输入的
- netstat会看到现在的情况:
linux % netstat -a | grep 9877 tcp 0 0 *:9877 *:* LISTEN tcp 0 0 localhost:9877 localhost:43604 FIN_WAIT2 tcp 0 0 localhost:43604loca lhost:9877 CLOSE_WAIT
- 这个时候client依然可以输入,我们输入一段话,会发现str_cli崩溃退出了:
- 我们打入"another line", str_cli就会调用writen来往socket里面写数据.这是 允许的client并不知道server发生了什么,只是知道"server不想跟他说话了",但是 没有收到FIN,说明"server还能听我的"
- server host 收到这些数据后,非常痛快的返回了一个RST,因为对应这个socket的 子进程已经不存在了
- client端却不会真正的看到这个RST,因为client在writen之后的操作是readline, 然后会读取到上面2)返回的0(EOF),这是由于FIN已经设置了,"server已经不想跟我说话" 了.不会再在socket里面取得任何数据了.所以错误信息是"server terminsted prematurely"
- client关闭,它所有的descriptor也会关闭.
- 上面的例子的问题在于当FIN来到的时候,client被block在fgets:
- client在同时和两个descriptor工作:socket和用户的input. 而且只能block在其中一个descriptor
- client应该的行为是:同时和"socket","用户的input"两个descriptor工作,而且能够block 在任意一个descriptor:无论哪个descriptor来了信息都能第一时间知道.
SIGPIPE Signal
- 上面的例子中,如果我们的client忽略了readline返回的错误,一意孤行的往socket里 面写呢?答案是:如果进程朝一个已经设置为RST的socket里面写入数据的话. SIGPIPE 信号就会发给这个进程.这个进程的默认处理方式是关闭进程,但是可以catch
- 如果你catch了这个signal,那么你写入的write函数,也会返回EPIPE
- 写入一个收到FIN的socket是合理的,写入一个收到RST的socket是错误的,所以因为我们 第一次的写入导致了RST,所以,我们只认定第二次的写入是错误的.
- 下面这个例子,就是把写入的数据分成了两个部分,第一个char负责触发RST,剩下的chars
负责产生SIGPIPE
#include "unp.h" void str_cli(FILE *fp, int sockfd) { char sendline[MAXLINE], recvline[MAXLINE]; while(Fgets(sendline, MAXLINE, fp) != NULL) { Writen(sockfd, sendline, 1); sleep(1); Writen(sockfd, sendline + 1, strlen(sendline) - 1); if (Readline(sockfd, recvline, MAXLINE) == 0) { err_quit("str_cli: server terminated prematurely"); } Fputs(recvline, stdout); } }
- 这个新的client的效果如下:就不会有机会到达readline了SIGPIPE没catch,默认的效
果就是关闭进程
linux % tcpcli11 127.0.0.1 hi there hi there bye
- 说道如何处理SIGPIPE,这个真是得依情况而定.一般来说设置SIG_IGN(ignore)是比较好
的方法.因为两点:
- 系统对于这个错误不仅仅发了SIGPIPE,而且让接下来的write都返回EPIPE,所以就算 ignore了SIGPIPE,也可以通过EPIPE来发现错误
- 如果当前有多个socket在传递,而signal只是通知错误,又无法确定是哪个socket的 问题,贸然删除其中某一个显然不好.
Crashing of Server Host
- 说完了server process崩溃,这里讲讲server host崩溃:我们首先开启server和client, 然后输入一些字符串表示成功建立connection,最后把server的网线拔掉:拔掉就是最 成功的模拟了server host崩溃.这同时也模拟了由于路由原因server unreachable的情况
- server host崩溃后的情况如下:
- 当server host崩溃的时候,在网络上没有任何的数据包传输的
- 我们在client端输入一些东西, 通过writen写入到socket里面,然后就block在readline 等待结果
- 如果使用tcpdump, 我们会看到client 不停的重发数据,希望能够对得到server的ACK:
Berkeley的实现会尝试12次重传等待9分钟之后,放弃.然后发送一个错误到client进程,
这个时候是block在readline的,所以readline会返回一个错误:
- 如果client和server中间的路由器判断出来server host无法到达,并且回应以ICMP "destination unreachable"信息.那么错误就是EHOSTUNREACH
- 如果server host宕机,并且没有其他情况,那么返回ETIMEDOUT
- 虽然我们的client会经过很久(比如9分钟),最后知道了结果,但是我们希望能更快的知道结果, 方法就是在readline里面设置超时
- 这个例子我们是通过发送数据换来的知道server宕机,我们还可以通过SO_KEEPALIVE socket 来做到同样的效果.
Crashing and Rebooting of Server Host
- server host崩溃之后又重启的话,其实和前面差不多,因为原来的connection已经全部
都丢失了,所以server还是会返回RST:
- 开启server和client,输入一行来确认connection建立成功
- server崩溃并重启
- 我们在client端输入一行,这将会导致一段TCP 数据传给server端
- server host崩溃后重启,但是所有原来的connection的信息都已经不存在了,所以 对client传来的数据只能报以RST
- 我们的client一直block在readline,然后当RST传来的时候,readline就返回错误 ECONNRESET
Shutdown of Server Host
- 前面我讨论了1)关闭server进程2)关闭server主机两种方式,这里我们讨论的是server
用shutdown的正常方式关机:
- init会首先发送SIGTERM signal给所有server process
- 在过了5到20秒之后,还有进程没有关闭,那么就给所有的进程发送SIGKILL
- SIGTERM是可以catch的,如果我们的server没有catch住,那么SIGKILL就无法catch 了,SIGKILL会结束server进程,也就意味着关闭server所有的descriptor.
- 在client端,可能需要select或者epoll函数来探知server的结束
Summary of TCP Example
- 在client和server通信之前,他们都要指定两对儿socket地址:
- local IP address && local port
- foreign IP address && foreign port
- 从client的角度来说:
- 在socket()之后,foreign IP和address必须要通过connect来指定,
- 同时,local IP和address要靠bind()来指定,但是一般来说不在client端指定这个.
- 我们可以在连接建立之后通过getsockname来了解local IP和address
- 从server的角度来说:
- 在socket()之后, local IP和address靠bind()来指定,一般来说local的IP都是设置 为waildcard, 那么具体的数值就要靠建立连接之后的getsockname()
- foreign IP address & port是靠accept的两个参数,
- 如果execed了原来的内存位置的话, accept的返回值就不再准确了.我们需要使用 getpeername().
Data format
- 由于不同的体系结构(big endian, small endian)上面传递二进制数据,会造成错误,这 本质上是由于不同体系对于内存的解释不同.
Chapter 6: I/O Multiplexing: The select and poll Functions
Introduction
- 前面TCP client是同时处理两个input: standard input和TCP socket, 这个体系有很
大的问题:
- client会被block在fgets上面
- 当server被kill的时候,会发送FIN到client,但是因为client一直在处理standard的 IO,所以一直等到有机会处理socket IO的时候,才发现,原来我已经被server抛弃了.
- 所以,我们希望能够有一种新的功能:
我们能够在某个IO ready的情况下,被kernel通知(这样一来,我们就不必通过循环做busy waiting了). - 这种功能已经存在了,名字叫做I/O multiplexing并且是通过select和poll函数实现的
- I/O multiplexing在网络中的应用场景有如下:
- 当一个client处理多个descriptor的情况,I/O multiplexing必须得应用(这也是前面 提到的场景)
- 一个client同时处理多个sockets的情况(不是很常见)
- 一个server同时吹离listenng socket和connected socket的情况
- 一个server同时处理TCP和UDP的情况
- 一个server处理多个服务,并且属于多个协议的情况.
- I/O multiplexing不仅仅限于网络编程, 也在其他领域有作用
I/O Models
- 在我们解释select和poll之前,我们先总结一下Unix下面的五种I/O models:
- blocking I/O
- nonblocking I/O
- I/O multiplexing (select and poll)
- signal driven I/O (SIGIO)
- asynchronous I/O(the POSIX aio_ functions)
- 通过前面的例子,我们也知道对于"输入"这个操作, 有两个不同的阶段:
- 等待数据的到来
- 把数据从kernel拷贝到进程
- 对于socket来说,1)就是等待数据从网络上传来,然后数据拷贝到kernel的buffer 2)就 是把kernel buffer的数据传递到进程的buffer
Blocking I/O Model
- 最常见的IO模型是blocking I/O, 默认情况下所有的socket都是blocking的
application system call kernel / recvfrom ------------------> no datagram ready \ | | | | | | | | | | | |> wait for data | | | | V | | datagram ready / | process blocks | copy datagram \ in call to <| | | recvfrom | | | | | | | | | | | | | | | | | |> copy data from | | | kernel to user | | | | | | | | | | V | \ return OK | process <---------------------- copy complete / datagram - 我们上面的例子使用的是UDP,因为UDP不涉及到拆分数据包,重组数据包.对于UDP来说, 数据的"ready"就是要么一个datagram全来了,要么都没来
- 在整个调用system call recvfrom的时候,我们的process都是被block的,当我们从 recvfrom函数返回, 我们的application就会开始处理传来的datagram
Nonblocking I/O Model
- 如果设置了socket为nonblocking,我们就有了如下的流程图,言简意赅的解释就是"如
果我要求的IO操作无法马上返回要被迫进入sleep状态的话,请不要sleep,直接返回给
我错误得了"
application system call kernel / recvfrom ---------------> no datagram ready \ | EWOULDBLOCK | | | <-------------- | | | | | | recvfrom ---------------> no datagram ready | | EWOULDBLOCK | | | <-------------- | | | | |> wait for data process repeatly| recvfrom ---------------> no datagram ready | calls recvfrom | EWOULDBLOCK | | waiting for <| <-------------- | | an OK | | | | recvfrom ---------------> datagram ready / | | copy datagram \ | | | | | | | | | | | |> copy data from | | | kernel to user | | | \ return OK | process <---------------------- copy complete / datagram - 这种设置了nonblocking,然后在循环里面不停调用函数的做法叫做polling.
I/O Multiplexing Model
- I/O Multiple Model其实就是利用select来探测数据,然后用recvfrom在确定数据已
经在的情况下,去调用.
application system call kernel / select -----------------> no datagram ready \ process blocks | | | in call to | | | select waiting | | | for one of | | | possibly many <| | |> wait for data sockets to | | | become readable | return readable | | | <---------------- datagram ready / | system call \ recvfrom ----------------> copy datagram \ / | | | | | | | | | | | process blocks | | | while data | | | copied into <| | |> copy data application | | | from kernel buffer | | | to user | | | | | | | | | \ return OK | process <----------------- copy complete / datagram - 看上去好像非但不比blocking模型有优势,反而多调用了一次select system call. 其 实不然,因为select函数可以同时等待不止一个descriptor
- 所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使 用multi-threading + blocking IO的web server性能更好,可能延迟还更大。 select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接.
Signal-Driven I/O Model
- Unix系统还为IO设计了一个SIGIO的信号,我们可以通过设置这个信号的handler来达到类
似select的作用
sigaction application system call kernel / establish SIGIO ----------------> \ | signal handler <---------------- | process | return | continues <| |> wait for data executing | deliveer SIGIO | | signale handler <---------------- datagram ready / | system call \ recvfrom ----------------> copy datagram \ / | | | | | process | | | blocks <| | | when data | | | copied | | | into | | |> copy data from application | | | kernel to user | | | | | | | | | | V | \ return OK | process <----------------- copy complete / datagram - 这种处理方法已经有非常大的效率上面的优势了, 这是第一种能有半天空闲的调用方法: 在第一个阶段,我们通过sigaction之后,进程的main函数可以正常的运行不会block, 而只有在收到信号,知道肯定有数据ready,正式开始读取数据的适合才block
Asynchronous I/O Model
- Asynchronous IO是比SIGIO信号法效率更高的处理方式:在数据处理的整个过程中进程 的main函数都可以自由的运行, 没有block!
- 我们通过aio_read把descriptor, buffer pointer,buffer size和通知成功的方法
传递给内核, 这个系统调用会马上返回的(不返回就是block了) 当我们要传的数据都已经
到我们制定的buffer里面了, 会有一个signal传递给我们的.
application system call kernel / aio_read ------------------> no datagram ready \ | ------------------- | | | | | | | | | | |> wait for | | | data | V | | datagram ready / | process | copy datagram \ continues <| | | executing | | | | | | | | | | | | | | | | | |> copy data | | | from kernel | | | to user | | | | | | | V | \ deliver signal | process <---------------------- copy complete / datagram specified in aio_read - 和上面signal-driven IO不同的是:
- 上面的signal-driven是说"等IO准备好可以开始拷贝了,再通知我, 我调用其他函 数来拷贝"
- 而Asynchronous IO是说"等IO全部拷贝好了再通知我"
Comparison of the I/O Models
- 下面是五种IO的对比,前四种的第二个phase都是一样的:block在recvfrom里面等待
着读取.Asynchronous IO最不同
blocking nonblocking I/O mulitplexing signal-driven I/O asynchronous I/O initiate check check initiate V check V V check V V check ready notification V V initiate initiate V V V V V V V V complete complete complete complete notification
Synchronous I/O versus Asynchronous I/O
- POSIX定义下面的两个术语:
- synchronous I/O 操作沪会导致进程阻塞,知道IO操作完成
- asynchronous I/O 操作不会导致提出IO要求的进程的阻塞
- 通过定义发现,前四种(blocking, nonblocking, I/O multiplexing, signal-driven IO)统统都是synchronous IO. 只有Asynchrous IO符合asynchronous IO的定义.
select Function
- 这个函数运行进程指导kernel,让其在某些特定条件下通知自己,比如:
- 集合{1,4,5}中有任何一个descriptor准备好读取了
- 集合{2,7}里面有任何一个descriptor准备好写入了
- 集合{1,4}里面有任何一个descriptor有了exception情况
- 10.2秒已经过去了.
- select的定义如下:
#include <sys/select.h> #include <sys/time.h> /*************************************************/ /* Returns: positive count of ready descriptors, */ /* 0 on timeout, -1 on error */ /*************************************************/ int select(int maxfdp1, fd_set* readset, fd_set* writeset, fd_set* exceptset, const struct timeval* timeout);
- 其中timeval的结构如下:
struct timeval { long tv_sec; /* secondes */ long tv_usec; /* microseconds */ };
- 我们在时间设置上面有如下几种情况:
- 一直等待下去: 我们只希望等待我们指定的descriptor,不想设置超时,那么就把 timeout参数为NULL
- 等待一个固定的时间:等待指定的descriptor,但是不能超过一定的时间.那么就把 timeout设置为具体数据
- 根本就不等待.如果我们把timeout参数设置为0的话,那么就退化成了busy wait 的polling.
- 上面所述的1,2两种情况都会受到signal的影响而让select中断(errno为EINTR), 某些 系统还是可以重启select(设置SA_RESTART), 某些系统还是要while loop重启
- timeval的设置还会出现两种"不准"的情况:
- 有些系统支持的最小时间精度是10ms,应用到最小精度为ms的tv_usec可能会出现一 些错误
- 有些系统不允许tv_sec设置为某些特别大的不合理的时间(比如1亿秒)
- timeout的参数有一个const,也就是说,你无法通过返回值来判断,真实的系统完成时间 为多少(有可能在指定时间之前就完成返回了)
- 中间三个参数readset, writeset和exceptset的类型都是fd_set*.其实fd_set*
就是int*(整形数组). 所有的descriptor号码都用整形数组的一个bit表述,比如,
descritpr为31,那么就是整形数组的第一个参数arr的最后一位bit,通过下面的
宏,我们可以让fd_set跨平台
void FD_ZERO(fd_set *fdset); /* clear all bitst in fdset */ void FD_SET(int fd, fd_set *fdset); /* turn on the bit for fd in fdset */ void FD_CLR(int fd, fd_set *fdset); /* turn off the bit for fd in fdset */ int FD_ISSET(int fd, fd_set *fdset); /* is the bit for fd on in fdset? */
- 对于exceptset参数来说,其只有下面两种选择(两个bit就够了)
- out-of-band 数据在socket上出现
- 控制信息出现在了pseudo-terminal上
- 如果我们把中间的三个fd_set*类型的数据设置为NULL的话,我们就得到了一个精度更 高的sleep(精度为ms). 实际上APUE上面就曾利用过select河poll来实现sleep_us
- maxfdp1参数的意思是前多少个descriptor被测试, 比如0,1,2,就是前"三"个descriptor 被测试(也就是最大的2+1,这也是maxfdp1中, 1的来历),设置"max file descriptor 加1"的目的是,我们能够减轻内核的负担. "我们保证只有前maxfdp1的会有问题",那么 就只需要检测[0,mafdp1)的数据啦.
- 每个进程能够拥有的descriptor的数目是一定的,在<sys/select.h>里面我们定义了 一个极值FD_SETSIZE(通常是1024)
- 如果我们把中间的三个fd_set*类型的数据都没有const,也就意味着select会改变他们
的值:
- 在调用select之前我们会把我们感兴趣的bit设置为1, 比如{1,3,4}有兴趣,就都设置 为1.那么输入就是01011
- select返回的时候,所有数据准备好的域都是1, 没准备好的(或者我们开始就设置为0的) 就还是0.比如13准备好了,那么返回值就是01010
- 函数的返回值代表了此次select有多少的descriptor可以readay了(当然是在我们关注 的那些descriptor中去选择)
- 返回值为-1,代表错误(比如返回-1,同时errno为EINTR,那么代表着函数被中断)
Under What Conditions Is a Descriptor Ready?
- 对于一个regular file来说,ready for "读"或者"写",都是很容易理解的.但是对于
socket来说(Unix下面一切皆文件,socket也被看做是一种文件),情况会复杂的多:
- 如果一个socket 满足下面任意一个condition就说它"准备好可读"了
- socket receive buffer的值比low-water mark要大(这样read就不会block, 并且会返回一个大于0的数字), 一般来说SO_RCVLOWAT为这个low-water mark的 默认值(一般为1)
- TCP处于半关闭状态,而且是read半关闭(收到FIN),这个时候read不会block,并且 会返回0
- socket是listening socket,并且completed queue里面的数目大于0, accept 这个listening socket不会block(有种timing condition会block accept, 后面会讲到)
- 会存在socket错误,存在错误的时候,read肯定会返回-1,也肯定不会block
- 如果一个socket 满足下面任意一个condition就说它"准备好可写"了
- 在socket send buffer里面的空间大于send buffer的low-water mark,并且要么 socket是connected, 要么socket不需要connection(UDP).send buffer的low-water mark一般数值为SO_SNDLOWAT(一般为2048)
- TCP处于半关闭状态,而且是write半关闭(发送FIN),这个时候write会产生SIGPIPE 信号
- 使用nonblocing的connect:要么成功完成了connection,要么connect失败
- 会存在socket错误,存在错误的时候,write肯定会置errno为一个错误状态的.这些错误 我们是可以通过getsockopt来读取的.
- 如果一个socket有out-of-band的数据,那么肯定返回exception condition pending
- 如果一个socket 满足下面任意一个condition就说它"准备好可读"了
- 我们可以看到如果socket上发生了错误,select会标记他"即可读又可写"
- 如果我们的读写在某一个数值下是无意义的,比如小于64个数据读取无意义,我们可以设置low-water mark 为64
Maximum Number of Descriptors for select
- 我们前面说过,大部分的应用都只会使用一小部分的descriptor,所以FD_SETSIZE的定 义足够用了.但是如果select想要使用更大数目的descriptor,那么仅仅简单的重定义 头文件里面的FD_SETSIZE是不够的,还需要重新编译内核.
str_cli Function (Revisited)
- 我们前面用两个循环设计过一次str_cli,那个版本的主要问题是client被困在等待两 个descriptor里面,在server已经关闭的情况下,却完全不知情,一定要再次输入打破 standard input才能发现socket descriptor的关闭.
- 下面我们使用select来构建新的版本, select设置standard input和socket两个
descriptor为其所关心,一旦哪个有可读的就返回.
#include "unp.h" void str_cli(FILE *fp, int sockfd) { int maxfdp1; fd_set reset; char sendline[MAXLINE], recvline[MAXLINE]; FD_ZERO(&rset); for( ; ;) { FD_SET(fileno(fp), &rset); FD_SET(sockfd, &rset); maxfdp1 = max(fileno(fp), sockfd) + 1; Select(maxfdp1, &rset, NULL, NULL, NULL); if (FD_ISSET(sockfd, &rset)) { /* socket is readable */ if (Readline(sockfd, recvline, MAXLINE) == 0) { err_quit("str_cli: server terminated prematurely"); } Fputs(recvline, stdout); } if (FD_ISSET(fileno(fp), &rset)) { /* input is readable */ if (Fgets(sendline, MAXLINE, fp) == NULL) { return; /* all done */ } Writen(sockfd, sendline, strlen(sendline)); } } }
- 从socket的角度,上面的这个程序有如下几个情况需要处理:
- 如果peer TCP传递了数据,那么socket就变得可读了.read()会返回一个大于0的数
- 如果peer TCP发送了一个FIN(peer process结束了,那么我们是passive close), 所以当前socket也是可读的,read()返回0(对方不想给我们说什么了,所以读取总是 nothing)
- 如果peer TCP发送了一个RST(peer host宕机或者重启), 那么socket也会变成readable, 只不过read()会返回-1. errno也会有相应的设置
Batch Input and Buffering
- 其实前面我们的str_cli版本依然不是理想的版本(当然,对于interactive的用户来说,
还不错).但是效率方面非常的差,这种模式叫做stop-and-wait模式,下面这个传输图标
有如下的假设:
- 我们把RTT分成八个相等的时间.
- 每个request和reply的在两个方向上传输时间相等
- server处理的时间为0
- 忽略其他不重要的时间,如TCP确认,握手,挥手的时间.

- stop-and-wait模式在处理交互性(interactive)的程序方面有一定优势,但是如果是单 单从网络传输信息的效率来看,实在是差(1/8的利用率),如果我们只关心网络的利用率, 希望尽可能快的传输数据,那么我们就进入了batch mode
- 下图就是batch mode的传输情况,我们可以看到,我们传输的速率是TCP能接受多快,我们就
传多快,即便当前没有数据: 换句话说就是
我们不再是根据newline来发起一次传输,而是如果网络上能同时承受N个包,那么我就 每过1/N个RTT时间发送一个包.
- 利用batch mode的方法发送如果还用上一节的str_cli的话,会面临一个重要的问题:如 何判断结束:在上一节的str_cli中,我们是通过EOF来判断结束的,但是在batch mode中 EOF和其他数据一样没有区别:我们只是按频率在发送
- 比如,上图中,我们假设有8行输入,time7刚好发送完第8行,那么
- 如果不关闭connection, time8还是会传输数据.
- 如果关闭了connection,那么server端还有数据传递怎么办
- 所以,结论是要half close connection,发送一个FIN给server就行(程序实现的方法是 shutdown函数)
- 把stdio的函数和select一起使用是非常危险的,因为select并不知道stdio的函数的buffer 的情况.
shutdown Function
- close是关闭网络连接的方法,引入shutdown是为了弥补close的两个局限性:
- 前面我们在fork出子进程处理connection的时候说了,close首先只会减少ref count,只有你的ref count到达0的时候,它才会真的发起"四次挥手", 但是shutdown 没有这个问题,只要调用了shutdown,无论ref count是多少,都开始"四次挥手"
- TCP是个双向车道(全双工), close一下子就关闭了两个方向的车道.TCP特有 的half close,就要靠shutdown来实现.
- shutdown函数声明如下:
#include <sys/socket.h> int shutdown(int sockfd, int howto);
- howto函数的值有如下:
- SHUT_RD: connection的read half被关闭,不能从socket上再读取任何的数据,socket receive buffer里面的数据全部丢弃.以后再从server接受到的数据,会ACK,然后丢弃. (因为是无法单方面提起read half close的,所以只是内核标记这个connection无法 读取了,实际上对方还是可以传递数据过来的,我们也会确认,只是不让应用层读取了)
- SHUT_WR: connetion的write half被关闭,不能冲socket上再写入任何数据, socket send buffer里面的数据会全部发送完毕.这才是真正的half close(只有write half close,没有read half close), 因为可以使用发送FIN到对方的方式来解决.而且无论 ref descriptor是不是零,都会发送FIN到对方
- SHUT_RDWR: read half和write half都关闭,这相当于调用两次shutdown:一次用参数 SHUT_RD,一次用参数SHUT_WR
str_cli Function (Revisited Again)
- 我们来看看引入了shutdonw和select之后的str_cli的代码
#include "unp.h" void str_cli(FILE *fp, int sockfd) { int maxfdp1, stdineof; fd_set reset; char buf[MAXLINE]; int n; stdineof = 0; FD_ZERO(&rset); for (; ;) { if (stdineof == 0) { FD_SET(fileno(fp), &rset); } FD_SET(sockfd, &rset); maxfdp1 = max(fileno(fp), sockfd) + 1; Select(maxfdp1, &rset, NULL, NULL, NULL); if (FD_ISSET(sockfd, &rset)) { /* socket is readable */ if ((n = Read(sockfd, buf, MAXLINE)) == 0) { if (stdineof == 1) { return; } else { err_quit("str_cli: server terminated prematurely"); } Write(fileno(stdout), buf, n); } } if (FD_ISSET(fileno(fp), &rset)) { /* input is readable */ if ((n = Read(fileno(fp), buf, MAXLINE)) == 0) { stdineof = 1; Shutdown(sockfd, SHUT_WR); /* send FIN ==> half close */ FD_CLR(fileno(fp), &rset); continue; } Writen(sockfd, buf, n); } } }
- 新的实现引入了一个flag stineof, 初始化的时候为0, 只要这个flag为0,我们就在 select的时候考虑standard input, 注意EOF是end of line (ctrl + D), 这里命名成 stdineof的原因是, socket和standard input都最终会有自己的EOF的,而standard input的到来更早些,所以我们把它作为一个flag
- 在读取socket的时候,如果读到socket的EOF,而且此时stdineof也是出现过了(值为1), 那么说明这是正常的退出, 直接return
- 在读取standard input的时候读取到EOF,这个时候就把flag stdineof设置为出现(为1), 然后调用shutdown函数来半关闭.
TCP Echo Server (Revisited)
- 既然我们引入了select,那么我就可以在server端使用select来管理所有的socket(因
为socket本质上是file). 使用了select的话,多进程(fork)就变得不必要了
1: #include "unp.h" 2: 3: int main(int argc, char *argv[]) 4: { 5: int i, maxi, maxfd, listenfd, connfd, sockfd; 6: int nready, client[FD_SETSIZE]; 7: ssize_t n; 8: fd_set rset, allset; 9: char buf[MAXLINE]; 10: socklen_t clilen; 11: struct sockaddr_in cliaddr, servaddr; 12: 13: listenfd = Socket(AF_INET, SOCK_STREAM, 0); 14: 15: bzero(servaddr, sizeof(servaddr)); 16: servaddr.sin_family = AF_INET; 17: servaddr.sin_addr.s_addr = htonl(INADDR_ANY); 18: servaddr.sin_port = htons(SERV_PORT); 19: 20: Bind(listenfd, (SA*)&servaddr, sizeof(servaddr)); 21: 22: Listen(listenfd, LISTENQ); 23: 24: maxfd = listenfd; /* initialize */ 25: maxi = -1; /* index into client[] array */ 26: for (i = 0; i < FD_SETSIZE; i++) { 27: client[i] = -1; /* -1 indicates available entry */ 28: } 29: FD_ZERO(&allset); 30: FD_SET(listenfd, &allset); 31: 32: for (; :) { 33: rset = allset; /* structure assignment */ 34: nready = Select(maxfd + 1, &rset, NULL, NULL, NULL); 35: 36: if (FD_ISSET(listenfd, &rset)) { /* new client connection */ 37: clilen = sizeof(cliaddr); 38: connfd = Accept(listenfd, (SA*)&cliaddr, &clilen); 39: 40: for (i = 0; i < FD_SETSIZE; i++) { 41: if (client[i] < 0) { 42: client[i] = connfd; /* save descriptor */ 43: break; 44: } 45: } 46: if (i == FD_SETSIZE) { 47: err_quit("too many clients"); 48: } 49: FD_SET(connfd, &allset); /* add new descriptor to set */ 50: 51: if (connfd > maxfd) { 52: maxfd = connfd; 53: } 54: if (i > maxi) { 55: maxi = i; 56: } 57: if (--nready <= 0) { 58: continue; 59: } 60: } 61: 62: for (i = 0; i <= maxi; i++) { 63: if ((sockfd = client[i]) < 0) { 64: continue; 65: } 66: if (FD_ISSET(sockfd, &rset)) { 67: if ((n = Read(sockfd, buf, MAXLINE)) == 0) { 68: /* connection closed by client */ 69: Close(sockfd); 70: } else { 71: Writen(sockfd, buf, n); 72: } 73: 74: if (--nready <= 0) { 75: break; 76: } 77: } 78: } 79: } 80: return 0; 81: }
- 程序非常的长,慢慢来分析:
- line 13-22这部分是创建listening socket, 还是老三样:socket(),bind(), listen().
- line 22-30有两个数据很关键:
- 一个client[]数组,用来跟踪所有的client,因为一个进程最大的file descriptor
数目有限,所以client数组的大小是FD_SETSIZE.数组的初始化值为(-1),表示
相应index的client没有连接, maxi这是最大的以连接的index.整数表示连接到哪个
descriptor

- maxfd = listenfd说明这个阶段关心的只到listening socket,还不关心其他的descriptor,
也没有其他的descriptor(前三个descriptor分别对应standard input, standard output,
standard erro, 所以listenfd最小也得是4)

- 一个client[]数组,用来跟踪所有的client,因为一个进程最大的file descriptor
数目有限,所以client数组的大小是FD_SETSIZE.数组的初始化值为(-1),表示
相应index的client没有连接, maxi这是最大的以连接的index.整数表示连接到哪个
descriptor
- line 32-33: 一个大循环每次等待数据的ready(每次rset会被allset所覆盖,因为
allset会加上每次connected成功的descriptor line42), ready通常意味这两种
情况:
- listening 的connection又来了新的请求:新的成员从completed queue里面出来 形成新的connection
- 已经连接成功的connection来了数据(也可能是信息,比如FIN, RST)
- line 36-60是处理listening connection的地方,listening socket可读,就说明一个
connection已经成功建立了,我们调用accept就可以返回新的descriptor.我们用nready
来记录这次select有几个需要处理的connection,处理完一次就减一.如果为0了,那么下
一个处理已经连接成功的connection的for就不需要进入了.
- 新的client[] slot会被填充 line 42:

- allset也会增加(以后会变成rset) line 49:

- 新的client[] slot会被填充 line 42:
- line 62-78: 是第二个循环,来处理已经连接的connection,是通过从0开始到maxi 逐个检查已经connected过的连接的方法.检测到来袭的数据,那么我们就write back 回去.如果read为0,那么说明client已经关闭了连接,我们也不含糊,直接close().
Denial-of-Service Attacks
- 很可惜的是,我们刚才完成的代码有一个很致命的问题:恶意用户可以connected到我们的 server,发送一个字节,然后sleep. server当然要响应这个用户,打开一个连接读取那个 字节,然后hung在那里等client的新的数据.无法为其他用户服务:"在处理多个client服务 的时候,server"永远不能"block在处理某一个client的函数里面,如果这样的话server会 huang住无法为其他client提供服务"–>这就叫做denial-of-service
- 解决denial-of-service的方法有:
- nonblocking I/O
- 为每一个client提供一个thread(只是暂时解决问题,遇到攻击,会出现procesID用 尽的问题)
- 为IO操作设置一个timer
pselect Function
- POSIX发明了一个pselect,很多Unix系统已经支持它了
#include <sys/select.h> #include <signal.h> #include <time.h> /*****************************************************************/ /* Returns: count of ready descriptor, 0 on timeout, -1 on error */ /*****************************************************************/ int pselect(int maxfdp1, fd_set* readset, fd_set* writeset, fd_set* exceptset, const struct timespec* timeout, const sigset_t *sgmask);
- 和普通的select相比pselect有如下变化:
- 使用了timespec,而不是timeval, tv_usec是纳秒级别,更加精确
struct timespec { time_t tv_sec; /* seconds */ long tv_nsec; /* nanoseconds */ };
- 增加了第六个参数:指向signal mask的指针:因为select有block的可能,在select被
block的时候,可能会有signal丢失,或者signal会打扰select的block:
- 想要既不丢失signal,又不打扰我们的select,就要用到sigprocmask:
/* 如果oset不是NULL指针的话,当前的signal mask会保存到这里 */ /* 如果set不是NULL指针的话,第一个参数how决定了怎么处理set所包含的signal mask的处理方式 */ /* how共有三个值: */ /* SIG_BLOCK 设置当前的signal mask为set和原有signal mask的并集 */ /* SIG_UNBLOCK set是我们想从原有signal mask中unblock掉的信号 */ /* SIG_SETMASK 用set来替换原有的signal mask. */ sigprocmask(int how, const sigset_t *restrict set, sigset_t * restrict oset)
- 从某种意义上来讲,pselect就是收到sigprocmask保护的select
ready = pselect(nfds, &readfds, &writefds, timeout, &sigmask); /************************************************************************/ /* Previous line equals following three lines(timeout maybe different): */ /************************************************************************/ sigprocmask(SIG_SETMASK, &sigmask, &origmask); ready = select(nfds, &readfds, &writefds, &exceptfds, new_timeout); sigprocmask(SIG_SETMASK, &origmask, NULL);
- 想要既不丢失signal,又不打扰我们的select,就要用到sigprocmask:
- 使用了timespec,而不是timeval, tv_usec是纳秒级别,更加精确
poll Function
- poll 函数原来是SVR3为STREAM设备开发的,后来改为对所有类型文件(也就是所有类型
的descriptor)的支持, poll和select的功能相似,但是多了STREAM支持(STREAM被Linux
所淘汰), 以及没有FD_SETSIZE的限制
#include <poll.h> /******************************************************************/ /* Returns: count of ready descriptors, 0 on timeout, -1 on error */ /******************************************************************/ int poll(struct pollfd *fdarray, unsigned long nfds, int timeout);
- pollfd是一个新的自定义类型,集合了某一fd的所有condition
struct pollfd { int fd; /* descriptor to check */ short events; /* events of interest on fd */ sthort revents; /* events that occurred on fd */ };
- 需要测试的condition设置在events, poll返回的时候,会把fd的status信息写入到
revents成员里面.(使用两个成员变量的方法,防止了"调用的时候设置,返回的时候复
写内存"的方法),下面是这两个condition可能的值:分成了三部分:读,写,错误信息.
Constant Input to Result from Description events? events? POLLIN Yes Yes Normal or priority band data can be read POLLRDNORM Yes Yes Normal datat can be read POLLRDBAND Yes Yes Priority band data can be read POLLPRI Yes Yes High-priority data can be read POLLOUT Yes Yes Normal data can be written POLLWRNORM Yes Yes Normal data can be written POLLWRBAND Yes Yes Priority band data can be read POLLERR No Yes Error has occurred POLLHUP No Yes Hangup has occurred POLLNVAL No Yes Descriptor is not an open file - 对于TCP和UDP来说,下面的condition会让poll返回相应的revent,不幸的是POSIX没有说
的太具体
- 所有的正常TCP,UDP信息会被认为是normal
- TCP的out-of-band会被认为是priority band
- TCP的half close情况下依然会被认为是normal
- TCP的error可能会被认为是error或者normal
- TCP的listening connection收到信息有new connection,也会被认为是priority或 者normal
- nonblocking connect会让poll认为这个socket可写
- 如果我们对某个descriptor不再感兴趣,我们只要把fdarray里面响应的struct pollfd 的fd设置成负数就行
- timeout参数可以设置的数值如下(INFTIM为POSIX规定的负数),某些系统时间精度不到
ms,可能会有误差:
timeout value Description INFTIM Wait forever 0 Return immediately, do not block >0 Wait specified number of milliseconds - 我们前面提到过select所关心的descriptor总数有限制:FD_SETSIZE,在poll这里,这个 限制不存在了,因为我们不再使用select类似的固定的参数,这些参数原来是在stack上面 设置的,不可能无限大.而限制poll使用的是用户申请的.那么原则上,可以无限的大(放在 heap上面),当然不太大的时候,还是可以放到stack上面.
- 其实现在的第一选择还不是poll,而且linux的epoll,因为就算poll没有FD_SETSIZE的缺 点,但是他却需要O(n)的复杂度来轮询fdarray.这个是无法避免的(其实select也一样,我 们从select那里仅仅知道了,有I/O事件发生了,但却并不知道是那几个流(可能有一个, 多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流, 对他们进行操作.)
- Linux的epoll创造性的使用内核"推送"的方式(具体是我们关心的fd会调用callback函数, 从而让内核知道了哪些fd是"活跃的",而把活跃的函数作为返回值返回)实现了一个"伪AIO (Asynchronous IO)".
TCP Echo Server(Revisited Again)
- 既然介绍了比select功能更强大的poll,我们就来看看如何用poll来实现我们的server,
其实现思路和select版本相似.
#include "unp.h" #include <limits.h> /* for OPEN_MAX */ int main(int argc, char *argv[]) { int i, maxi, listenfd, connfd, sockfd; int nready; ssize_t n; char buf[MAXLINE]; socklen_t clilen; struct pollfd client[OPEN_MAX]; struct sockaddr_in cliaddr, servaddr; listenfd = Socket(AF_INET, SOCK_STREAM, 0); bzero(&servaddr, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htol(INADDR_ANY); servaddr.sin_port = htons(SERV_PORT); Bind(listenfd, (SA*) &servaddr. sizeof(servaddr)); Listen(listenfd, LISTENQ); client[0].fd = listenfd; client[0].events = POLLRDNORM; for (i = 1; i < OPEN_MAX; i++) { client[i].fd = -1; } maxi = 0; for (; ;) { nready = Poll(client, maxi + 1, INFTIM); if (client[0].revents & POLLRDNORM) { /* new client connection */ clilen = sizeof(cliaddr); connfd = Accept(listenfd, (SA*)&cliaddr, &clilen); for (i = 1; i < OPEN_MAX; i++) { if (client[i].fd < 0) { client[i].fd = connfd; /* save descriptor */ break; } } if (i == OPEN_MAX) { err_quit("too many clients"); } client[i].events = POLLRDNORM; if (i > maxi) { maxi = i; } if (--nready <= 0) { continue; } } } for (i = 1; i <= maxi; i++) { /* check all clients for data */ if ((sockfd = client[i].fd) < 0) { continue; } if (client[i].revents & (POLLRDNORM | POLLERR)) { if ((n = read(sokfd, buf, MAXLINE)) < 0) { if (errno == ECONNERESET) { /* connection reset by client */ Close(sockf); client[i].fd = -1; } else if (n == 0) { /* connection close by client */ Close(sockfd); client[i].fd = -1; } else { Writen(sockfd, buf, n); } if (--nready <= 0) { break; } } } } return 0; }
Chapter 7: Socket Options
Socket Options
Introduction
- 有如下几种方法来设置socket的参数:
- getsockopt()和setsockopt()
- fcntl()
- ioctl()
getsockopt and setsockopt Function
- 两个函数的声明如下:
#include <syt/socket.h> int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t* optlen); int setsockopt(int sockfd, int level, int optname, const void* optval, socklen_t optlen);
- sockfd参数必须是一个已经open的socket descriptor.
- level参数指定了协议层(比如,IPv4, IPv6还是TCP, SCTP)
- optname是需要访问的选择的名字(比如, level层的sender buffer size大小)
- optval指向一个变量的指针,这个变量的值是由setsockopt设置的,可由getsockopt来 读取.
- optlen对于getsockopt()返回optval的最大长度, 对于setsockopt, 设置optval的最 大长度
Checking if an Option Is Supported and Obtaining the Default
- 我们下面来写一个函数来测试哪些socket option被当前系统所支持,如果支持,就读取
其默认值.
1: #include "unp.h" 2: #include <netinet/tcp.h> /* for TCP_xxx defines */ 3: 4: union val { 5: int i_val; 6: long l_val; 7: struct linger linger_val; 8: struct timeval timeval_val; 9: }val; 10: 11: static char *sock_str_flag(union val*, int); 12: static char *sock_str_int(union val*, int); 13: static char *sock_str_linger(union val*, int); 14: static char *sock_str_timeval(union val*, int); 15: 16: struct sock_opts{ 17: const char* opt_str; 18: int opt_level; 19: int opt_name; 20: char *(*opt_val_str) (union val *, int); 21: } sock_opts[] = { 22: { "SO_BROADCAST", SOL_SOCKET, SO_BROADCAST, sock_str_flag }, 23: { "SO_DEBUG", SOL_SOCKET, SO_DEBUG, sock_str_flag }, 24: { "SO_DONTROUTE", SOL_SOCKET, SO_DONTROUTE, sock_str_flag }, 25: { "SO_ERROR", SOL_SOCKET, SO_ERROR, sock_str_int }, 26: { "SO_KEEPALIVE", SOL_SOCKET, SO_KEEPALIVE, sock_str_flag }, 27: { "SO_LINGER", SOL_SOCKET, SO_LINGER, sock_str_linger }, 28: { "SO_OOBINLINE", SOL_SOCKET, SO_OOBINLINE, sock_str_flag }, 29: { "SO_RCVBUF", SOL_SOCKET, SO_RCVBUF, sock_str_int }, 30: { "SO_SNDBUF", SOL_SOCKET, SO_SNDBUF, sock_str_int }, 31: { "SO_RCVLOWAT", SOL_SOCKET, SO_RCVLOWAT, sock_str_int }, 32: { "SO_SNDLOWAT", SOL_SOCKET, SO_SNDLOWAT, sock_str_int }, 33: { "SO_RCVTIMEO", SOL_SOCKET, SO_RCVTIMEO, sock_str_timeval }, 34: { "SO_SNDTIMEO", SOL_SOCKET, SO_SNDTIMEO, sock_str_timeval }, 35: { "SO_REUSEADDR", SOL_SOCKET, SO_REUSEADDR, sock_str_flag }, 36: #ifdef SO_REUSEPORT 37: { "SO_REUSEPORT", SOL_SOCKET, SO_REUSEPORT, sock_str_flag }, 38: #else 39: { "SO_REUSEPORT", 0, 0, NULL }, 40: #endif 41: { "SO_TYPE", SOL_SOCKET, SO_TYPE, sock_str_int }, 42: { "SO_USELOOPBACK", SOL_SOCKET, SO_USELOOPBACK, sock_str_flag }, 43: { "IP_TOS", IPPROTO_IP, IP_TOS, sock_str_int }, 44: { "IP_TTL", IPPROTO_IP, IP_TTL, sock_str_int }, 45: { "IPV6_DONTFRAG", IPPROTO_IPV6,IPV6_DONTFRAG, sock_str_flag }, 46: { "IPV6_UNICAST_HOPS", IPPROTO_IPV6,IPV6_UNICAST_HOPS,sock_str_int }, 47: { "IPV6_V6ONLY", IPPROTO_IPV6,IPV6_V6ONLY, sock_str_flag }, 48: { "TCP_MAXSEG", IPPROTO_TCP,TCP_MAXSEG, sock_str_int }, 49: { "TCP_NODELAY", IPPROTO_TCP,TCP_NODELAY, sock_str_flag }, 50: { "SCTP_AUTOCLOSE", IPPROTO_SCTP,SCTP_AUTOCLOSE,sock_str_int }, 51: { "SCTP_MAXBURST", IPPROTO_SCTP,SCTP_MAXBURST, sock_str_int }, 52: { "SCTP_MAXSEG", IPPROTO_SCTP,SCTP_MAXSEG, sock_str_int }, 53: { "SCTP_NODELAY", IPPROTO_SCTP,SCTP_NODELAY, sock_str_flag }, 54: { NULL, 0, 0, NULL } 55: };
- line 4-9: 我们的getsockopt函数可能会返回四种基本类型:int, long, timeval{}, linger{},所以我们的union也设置成这四种类型,一旦指针指向对应位置,就可以方便获取 实际值.
- line 11-14: 函数声明,这四个函数用来把相应flag(或者int,或者linger,或者timeval)
转换成易读的字符串, 下面是其中sock_str_flag的实现
static char strres[128]; static char* sock_str_flag(union val* ptr, int len) { if (len != sizeof(int)) { snprintf(strres, sizeof(strres), "size (%d) ont sizeof(int)", len); } else { snprintf(strres, sizeof(strres), "%s", (ptr->i_val == 0) ? "off" : "on"); } }
- line 16-55:我们创建了结构体sock_opts, 然后把getsockopt()的所有四个参数(除了
fd)都写到这个结构体里面,注意,最后一行我们设置了全NULL,为了就是能够在使用的时候
知道"结构体到头了"
{ NULL, 0, 0, NULL }
- 我们使用这个上面结构体的main代码如下:
1: int main(int argc, char *argv[]) 2: { 3: int fd; 4: socklen_t len; 5: struct sock_opts* ptr; 6: 7: for (ptr = sock_opts; ptr->opt_str != NULL; ptr++) { 8: printf("%s: ", ptr->opt_str); 9: if (ptr->opt_val_str == NULL) { 10: printf("(undefined) \n"); 11: } else { 12: switch(ptr->opt_level) { 13: case SOL_SOCKET: 14: case IPPROTO_IP: 15: case IPPROTO_TCP: 16: fd = Socket(AF_INET, SOCK_STREAM, 0); 17: break; 18: #ifdef IPV6 19: case IPPROTO_IPV6: 20: fd = Socket(AF_INET6, SOCK_STREAM, 0); 21: break; 22: #endif 23: #ifdef IPPROTO_SCTP 24: case IPPROTO_SCTP: 25: fd = Socket(AF_INET, SOCK_SEQPACKET, IPPROTO_SCTP); 26: break; 27: #endif 28: default: 29: err_quit("Can't create fd for level %d\n", ptr->opt_level); 30: } 31: len = sizeof(val); 32: if (getsockopt(fd, ptr->opt_level, ptr->opt_name, 33: &val, &len) == -1) { 34: err_ret("getsockopt error"); 35: } else { 36: printf("default = %s\n", (*ptr->opt_val_str) (&val, len)); 37: } 38: close(fd); 39: } 40: } 41: return 0; 42: }
- opt_val_str是一个函数指针,会返回字符串然, main函数会通过line 36把默认值写入 到standard output
- 在Ubuntu上面测到的结果如下(某些const不支持,删掉了)
hfeng@ubuntu-server64:~/tmp/unpbook/sockopt$ ./checkopts SO_BROADCAST: default = off SO_DEBUG: default = off SO_DONTROUTE: default = off SO_ERROR: default = 0 SO_KEEPALIVE: default = off SO_LINGER: default = l_onoff = 0, l_linger = 0 SO_OOBINLINE: default = off SO_RCVBUF: default = 87380 SO_SNDBUF: default = 16384 SO_RCVLOWAT: default = 1 SO_SNDLOWAT: default = 1 SO_RCVTIMEO: default = 0 sec, 0 usec SO_SNDTIMEO: default = 0 sec, 0 usec SO_REUSEADDR: default = off SO_REUSEPORT: (undefined) SO_TYPE: default = 1 IP_TOS: default = 0 IP_TTL: default = 64 IPV6_DONTFRAG: (undefined) IPV6_UNICAST_HOPS: default = 64 IPV6_V6ONLY: default = off TCP_MAXSEG: default = 536 TCP_NODELAY: default = off SCTP_AUTOCLOSE: (undefined) SCTP_MAXBURST: (undefined) SCTP_MAXSEG: (undefined) SCTP_NODELAY: (undefined)
Socket States
- connected TCP socket必须从listening socket下面继承下面这些option
- SO_DBUG
- SO_DONTROUTE
- SO_KEEPALIVE
- SO_LINGER
- SO_OOBINLINE
- SO_RECVBUF
- SO_RCVLOWAT
- SO_SNDBUF
- SO_SNDLOWAT
- TCP_MAXSEG
- TCP_NODELAY
- 为了保证上面的参数能在connected socket里面出现,我们必须在listening socket的 时候就设置这些参数
Generic Socket Options
- 虽然我们前面说到了generic socket option,但是其实这些socket并不是那么的"generic", 它们顶多只能对"几种"协议有效,有些甚至只对一红协议有效
SO_BROADCAST Socket Option
- 打开或者关闭进程发送broadcast message的功能.一般只能在datagram socket种实现,并且 要求底层的网络支持广播(SCTP和TCP这种point-to-point的协议就不行)
SO_DEBUG Socket Option
- 设置了这个选项之后,kernel会跟踪TCP所有的packet,然后保存在kernel的buffer里面,我们 可以通过trpt来读取
SO_DONTROUTE Socket Option
- 通常用来强制从某个interface传出数据,而不经过路由器的路由表
SO_ERROR Socket Option
- 当socket上面发生错误的时候, Berkeley系列的kernel会设置so_error为一个Unix
Exxx value.这叫做socket's pending error.进程会马上以如下两种方式得知错误:
- 如果进程被block在select里面,那么select会马上返回,errno肯定就设置了
- 如果在使用signal-driven I/O的话,那么系统会对进程发送SIGIO信号
- 得知错误后,进程就可以从"出现SO_ERROR错误的socket"里面读取so_error的值
- 这个参数是我们遇到的第一个"可以读取"但是"不可以设置"的参数
SO_KEEPALIVE Socket Option
- 如果设置了这个参数,那么当TCP连接建立,但是很久都没有通信的情况下,一方会发送
一keep-alive probe给对方. keep-alive probe是一种对方必须回复的TCP segment.
一般对方会有如下反应:
- 返回一个ACK,说明一切正常.那么这次成功的probe是不会通知给上层应用的
- 返回一个RST,说明对方重启或者死机.socket's pending error会设置成ECONNRESET
- 如果长期不返回,那么就会不停的发送probe(不同实现不一样,Berkeley会最终在11分
15秒的情况下下结论,对方无法连通,放弃尝试):
- 如果所有的尝试都失败,那么就设置错误为ETIMEOUT(超时)
- 如果socket收到来自ICMP的错误,一般来说是"host unreachable",那么我们也就 设置错误为EHOSTUNREACH
- 这个参数一般是server在应用(虽然client也可以用),因为server在大部分的时间都是在 等待client要求什么服务
SO_LINGER Socket Option
- 这个参数指导了close如何对待connection-oriented 协议(比如TCP, SCTP但是没有UDP)
- 默认情况下close会马上返回(甚至不等四次挥手完成).但是如果在socket send buffer 里面依然有数据的情况下,会尽量完成给对方的传递, SO_LINGER就是改变这种默认设置的
- 调用setsockopt的时候会设置linger结构体的两个部分:
struct linger { int l_onof; /* 0=off, nonzero=on */ int l_linger; /* linger time, POSIX specifies units as seconds */ };
- 如果l_onoff是0,那么这个option是关闭的.l_linger不会被使用,close还是默认 的马上关闭
- 如果l_onoff非0, 而且l_linger是0的话,那么close的同时,所有send buffer里面 的数据都丢弃掉:这样的话,常规的四次握手就全部不能实施了!这会避免TIME_WAIT, 我马上知道TIME_WAIT有两个作用1防止最后的FIN丢失2防止同一个线路上面在2MSL 内新建了其他的connection.第2点就无法避免了
- 如果lonff非0, 而且l_linger非0的话.就是依然会执行四次挥手,只不过现在会加上 一个时间限制:如果在l_linger秒内依然完成不了的话,那么会强制返回.
- 下面我们来总结一下close的几种返回情况:
- 默认情况下:
- client的close是直接返回(发送完FIN就完了,不等ACK回来),server端也是一样的.
- 存在这么一种可能:client的FIN发送给了server,但是server很忙,所以FIN就等待 在server的receive buffer了,在server读取到这个FIN之前,很可能server就crash 了.这个时候client永远无法得知server的情况
- 值得注意的是ACK是系统返回的,不是server进程.所以即便ACK返回了,数据可能还是 在server的receive buffer里面.
- 使用SO_LINGER,并且设置linger time为足够大正数的情况:
- close是等到ACK回来以后才返回的.
- 但是ACK只是证明了server host接收到这个FIN,但是并不意味这server进程读取到了 这个FIN
- 使用SO_LINGER,linger time设置的不够大:
- close等了很短的linger time时间就返回了:因为没等到ACK, close返回了-1,而且 errno设置为了EWOULDBLOCK
- 默认情况下:
- 总结起来就是SO_LINGER只能让我们知道server host收到了FIN,但不代表server读取成功了
- client可以使用shutdonw来先half close,然后read的办法来确认对方的server进程读取 到了你的FIN
SO_OOBINLINE Socket Option
- 设置这个参数后, out-of-band 数据会放到normal input queue
SO_RECVBUF and SO_SNDBUF Socket Option
- 我们前面提起过TCP,UDP都有自己的send buffer和receive buffer:
- 对于TCP来说,由于通知窗口(advertised window)的存在,receive buffer不会接受到过多 的信息的,如果发送方执意ignore通知窗口,发送过多的信息,那么会被接收方丢弃
- UDP没有flow control的概念,其会随意发送,超过receive buffer的内容会被丢弃,UDP 发送过快,甚至会溢出send buffer,溢出部分也是被丢弃.
- SO_RECVBUF和SO_SNDBUF就是用来设置receive buffer和send buffer的默认值的.需要注意
的是:
- send buffer要在client调用connect开始三次握手之前设置(因为windows scale参数会 在三次握手之前设置)
- receive buffer也要在server调用listen之前设置(也是因为windows scale 参数.我们 还记得第二章讲过windows scale参数是个新参数,比如client和server都确认对方支持才 可以使用)
SO_RECVLOWAT and SO_SENDLOWAT Socket Option
- 前面我们讲过每个send, receive buffer都有一个low water mark.(select会使用,select 判断一个socket是否可读,就看其receive buffer的值是不是大与这个low-water mark要大)
- receive low-water mark的默认是值一般是1 (对TCP,UDP都是)
- send low-water mark的默认值对TCP来说是2048
- send low-water mark对于UDP来说意义不大,因为它不会保留一份数据在sender buffer里面 (防止发送失败而重发).所以我们的的send low-water mark只要小于 send buffer size, 那么我们就一直可写(超过一定数据量就可以发送,太少了不值当). 其实UDP只有send bufer size和send low-warter mark的概念,其并没有send buffer…(囧)
SO_RCVTIMEO and SO_SNDTIMEO Socket Options
- 这两个参数为我们的socket设置了发送和接受的timeout时间. 其数据类型为timeval(和select 使用的一样,精度为ms)
- SO_RCVTIMEO为如下五个函数设置了timeout:
- read()
- readv()
- recdv()
- recvfrom()
- recvmsg()
- SO_SNDTIMEO为如下五个参数设置了timeout:
- write()
- writev()
- send()
- sendto()
- sendmsg()
SO_REUSEDADDR and SO_REUSEPORT Socket Options
- SO_REUSEDADDR 参数有如下四种用途:
- 允许一个listening server在已经有其他socket占用某个端口比如22,的情况下再
次在这个端口上建立一个socket.下面是模拟这个使用场景:
- 建立一个listening serveer
- 一个connection request来了, fork一个child来处理这个client
- listening server经过一定时间运行关闭了.但是child依然在处理着来自client 的请求.
- listening server重新启动: 通常重启会失败的.因为在这个well-known(22)的 端口上面有其他应用了.但是我们在socket()和bind()之间加上设置这个SO_REUSEDADDR 的参数的话,我们就可以.
- 允许在某个server以wildcard IP运行在某个port的情况下, 以其他specific的IP
来增加新的server.注意我们这里第一次使用的是wildcard IP,第二次使用的是其
specific IP. 如果两次IP和端口都是一样的.那在TCP里面是绝对不可以的.下面
是使用场景模拟:
- 假设一个local host的IP地址为198.69.10.2, 但是其有两个IP aliase: 192.168.10.128和192.168.10.129
- 第一个HTTP server会bind wildcard IP, 和端口20
- 第二个HTTP server会bind 192.168.10.128 和端口20: 通常会bind失败,但是 加上参数SO_REUSEADDR在bind前面就不会失败了
- 第三个HTTP server会bind 192.168.10.129 和端口20: 通常会bind失败,但是 加上参数SO_REUSEADDR在bind前面就不会失败了
- 允许一个进程bind的时候使用同样的port,只要IP不一样就可以.
- 允许一个进程bind的时候使用同样的port,同样的IP.这个只有UDP支持.
- 允许一个listening server在已经有其他socket占用某个端口比如22,的情况下再
次在这个端口上建立一个socket.下面是模拟这个使用场景:
- 还有一个很常见的情况就是前一个connection已经进入TIME_WAIT状态, 如果你不设置为 SO_REUSEADDR的话,即便前面一个connection已经马上确定要死了,但是你还是不能bind 到它的ip+port上面,要一直等到TIME_WAIT退出.
- BSD后期引入了SO_REUSEPORT,其功能在普通IP上面是SO_REUSEADDR的超集,除了 SO_REUSEADDR的全部功能外,还允许完全相同的souce地址和ip地址:但是也是有代价的, 那就是两个程序(已经运行在192.168.10.128:80的第一个进程和下一个也想要在 192.168.10.128:80运行的进程)都必须设置SO_REUSEPORT
- 如果IP绑定的是multicase 地址,那么SO_REUSEADDR和SO_REUSEPORT是一模一样的
SO_TYPE Socket Option
- 返回socket type.
SO_USELOOPBACK Socket Option
- 这个参数只对AF_ROUTE的routign domain起作用.
- 如果这个参数为enable的化, socket会收到一份接受数据的拷贝(比如给127.0.0.1)
IPv4 Socket Options
- 前面说过setsockopt的参数里面的level是用来指示所属协议的,这一节所说的洗衣额 都是IPv4的,其level值为IPPROTO_IP
IP_HDRINCL Socket Option
- 当需要编写自己的IP数据包首部时,可以在原始套接字上设置套接字选项IP_HDRINCL. 在不设置这个选项的情况下,IP协议自动填充IP数据包的首部
IP_OPTIONS Socket Option
- 设置这个允许我们自己设置IPv4 Header
IP_RECVDSTADDR Socket Option
- 设置该选项导致所接受到的UDP数据报的目的IP地址返回(在函数recvmsg的帮助下)
IP_RECVIF Socket Option
- 设置该选项导致所接受到的UDP数据报的接口索引(index of the interface)返回(在 函数recvmsg的帮助下)
IP_TOS Socket Option
- 该设置让我们用来设置IP的TOS域
IP_TTL Socket Option
- 这个用来设置(还可以读取)TTL(Time To Live)的值
ICMPv6 Socket Option
ICMP6_FILTER Socket Option
- 我们用这个来设置icmp6_filter structure(这个结构体描述了哪些ICMPv6 message会 传递给process)
IPv6 Socket Options
- to be continue
TCP Socket Options
- TCP 协议的level设置为IPPROTO_TCP
TCP_MAXSEG Socket Option
- 这个设置让我们读取(或者设置,但很多实现不支持设置,因为他们把MSS设置成了 read-only)MSS.也就是TCP传递给对方的maximum amount data
- 一般来说MSS都是对方在SYN的时候一块传递给我们的,当然我们也可以选择一个比 对方传来的MSS更小的值
- 如果在链接建立之前就读取这个值,那么返回的就是"如果对方不发送MSS,我们默认 使用多大的MSS"
- 如果timestamp option开启的话. 我们的"真正MSS使用值"会比"返回的MSS"要小, 因为timestamp option会占用12bytes
- 我们还要知道的是MSS在connection的整个生命过程中,可能会改变的(如果TCP支持 path MTU discovery)
TCP_NODELAY Socket Option
- 这个选项会开启TCP的Nagle算法.默认情况下,这个选项是开启的.
- Nagle算法主要是为了减少WAN上面的小的packet:
- 如果当前connection有outstanding data(数据发出,但是没有被对方ACK),那么 "small packet"就不能再发送了
- 所谓"small packet",就是packet比MSS还小的数据
- 这样的话,促使TCP尽可能的只发送full-size packet.从而提高传输效率
- small packet的主要产生者是Rlogin和Telnet. 在LAN上面,small packet导致的 延迟并不是特别的明显,但是在WAN上面.这个延迟就会很明显,并且会因为Nagle算法 而放大:因为只有数据确认了才发送下一个.数据确认的过程在WAN上面长达几秒
- Nagle算法经常和其他的TCP算法合作.比如, delayed ACK算法.这个算法会让TCP 延迟发送ACK一段时间(通常是50-200ms):因为希望这个ACK和搭后面的数据的"顺风车", 能减少网络上一个packet.
- 但是如果server不产生返回的data,那么ACK的返回就会明显的变慢了.这种情况下就要 设置TCP_NODELAY为disable啦.
- 在使用Rlogin和Telnet的时候,delayed算法就和Nagle搭上界了: 本来ACK要马上返回的, 但是等了一等,就等到了server返回的字符.一起返回了.
- 还有写设计不好的请求,比如一个请求一共400bytes,却分成了两份
- 4byte的request type
- 396 byte的request date.
- 这种设计会极大的浪费带宽.因为:
- 由于第一个4byte没有ACK, 第二个396bytes无法发送
- 而第一个ACK还要等50-200ms才发送,如果没有"顺风车"的情况.
- 解决上面这种不良设计的方法有如下:
- 使用writev()替代write.writev将多个数据存储在一起,将驻留在两个或更多的 不连接的缓冲区中的数据一次写出去, 这就会只产生一个TCP segment. 这个是 最好的解法
- 把4bytes和396bytes数据都拷贝到一个buffer里面然后write一次
- 设置TCP_NODELAY为disable,然后调用两次write. 这个是最差的解法,由于对网络 有危害,我们甚至都不要去考虑去这么做.
SCTP Socket Options
- to be continue
fcntl Function
- fcntl意为"file control", 主要是来对file descriptor进行一些操作.socket也是一种 file descriptor,所以fcntl也可以对它
- 下图是fcntl,ioctl和routing sockets能够进行的操作列表
Option fcntl ioctl Routing socket POSIX Set socket for nonblocking I/O F_SETFL, O_NONBLOCK FIONBIO fcntl Set socket for signaldriven I/O F_SETFL, O_ASYNC FIOASYNC fcntl Set socket owner F_SETOWN SIOCSPGRP fcntl Get socket owner F_GETOWN SIOCGPGRP fcntl Get #bytes in socket receive buffer FIONREAD Test for socket at out-of-band mark SIOCATMARK sockatmark Obtain interface list SIOCGIFCONF sysctl Interface operations SIOCIFxxx ARP cache operations SIOCxARP RTM_xxx Routing table operations SIOCxxxRT RTM_xxx - fcntl在网络编程方面的贡献如下:
- Nonblocing I/O : 我们可以设置文件flag:O_NONBLOCK(通过F_SETFL)
- Signal-driven I/O: 我们可以设置文件flag:O_ASYNC(通过F_SETFL)
- F_SETOWN可以设置SIGIO, SIGURG信号的socket owner(process ID 或者 process group ID)
- 下面来看看fcntl的定义
#include <fcntl.h> /**********************************************/ /* Returns: depends on cmd if OK, -1 on error */ /**********************************************/ int fcntl(int fd, int cmd, .../*int arg*/);
- fd参数通常有一系列的flags(比如O_NONBLOCK, O_ASYNC), 通过cmd参数来进行设置( F_SETFL)或者读取(F_GETFL)
- 下面是设置O_NONBLOCK的例子
int flags; if ((flags = fcntl(fd, F_GETFL,0)) < 0) { err_sys("F_GETFL error"); } flags |= O_NONBLOCK; if (fcntl(fd, F_SETFL, flags) < 0) { err_sys("F_SETFL error"); }
- 注意一定要先通过F_GETFL,把原来的参数读取过来,否则,像下面一样,虽然设置
nonblocking成功,但同时也就把原来的参数都清零了
/* !! Wrong way to set a socket as non blocking !! */ if (fcntl(fd, F_SETFL, O_NONBLOCK) < 0) { err_sys("F_SETFL error"); }
- 关闭nonblocking的设置也很简单,只在位操作上有稍许不同(当然还是要读取原来
的设置)
int flags; if ((flags = fcntl(fd, F_GETFL,0)) < 0) { err_sys("F_GETFL error"); } flags &= ~O_NONBLOCK; if (fcntl(fd, F_SETFL, flags) < 0) { err_sys("F_SETFL error"); }
Chapter 8: Elementary UDP Socket
Introduction
- UDP和TCP的最大不同就是,UDP是一个connectionless, unreliable的datagram协议.
意义上是connection-oriented, reliable的byte stream协议. 从函数调用图来看
UDP是被TCP简单很多

recvfrom and sendto Functions
- 这两个函数和read, write相似,只不过多了几个参数
#include <sys/socket.h> /*******************************************************************/ /* Both return: number of bytes read or written if OK, -1 on error */ /*******************************************************************/ ssize_t recvfrom(int sockfd, void* buff, size_t nbytes, int flags, struct sockaddr* from, socklen_t* addrlen); ssize_t sendto(int sockfd, const void* buff, size_t nbytes, int flags, const struct sockaddr* to, socklen_t addrlen);
- 前三个参数sockfd, buff, nbytes就正好对应read和write的前三个参数(descriptor, pointer to buffer to read into or write from, number of bytes to read or write)
- flag一般为0
- from参数也是一个socket address structure,表示数据从哪里来的. addrlen是一个 指针(返回值),表示收到了多少字节.
- recvfrom如果只看后两个参数的话,会很像accept()
- to参数一般是一个socket address structure (长度由addrlen指定),表示数据传到 什么地方.
- sendto如果只看后两个参数的话,会很想connect()
- UDP是可以传递0个字节的.对方通过recvfrom()就会收到一个0,这并不意味着我们要关闭 connection,话说回来了,UDP里面就没有connection
UDP Echo Server: main Function
- 我们来看一个UDP server的例子
#include "unp.h" int main(int argc, char *argv[]) { int sockfd; struct sockaddr_in servaddr, cliaddr; sockfd = Socket(AF_INET, SOCK_DGRAM, 0); bzero(&servaddr, sizeof(servaddr)); servadr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(SERV_PORT); Bind(sockfd, (SA*)&servaddr, sizeof(servaddr)); dg_echo(sockfd, (SA*)&cliaddr, sizeof(cliaddr)); return 0; }
- UDP的类型就是SOCK_DGRAM了(也就是datagram), 还记得TCP么,是SOCK_STREAM(byte stream).这也是两者的重要不同.
UDP Echo Server: dg_echo Function
- server的主要工作都是dg_echo完成的
#include "unp.h" void dg_echo(int sockfd, SA* pcliaddr, socklen_t clilen) { int n; socklen_t len; char mesg[MAXLINE]; for (; ;) { len = clilen; n = Recvfrom(sockfd, mesg, MAXLINE, 0, pcliaddr, &len); Sendto(sock, mesg, n, 0, pcliaddr, len); } }
- server的处理很简单recvfrom了以后再sendto,需要注意的是这个函数永远都不会 结束,因为UDP是connectionless的协议,没有EOF
- UDP是提供的一种iterative server.不像TCP那样fork出来单独的process来处理, 而是一个process处理所有的需求
- UDP每个socket也都是有自己独立的receive buffer的,如果多个datagram在同一个
时间到达的话,是会放到buffer里面等待读取的.但是前面说了UDP不会fork,所以一直
只有一个proces在处理的话,其receive buffer也就只有一份.

- 而TCP每个process都有一个receive buffer

- 前一节介绍的main()是protocol-dependent的(因为指定了AF_INET了),而这一节的 dg_echo却是protocol-independent的,因为dg_echo永远不会去内部查看传递给它的 这个SA结构体的内容(只把它当作一个generic的指针).dg_echo只是把pcliaddr在 recvfrom和sendto直接传递而已.
UDP Echo Client: main Funtion
- udp client的代码如下
1: #include "unp.h" 2: int main(int argc, char *argv[]) 3: { 4: int sockfd; 5: struct sockaddr_in servaddr; 6: 7: if (argc != 2) { 8: err_quit("usage: udpcli <IPaddress>"); 9: } 10: 11: bzero(&servaddr, sizeof(servaddr)); 12: servaddr.sin_family = AF_INET; 13: servaddr.sin_port = htons(SERV_PORT); 14: Inet_pton(AF_INET, argv[1], &servaddr.sin_addr); 15: 16: sockfd = Socket(AF_INET, SOCK_DGRAM, 0); 17: dg_cli(stdin, sockfd, (SA*) &servaddr, sizeof(servaddr)); 18: return 0; 19: }
- line 11-14: 填满我们的generic socket structure, 当然现在用的是SOCK_DGRAM
- 大部分的工作是在dg_cli里面完成的
UDP Echo Client: dg_cli Function
- dg_cli完成了主要的client的工作
1: #include "unp.h" 2: 3: void dg_cli(FILE* fp, int sockfd, const SA* pservaddr, socklen_t servlen) { 4: int n; 5: char sendline[MAXLINE], recvline[MAXLINE + 1]; 6: 7: while (Fgets(sendline, MAXLINE, fp) ! = NULL) { 8: Sendto(sockfd, sendlin, strlen(sendline), 0, pservaddr, servlen); 9: 10: n = Recvfrom(sockfd, recvline, MAXLINE, 0, NULL, NULL); 11: 12: recvline[n] = 0; /* null terminate */ 13: Fputs(recvline, stdout); 14: } 15: }
- line 7: 使用fgets()从fp(也就是stdin)读取一行
- line 8: 使用sendo()把刚才fget()读取的数据发送给server
- line 10: 使用recvfrom()读取serve的反馈
- line 13: 使用fputs()把反馈打印到stdout上.
- 在TCP里面,client端可以使用bind来要求获取指定的端口号.或者在connect()的时候, 赋予socket一个临时端口号. 在UDP这里是调用sendto的时候,会自动赋予临时端口号
- 我们的recffrom把第五第六个参数设置成了NULL,说明我们不关心对方(返回给我们数据 的server)是谁. 这很可能会引入风险:谁都可以发送数据给我们,而且我们还会读取到.
- dg_cli和dg_echo一样是protocol-independent的.